






摘要
如今,互联网或公共互联网络已成为一个易受攻击的地方,因为新手或粗心的用户可以使用如此多的威胁,因为臭名昭著的人使用多种类型的工具和技术以某种方式使人们受害并访问他们宝贵的个人数据,导致有时更小。然而,这些受害者在许多情况下遭受了相当大的损失,因为他们陷入了黑客攻击、破解、数据欺骗、特洛伊木马攻击、网络劫持、萨拉米香肠攻击和网络钓鱼等陷阱。因此,尽管 Web 用户以及软件和应用程序开发人员不断努力使用许多技术(包括加密、数字签名、数字证书等)来确保 IT 基础设施的安全,但本文重点关注网络钓鱼问题以检测和预测网络钓鱼网站 URL、主要机器学习分类器和新的基于集成的技术用于 2 个不同的数据集。同样在合并的数据集上,这项研究分 3 个阶段进行。首先,它们包括使用基本分类器、集成分类器进行分类,然后在有和没有交叉验证的情况下测试集成分类器。最后,分析了他们的表现,最后呈现了结果,以帮助其他人将这项研究用于他们即将到来的研究。
介绍
互联网的使用在我们的生活中激增,我们变得非常依赖在线提供的服务。从网上购物银行到智能家居解决方案,人们的工作文化也受到了影响,因此,威胁的数量也在以相当的速度增长。这些全球运营的网络平台上存在多种威胁。除了黑客攻击、破解、网络劫持、在线恐怖组织等众所周知的术语外,网络钓鱼是普遍存在的威胁之一。网络钓鱼是在线犯罪的一种方式,但不幸的是,此类攻击的受害者要么不知道这些攻击,要么没有给予足够的关注。此类攻击针对两种类型的用户,第一种是新手,这意味着他们不了解互联网的底层技术方面,而其他用户则是那些粗心大意的人,因此他们可能了解相关风险,但由于他们粗心大意,他们甚至不注意。
根据 Great horn 的 2020 年网络钓鱼攻击态势报告(2020 年网络钓鱼攻击态势 2020),大约 53% 的网络安全专业人员表示,他们在 COVID 19 大流行期间目睹了这些攻击的激增,企业每月面临约 1185 次网络钓鱼攻击。企业安全团队需要花费 1-4 天的时间来修复网络攻击。根据同一份报告,大约 30% 的网络安全专家认为网络钓鱼攻击在这场大流行期间取得了巨大的成功(2020 年网络钓鱼攻击形势 2020)。他们的研究揭示了针对全球组织的网络钓鱼电子邮件数量(2020 年网络钓鱼攻击态势 2020)。很大一部分网络钓鱼攻击会成功,并且由于在补救此类攻击上花费的时间,生产力和利润也有所下降。因此,鉴于这些事实,建议公司必须对员工进行有关网络钓鱼威胁的教育。
本文中的研究旨在为预测网络钓鱼网站提供可能的解决方案,使用最终可能对进一步研究有用的 URL 功能。本文分为 6 个部分,其中“引言”部分包含引言,“动机”部分包括动机。“文献综述”部分包括对以往研究论文和全球其他研究人员进行的研究的文献综述。“方法论”部分包括本文采用的方法论。“结果和讨论”部分包括结果和显示本研究所有结果和结果的讨论。最后,“结论和未来范围”部分包括结果。本文详细介绍了机器学习方法及其结果,并提供了有关各个算法的特征和其他细节。
赋予动机
网络钓鱼是互联网世界中最危险、最可怕的恶意行为之一。然而,当今的互联网工作场所还存在许多其他网际安全威胁。互联网被称为工作场所,因为我们越来越依赖数据、网络和相关技术。许多分析师和研究人员正在严格工作,可能与与网络钓鱼攻击研究相关的组织有关,也可能没有关联。但是,所有这些人和组织的目标都是相同的,即与网络钓鱼威胁作斗争。大多数时候,臭名昭著的网络犯罪分子所执行的活动被证明是成功的,因为缺乏一种行之有效的机制,可以在正确的时间或需要的时候为人们提供正确预测的信息。基于机器学习的研究和模型可以在开发此类工具方面发挥至关重要的作用。
网络钓鱼网站预测成为研究人员讨论的一部分。Gupta 等人的研究(Gupta 等人,2021 年)致力于网络钓鱼网站预测。BB Gupta 等人使用 9 个特征和 4 种分类器算法,即随机森林、KNN、SVM 和 Logistic 回归。
Sahingoz 等人(2019 年)的研究使用 7 种算法,即决策树、Adaboost、Kstar、KNN、随机森林、SMO 和朴素贝叶斯,使用词向量、混合和基于 NLP 的特征来预测网络钓鱼网站。
Jain和Gupta(2018a)进行的研究使用了19个特征5个分类器,即随机森林,SVM,神经网络,逻辑回归,朴素贝叶斯,使用基于URL的特征进行网络钓鱼网站预测。
Moghimi 等人(2016 年)的研究提出了一个用于检测网络钓鱼网站的浏览器附加扩展,该扩展使用基于规则的 URL 功能方法和 SVM 分类器。
所发表的研究论文研究了 12 种机器学习分类器算法,分为 2 类;集成分类器和基本分类器。所有 12 种机器学习分类器算法都使用所有 30 种特征来找到预测网络钓鱼网站的最佳预测算法。
文献综述
不同的作者进行了许多研究,许多研究人员在不同时间根据不同的方法进行了许多研究来检测和预测网络钓鱼网站。例如,一些研究人员提出了视觉特征,而一些研究人员提出了基于图像的方法,徽标也被认为是检测的基础之一,一些研究人员建议为此目的检查基于HTML的特征,而其中一些人还建议将域名列入黑名单和白名单。本文提出了一种基于URL特征的方法,可以检测和预测这些网站,就好像它们是网络钓鱼网站或非网络钓鱼网站一样。URL 数据集取自 UCI 机器学习存储库 (2020)。第二个数据集取自 Kaggle Repository(网络钓鱼网站数据集 |Kaggle 2020 年)。本节讨论了研究人员以前进行的研究以及他们对工作及其工具的详细描述。
Hong et al. (2020) 介绍了一种使用 Adaboost、Random Forest 和 SVM 使用词法特征和黑名单域执行网络钓鱼 URL 检测的方法。他们还使用了 3 个基于字符串的分类器;和深度学习分类器:1DConv、LSTM 和 1DConv + LSTM。
Orunsolu 等人(2020 年)提出了一种基于特征选择的方法,使用支持向量机和朴素贝叶斯机器学习分类器,使用 weka 工具预测网络钓鱼 URL。
Aassal 等人(2020 年)提出了对网络钓鱼检测研究的基准和评估,该模型被命名为 PhishBench。在所提出的方法中,他们使用了术语频率-逆文档频率 (TF-IDF) (Shiri 2004),这是一种著名的统计工具,它是一种术语加权方案,它使用文档中的术语频率和对数值的反向流行度值。他们的研究还集成了 2 个自动化机器学习 (AutoML) 库,即 AutoSklearn,基于树的管道优化工具 (TPOT)。
Sonowal 和 Kuppusamy (2020) 提出了他们开发的名为 PhiDMA 的模型。它是一个多过滤器模型,由五个层组成:白名单层、特征层、词法签名、字符串匹配和可访问性分数的比较层。他们还介绍了他们的算法来预测网络钓鱼网站的URL。
Abutair 等人(2019 年)引入了一种基于案例的网络钓鱼检测推理方法,并将其命名为 CBR-PDS。他们使用特征提取和 URL 黑名单以及遗传算法称重技术来预测网络钓鱼 URL。
Satapathy等人(2019)提出了基于机器学习特征分类的网络钓鱼检测模型,并使用了人工神经网络(ANN)以及朴素贝叶斯、极限学习机(ELM)。
Chin et al. (2018) 介绍了他们的方法,即使用软件定义网络 (SDN) 和全球网络创新环境 (GENI) 开发的方法 Phishlimiter、网络钓鱼检测和缓解方法,这是一个经过测试的测试平台环境。他们还测试了支持向量机 (SVM)、J48 树、朴素贝叶斯和逻辑回归算法,这些算法构成了用于网络钓鱼检测的 ANN 环境。
Jain和Gupta(2018b)提出了他们的工作,并将其命名为PHISH-SAFE,这是一种使用机器学习技术的基于特征的网络钓鱼URL检测系统。他们使用支持向量机(SVM)和朴素贝叶斯分类器训练他们的模型。
Kumar和Gupta(2018)还讨论了一种基于超链接信息来检测网络钓鱼网站URL的方法。他们使用特征选择和 CSS 以及各种机器学习分类算法,如 SMO、朴素贝叶斯、随机森林、支持向量机 (SVM)、Adaboost、神经网络、C4.5 和 WEKA 工具上的逻辑回归来预测钓鱼网站 URL。
