






数据来源:使用使用师兄自学课程2.0从2021.8~2022.12的弹幕数据进行内容分析
数据如下:(在该份数据中有5张excel表格,接下来我们会对这5张表格进行处理)
接下来我们以表格1为例,对其字段进行分析。
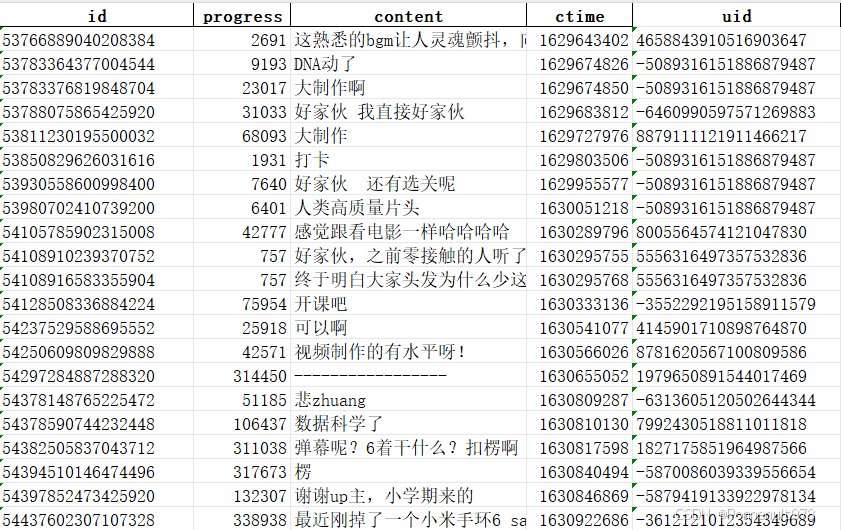
这里的字段包换,id,progress,content,ctime,uid。
分别代表:id——不同的弹幕,progress——进度条,content——弹幕内容,ctime——弹幕时间,uid——发弹幕的人
1.数据处理
-
对所用数据进行导入,同是在系统中筛选出所需的xlsx文件,同时对表格内容进行拼接。
import pandas as pd
user_level = pd.read_excel('user_level.xlsx')
import os
excel_list = []
for item in os.listdir('./'):
if 'xlsx' in item and 'user_level' not in item:
excel_list.append(item)
danmu = pd.DataFrame()
for item in excel_list:
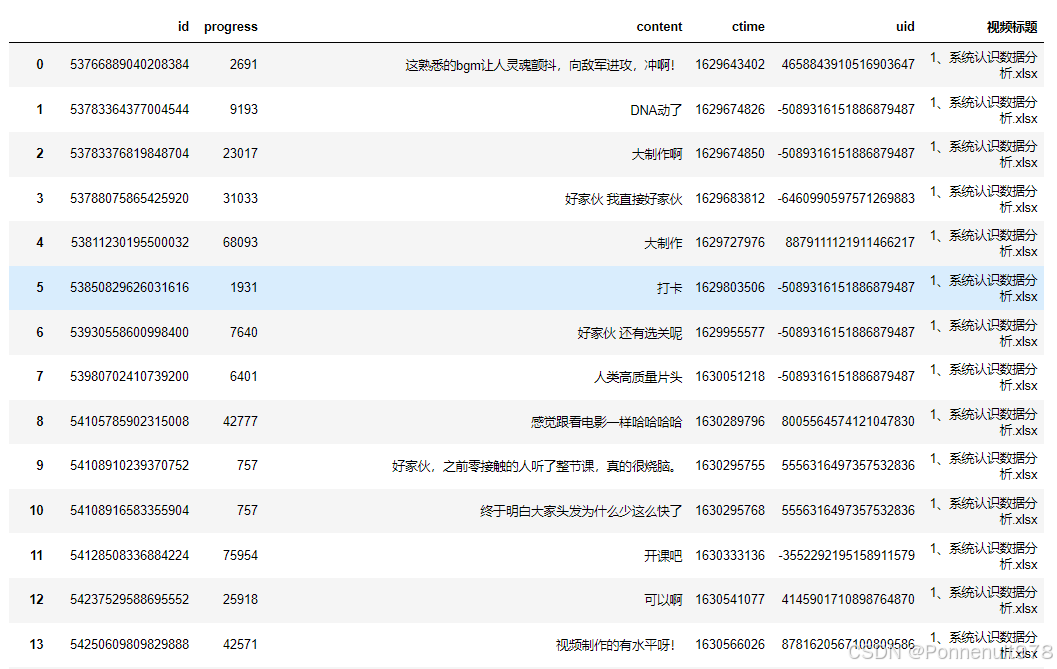
excel = pd.read_excel(item, converters={'uid': str, 'id': str})
excel['视频标题'] = item
danmu = pd.concat([danmu, excel], axis=0)
danmu结果如下:
知识点:
converters={'uid':str,'id':str}: 这是一个参数,用于指定在读取 Excel 文件时将特定列的数据转换为特定的数据类型。在这个例子中,converters 是一个字典,其中:'uid':str 表示将 uid 列的数据转换为字符串类型。'id':str 表示将 id 列的数据转换为字符串类型。
