







在训练自己的数据集时发生的错误,运行train.py,如图所示,就是报错

应该是能够找到标签信息,也可以获取照片,但标签的类别有问题
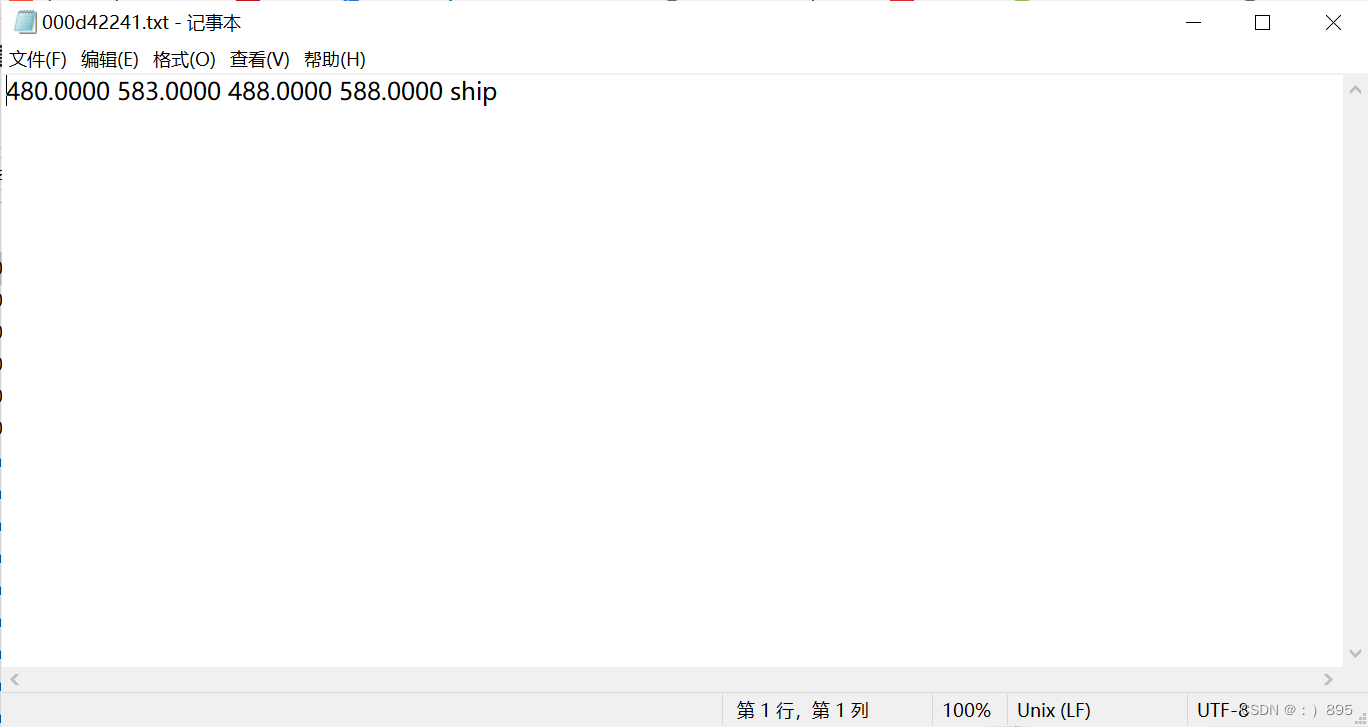
这是标签的.txt文件

这是.yaml文件的路径信息
!!!!更新
已解决
仅针对于我出现的问题
将ship类别名称转化为对应的整数,此外还要将.txt文档里的四个数据归一化处理,处理后类别整数在最前面为0,后面四个数字分别为归一化后的数字,均不超过1且大于0.


以下是归一化.txt文档数据的代码,图像高度宽度自己根据自己的实际情况修改,文件读入路径,写入路径也要自己修改,此外,最开始未被归一化的文档,我的类别id,在最后面,所以代码中class_id索引为4,索引0到4,即为要读取的x_center,y_center,width,height,经过归一化后class_id在最前面,可根据代码自身需要情况修改。
# 假设图像的宽度和高度已知
image_width = 800
image_height = 800
# 打开原始标签文件进行读取
with open('D:/www/datadata/images/train/labels/00ef28664.txt', 'r') as file:
lines = file.readlines()
# 归一化坐标并写入新文件
with open('D:/www/datadata/images/train/labels1/00ef28664.txt', 'w') as new_file:
for line in lines:
# 解析每行数据
parts = line.strip().split(' ')
class_id = parts[4] # 类别索引,直接使用字符串
x_center, y_center, width, height = list(map(float, parts[0:4])) # 浮点数坐标
# 归一化坐标
normalized_x_center = x_center / image_width
normalized_y_center = y_center / image_height
normalized_width = width / image_width
normalized_height = height / image_height
# 写入归一化后的坐标,类别索引保持为字符串
new_file.write(f"{class_id} {normalized_x_center} {normalized_y_center} {normalized_width} {normalized_height}\n")
print("Normalization completed.")小菜鸟第一次发文章好激动!!!哈哈哈哈哈















 8395
8395











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