Gupta和Singhal(2018)讨论了他们从UCI在线存储库中获取的数据集中检测网络钓鱼URL的方法,他们至少使用了5个机器学习分类器进行实验。他们使用了 Random Tree、J48、Random Forest、Naïve Bayes 和 LMT。
Abdelhamid和Abdel-jaber(2017)讨论了基于模型内容和特征的网络钓鱼检测方法。为了进行实验研究,他们使用了各种机器学习分类器,即 C4.5、OneRule、Conjunctive Rule、eDRI、RIDOR、Bayes Net、SVM 和 Boosting。
Shirazi 等人(2017 年)引入了名为 Fresh-Phish 的框架,用于自动检测网络钓鱼网站。他们对从 whoixmlsapi.com 获取的 Whois 数据进行了实验(WHOIS API 允许访问域名注册记录 |WhoisXML API 2020)包含6000个网站的数据,并实现了4个分类器Tfcontrib(2020)库,以及来自sci-kit-learn库(Varoquaux等人,2015)的2个分类器,用于比较准确性。此外,他们还使用 TensorFlow 和 TFcontrib 构建了具有内置优化的深度神经网络 (DNN),例如 Adadelta、Adagrad 和 Gradient Descent;最后,他们使用具有分层 K 折叠的支持向量机 (SVM) 进行验证和网格搜索,以预测网络钓鱼网站 URL 的网络钓鱼或非网络钓鱼性质。
Leng et al. (2019) 介绍了他们使用机器学习方法实现的基于集成的特征选择框架。他们将WEKA工具与支持向量机(SVM)、随机森林(Random Forest)、朴素贝叶斯(Naïve Bayes)等ML算法结合使用,并结合累积分布功能进行特征选择,并按上述算法进行分类。Web URL 数据取自 phishtank.com (PhishTank |加入 2020 年打击网络钓鱼的斗争)。
Srinivasa et al. (2019) 提出了一种两级过滤机制,用于检测网络钓鱼网站,首先提取域信息,然后执行特征选择。接下来,他们在每个函数上应用了哈希函数。然后,他们将数据与列入黑名单的URL进行了比较。如果找到匹配项,则将其宣布为网络钓鱼网站,如果没有,则使用机器学习分类算法应用启发式方法来实现比较。
毛 (2019) 讨论了使用页面布局功能和分类器的网络钓鱼检测模型。该数据集包含490个钓鱼网站,取自 Phishtank.com,使用4个机器学习分类器,即支持向量机(SVM)、决策树(DT)、随机森林(RFC)和AdaBoost;CSS用于页面布局,分类器的训练是在基于向量的数据上进行的。
Ali(2017)介绍了一种基于监督机器学习算法的网络钓鱼网站检测方法。本研究包括借助机器学习分类器进行包装特征选择,如反向传播神经网络(BPNN)、径向基函数网络(RBFN)、朴素贝叶斯(NB)支持向量机(SVM)、决策树(C4.5)、K最近邻(k-NN)和随机森林(RF)。利用从文献综述中获得的知识和内容信息,对本文及其实验进行了研究。
方法论
本文共进行了3个实验,其性能显示在本文的“结果与讨论”部分。
基本分类器本实验中使用的基本机器学习分类器是:首先使用逻辑回归分类器,其次使用高斯朴素贝叶斯分类器,接下来使用决策树分类器,接下来使用支持向量机分类器,然后使用K-最近邻分类器,然后使用线性判别分析分类器。这些基本分类器的流程图如下图所示。1. 流程图旁边描述了所有单独的基本分类器。
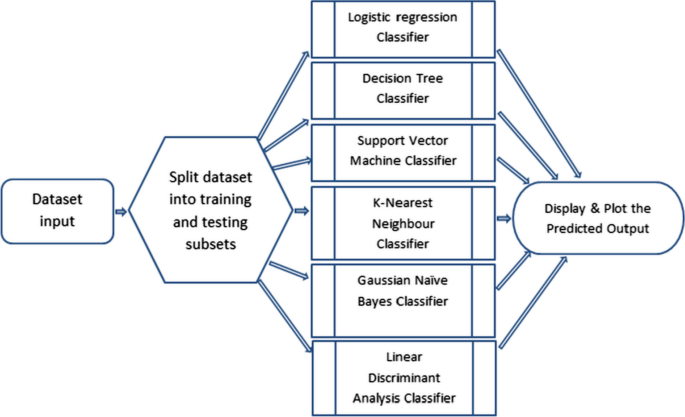
使用的基本分类器
- 1.
逻辑回归分类器
物流功能早期被命名为“物流”,皮埃尔·弗朗索瓦·韦尔斯特 (Pierre François Verhulst) 将其发展为 1830 年代至 1840 年代人口增长的模型(物流回归——维基百科 2020 年)。后来,许多研究人员致力于这种功能的发展;Cox (1966) 和 Theil (1969) 在 1966 年和 1969 年引入了称为“logit”的多项式模型。McFadden(1973)将多项式函数logit与离散选择理论联系起来,表明它来自不相关备选作为相对偏好的独立性假设。它为新的逻辑回归概念奠定了理论基础(Cramer 2005)。逻辑回归对许多应用都很有用,例如机器学习、医学、社会科学。这种技术对于工程也很有用,特别是对于预测系统或模型的成功或失败。逻辑回归的简要说明如下:
逻辑回归仅预测两个值的概率,而线性回归预测 (0–1) 范围之外的值。
逻辑回归计算公式如下:
其中 p = 逻辑模型预测概率,x = 特征或属性,b我= x 值的变化。
- 2.
决策树分类器
决策树是一种基于监督学习的预测建模工具,由悉尼大学的 Quinlan (1986) 创建并发表在他的《机器学习》一书中。该工具基于多变量分析原理工作,可以帮助预测、解释、描述和分类结果。它根据多种情况对数据集进行拆分,从而允许它描述超越一种原因的情况,并帮助我们根据多种影响来描述情况。Quinlan (1986) 创建了用于生成决策树的迭代二分法第 3 版 (ID3) 算法。然后,他扩展了基于 ID3 的研究,并创建了 C4.5,这是 ID3 的改进版本。Quinlan 正在销售一个功能丰富且改进的 C4.5 版本,Quinlan 正在销售的是 GPL 下的 C5.0。首先,按照涉及数据分区的自上而下的方法从根生成决策树。然后,使用下面给出的公式计算熵和基尼指数。
其中P我= 第 i 项的概率。C = 类标签。i = 迭代。
许多算法用于生成决策树。
- I.
Classification and regression tree (CART)
- II.
ID3
- III.
CHAID
- IV.
ID4.5
- 3.
支持向量机分类器
支持向量机(Master Machine Learning Algorithms 2020)分类器是一种用于回归和分类的监督学习有用工具。SVM 工作的核心主题是它是一种二元分类算法,它分离数据点以在许多可能的输入的情况下找到一个超平面。它可以有效地处理异常值,并且在高维空间的情况下效果很好。它使用决策函数(也称为支持向量)来执行分类。至少 4 种类型的内核用于分类:SVC 与线性核、线性 SVC、SVC 与 RBF 内核和 SVC 与多项式核。分类器算法的数学表示如下。
其中:w = 权重向量,x = 输入向量,b = 偏差。
- 4.
K-最近邻分类器
K-Nearest Neighbor (Master Machine Learning Algorithms 2020) 是最简单的分类器算法,但它在应用时可以通过分类提供合理的预测准确性。它是一种监督学习分类器,适用于分类和回归。它是非参数的,可以根据 K 值对未知对象进行分类。训练样本数是 K 的值,在算法中起着至关重要的作用,因为该值的最近邻是根据距离函数选择的。用于此目的的距离函数是 Minkowski、Manhattan、Hamming 和 Euclidian。它是一个缓慢的分类器,因为它需要加载完整的训练数据集进行分类。该算法的所有三个数学表示如下。
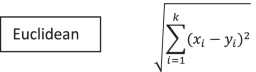
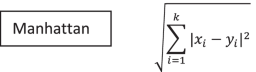
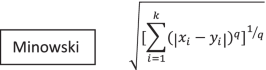
其中:x我= 属性变量,y我= 属性变量,k = 最近邻。
- 5.
高斯朴素贝叶斯分类器
高斯朴素贝叶斯 (Master Machine Learning Algorithms 2020) 是一种监督学习算法,用于基于贝叶斯定理的预测建模。理想情况下,它用于使用分箱的连续数据的情况,并且它使用最大似然法。它适用于需要二元分类和需要多类分类的情况。它使用概率方法,涉及数据集和测试数据的概率计算,以进行分类和预测。该算法的数学表示如下。
其中:P = 概率,x = 特征,c = 类。
- 6.
