







- 什么是机器学习?
让机器具备自动找到一个函数function的能力(函数f 输入x—输出f(x))
| 应用 | 函数输入 | 函数输出 |
| 语音识别 | 声音信号 | 音频对应文字 |
| 图像分类 | 图片 | 图片内包含内容 |
| AlphaGo下围棋 | 黑白棋的位置 | 下一步应该落子的位置 |
2.机器学习的三大任务
| 任务 | 函数输出 | 实例 | ||
| Regression 回归 | 连续数值 | PM2.5预测 | ||
| Classification 分类 | 二分类(Binary Classification) | 离散的值(从设定好的选项中选择正确的一个) | 0/1 Yes/No | 判断是否为垃圾邮件 |
| 多分类(Multi-Category Classification) | [1,2,3,…,N] | 图像分类里判断一张图片是猫、狗还是杯子 | ||
| Structured Learning 结构学习 | 有结构的内容 | 生成图片、文本 | ||
3.机器学习三个步骤(机器如何找函数?训练)
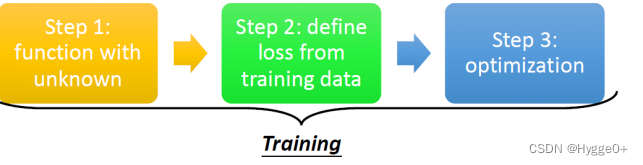
| 训练步骤 | 描述 |
| Function with unknown parameters 确定模型Model | 特征x、标签y、权重w、偏置b 线性回归模型 y=wx+b(w,b为待训练参数) |
| Define Loss from training data 确定如何评价函数的好坏 | 含义:L(w,b)衡量模型参数的好坏 公式:Loss:L(w,b)=I/N∑en e=|y-yhat|时,L is mean absolute error(MAE) e=(y-yhat)²时,L is mean square error(MSE) |
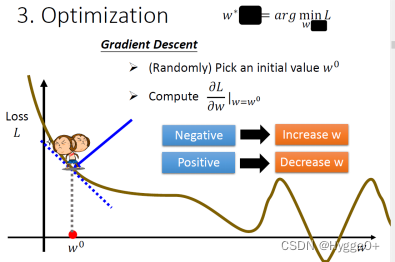
| Optimization 确定如何找到最好的函数 | 目标:找到一组w,b值使Loss最小 方法:梯度下降法Gradient decent LearningRate:学习率。是自设定参数hyperparameter error surface:先假设未知的参数只有w这个未知的参数,那当w代不同数值时,就会得到不同的Loss,这一条曲线就是error surface
步骤:
w,b的变化量取决于梯度和学习率的大小:梯度绝对值或学习率越大,则w,b变化量越大。
|
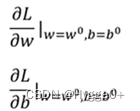
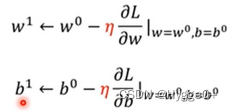
4.Regression(简单的神经网络)
引入:Piecewise Linear Curves(分段线性曲线)
- Linear Model有限制 不是所有的数据都存在线性关系
- 任何piecewise linear curve都可以看作是一个常数,再加上一堆蓝色的Function
【即red curve=constant+sum of a set of blue function】
【蓝色Function特点:当输入的值,当 x 轴的值小于某一个Treshold时,它是某一个定值;大于另外一个 Treshold 的时候,又是另外一个定值;中间有一个斜坡】
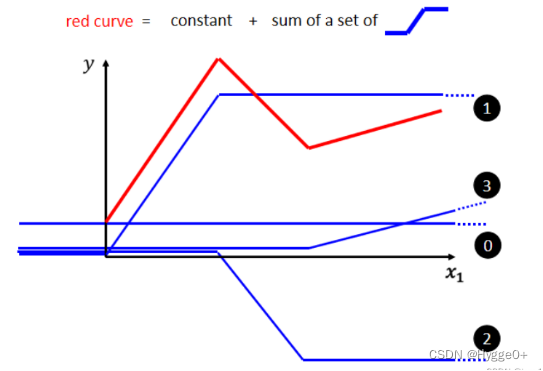
- 任何连续曲线,你只要取足够多的转折点,你都能用piecewise linear curve去逼近它
Back to ML_Step 1 :function with unknown
- 如何表示蓝色折线function?