pd.concat([danmu, excel], axis=0): 这是 Pandas 库中的一个函数,用于连接(合并)两个或多个 DataFrame。在这个例子中,pd.concat 将 danmu 和 excel 这两个 DataFrame 沿着指定的轴进行合并。axis=0 表示沿着行的方向进行合并(即纵向合并)。如果 axis=1,则表示沿着列的方向进行合并(即横向合并)。
2.时间处理
2.1.时间处理
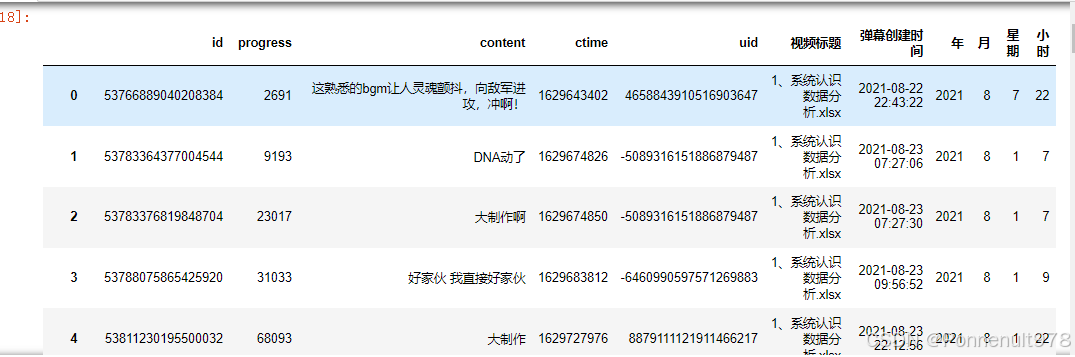
同时在原有表格当中新建:弹幕创建时间,年,月份,星期,小时等字段。
from datetime import datetime
danmu['弹幕创建时间'] = danmu['ctime'].map(datetime.fromtimestamp)
danmu['年'] = danmu['弹幕创建时间'].map(lambda x: x.year)
danmu['月'] = danmu['弹幕创建时间'].map(lambda x: x.month)
danmu['星期'] = danmu['弹幕创建时间'].map(datetime.isoweekday)
danmu['小时'] = danmu['弹幕创建时间'].map(lambda x: x.hour)
danmu结果如下:
知识点:
danmu['ctime']:这部分代码选取 danmu DataFrame 中名为 ctime 的列。ctime 列中应包含 Unix 时间戳(秒数表示的时间)。
map():map 是一个方法,它应用一个函数到 Series(即 DataFrame 的一列)的每一个元素。
在这里,它将 datetime.fromtimestamp 函数应用到 ctime 列中的每一个元素。