线性判别分析分类器
线性判别分析,也称为LDA,是一种降维算法。它是一种监督分类技术。它由 Ronald A. Fisher 于 1936 年开发,更早地命名为 Fisher 判别分析(Fletcher 和 Reeves 1954)。C. R. Rao 后来推广了一个称为多重判别分析的多类版本(Rao 2011)。所有这些都称为线性判别分析。它通常用于在对数据进行预处理时执行模式分类。其主要目标是从泛化方法中实现专业化,最终降低维度成本和资源。它通常用于图像处理和预测营销分析。它可以在数学上表示为:
其中 p = 概率,Y = 类向量,X = 特征向量,f = 线性得分函数。
基于集成的分类器
在下一阶段,将使用基于集成的机器学习分类器。首先,使用装袋分类器。其次,使用 Adaboost 分类器。接下来,使用梯度提升分类器,然后使用投票集成分类器。最后,使用了额外的树分类器,然后是 XGBoost 分类器。我们结合了十倍交叉验证,用于训练、测试模型和对数据集进行分析。这些基于集成的分类器没有交叉验证的过程图如下图所示。2.所有基于集成的单个分类器都在流程图旁边进行了描述,无论是否经过验证。
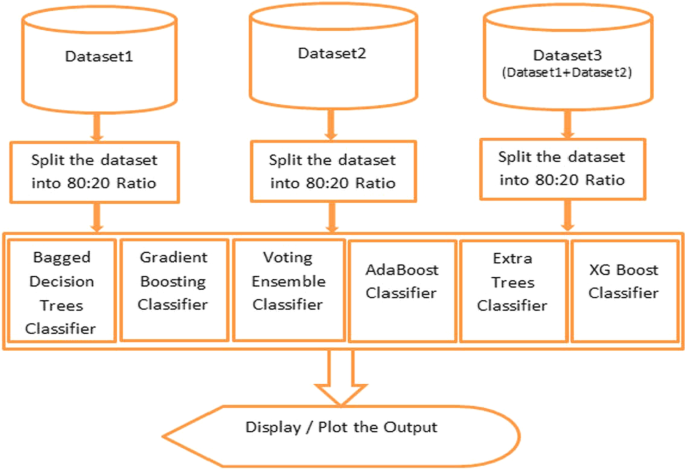
使用的集成分类器
- 1.
袋装决策树 (Bagging) 分类器
Bagging 分类器 (Kleinberg 2000) 之所以如此命名,是因为它创建了决策树的集合,并且用于分类或回归。它也被称为引导聚合。输入数据副本在每棵树中独立绘制以进行增长。为了处理回归问题,它支持均值和分位数回归。
- 2.
Adaboost 分类器
Adaboost算法(Breiman 2001)由Adaptive Boosting命名,被认为是第一个二元分类算法;使用该算法的提升功能构建了其他方法,例如梯度提升机算法。Adaboost 是使用短决策树实现的。创建第一棵树后,在每次训练实例中使用其性能,以权衡对下一棵树的关注程度,因此将最大的权重分配给包含需要更多努力进行训练和预测的数据的树,使用权重较小的树很容易预测。
- 3.
梯度提升分类器
梯度提升算法(Friedman 1997)基于用于执行回归、分类和排名的提升方法。它使用多个弱学习器的集合,这些弱学习器迭代地从弱学习器中学习,通过利用所有这些弱学习器算法中的最佳功能来构建一个强大的模型。将收集在一起的较弱分类器算法组成集成(组)以实现集成分类器算法。对收集到的弱势学习者进行修改,以做出更好的分类。
- 4.
投票集成分类器
根据所有基于集成概念的算法,这些算法涉及多个基础学习分类器算法的组合,以改进这些模型所做的预测,并进一步组合这些基础分类器模型所做的单个预测以获得最终预测,投票集成分类器算法(Koray 等人,2019 年)和堆叠不要求基分类器是同质的,它们可以混合使用不同类型的算法来执行预测,并最终组合这些分类器算法产生的结果,以充分利用它们。投票集成分类器执行两种投票:硬投票和软投票。在前一种方法中,多数票是要考虑的关键,即选择模型之间的预测频率。在后一种方法中,考虑了不同模型执行的预测的平均值。平均值取自基础模型预测的概率,构成投票分类器。
- 5.
额外的树分类器
额外的树分类器算法 (Srinivasa 2019) 扩展或修改袋装决策树分类器。在此方法中,树是根据用于训练的数据集样本创建的。额外树算法与随机森林算法非常相似,在随机森林算法中,采用最佳特征或拆分组合来拆分数据集,因为这两种算法都使用决策树的基本功能,以递归方式拆分数据集来构建树。随机数或值用于拆分数据集,以在额外树算法中构建决策树。由于随机森林分类器中使用了大量决策树,并且额外的树被视为扩展,因此有时将其称为极端随机森林。
- 6.
XGBoost 分类器
XGBoost 算法 (Ali 2017) 是一种基于决策树的梯度提升分类器算法。它涉及一组弱学习器组合在一起进行预测。它是一个顺序集合,用于改进或纠正先前模型所犯的错误,其中模型是通过对先前模型的错误分类进行更正来构建的。
集成分类器第二阶段
上面提到的分类器再次用于第二个数据集,在这个阶段,我们在使用这些分类器进行分类时也使用了十倍的交叉验证。
对合并的数据集进行分类
数据集,即包含 2056 个和 11,055 个实例的第一和第二个数据集已合并,生成的数据集包含 13,511 个实例。所有集成分类器都已应用于此合并数据集。由于数据集包含更多实例,因此需要花费更多时间进行分类,并且结果仅因一点差异而降级,这在“结果和讨论”部分中讨论。该过程的交叉验证过程图如下图所示。三、
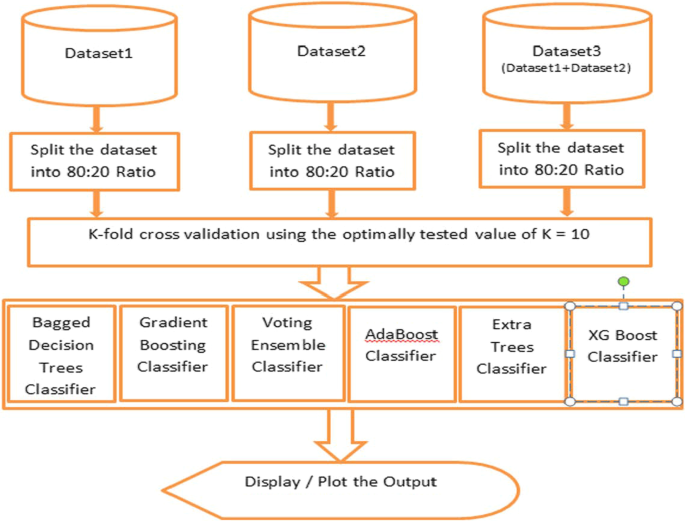
K-fold 交叉验证
这是一种可以改进保持方法的技术。它改变了我们选择数据集进行训练和测试的方式;相反,它将数据集划分为 k 个子集,并重复 Holdout 方法 k 次。K 折交叉验证的步骤如下。
- 1.
它将我们的数据集拆分为 k 个子集,称为折叠。
- 2.
对于从我们的数据集创建的每个折叠,在创建的 k-1 折叠上构建一个模型,这些折叠将测试模型,以检查模型对第 k 个折叠的有效性。
- 3.
重复此过程,直到通过使每个 k 折叠成为独立的测试集来测试它们。
- 4.
记录结果,然后取出预测精度的平均值,并作为当前正在测试或实现的模型的测试指标。
我们为每个基于集成的分类器整合了 k 折叠交叉验证。我们在实验中测试了不同的 K 值,并选择了 K = 10 的最优值。
结果与讨论
本文使用的第一个数据集是从 UCI 机器学习存储库中获得的,该存储库包含 2456 个具有 31 个不同属性的网站 URL 数据实例。第二个数据集是从 Kaggle.com 存储库中获取的,该存储库包含数据集中的 11,055 个实例和相同的 31 个属性。在这两个数据集中,30 个属性包含 URL 要素,而 31 个属性中的其余一 (1) 个属性(标记为结果)包含根据 URL 要素将 − 1 表示为(网络钓鱼网站)、oneas(非网络钓鱼网站)和 0 表示(可疑网站)的值。虽然数据集已经过预处理,但我们已经对数据进行了标准化处理,以确保在对上述数据集进行分类和预测时正确和顺利地进行处理。下表 1 给出了数据集的详细说明。
表1 dataset1和数据集2属性说明
该研究是针对所有 30 个特征进行的,考虑到所有特征都是必不可少的。该研究测试了所有属性对用于预测网络钓鱼网站的分类器性能的影响。
本文中已进行或进行的实验突出了最佳结果。使用 Extra Trees 和 XGBoost 分类器算法,在 UCI 机器学习存储库中为这些实验选择的两个数据集上实现了最佳准确率,准确率为 99.18%:网络钓鱼网站数据集(UCI 机器学习和存储库:网络钓鱼网站数据集 2020)和 Kaggle.com(网络钓鱼网站数据集 |Kaggle 2020 年)。数据集是经过预处理的规范化数据集,其中包含 30 个不同的 URL 要素,以及 1 个结果属性,其中包含从数据派生的数值,第一个数据集中有 2456 个实例,第二个数据集中有 11,055 个实例。这些值用于确定网站是网络钓鱼、非网络钓鱼还是可疑网站。
探索性数据分析 (EDA) 已使用 python 代码对第一个数据集和合并数据集进行了执行,并且由于数据集已经处于良好状态,尽管执行了数据标准化。在该过程之后,所有特征描述都通过下面的小提琴图以图形表示给出。4 和 5.
