






在eclipse进行MapReduce单词计数。
目录
一、登陆开启
2.在Hadoop01查看运行MapReducer_jar包
前言
需要配置好jdk环境,准备好eclipse,虚拟机,hadooop集群,Xshell,xtfp传输软件
(不同的版本的jdk,hadoop,eclipse环境不同,可能对实验结果有影响,之前用的jdk11.0.13就不能正常运行)
一、登录开启
1.登陆集群,虚拟机已提前挂好
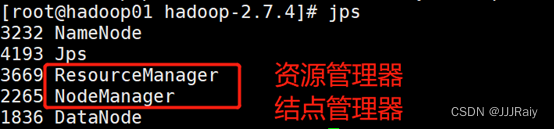
2.启动hdfs,yarn组件,并用jps命令条查看所有节点,是否已经开启
启动hdfs,yarn命令条为:
start-dfs.sh
start-yarn.sh3.使用jps查看hdfs组件
hadoop01节点组件:
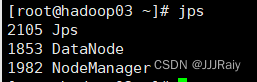
hadoop02和Hadoop03节点组件:

4.上传文件到hdfs,上传前需验证是否有上传的文件
使用以下命令条查看
Hadoop fs -ls /
上传命令条
hadoop fs -put /<路径,名称>/
查看命令条
Hadoop fs -cat /<名称>![]()

二、启动eclipse,编写MapReduce程序
1.创建java工程后,导入库
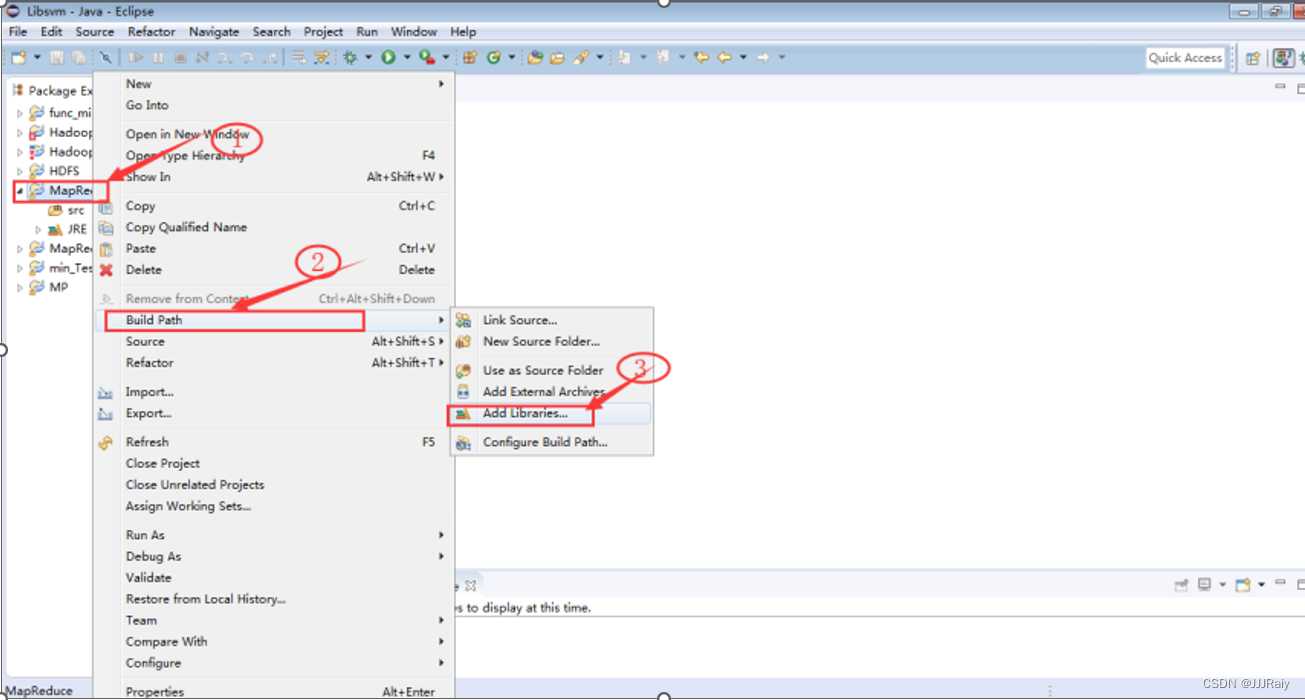
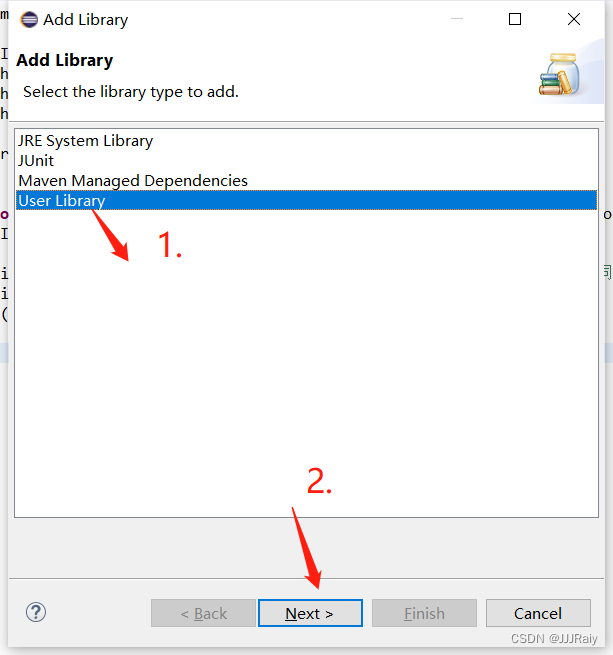