datetime.fromtimestamp:datetime 是 Python 的 datetime 模块中的一个类。
fromtimestamp 是 datetime 类的一个方法,它将一个 Unix 时间戳(从1970年1月1日以来的秒数)转换为一个 datetime 对象,表示相应的日期和时间。
2.2.时间分析
2.2.1.月份
- 基于2022年的月份进行弹幕数据分析
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei']
danmu_year = danmu[danmu['年']==2022]
danmu_year.groupby('月份')[['id']].count().plot()结果如下:
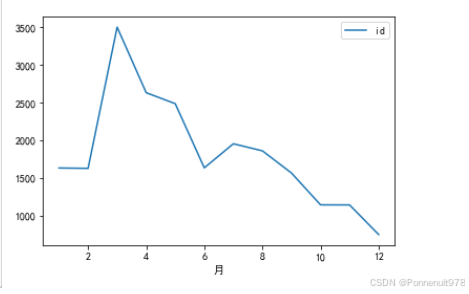
分析:22年,3月份的弹幕非常活跃
- 基于2022年的月份对发弹幕的人进行数据分析
danmu_year.groupby('月份')[['uid']].nunique().plot()结果如下:
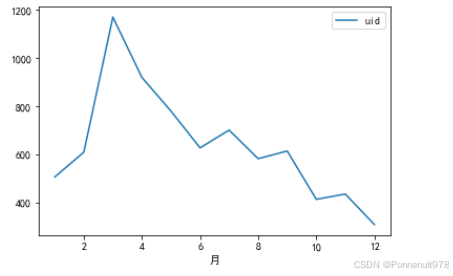
分析:22年,3月份,发弹幕的人也是最多的
2.2.2.星期
- 基于星期进行弹幕数据分析
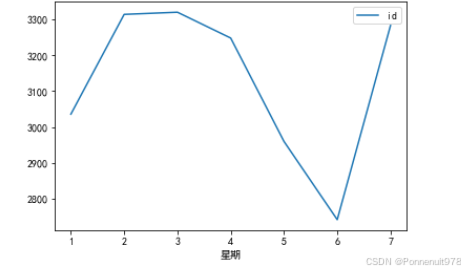
danmu_year.groupby('星期')[['id']].count().plot()结果如下:
- 基于星期对发弹幕的人进行数据分析
danmu_year.groupby('星期')[['uid']].nunique().plot()结果如下:
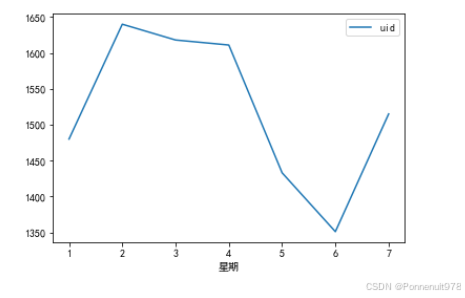
分析:惊奇的发现,工作日1~4,周天,弹幕是最活跃的;周五或者周六活跃度会下降
2.2.3.小时
- 基于小时进行弹幕数据分析
