






一、HDFS的JavaAPI操作
之前我们都是用HDFS Shell来操作HDFS上的文件,现在我们通过编程的形式操作HDFS,主要就是用HDFS中提供的JavaAPI构造一个访问客户对象,然后通过客户端对象对HDFS上的文件进行相应的操作(新建、上传、下载、删除等)。
1、常用的类
(1)Configuration:该类的对象封装了客户端或服务器的配置
(2)FileSystem:该类的对象是一个文件系统对象,通过该对象调用一些他的方法,从而实现对文件的操作。
| mkdirs(Path f) | 新建子目录 |
| copyFromLocalFile(Path src,Path dst) | 从本地磁盘复制文件到HDFS |
| copyToLocalFile(Path src,Path dst) | 从HDFS复制文件到把我弄得磁盘 |
2.HDFSAPI开发的步骤
(1)在HDFS上创建文件夹
A.设置客户端身份,以具备权限在hdfs上进行操作
System.setProperty("HADOOP_USER_NAME","root”);
B.与HDFS建立连接
a.创建配置对象实例
Configuration conf = new Configuration();b.设置操作的文件系统是hdfs,并且指定hdfs的操作地址
conf.set("fs.defaultFS","hdfs://192.168.204.125:9000");c.创建FileSystem对象
FileSystem fs = FileSystem.get(conf);
d.断开与HDFS平台的连接
fs.close();
C.判断要创建目录是否存在,不存在则创建

(2)在HDFS上传文件
(3)从HDFS上下载文件
(4)从HDFS上删除文件
在IDEA中的实例:

需要注意的以下几点:
1)导入Configuration时必须是hadoop.conf.Configuration
导入FileSystem时必须是hadoop.fs.FileSystem
导入Path时必须是hadoop.fs.Path
2)"fs.defaultFS","hdfs://192.168.204.125:9000"此处可以在虚拟机中配置hadoop下的core-site.xml文件里查看

注意这里的master1即192.168.204.125(linux下可以直接写master1主机名,是因为配置hadoop时做了hosts映射,而IDEA中没有做hosts映射,所以必须写192.168.204.125这样的主机ip)
3)"hdfs://(192.168.204.125):9000"此处的ip是虚拟机中的master主机的ip
IDEA中运行错误:

1)首先在电脑本地下载一个Hadoop安装包,后解压,将解压后的hadoop-2.4.1、winutils.exe 和hadoop.dll这三个文件放到同一目录下
2)将log4j.properties文件粘贴到IDEA中创建的类的对应src下
3)将winutils.exe 和hadoop.dll放到解压好的hadoop-2.4.1的bin目录下
4)配置hadoop坏境变量:
此电脑----属性----高级系统设置----环境变量----新建:

变量值必须是你所解压的hadoop-2.4.1的路径
在系统变量中找path变量将hadoop引用进去

path----编辑----新建----添加一行:%HADOOP_HOME%\bin
5) Windows键+R:打开cmd,输入hadoop,后输入hadoop version

hadoop环境变量配置完成
6)重启IDEA后重新运行
7)依旧报错:
a.查看虚拟机中hadoop是否启动,jps后进程是否都有
b.若没有namenode或datanode:进去到hadoop目录下的dfs下,删除dfs(rm -rf)下的所有文件,后命令行中输入hdfs namenode -format(格式化hdfs命令),重新启动hadoop:start-all.sh
c.如果是格式化重启hadoop后是有namenode没有datanode或者有datanode没有namenode这种情况时:
原因:
可能是当我们使用hadoop namenode -format格式化namenode时,会在namenode数据文件夹(这个文件夹为自己配置文件中dfs.name.dir的路径)中保存一个current/VERSION文件,记录clusterID,datanode中保存的current/VERSION文件中的clustreID的值是上一次格式化保存的clusterID,这样,datanode和namenode之间的ID不一致。
解决方法:
在dfs/name目录下找到一个current/VERSION文件,记录clusterID并复制,后dfs/data目录下找到一个current/VERSION文件,将其中clustreID的值替换成刚刚复制的clusterID的值即可;重新启动hadoop,jps就有了
d.继续报错:


这样的错误,首先可以打开192.168.204.125:50070网址查看Live Nodes

若显示为1,则证明slave1和slave2中node进程没有
解决方法:
在master1主机中重新给slave1和slave2中传输即可
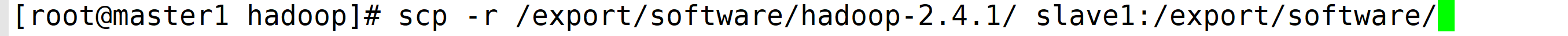
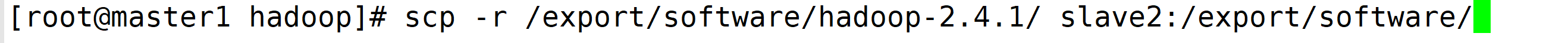 重新启动hadoop,然后jps就有了
重新启动hadoop,然后jps就有了
然后重新启动IDEA,重新运行

















 1154
1154











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









