






str1 = '''<tbody>
<tr><td><span><span class="c-index c-index-hot1 c-gap-icon-right-small">1</span>张婷婷</span></td><td class="opr-toplist-right">92<i class="opr-toplist-st c-icon c-icon-down"></i></td></tr>
<tr><td><span><span class="c-index c-index-hot2 c-gap-icon-right-small">2</span>王华</span></td><td class="opr-toplist-right">91<i class="opr-toplist-st c-icon c-icon-down"></i></td></tr>
<tr><td><span><span class="c-index c-index-hot3 c-gap-icon-right-small">3</span>张岚</span></td><td class="opr-toplist-right">90<i class="opr-toplist-st c-icon c-icon-down"></i></td></tr>
<tr><td><span><span class="c-index c-gap-icon-right-small">4</span>孙鸿峰</span></td><td class="opr-toplist-right">90<i class="opr-toplist-st c-icon c-icon-down"></i></td></tr>
<tr><td><span><span class="c-index c-gap-icon-right-small">5</span>周海栋</span></td><td class="opr-toplist-right">89<i class="opr-toplist-st c-icon c-icon-down"></i></td></tr>
<tr><td><span><span class="c-index c-gap-icon-right-small">6</span>武静</span></td><td class="opr-toplist-right">88<i class="opr-toplist-st c-icon c-icon-down"></i></td></tr>
</tbody>'''
startpos = 0
number = str1.count('<tr><td>') # 计算信息中的总人数,便于确定需要循环的次数
for i in range(number): # 开始循环查找、分割
pos1 = str1.find('</span>', startpos) # 找到每行的第一个'</span>'的位置
num = str1[pos1 - 1:pos1] # 分割获得学生序号
pos2 = str1.find('</span>', pos1 + len('</span>')) # 找到每行的第二个'</span>'的位置
name = str1[pos1 + len('</span>'):pos2] # 分割获得学生姓名
substr1 = '<td class="opr-toplist-right">'
substr2 = '<i class="opr-toplist-st c-icon c-icon-down">'
pos3 = str1.find(substr1, startpos) # 获得每行字符串'<td class="opr-toplist-right">'的位置
pos4 = str1.find(substr2, startpos) # 获得每行字符串'<i class="opr-toplist-st c-icon c-icon-down">'的位置
grade = str1[pos3 + len(substr1):pos4] # 分割获得学生成绩
startpos = (pos4 + len(substr2)) # 确定下一次查找定位的开始位置
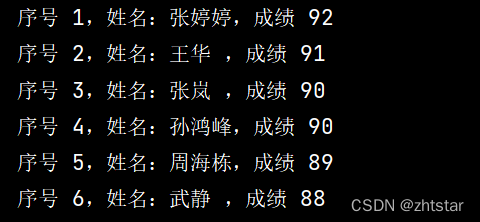
print('序号%2s,姓名:%-3s,成绩%3s' % (num, name, grade)) # 输出分割所得学生的信息
运行结果截图:

















 1898
1898

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