danmu_year.groupby('小时')[['id']].count().plot()结果如下:
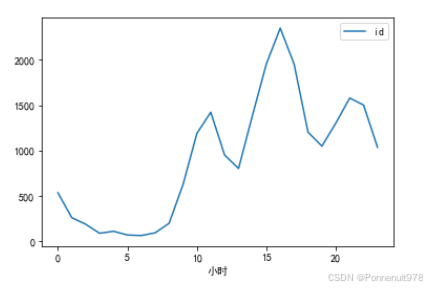
- 基于小时对发弹幕的人进行数据分析
danmu_year.groupby('小时')[['uid']].nunique().plot()结果如下:
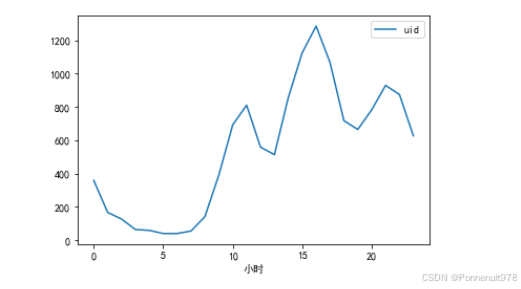
分析:按照小时分析可得出,大家白天摸鱼看视频(15时)、晚上也看很勤奋(20时),大家都在偷偷的卷呀
3.用户画像
3.1.用户处理
#对DataFrame danmu按uid列分组,并对每个组计算id列的数量,然后将每个组的结果广播到原DataFrame中。
danmu['用户弹幕数']=danmu.groupby('uid')['id'].transform('count')
danmu
结果如下:
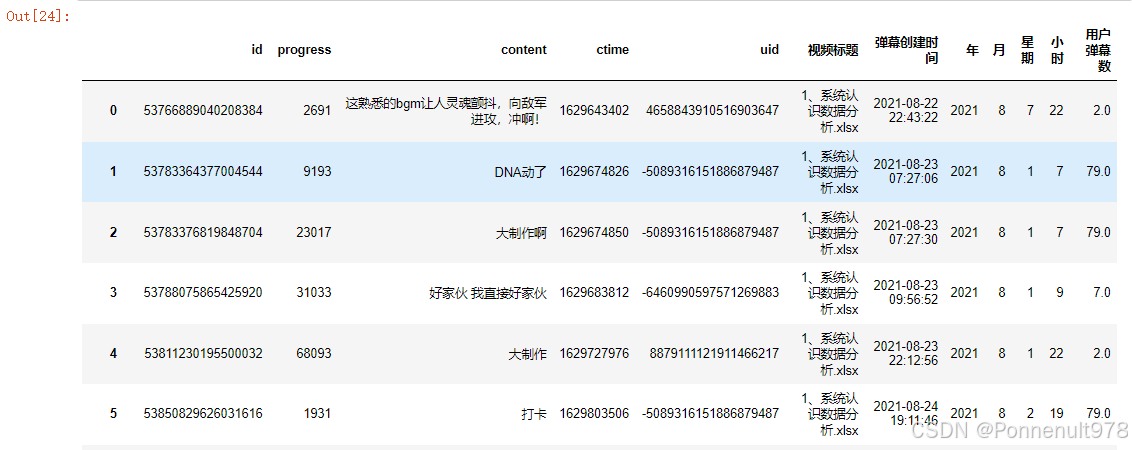
- 根据uid合并danmu表和user_level表,注意合并时两个表的uid字段类型要一样,否则报错
user_level['uid']=user_level['uid'].astype(str)
danmu_level=pd.merge(danmu,user_level,on='uid',how='inner')
danmu_level
3.2.弹幕内容
- 对每个用户发的弹幕数量,进行降序排序
danmu_level.groupby('uid'[['id']].count().sort_values('id',ascending=False)结果如下:
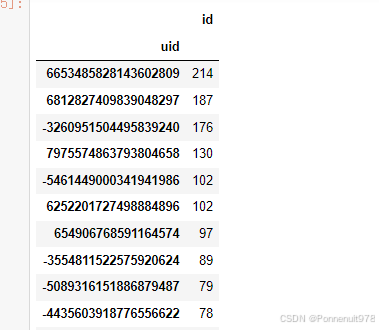
- 对发弹幕数量最多的uid的弹幕内容进行分析
#这条命令设置了Pandas在显示DataFrame时最多显示的行数为300行。
