







一、基本操作
Spark SQL提供了两个常用的加载数据和写入数据的方法:load()方法和save()方法。load()方法可以加载外部数据源为一个DataFrame,save()方法可以将一个DataFrame写入指定的数据源。
二、默认数据源
(一)默认数据源Parquet
默认情况下,load()方法和save()方法只支持Parquet格式的文件,Parquet文件是以二进制方式存储数据的,因此不可以直接读取,文件中包括该文件的实际数据和Schema信息,也可以在配置文件中通过参数spark.sql.sources.default对默认文件格式进行更改。Spark SQL可以很容易地读取Parquet文件并将其数据转为DataFrame数据集。
(二)案例演示读取Parquet文件
将数据文件users.parquet上传到master虚拟机/home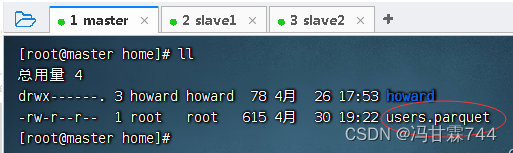
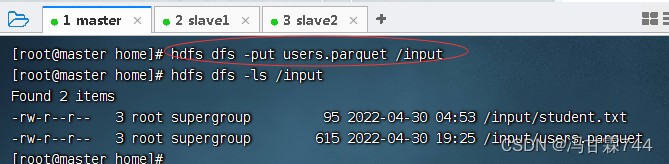
将数据文件users.parquet上传到HDFS的/input目录
1、在Spark Shell中演示
- 启动Spark Shell,执行命令:
spark-shell --master spark://master:7077 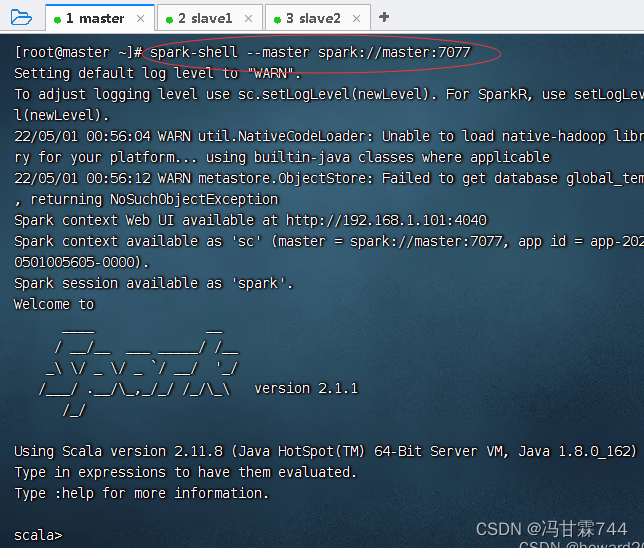
- 加载parquet文件,返回数据帧
- 执行命令:
val userdf = spark.read.load("hdfs://master:9000/input/users.parquet") 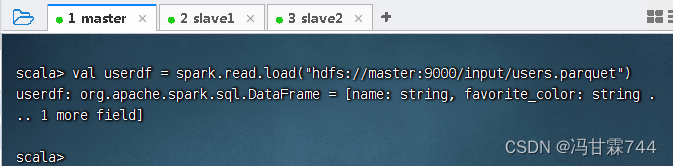
执行命令:userdf.show(),查看数据帧内容
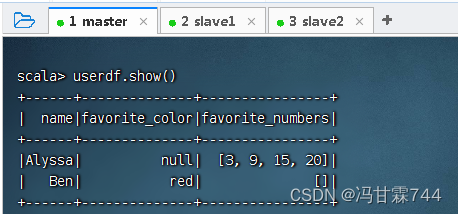
执行命令:userdf.select("name", "favorite_color").write.save("hdfs://master:9000/result"),对数据帧指定列进行查询,查询结果依然是数据帧,然后通过save()方法写入HDFS指定目录

查看HDFS上的输出结果

- 除了使用select()方法查询外,也可以使用SparkSession对象的sql()方法执行SQL语句进行查询,该方法的返回结果仍然是一个DataFrame。
- 基于数据帧创建临时视图,执行命令:
userdf.createTempView("t_user") 
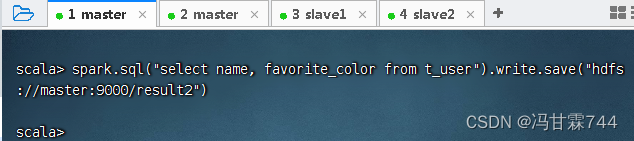
执行SQL查询,将结果写入HDFS,执行命令:spark.sql("select name, favorite_color from t_user").write.save("hdfs://master:9000/result2")
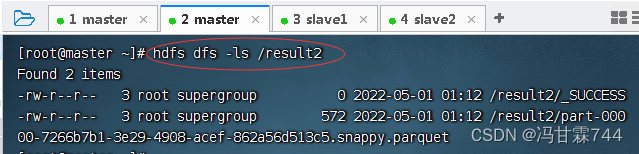
查看HDFS上的输出结果
2、通过Scala程序演示
- 创建Maven项目 - SparkSQLDemo
- 在pom.xml文件里添加依赖与插件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0
http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>net.hw.sparksql</groupId>
<artifactId>SparkSQLDemo</artifactId>
<version>1.0-SNAPSHOT</version>
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1021
1021











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