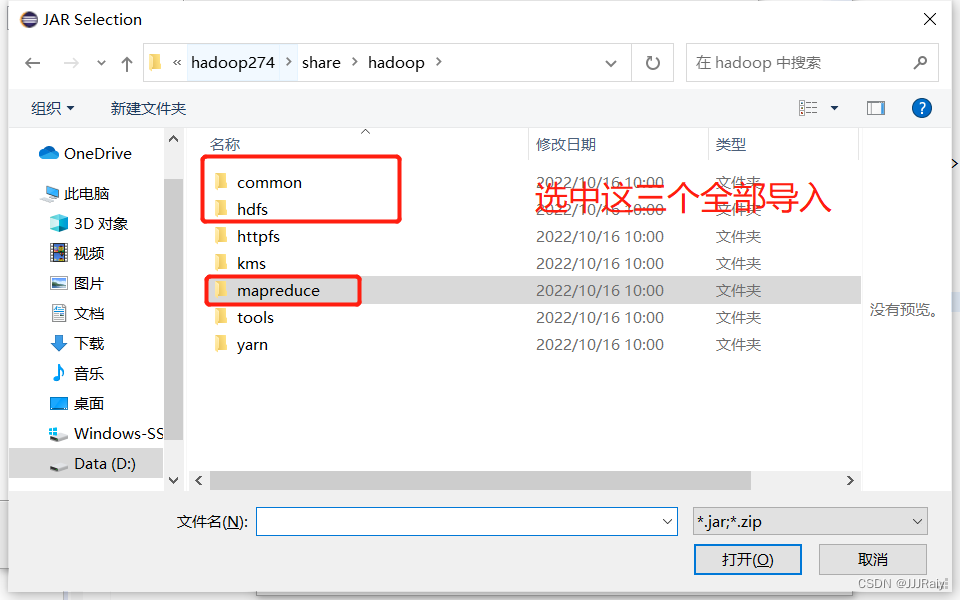 分三次导入库
分三次导入库
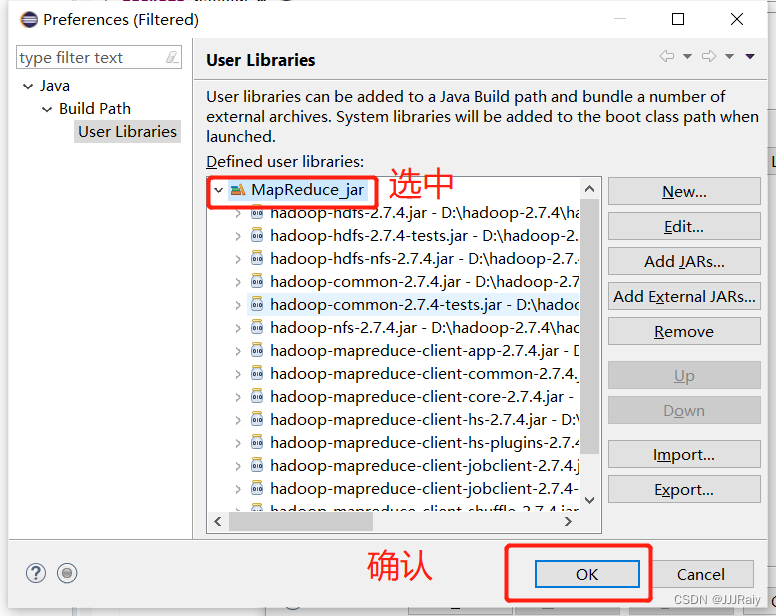