pd.set_option('display.max_rows',300)
danmu_level[danmu_level['uid']=='6653485828143602809']结果如下:
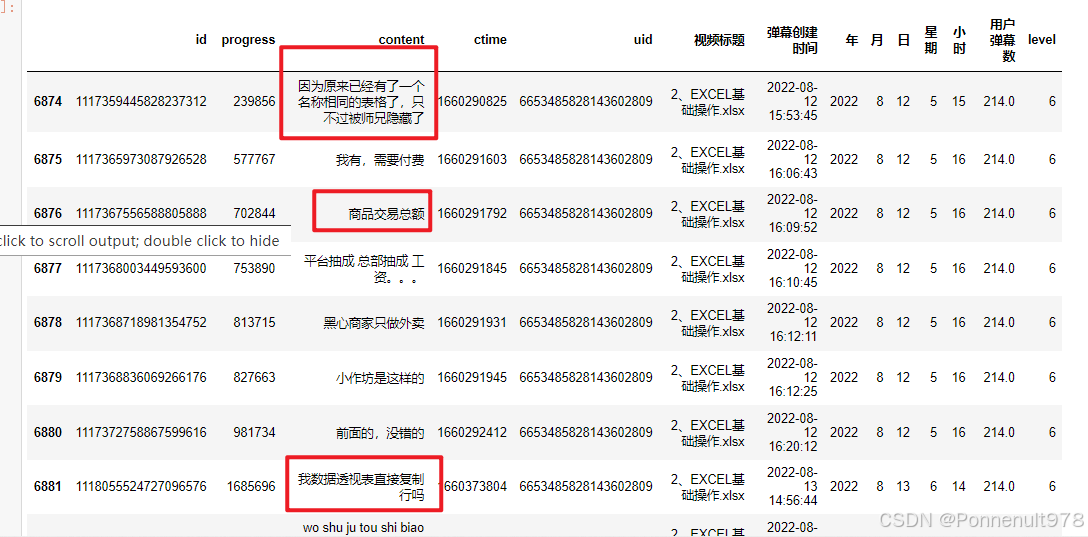
分析:老大总共发了214条弹幕,具体内容可以发现,是一个上课非常积极的人,师兄在课程内有问,老大必有答,建议,纳为《学习课代表》
- 对发弹幕数量第二多的uid的弹幕内容进行分析
danmu_level[danmu_level['uid']=='6812827409839048297']结果如下:
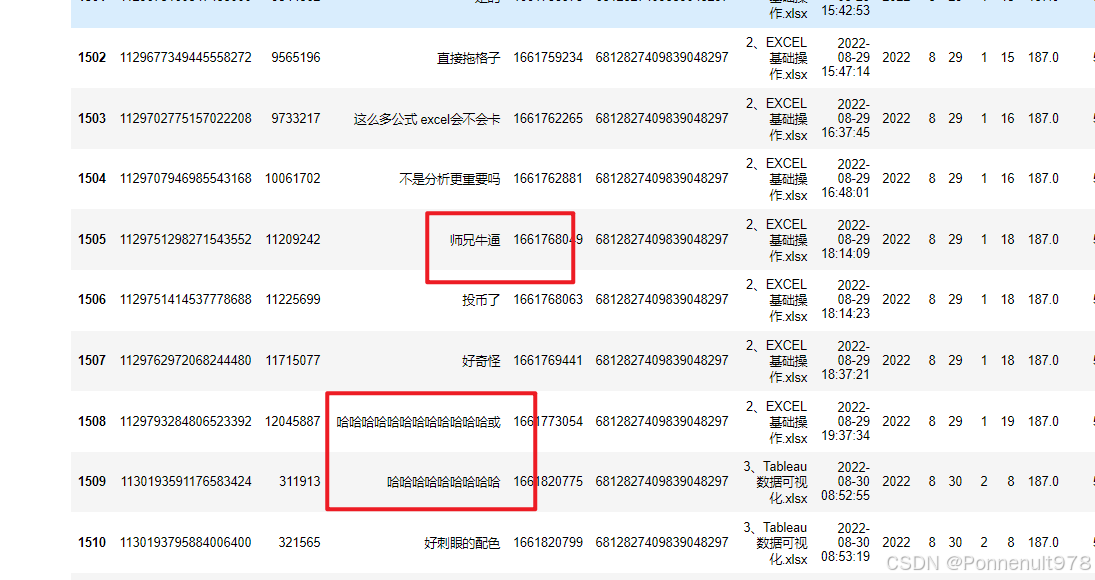
分析:老二,发了187条弹幕,具体内容可以发现老二很有礼貌、嘴很甜,发了夸奖师兄的弹幕 同时 非常的爱笑,建议收纳为《课堂氛围组组长》
- 对发弹幕数量第三多的uid的弹幕内容进行分析
danmu_level[danmu_level['uid']=='-3260951504495839240']结果如下:
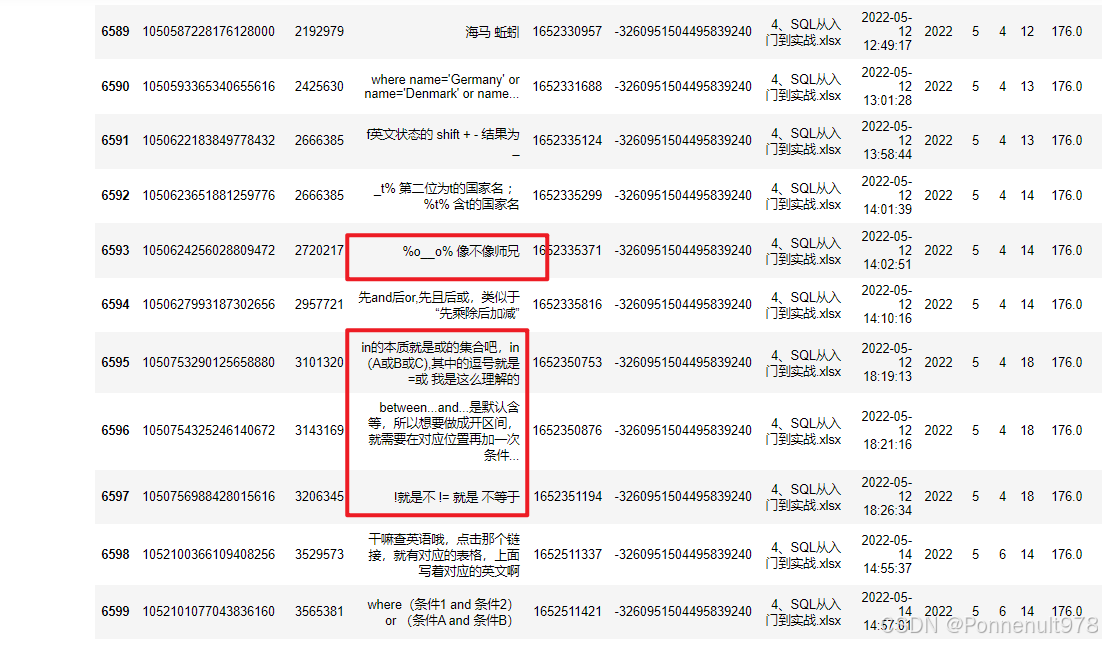
分析:老三,一共发了176条弹幕,老三是一个实操小能手,还是一个小黑子!发了一条:%o__o% 像不像师兄。
3.3.等级分布
- 根据用户等级进行分组的,并画出不同等级所发弹幕数的柱状图
danmu_level.groupby('level')[['id']].count().plot(kind='bar')结果如下:
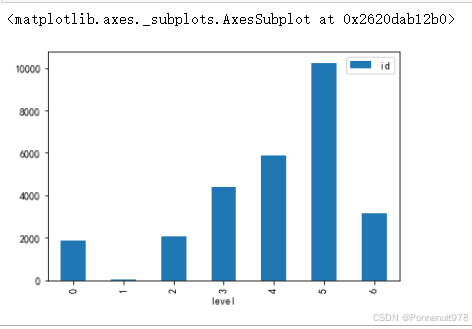
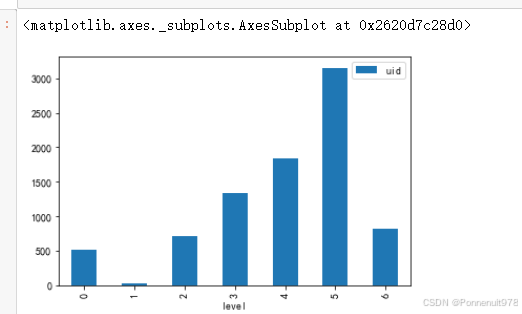
分析:大部分弹幕主要来自于4、5级用户。自学课程大部分发弹幕的观众,都是B站的粘性用户
- 根据用户等级进行分组的,分析发弹幕的不同用户uid,并画出不同等级的uid数量柱状图