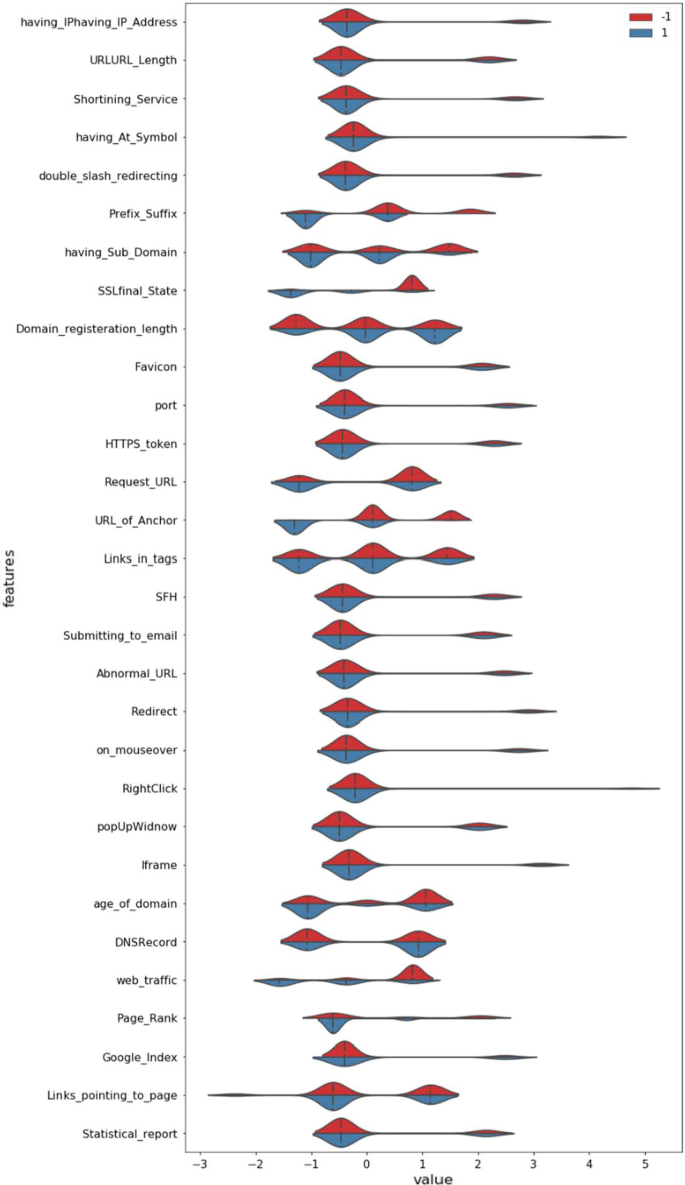
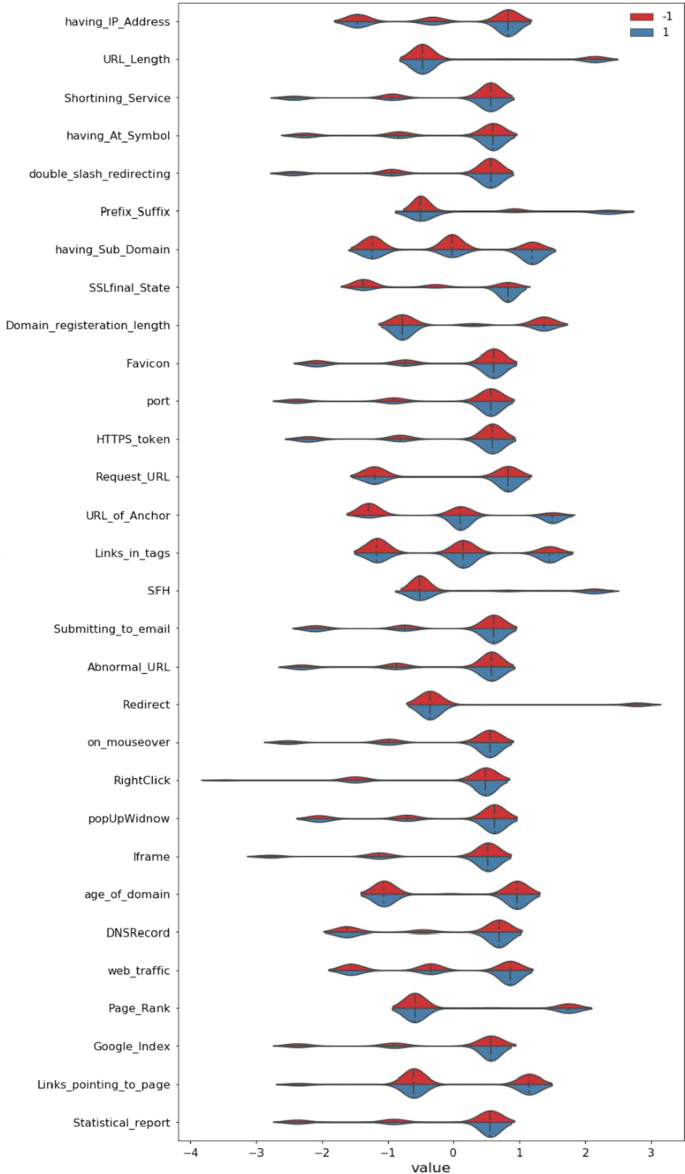
显示数据集中特征的汇总统计,如图所示。4 和 5 使用小提琴图。此小提琴图表示类的分布(具有配色方案的相应功能的网络钓鱼或非网络钓鱼)。图 4 表示数据大小为 2456 的 UCI 数据集分布,而 Fig.5 表示 UCI 和 kaggle 合并后的数据集,数据量均为 13,511。图 4 和图 5 共同解释合并文件的数据分布比 UCI 数据集更重要。整个研究是在UCI、kaggle和合并数据集上应用选定的算法进行的,以找到最合适的网络钓鱼预测算法。
本文将机器学习分类器分两个阶段使用,首先使用逻辑回归分类器,其次使用高斯朴素贝叶斯分类器,然后使用决策树分类器。之后,支持向量机分类器和 K 最近邻分类器后跟线性判别分析分类器。最后,所有这些分类器都在上面的“方法论”部分中进行了描述。
下表 2 给出了从基分类器获得的结果的详细说明:
表2 实验1:基础分类器准确分类报告
解释根据表 1 中讨论的元数据获得的数据使用多种算法进行处理。表 2 有 8 列。第一列是用于表示相应分类算法名称的分类器。第二列表示相应分类算法的混淆矩阵。第三列表示相应算法和混淆矩阵的相应行的网络钓鱼或非网络钓鱼类别。同样,在后续列中实现的精确率、召回率、f1 分数支持和准确性表示特定算法的相应值。
第一种算法是逻辑回归,它为非网络钓鱼生成精度值为 0.96,为网络钓鱼生成精度值为 0.95;非网络钓鱼的召回值为 0.96,网络钓鱼的召回值为 0.95;F1 分数值:非网络钓鱼为 0.96,网络钓鱼为 0.95;接收到的总准确率为 93.28%。
第二种算法是线性判别分析,它为非网络钓鱼生成精度值为 0.95,为网络钓鱼生成精度值为 0.94;非网络钓鱼的召回值为 0.96,网络钓鱼的召回值为 0.93;F1 分数值:0.95(非网络钓鱼);0.94(网络钓鱼);接收到的总准确率为 92.87%。
第三种算法是 K-最近邻算法,它为非网络钓鱼生成精度值 0.97,为网络钓鱼生成精度值为 0.94;非网络钓鱼的召回值为 0.95,网络钓鱼的召回值为 0.96;F1 分数值:非网络钓鱼为 0.96,网络钓鱼为 0.95;接收到的总准确率为 93.43%。
第四种算法是决策树,它为非网络钓鱼生成精度值为 0.99,为网络钓鱼生成精度值为 0.97;非网络钓鱼的召回值为 0.98,网络钓鱼的召回值为 0.99;F1 分数值:非网络钓鱼为 0.98,网络钓鱼为 0.98;接收到的总准确率为 95.92%。
第五种算法是高斯朴素贝叶斯算法,它为非网络钓鱼生成精度值为 0.96,为网络钓鱼生成精度值为 0.89;非网络钓鱼的召回值为 0.91,网络钓鱼的召回值为 0.95;F1 分数值 0.94 表示非网络钓鱼,0.92 表示网络钓鱼;接收的总准确率为 91.44%。
第六种算法是支持向量机,它为非网络钓鱼生成精度值为 0.96,为网络钓鱼生成精度值为 0.95;非网络钓鱼的召回值为 0.96,网络钓鱼的召回值为 0.95;F1 分数值:0.96(非网络钓鱼);0.95(网络钓鱼);F1 分数值:0.96(非网络钓鱼);F1 分数值:0.96(非网络钓鱼);F1 分数值:0.96(非网络钓鱼);F1 分数值:0接收到的总准确率为 94.80%。
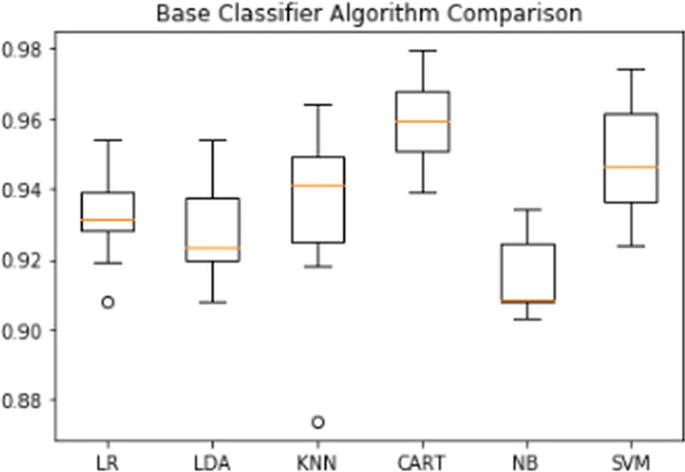
结果使用箱线图绘制,使用 python 代码清楚地显示准确度分数和异常值。例如,显示用于预测的所有基本分类器之间比较的箱线图显示在下面的箱线图中。6.