用Sigmoid函数表示这个蓝色折线(即Hard Sigmoid)
【为什么不用分段函数表示蓝色折线function?因为分段函数在折点处不可导,不能根据梯度下降法进行调参优化】
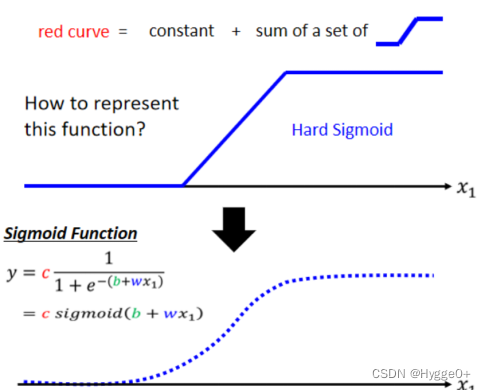
- 只需要调整w、b、c的值就可以制造不同形状的Sigmoid Function
【w决定曲线斜率;b决定曲线左右平移位置;c决定曲线高度】
- 把不同的Sigmoid Function叠起来,可以去逼近各种不同的Piecewise Linear的Function,Piecewise Linear的Function可以拿来近似各种不同的Continuous的Function。
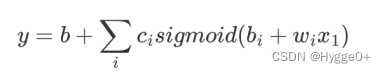
【red curve=constant+sum of a set of blue function】
- 多个特征的函数表示
- i表示不同的sigmoid函数
- j表示不同的Feature
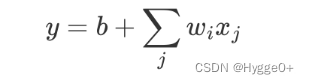
用sigmoid函数表示后,上式替换为:
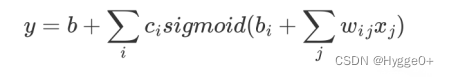
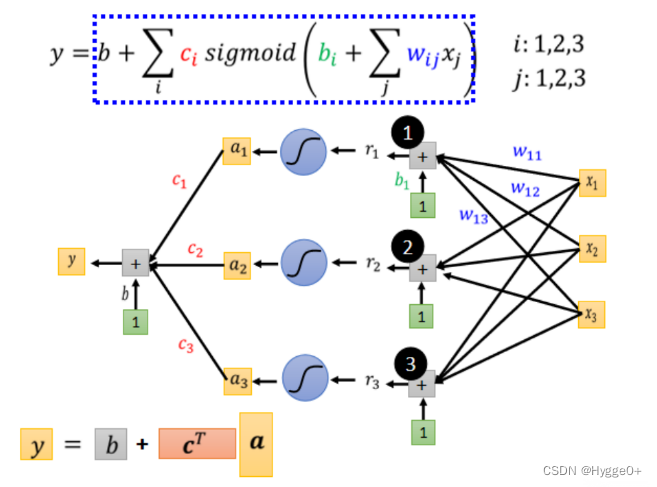
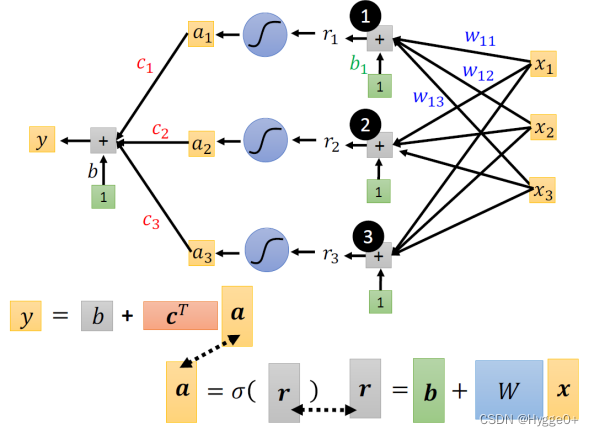