导入成功
2.新建Mapper类
代码如下(示例):
package hadoop.mapreduce.word; import java.io.IOException; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; public class wordMapper extends Mapper<LongWritable,Text,Text,LongWritable> { @Override protected void map(LongWritable key,Text value,Mapper<LongWritable,Text,Text,LongWritable>.Context context) throws IOException,InterruptedException { String line=value.toString(); //读取一行数据,转换为字符串,获取单词数组 String[] words=line.split(""); //以空格,切分字符串 for(String word:words) //记录单词频率 { context.write(new Text(word),new LongWritable(1)); //输出 } } }3.新建Reducer类package hadoop.mapreduce.word; import java.io.IOException; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; public class wordReducer extends Reducer<Text,LongWritable,Text,LongWritable> { @Override protected void reduce(Text key,Iterable<LongWritable> value,Context context) throws IOException,InterruptedException { int count=0; //初始化变量 for(LongWritable values:value) //定长格式,汇总单词个数 { count=(int)(count+values.get()); } context.write(key,new LongWritable(count)); //输出 } }4.新建驱动类package hadoop.mapreduce.word; import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class wordDriver { public static void main(String[] args)throws IOException,ClassNotFoundException,InterruptedException { Configuration conf=new Configuration(); //创建配置对象 Job wcjob=Job.getInstance(conf); //获取conf的作业job wcjob.setJarByClass(wordDriver.class); //设置运行的主类 wcjob.setMapperClass(wordMapper.class); //设置运行的mapper类 wcjob.setReducerClass(wordReducer.class); //设置运行的reducer类 wcjob.setMapOutputKeyClass(Text.class); wcjob.setMapOutputValueClass(LongWritable.class); //设置运行的mapper类输出的key-value数据类型 wcjob.setOutputKeyClass(Text.class); wcjob.setOutputValueClass(LongWritable.class); //指定作业job的输入和输出类型 FileInputFormat.setInputPaths(wcjob,"/word"); FileOutputFormat.setOutputPath(wcjob,new Path("/output")); //指定作业job,提交和返回时成功的标志 boolean res=wcjob.waitForCompletion(true); System.out.println(res?0:1); } }
5.打包工程,使用xtfp,win等工具上传至虚拟机