danmu_level.groupby('level')[['uid']].nunique().plot(kind='bar')结果如下:
4.视频内容
4.1.视频内容处理
from time import strftime
from time import gmtime
danmu['progress'] = danmu['progress']/1000
danmu['视频进度'] = danmu['progress'].map(lambda x: strftime('%H:%M:%S', gmtime(x)))
#分析进度不用精准到秒,所以只考虑小时和分钟
danmu['视频进度【时分】'] = danmu['视频进度'].str[:5]
danmu结果如下:

知识点:
progress为进度条,单位是毫秒,得除以1000
map(lambda x : strftime('%H:%M:%S', gmtime(x))):对 progress 列的每个元素应用 lambda 函数。该函数使用 gmtime 将秒数转换为包含年、月、日、小时、分钟和秒的时间元组,然后用 strftime 将其格式化为 HH:MM:SS 字符串。这个转换过程会将原本以秒为单位的视频进度变成更易读的时间格式,例如:将进度 125 秒转换为 00:02:05。
4.2.视频内容分析
4.2.1. p1、系统认识数据分析
- 将不同视频进度的弹幕数据统计出来,降序排序
p1 = danmu[danmu['视频标题']=='1、系统认识数据分析.xlsx']
p1.groupby('视频进度【时分】')[['id']].count().sort_values('id', ascending=False)结果如下:
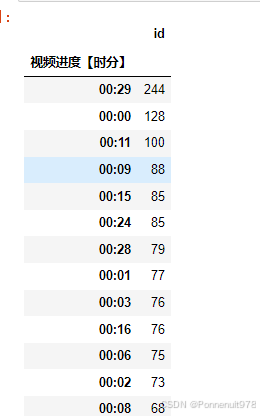