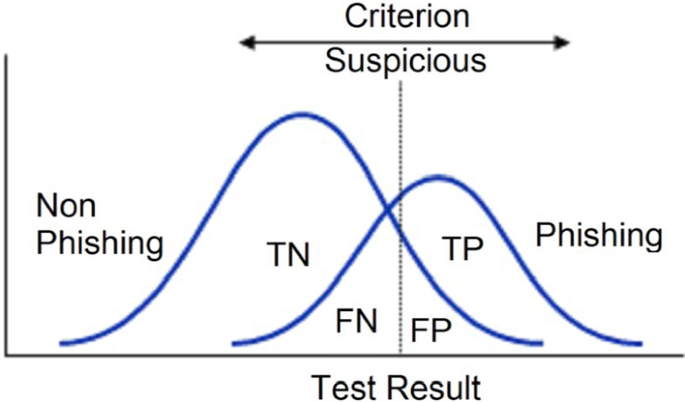
受试者工作特征 (ROC) 曲线分析
ROC曲线是用于诊断测试评估的基本工具。这是一个常用的图形,用于汇总分类器的性能总体可能阈值。它是通过将 y 轴上的真阳性率 (TPR) 与 x 轴上的假阳性率 (FPR) 进行绘制来生成的,因为给定类的观测值分配的阈值发生了变化。 ROC 曲线也可用于 2 个测试之间的比较。ROC 还可用于决策过程中的成本效益分析。它用于绘制有关特异性的不同临界点,也称为假阳性率。这些点代表了与特定决策有关的一对敏感性/特异性。非常接近左上角的 ROC 曲线表示更高的准确度和大约 100% 的灵敏度和 100% 的特异性。在两个部分之间可以观察到重叠,即,如果我们考虑本文情景中的人口,我们很少发现它们之间的完美区分,相反,我们看到它们之间存在重叠。考虑图。下文第7段供说明。
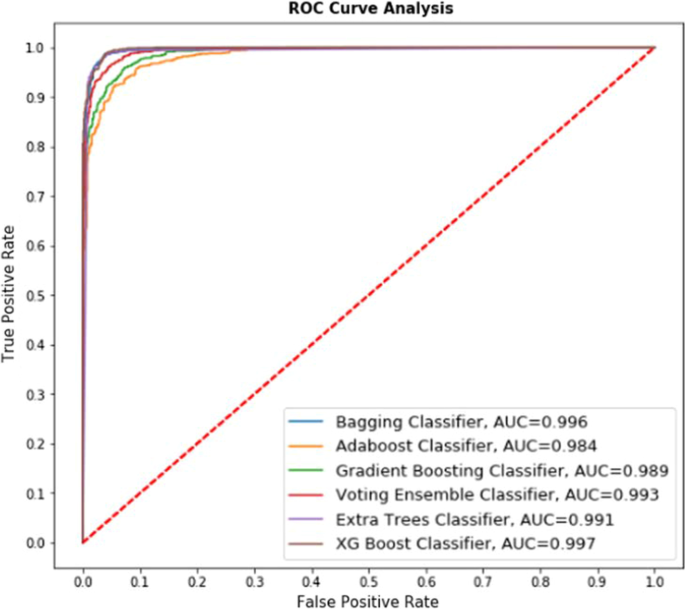
通过在上述第一、第二和第三(合并)数据集上应用所有基于集成的分类器获得的结果,已经绘制了 ROC 曲线,如图所示。下文第8、9、10和11段。
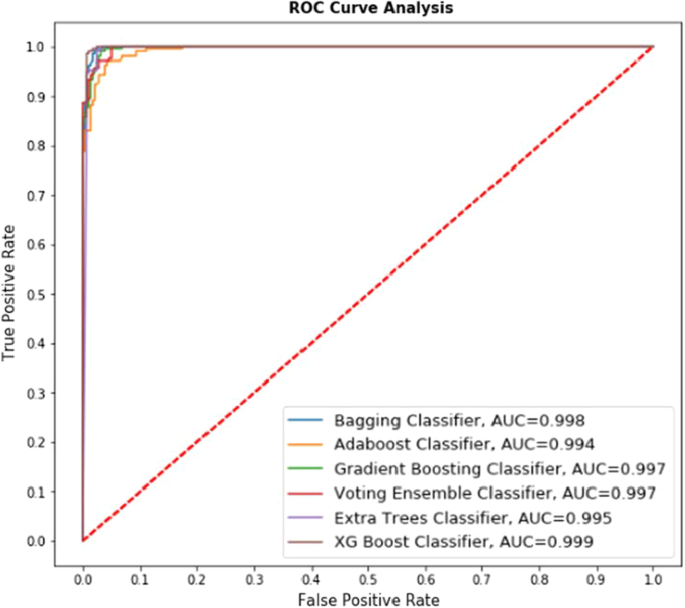
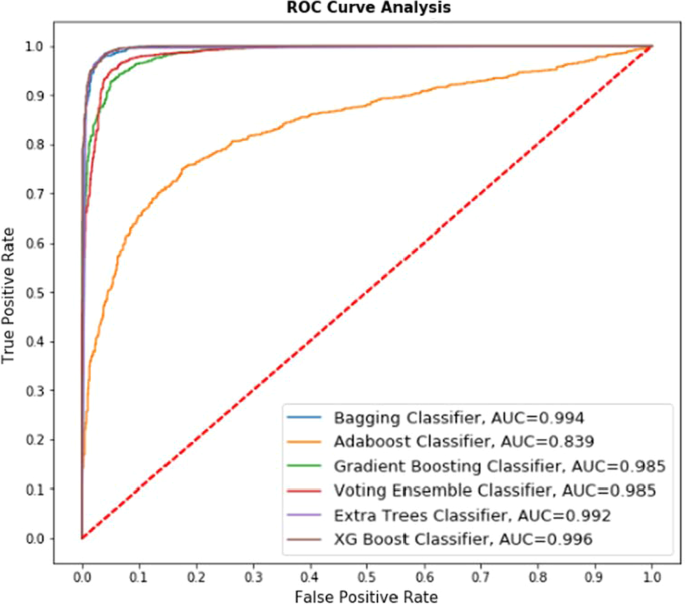

解释无花果。8 表示 6 个分类器(Bagging 分类器、Adaboost 分类器、梯度提升分类器、投票集成分类器、Extra Trees 分类器、XG Boost 分类器)在 UCI 数据集上的比较性能。图中显示了相应分类器的 AUC 值。8. 例如,在 Adaboost 分类器中接收到的最低 AUC 值为 0.994,而在 XG Boost 分类器中接收到的最高 AUC 值为 0.999,使用此算法获得的准确率为 99.18%,显示最佳真阳性率。因此,可以说预测值更接近 ROC 曲线所表示的值。
解释无花果。9 表示 6 个分类器(Bagging 分类器、Adaboost 分类器、Gradient Boosting 分类器、Voting Ensemble 分类器、Extra Trees 分类器、XG Boost 分类器)在 Kaggle 数据集上的比较性能。图中显示了相应分类器的 AUC 值。9. Adaboost 分类器接收到的最低 AUC 值为 0.984,而 XG Boost 分类器接收到的最高 AUC 值为 0.997,使用该算法获得的准确率为 98.37%,显示最佳真阳性率。无花果的比较研究。图8和图9表示随着数据集大小的增加,算法的性能下降。
解释无花果。图10表示6种分类器(Bagging Classifier、Adaboost Classifier、Gradient Boosting分类器、Voting Ensemble分类器、Extra Trees分类器、XG Boost分类器)在UCI和Kaggle合并数据集上的比较性能。图 10 表示没有交叉验证的性能。图中显示了相应分类器的 AUC 值。10. 例如,在 Adaboost 分类器中接收到的最低 AUC 值为 0.839,而在 XG Boost 分类器中接收到的最高 AUC 值为 0.996,使用该算法获得的准确率为 88.71%,显示出最佳的真阳性率。
因此,可以说,随着数据集大小的增加,ROC 曲线显示的 AUC 值有时可能无法给出最接近的估计值;因此,为了提高准确性,还可以合并和测试一些其他方法。为此,将交叉验证合并到这个合并的数据集中,并进行实验。
解释无花果。图11代表了6种分类器(Bagging Classifier、Adaboost Classifier、Gradient Boosting分类器、Voting Ensemble分类器、Extra Trees分类器、XG Boost分类器)在UCI和Kaggle合并数据集上的比较性能。图 11 表示交叉验证的性能。图中显示了相应分类器的 AUC 值。10. 例如,在 Adaboost 分类器中接收到的最低 AUC 值为 0.839,而在 XG Boost 分类器中接收到的最高 AUC 值为 0.996,使用此算法获得的准确率为 98.07%。
无花果的比较研究。图10和表11以及表6和表7显示,在使用交叉验证的情况下,所有选定算法的性能都有所提高。Extratrees 分类器获得的一个令人兴奋的结果是,尽管 AUC 值为 0.992,但准确率为 98.59%,是所有分类器中最好的。
因此,可以看出,尽管合并了两个数据集并且数据集的大小有所增加,但实验中应包含交叉验证。
混淆矩阵
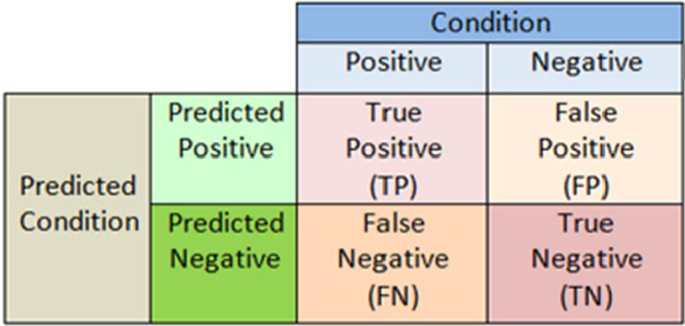
混淆矩阵是一种类似表格的结构,其中描述或评估分类器的性能。此性能描述是在已知真实值的数据集上执行的。尽管矩阵的术语可能看起来令人困惑,但混淆矩阵通常简单易懂。混淆矩阵的术语如下所述。
真阳性 (TP)在本例中,预测结果为“是”(它们是网络钓鱼 URL)。
真阴性 (TN)在本例中,预测是否定的(它们不是网络钓鱼 URL)。
误报 (FP)在这种情况下,预测是肯定的,但这是一个错误的预测,即它们不是网络钓鱼 URL(称为 I 类错误)。
假阴性 (FN)在本例中,预测是否定的,但它们是网络钓鱼 URL(称为 II 类错误)。
混淆矩阵值真阳性和真阴性是从分类器的期望(也称为预测)中获得的,真项和假项是从外部观测中获得的。混淆矩阵的形成如图所示。下文第12段。
分类报告
