






最近整理发票,担心发票重复,所以用excel条件格式对发票列进行重复项识别,结果如下
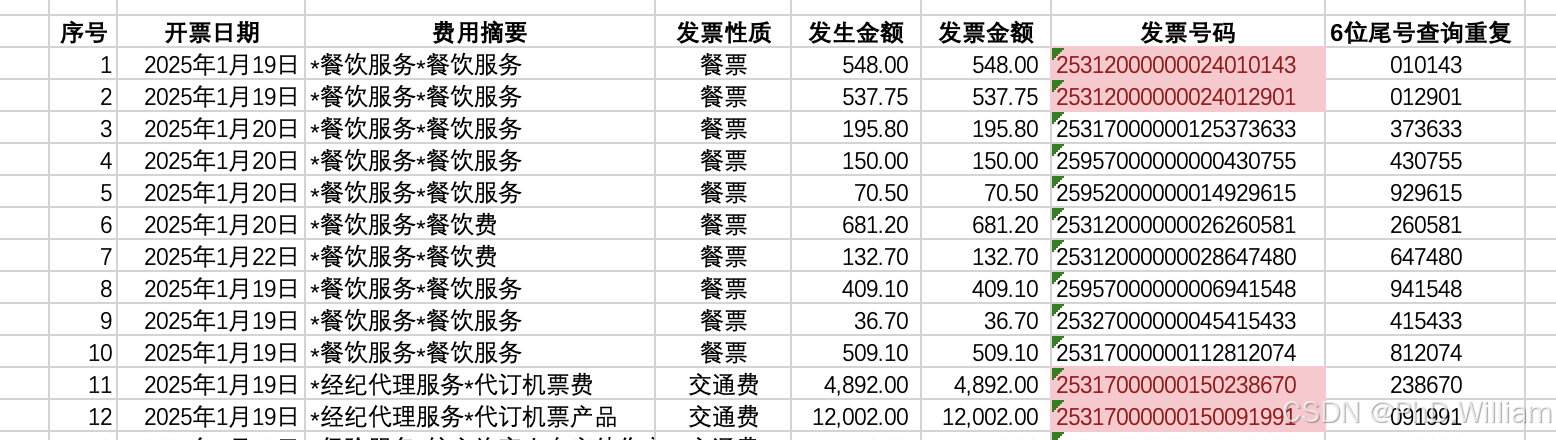
从结果来看识别出现了错误,明明不重复但也识别成了重复。
发票是增值税普通发票,20位,deepseek查了一下,通常由 发票代码(12位) + 发票号码(8位) 组成,共20位(合并后)。在Excel中,当文本字符串超过 15位数字 或 255个字符 时,可能会因精度限制或函数处理规则导致重复值识别的误判。
如果文本内容由纯数字组成且长度超过15位(如身份证号、订单号等),Excel默认会将其识别为数值类型,并按浮点数(双精度)存储,导致 后3位被强制舍入为0。例如,输入 12345678901234567890(20位),Excel会将其转换为 1.23456789012346E+19(科学计数法),实际存储值为 12345678901234500000,导致后续相同前缀但后几位不同的值被误判为重复。
deepseek给出的解决方案由两个,但方法1不适合大批量数据输入,方法2我试过不起作用,上图中实际上我就是以文本形式储存的。
方法1:在输入前添加英文单引号 '(如 '12345678901234567890),强制以文本格式存储。
方法2:将单元格格式设置为 文本格式(右键单元格 → 设置单元格格式 → 文本)。
所以我想到两个优化的方法,一是如上图最后一列所示,截取尾部一部分数字来做重复项识别,当然这个取决于对这一串数字含义的预判,尾部8位发票号码是系统随机产生的,出现重复的概率较小。
二是在这一串数字之前加上1-2个字母,比如fp,这样就不是纯数字了,也就不受限于上述15位纯数字的精度问题。

















 933
933

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