分析:去掉开头结尾,11分钟有100条弹幕,但似乎并没有什么特殊的视频内容;9分钟,是因为PPT内有提问,大家在互动
p1[p1['视频进度【时分】']=='00:11']结果如下:
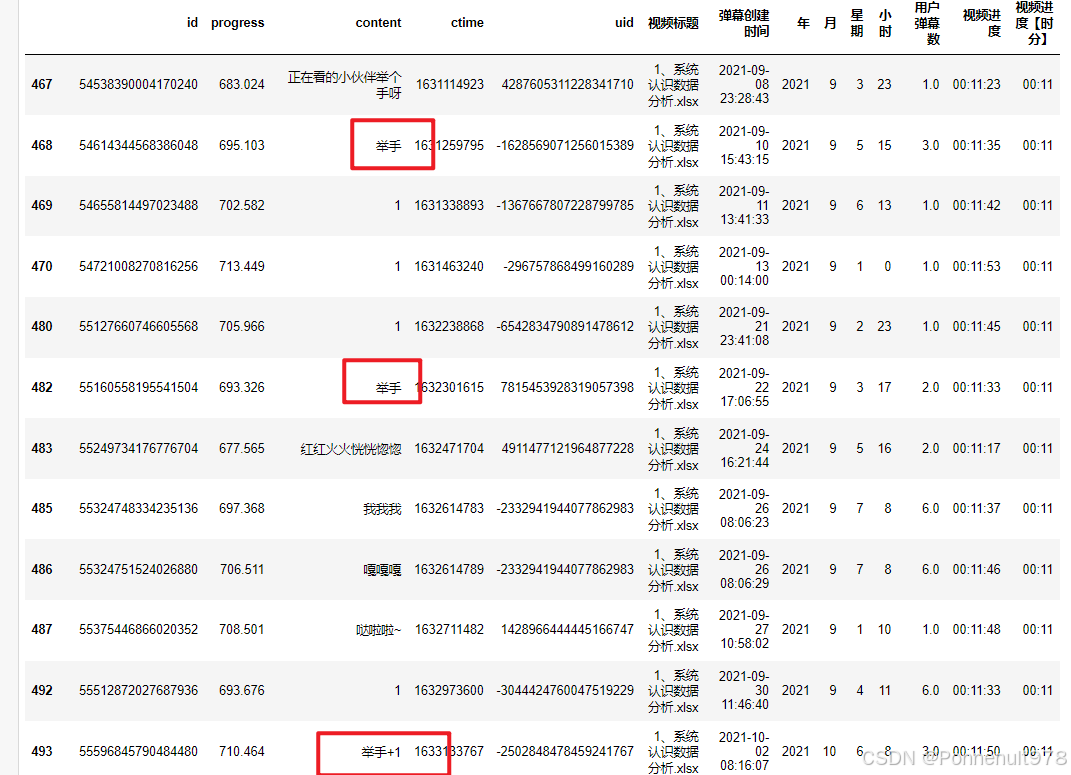
分析:出现了节奏弹幕(在看的举手),诱发了弹幕激增
4.2.2. p2、excel基础操作
p2 = danmu[danmu['视频标题']=='2、EXCEL基础操作.xlsx']
p2.groupby('视频进度【时分】')[['id']].count().sort_values('id', ascending=False)结果如下:
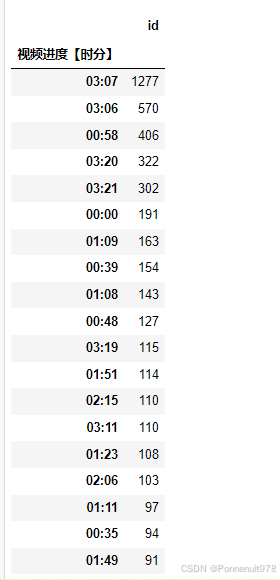
分析:在3小时06~07分,弹幕表达了对师兄excel课程的认可,满意度非常高
4.2.3. p3、tableau数据可视化
p3 = danmu[danmu['视频标题']=='3、Tableau数据可视化.xlsx']
p3.groupby('视频进度【时分】')[['id']].count().sort_values('id', ascending=False)结果如下:
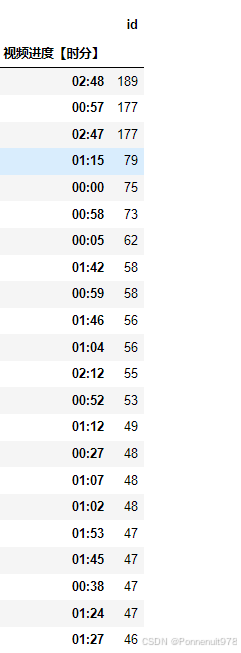
p3[p3['视频进度【时分】']=='00:57']结果如下:
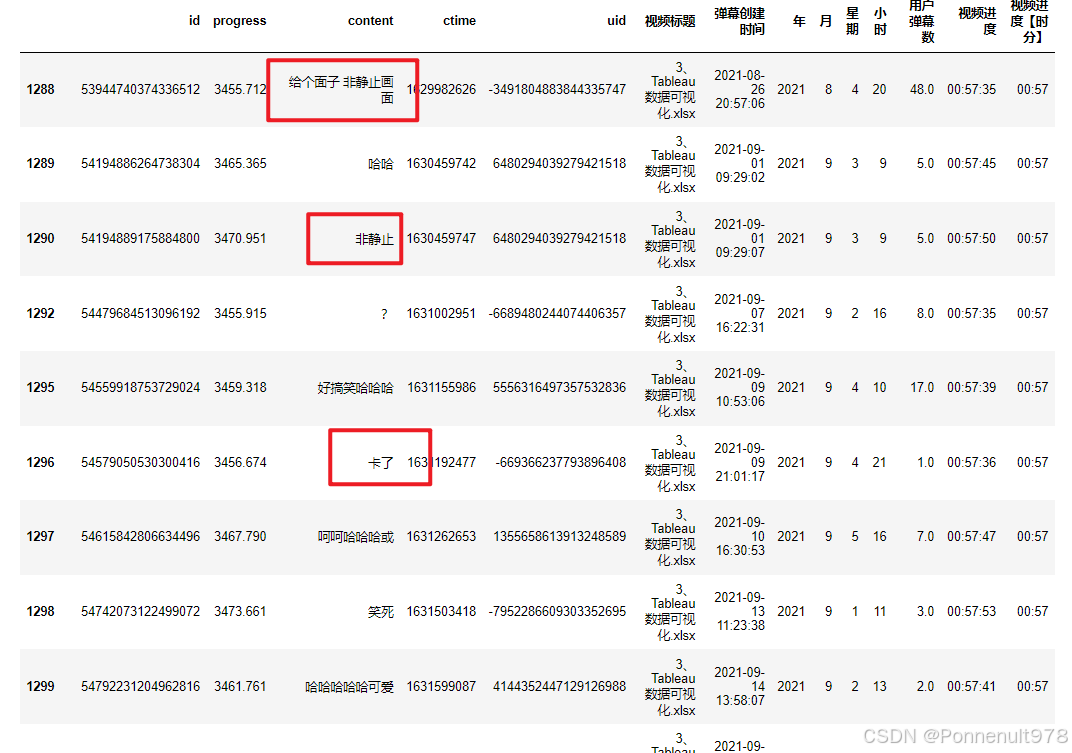
分析:57分,师兄的画面卡住了,导致弹幕的激增
4.2.4. p4、sql入门到实践
p4 = danmu[danmu['视频标题']=='4、SQL从入门到实战.xlsx']
p4.groupby('视频进度【时分】')[['id']].count().sort_values('id', ascending=False)结果如下:
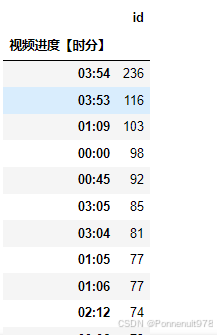
