




一、读流程解析
在 Hadoop 分布式文件系统(HDFS)中,读取数据的过程涉及多个组件的协同工作,包括客户端、NameNode 和 DataNode。为了确保数据的高可用性和容错性,HDFS 采用了分布式存储和副本机制。
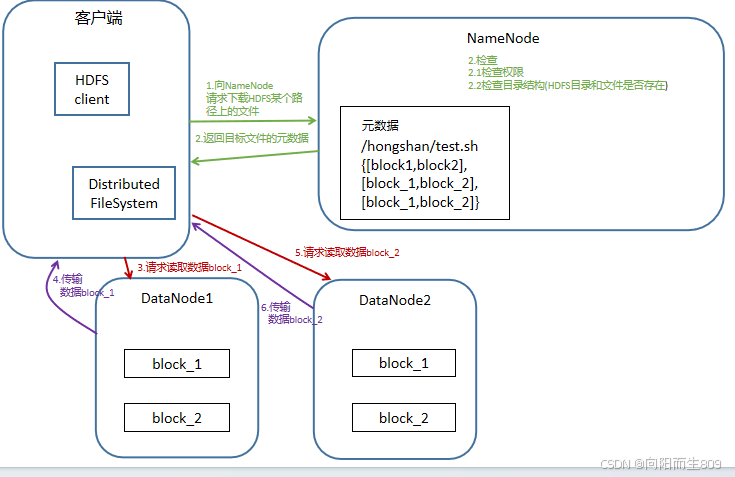
1、客户端发起读请求
客户端向NameData发送请求,告知要读取某个文件。
示例:
客户端调用 hdfs dfs -cat /user/hadoop/example.txt,请求读取 HDFS 中的 example.txt 文件。
客户端向 NameNode 发送读请求,包含文件路径 /user/hadoop/example.txt。
2、NameNode返回文件元数据
NameNode返回文件元数据,并告知客户端从哪些DataNode中读取数据。
示例:
•NameNode 检查文件 example.txt 是否存在,并返回文件的元数据,包括:
•Block 1 (blk_123456789) 存储在:
•DataNode 1 (192.168.1.10)•DataNode 2 (192.168.1.11)•DataNode 3 (192.168.1.12)
•Block 2 (blk_123456790) 存储在:
•DataNode 2 (192.168.1.11)•DataNode 3 (192.168.1.12)•DataNode 4 (192.168.1.13)
3、客户端直接与DataNode通信
客户端根据返回的NameNode返回的DataNode列表,直接和DataNode通信,读取数据块。
示例:
假设客户端在同一机架内的 DataNode 1 (192.168.1.10) 上
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4121
4121

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