【公式含义:输入Feature x 这个向量,x 乘上矩阵w加上向量b得到向量r,向量r通过 Sigmoid Function得到向量a,再把向量 a 跟乘上c的 Transpose 加上b就得到 y】
把这些未知参数通通拉直,拼成一个很长的向量,用一个符号叫做 θ来表示它。
θ是一个很长的向量,里面的第一个数值我们叫 θ1,第二个叫 θ2…,它统称所有未知的参数。
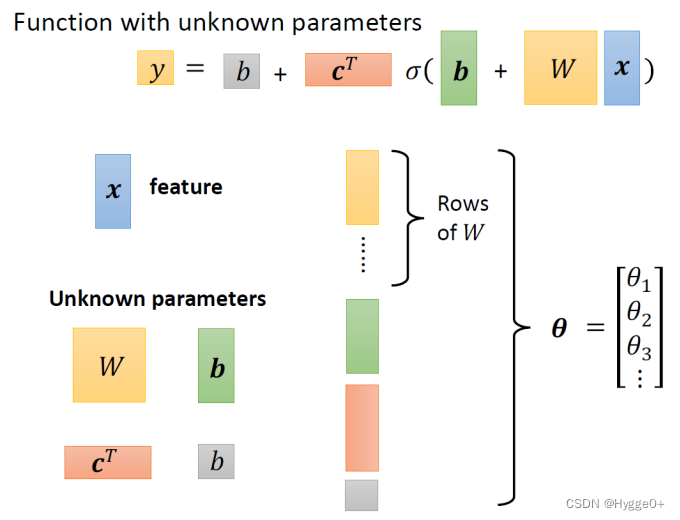
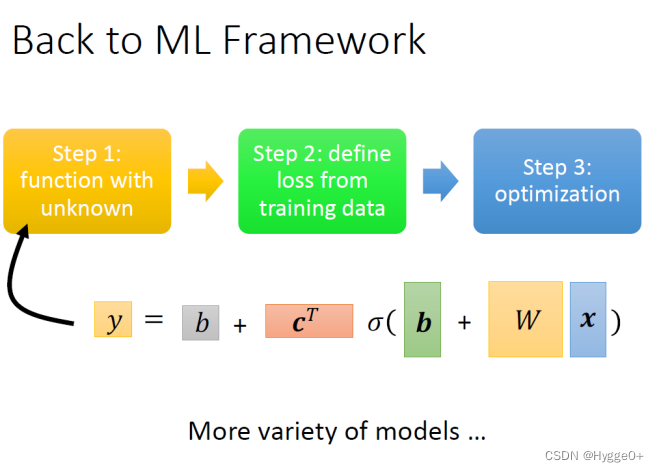
至此,我们完成了机器学习的step1:找到含未知参数的函数/确定模型
Back to ML_Step 2 :define loss from training data
定义Loss函数:所有参数均用θ表示,则 Loss Function 变成 L(θ)
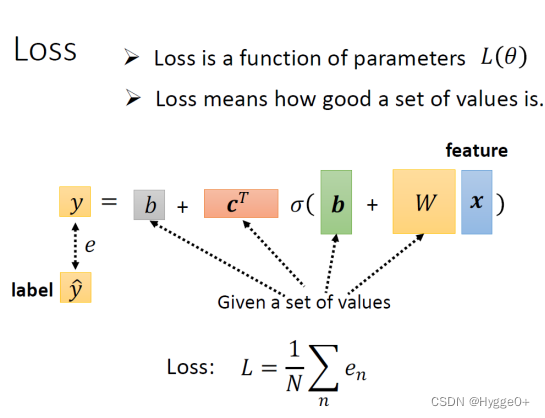
- 先给定某一组 W、b、c^T跟 b的初始值
- 然后把一种 Feature x 带进去,估测y
- 再计算跟真实的 Label之间的差距,得到 e
- 把所有的误差加起来,得到 Loss
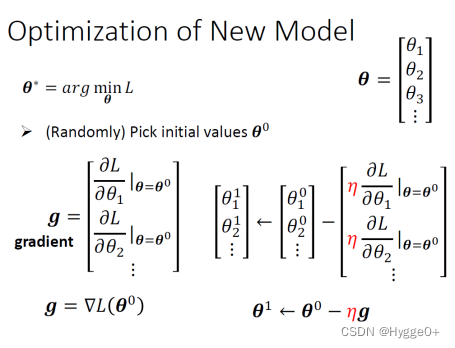
Back to ML_Step 3: Optimization