分类报告是使用许多组成变量参数构建的。这些参数用于显示用于计算准确度分数的参数值。例如,召回值称为命中率、真阳性率 (TPR) 或使用下表中给出的公式获得灵敏度。真阴性率(TNR),选择性也称为特异性,使用下表中给出的公式获得。阳性预测值 (PPV),也称为精确度,使用下表中给出的公式获得。F1 分数或平衡 f 分数,也称为传统 f 测量,是灵敏度和精度的谐波平均值。精度是使用下表 3 中给出的公式计算的。
表3 混淆矩阵指标公式表
Cohen's Kappa 系数指标
它是一种统计指标,可用于衡量分类器的性能以及与此分类器的性能进行比较。如果将其与以百分比表示分数的简单计算进行比较,则认为它是一种更稳健的衡量标准。它是通过放置两个被评估的评分者的协议值来计算的。数学表示如下。
式中:k = 统计系数,p0= 观察到的相对一致性,pe= 机会一致性的假设概率。
表4给出了第一个数据集上基于集成的分类器的性能图表,包括分类报告、混淆矩阵和kappa分数。
表4 实验1的准确分类报告:第一个数据集上基于集成的分类器
解释根据表 4 中讨论的元数据获得的数据使用多种算法进行处理。表 4 有 7 列。第一列是用于表示相应分类算法名称的分类器。第二列表示相应分类算法的混淆矩阵。第三列表示相应算法和混淆矩阵的相应行的网络钓鱼或非网络钓鱼类别。同样,在后续列中实现的精确率、召回率、f1 分数支持和准确性表示特定算法的相应值。
第一种算法是 Bagging Classifier,它为非网络钓鱼生成精度值 0.98,为网络钓鱼生成 0.99 的精度值;非网络钓鱼的召回值为 0.99,网络钓鱼的召回值为 0.97;F1 分数值:非网络钓鱼为 0.99,网络钓鱼为 0.98;接收到的总准确率为 98.78%。
第二种算法是 Adaboost 分类器分析,它为非网络钓鱼生成精度值为 0.97,为网络钓鱼生成精度值为 0.94;非网络钓鱼的召回值为 0.96,网络钓鱼的召回值为 0.96;F1 分数值:非网络钓鱼为 0.96,网络钓鱼为 0.95;接收到的总准确率为 95.91%。
第三种算法是梯度提升分类器,它产生的非网络钓鱼精度值为 0.97,网络钓鱼的精度值为 0.98;非网络钓鱼的召回值为 0.99,网络钓鱼的召回值为 0.96;F1 分数值:非网络钓鱼为 0.98,网络钓鱼为 0.97;接收的总准确率为 97.56%。
第四种算法是投票集成分类器,它产生的非网络钓鱼精度值为 0.97,网络钓鱼的精度值为 0.97;非网络钓鱼的召回值为 0.98,网络钓鱼的召回值为 0.96;F1 分数值:非网络钓鱼为 0.97,网络钓鱼为 0.97;接收到的总准确率为 97.15%。
第五种算法是额外树分类器,它为非网络钓鱼生成精度值为 0.97,为网络钓鱼生成精度值为 0.99;非网络钓鱼的召回值为 0.99,网络钓鱼的召回值为 0.96;F1 分数值:0.98(非网络钓鱼);0.98(网络钓鱼);F1 分数值:0.98;F1 分数值:0.98接收到的总准确率为 99.18%。
第六种算法是 XGBoost 分类器,它为非网络钓鱼生成精度值 0.97,为网络钓鱼生成 1.00 的精度值;非网络钓鱼的召回率值为 1.00,网络钓鱼的召回率为 0.97;F1 分数值:0.99(非网络钓鱼);0.98(网络钓鱼)分数值;接收到的总准确率为 99.18%。
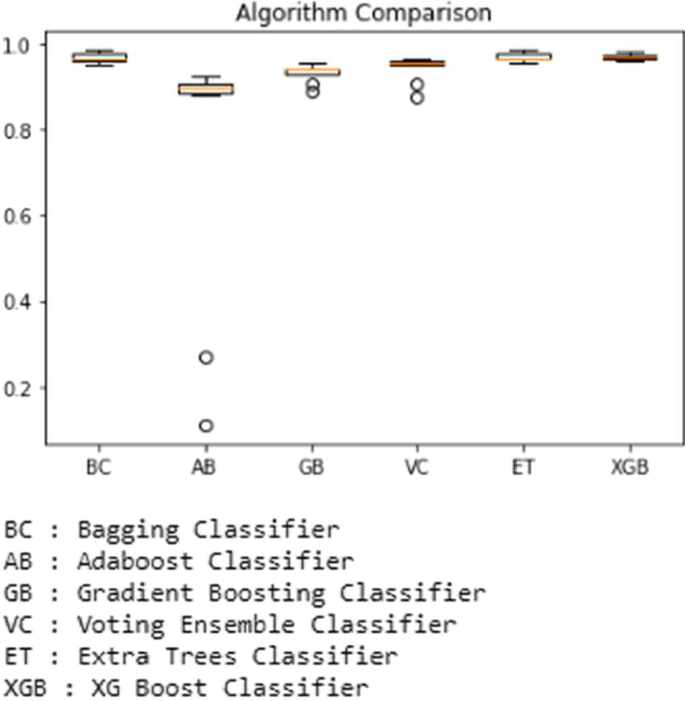
然后使用 python 代码使用箱线绘制结果,该代码清楚地显示了准确性分数和异常值。例如,显示用于预测的所有基于集成的分类器之间的比较的箱线图如图所示。下文第13段。
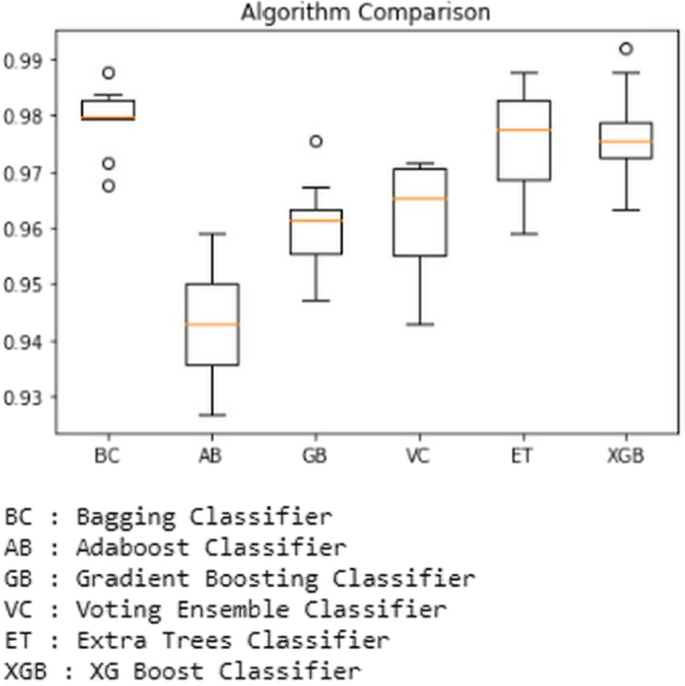
表5给出了第二个数据集上基于集成的分类器的性能图表,包括分类报告、混淆矩阵和kappa分数。
表5 实验2的准确分类报告:基于集成的分类器第二个数据集
解释根据表 5 中讨论的元数据获得的数据使用多种算法进行处理。表 5 有 7 列。第一列是用于表示相应分类算法名称的分类器。第二列表示相应分类算法的混淆矩阵。第三列表示相应算法的网络钓鱼或非网络钓鱼类别以及混淆矩阵的相应行。同样,在后续列中实现的精确率、召回率、f1 分数支持和准确性表示特定算法的相应值。
第一种算法是 Bagging Classifier,它产生的非网络钓鱼精度值为 0.97,网络钓鱼的精度值为 0.97;非网络钓鱼的召回值为 0.97,网络钓鱼的召回值为 0.97;F1 分数值:0.97(非网络钓鱼);0.97(网络钓鱼);接收到的总准确率为 98.64%。
第二种算法是 Adaboost 分类器分析,它为非网络钓鱼生成精度值为 0.91,为网络钓鱼生成 0.94 的精度值;非网络钓鱼的召回值为 0.93,网络钓鱼的召回值为 0.93;F1 分数值:非网络钓鱼为 0.92,网络钓鱼为 0.94;接收到的总准确率为 94.21%。
第三种算法是梯度提升分类器,它为非网络钓鱼生成精度值为 0.93,为网络钓鱼生成精度值为 0.96;非网络钓鱼的召回值为 0.95,网络钓鱼的召回值为 0.94;F1 分数值:非网络钓鱼为 0.94,网络钓鱼为 0.95;接收的总准确率为 96.47%。
第四种算法是投票集成分类器,它为非网络钓鱼生成精度值为 0.96,为网络钓鱼生成精度值为 0.95;非网络钓鱼的召回值为 0.94,网络钓鱼的召回值为 0.97;F1 分数值:非网络钓鱼为 0.95,网络钓鱼为 0.96;接收到的总准确率为 97.19%。
第五种算法是额外树分类器,它为非网络钓鱼生成精度值为 0.97,为网络钓鱼生成精度值为 0.98;非网络钓鱼的召回值为 0.97,网络钓鱼的召回值为 0.97;F1 分数值:0.97(非网络钓鱼);0.97(网络钓鱼);接收到的总准确率为 98.73%。