p4[p4['视频进度【时分】']=='01:09']结果如下:
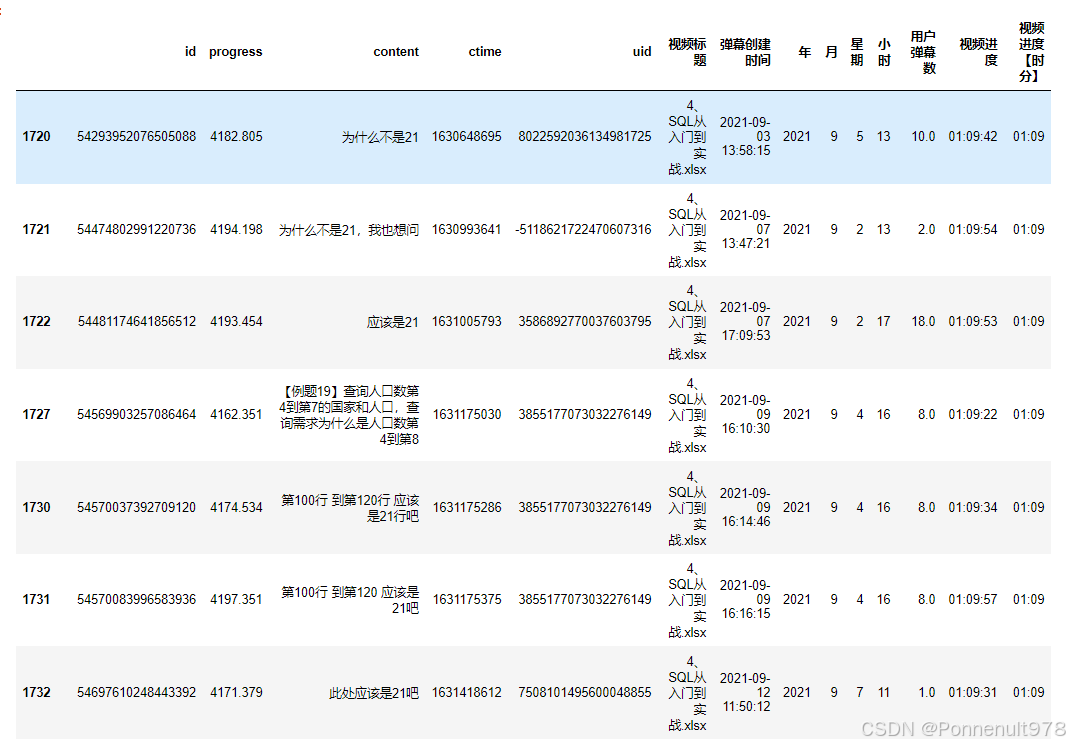
分析:1小时9分,是一个有争议的问答环节,大家各抒己见
4.2.5. p5、python
p4 = danmu[danmu['视频标题']=='5、Python.xlsx']
p4.groupby('视频进度【时分】')[['id']].count().sort_values('id', ascending=False)结果如下:
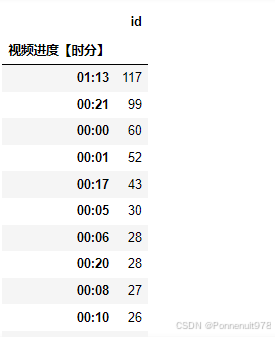
p5[p5['视频进度【时分】']=='00:21']结果如下:
分析:21分,师兄在折磨观众,导致弹幕激增
总结:
| 时序 | |
| 现象or猜想 | 1、从月份角度看,3月份参与互动的用户积极度最高,也有可能3月得到了B站大量的曝光 2、从星期维度的角度看,大家每周的状态be like:周一都在忙着开会和工作,周二、三四都在狠狠の摸鱼!周五、六在疯狂爽玩,周天逐渐找回一点学习状态 3、从小时维度来看:自学2.0,发送弹幕的人,似乎能够分为2or3类不同的人群 |
| 用户 | |
| 结论 | 自学课程2.0主要的活跃用户都是由4、5级用户组成,师兄的粉丝有可能大部分都是B站的高度用户(当然有可能DY和B站都玩) (6级大佬我就不多提了) |
| 备注 | 1、如果师兄的粉丝和观众真的大部分都是B站的高度用户,那么能否去进一步评估站外引流的空间有多大、以及可行性 2、在此畅想猜测,B站的用户等级分布 是否也呈现两头窄、中间宽的情况? |
| 内容 | |
| 结论 | 1、优质的视频内容是一定能够得到大家的认可的 2、弹幕的氛围与活跃度,可以直观的衡量教学类内容的视频节奏、以及知识的传达情况 |


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