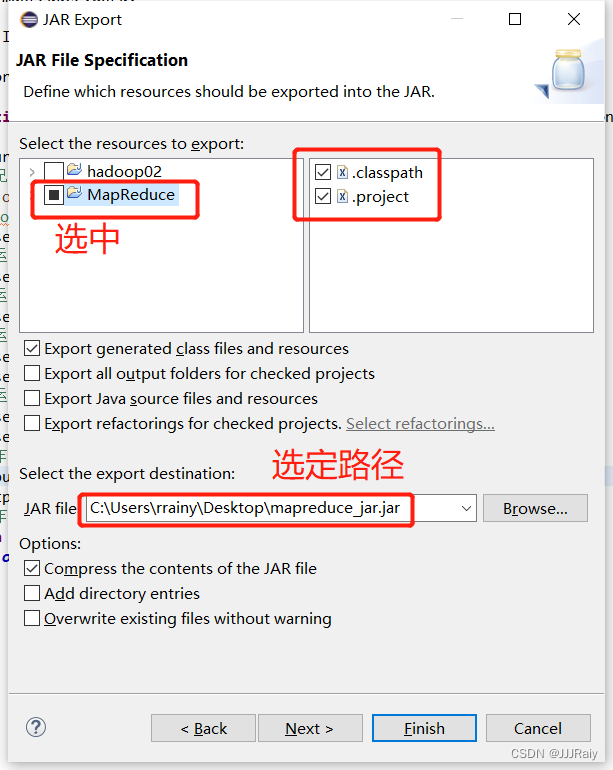
后续一直点next,直到选择类

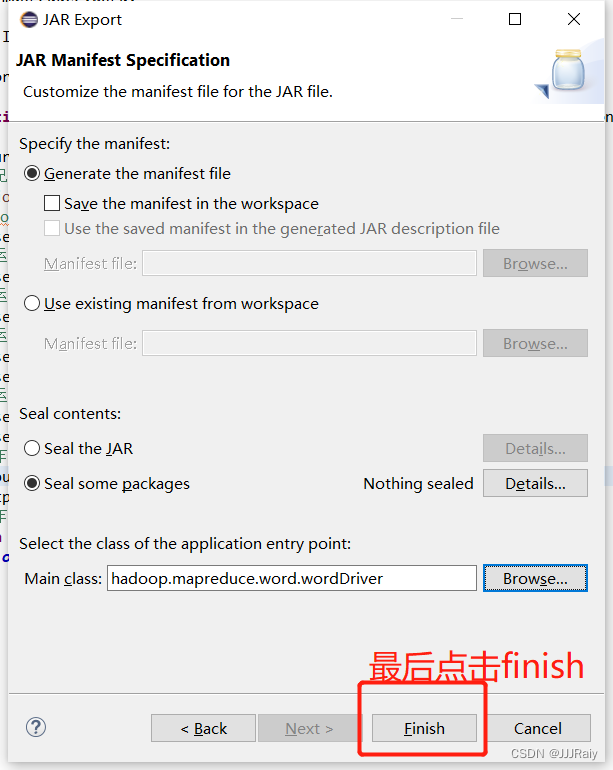
6.使用xtfp上传至虚拟机,直接拖动即可,登录xtfp和连接xshell步骤一样,使用ip地址,输入密码,用户名
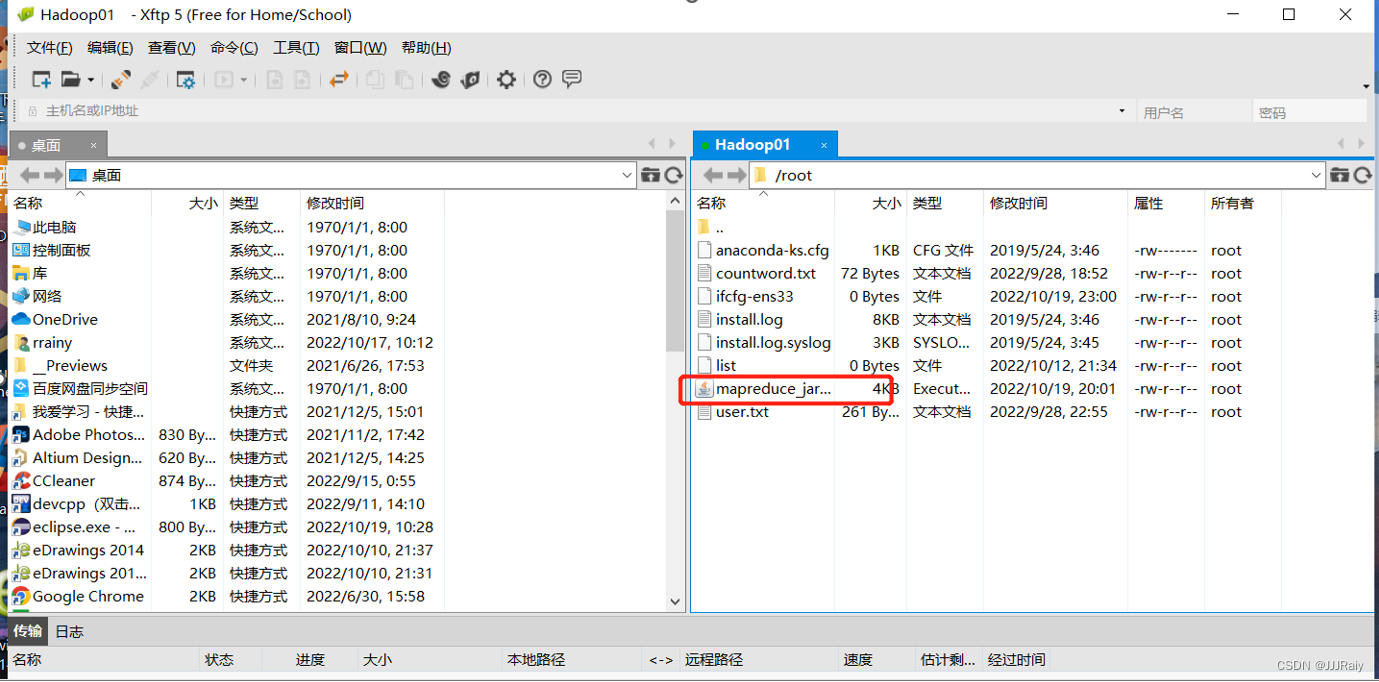
2.在Hadoop01查看运行MapReducer_jar包
1.查看

2.运行jar包

3.运行成功(不一定都是这个界面)

4.查看运行成果

总结
1.导入库时,由于eclipse不能将三个文件夹内容一起导入,要分三次导入文件夹内容
2.不要随意移动库路径
3.可以登入50070查看
是否成功















 580
580











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