第六种算法是 XGBoost 分类器,它为非网络钓鱼生成精度值为 0.96,为网络钓鱼生成精度值为 0.99;非网络钓鱼的召回值为 0.98,网络钓鱼的召回值为 0.97;F1 分数值:0.97(非网络钓鱼);0.98(网络钓鱼);接收到的总准确率为 98.37%。
然后使用 python 代码使用箱线绘制结果,该代码清楚地显示了准确性分数和异常值。例如,显示用于预测的所有基于集成的分类器之间比较的箱线图如图所示。下文第14段。
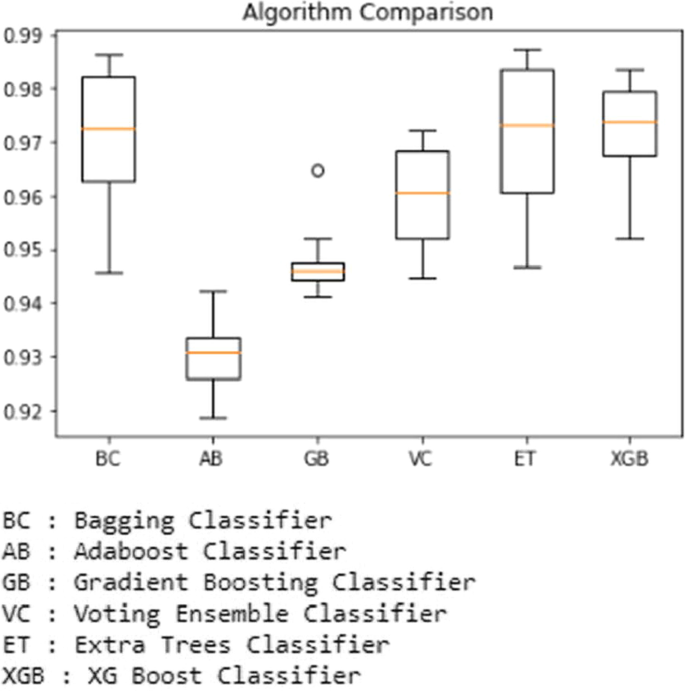
表 6 和表 7 给出了合并数据集上基于集成的分类器的性能图表,包括分类报告、混淆矩阵和 kappa 分数,无论是否经过 10 次交叉验证。
表 6 实验 3 准确度的分类报告:合并数据集上基于集成的分类器,无需交叉验证
表 7 具有实验 2 准确性的分类报告:合并数据集上基于集成的分类器与交叉验证
解释根据表 6 中讨论的元数据获得的数据使用多种算法进行处理。表 6 有 9 列。第一列是用于表示相应分类算法名称的分类器。第二列表示相应分类算法的混淆矩阵。第三列表示相应算法和混淆矩阵的相应行的网络钓鱼或非网络钓鱼类别。同样,在后续列中实现的精确率、召回率、f1 分数支持和准确性表示特定算法的相应值。
第一种算法是 Bagging Classifier,它为非网络钓鱼生成精度值为 0.96,为网络钓鱼生成精度值为 0.97;非网络钓鱼的召回值为 0.97,网络钓鱼的召回值为 0.97;F1 分数值:非网络钓鱼为 0.97,网络钓鱼为 0.97;接收到的总准确率为 89.03%。
第二种算法是 Adaboost 分类器分析,它为非网络钓鱼生成 0.71 的精度值,为网络钓鱼生成 0.81 的精度值;非网络钓鱼的召回值为 0.76,网络钓鱼的召回值为 0.76;F1 分数值:非网络钓鱼为 0.74,网络钓鱼为 0.79;接收到的总准确率为 67.41%。
第三种算法是梯度提升分类器,它为非网络钓鱼生成精度值为 0.92,为网络钓鱼生成精度值为 0.95;非网络钓鱼的召回率值为 0.94,网络钓鱼的召回率为 0.93;F1 分数值:非网络钓鱼为 0.93,网络钓鱼为 0.94;接收到的总准确率为 88.70%。
第四种算法是投票集成分类器,它为非网络钓鱼生成精度值为 0.94,为网络钓鱼生成精度值为 0.96;非网络钓鱼的召回值为 0.95,网络钓鱼的召回值为 0.95;F1 分数值:0.94(非网络钓鱼);0.95(网络钓鱼);F1 分数值:0.94;F1 分数值:0.94接收到的总准确率为 84.98%。
第五种算法是额外树分类器,它为非网络钓鱼生成精度值为 0.97,为网络钓鱼生成精度值为 0.98;非网络钓鱼的召回值为 0.97,网络钓鱼的召回值为 0.97;F1 分数值:0.97(非网络钓鱼);0.97(网络钓鱼);接收到的总准确率为 87.37%。
第六种算法是 XGBoost 分类器,它为非网络钓鱼生成精度值 0.96,为网络钓鱼生成精度值为 0.98;非网络钓鱼的召回值为 0.97,网络钓鱼的召回值为 0.97;F1 分数值:0.97(非网络钓鱼);0.97(网络钓鱼);接收到的总准确率为 88.71%。
解释根据表 7 中讨论的元数据获得的数据使用多种算法进行处理。表 7 有 9 列。第一列是用于表示相应分类算法名称的分类器。第二列表示相应分类算法的混淆矩阵。第三列表示相应算法和混淆矩阵的相应行的网络钓鱼或非网络钓鱼类别。同样,在后续列中实现的精确率、召回率、f1 分数支持和准确性表示特定算法的相应值。
第一种算法是 Bagging Classifier,它为非网络钓鱼生成精度值为 0.96,为网络钓鱼生成精度值为 0.97;非网络钓鱼的召回值为 0.97,网络钓鱼的召回值为 0.97;F1 分数值:非网络钓鱼为 0.97,网络钓鱼为 0.97;接收到的总准确率为 98.51%。
第二种算法是 Adaboost 分类器分析,它为非网络钓鱼生成 0.71 的精度值,为网络钓鱼生成 0.81 的精度值;非网络钓鱼的召回值为 0.76,网络钓鱼的召回值为 0.76;F1 分数值:非网络钓鱼为 0.74,网络钓鱼为 0.79;接收的总准确率为 92.52%。
第三种算法是梯度提升分类器,它为非网络钓鱼生成精度值为 0.92,为网络钓鱼生成精度值为 0.95;非网络钓鱼的召回率值为 0.94,网络钓鱼的召回率为 0.93;F1 分数值:非网络钓鱼为 0.93,网络钓鱼为 0.94;接收到的总准确率为 95.63%。
第四种算法是投票集成分类器,它为非网络钓鱼生成精度值为 0.94,为网络钓鱼生成精度值为 0.96;非网络钓鱼的召回值为 0.95,网络钓鱼的召回值为 0.95;F1 分数值:0.94(非网络钓鱼);0.95(网络钓鱼);F1 分数值:0.94;F1 分数值:0.94接收到的总准确率为 96.52%。
第五种算法是额外树分类器,它为非网络钓鱼生成精度值为 0.97,为网络钓鱼生成精度值为 0.98;非网络钓鱼的召回值为 0.97,网络钓鱼的召回值为 0.97;F1 分数值:0.97(非网络钓鱼);0.97(网络钓鱼);接收到的总准确率为 98.59%。
第六种算法是 XGBoost 分类器,它为非网络钓鱼生成精度值 0.96,为网络钓鱼生成精度值为 0.98;非网络钓鱼的召回值为 0.97,网络钓鱼的召回值为 0.97;F1 分数值:0.97(非网络钓鱼);0.97(网络钓鱼);接收到的总准确率为 98.07%。
然后,使用 python 代码使用箱线图绘制合并的数据集结果,用于显示准确度分数和异常值的 k 折叠交叉验证。例如,比较用于预测的所有基于集成的分类器的箱线图如图所示。下文第15和16段。
