







刚刚接触Hadoop,对于里面的HDFS感觉思想就是分而治之再综合的过程,不过这个分布式文件系统还是蛮厉害的。现在介绍一下它的基本原理,通俗易懂。
一、HDFS的一些基本概念:
数据块(block):大文件会被分割成多个block进行存储,block大小默认为64MB。每一个block会在多个datanode上存储多份副本,默认是3份。
namenode:namenode负责管理文件目录、文件和block的对应关系以及block和datanode的对应关系。
datanode:datanode就负责存储了,当然大部分容错机制都是在datanode上实现的。
二、HDFS基本架构图
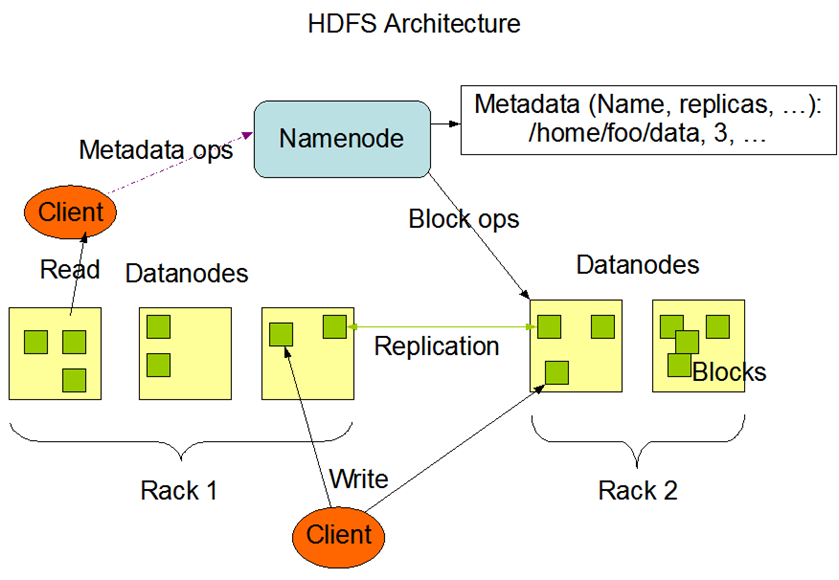
Rack 是指机柜的意思,一个block的三个副本通常会保存到两个或者两个以上的机柜中(当然是机柜中的服务器),这样做的目的是做防灾容错,因为发生一个机柜掉电或者一个机柜的交换机挂了的概率还是蛮高的]
三、HDFS读取文件操作:
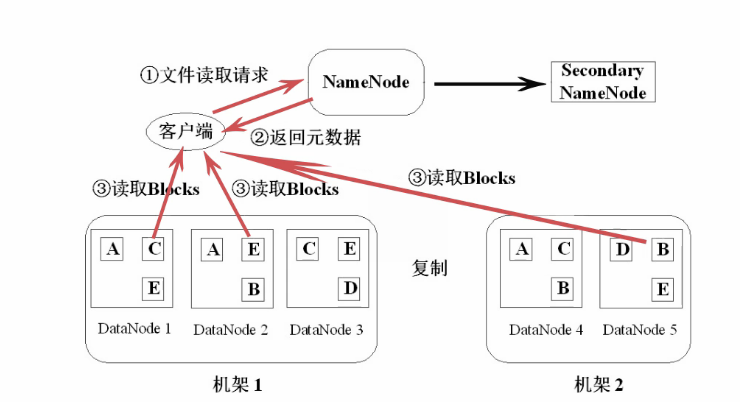
客户端发起读文件请求,向NameNode发送请求(当然还有第二个NameNode),由于NameNode存放着DataNode的信息,比如说数据块的存放信息等,所以NameNode会向客户端返回元数据,这些元数据包含了数据块的信息等。客户端得到元数据后直接去读取数据块,实现了文件的读取。
四、HDFS写文件操作:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 348
348

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