θ是一个很长的向量,要找一组θ让 Loss 越小越好,可以让 Loss 最小的那一组 θ,我们叫做 θ Star,θ^*,具体步骤如下:
(1)随机选一个初始的数值θ0
(2)对每一个未知的参数计算对 L 的微分以后,集合起来它就是一个向量g
(3)Update参数

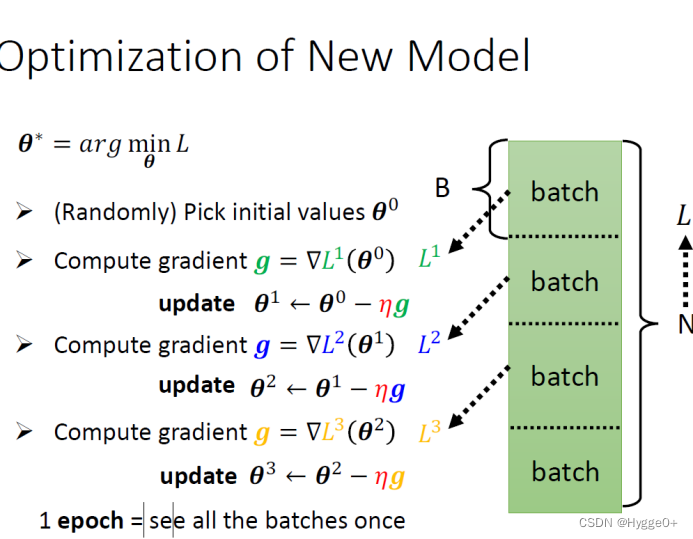
Batch、Update、Epoch
【Batch:将训练集随机划分为多个更小的单元,每一个batch里有一批资料。】
【每次只拿出一个Batch的资料进行计算gradient】
【Update:每次更新一次参数;Epoch:把所有batch都看过一遍,遍历所有数据】
ReLU、Sigmoid
【蓝色Function不一定要用 Soft Sigmoid表示,也可用Hard Sigmoid表示】
【Hard Sigmoid可以看作是两个Rectified Linear Unit 的叠加】
Rectified Linear Unit (ReLU)如下图所示:

【激活函数】
Sigmoid或是 ReLU在机器学习里面叫Activation Function
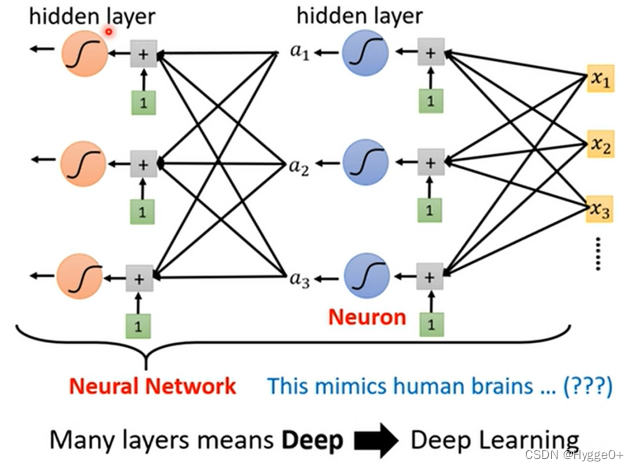
【神经元、神经网络、深度学习】















 460
460











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