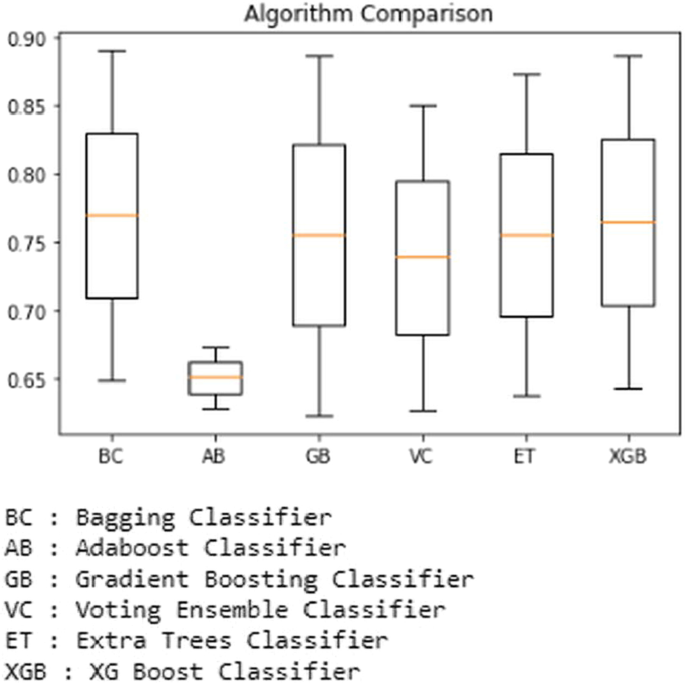
在本实验中,机器学习分类器是使用 python 代码实现的。首先,已经使用了基分类器,结果是;首先,使用逻辑回归分类器,其准确率为93.28%,其次,高斯朴素贝叶斯分类器给出的准确率为91.44%,然后使用决策树分类器。它预测的准确率为 95.87%,而支持向量机分类器的预测准确率为 94.80%。然后,以 93.43% 的准确率预测了 K 最近邻分类器。最后,线性判别分析分类器产生了 92.87% 的准确率。
在下一步中,我们试验了第一个数据集。首先,使用装袋分级机,其准确率为98.78%。其次,使用 Adaboost 分类器。它的准确率为95.91%。接下来,使用梯度提升分类器,它预测的准确率为 97.56%,而投票集成分类器的预测准确率为 97.15%。额外树分类器的预测准确率为 99.18%。XGBoost 分类器的准确率为 99.18%。在下一步中,我们试验了第二个数据集。首先,使用装袋分级机,其准确率为98.64%。其次,使用 Adaboost 分类器。它的准确率为94.21%。接下来,使用梯度提升分类器,它预测的准确率为 96.47%,而投票集成分类器的预测准确率为 97.19%。最后,对额外树分类器的预测准确率为 98.73%。XGBoost 分类器的准确率为 98.37%。
下一步,我们在合并的数据集上进行了实验;首先,使用装袋分类器,其准确率为 98.51%。其次,使用Adaboost分类器;它的准确率为92.52%。接下来,使用梯度提升分类器,它预测的准确率为 95.63%,而投票集成分类器的预测准确率为 96.52%。接下来,对额外树分类器进行了预测,准确率为 98.59%。最后,XGBoost 分类器产生了 98.07% 的准确率。
在这项研究中,对从基于集成的分类器中获得的有和没有十倍交叉验证的结果进行了比较,结果清楚地表明,集成分类器在执行分类时使用交叉验证时表现更好。与交叉验证方法一样,在使用 python 使用标准训练测试拆分时,数据集被拆分为与选择的折叠数量一样多的部分,而不是常规拆分为 2 个部分。从这项实验研究中证明,基于集成的分类技术优于基本分类器。我们在执行此实验时更改了数据集,其中观察到,当最初将实例数从 2456 个减少到 11,055 个时,结果大约下降了 0.2% 到 1.2%。但是,当我们合并两个数据集时,尽管在生成的数据集中具有相同的属性,并且实例总数增加到 13,511,但当未应用交叉验证时,结果会受到显着影响。在 Adaboost 分类器中观察到的最大降解约为 25%,在梯度提升分类器中观察到的最小降解约为 6.9%。Extra Trees 和 XGBoost 分类器提供了最准确的预测输出;两者都预测第一个数据集的输出得分为 99.18%,第二个数据集的输出得分为 98.73、98.37% 和 98.07、98.59%,两者都使用交叉验证。
在使用不同的数据集并合并两个数据集后,随后显着增加了实例数量,集成分类器的预测准确性并没有降低,并且发现远远领先于基础分类器,因为朴素贝叶斯分类器预测的最低准确率得分在基础分类器中为 91.44%,而基于集成的分类器预测的最低分数是 AdaBoost 分类器预测的 95.91%。在所有使用的基本分类器中,决策树分类器预测的最大准确率得分为 95.92,而额外树和 XGBoost 分类器预测的最大准确率得分为 99.18%。但是,当对第三个数据集(即合并数据集)进行分类时,XGBoost 分类器预测了 88.71% 的无 k 折交叉验证的最佳准确率,而通过交叉验证,ExtraTrees 分类器预测的最佳准确率为 98.59%。因此,尽管数据集更大,但 ExtraTrees 算法在交叉验证中表现最好。
结论和未来范围
在本文中,进行了一项研究,以解决一个非常重要的网络安全相关方面,这是组织中几乎每个级别都面临的重要问题。这不再局限于 IT 公司或此类组织,它们以某种方式使用网络/网络技术来运营其业务。这是整个社会关注的问题,因为如果有人成为这种攻击的牺牲品,对他们所有人来说都是同样危险或有害的。网络钓鱼可能是最古老的基于计算机的犯罪,一直是全球黑客和网络犯罪分子的最佳选择。在这项研究中,我们进行了三个实验,在机器学习算法的帮助下,使用网站 URL 特征分 2 个阶段检测和预测网络钓鱼网站 URL。我们在这项研究中使用了两个数据集。第一个取自 UCI 在线机器学习存储库,该存储库具有 2456 个 URL 数据,具有 30 个不同的特征。第二个取自 kaggle.com 存储库,拥有 11,055 个 URL 数据和 30 个特征。在实验的第一阶段,我们使用基本分类器测试了准确性,后来,我们还使用第一个和第二个数据集使用基于集成的机器学习分类器测试了预测。在此之后,在第二个实验中,我们在前面提到的两个合并数据集上进行了测试。在第三个实验中,我们应用了所有有和没有 k 折交叉验证的集成算法,结果显示在“结果和讨论”部分。这项研究取得的结果非常好,与以前的文献相比,我们发现它们的表现更好。此外,我们已经进行了测试,无论是否执行交叉验证,因此它提出了这样一种想法,即执行 k 折交叉验证比没有交叉验证的预测更好。
由于该领域的研究还处于初始阶段,因此我们已将所有 30 个特征纳入评估范围。然而,在未来的研究中,与其他降维方法相比,通过选择各种分类器中的贡献特征来减少特征。
数据和材料的可用性
该数据集可在 UCI 和 Kaggle 机器学习存储库中免费使用。

















 1752
1752

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









