







写在最前,
写文章的初衷只是为了复习与记录自己的成长,笔者本人也还是学生,文章中难免会出现许多问题与错误,文章内容仅供参考,有不足的地方还请大家多多包涵并指正,谢谢~
第六章 规划和维护索引操作
6.1 索引的作用与构架
索引是对数据库表中一个或多个列的值进行排序的结构。每个索引都有一个特定的搜索码与表中的记录相关联。索引按顺序存储搜索码的值。
数据库中的索引与书籍中的索引类似,在一本书中,利用索引可以快速查找所需信息,无须阅读整本书。在数据库中,索引使数据库程序无须对整个表进行扫描,就可以在其中找到所需数据。

索引的作用
1.通过创建唯一索引,可以保证数据记录的唯一性。
2.可以大大加快数据检索速度。
3.可以加速表与表之间的连接。
4.在使用ORDER BY和GROUP BY子句中进行检索数据时,可以显著减少查询中分组和排序的时间。
5.使用索引可以在检索数据的过程中使用查询优化器,提高系统性能。
SQL Server索引下的数据组织结构
在 SQL Server 数据库内,索引对象以 8 KB 页的集合存储。
索引页的结构与数据页的结构非常相似。索引页的大小固定为8KB,索引页都有一个 96 字节的页头,其中包含象拥有该页的表的标识符 (ID) 这样的系统信息。如果页链接在索引列表中,则页头还包含指向下一页及前面用过的页的指针。在页尾没有行偏移数组。数据行填充页的剩余部分。
SQL Server索引是通过sysindexes表进行管理。sysindexes表内的页指针可以定位表、索引和索引视图的所有页集合。
每个表、索引和索引视图在sysindexes内有一记录行,由对象标识符(id)列和索引标识符(indid)列的组合唯一标识。
索引分配映像(Index Allocation Map,简称IAM)页管理分配表、索引和索引视图所使用的页的空间。
1.堆集结构
堆集结构不按任何特殊顺序存储数据行,数据页序列没有任何特殊顺序。
记录按其插入的先后顺序存放,类似堆货物一样,来了新的货物堆放在上面。
堆集存储方式是最简单、最原始、最早使用的一种存储结构。
堆集结构插入容易,查找不方便。
堆集在 sysindexes 内有一行记录,其 indid = 0。sysindexes.FirstIAM 列指向 IAM 页链的 IAM 首页,IAM 页链管理分配给堆集的空间。 SQL Server 使用 IAM 页在堆集中浏览。堆集内的数据页和行没有任何特定的顺序,也不链接在一起。
通过扫描 IAM 页可以对堆集进行表扫描或串行读,以找到容纳这个堆集的页的扩展盘区。

2.聚集索引结构
聚集索引类似于电话簿。
聚集索引对表的物理数据页中的数据按列进行排序,然后重新存储到磁盘上,即聚集索引与数据是混为一体的,它的叶节点中存储实际数据。
每个表只能有一个聚集索引。
聚集索引在 sysindexes 内有一行记录,其 indid = 1。数据链内的页和其内的行按聚集索引键值排序。所有插入都在所插入行中的键值与排序顺序相匹配时执行。
SQL Server将索引组织为 B 树。索引内的每一页包含一个页首,页首后面跟着索引行。每个索引行都包含一个键值以及一个指向较低级页或数据行的指针。索引的每个页称为索引节点。B 树的顶端节点称为根节点。索引的底层节点称为叶节点。每级索引中的页链接在双向链接列表中。在聚集索引内数据页组成叶节点。根和叶之间的任何索引级统称为中间级。
对于聚集索引,sysindexes.root 指向B 树的顶端。SQL Server 沿着聚集索引浏览以找到聚集索引键对应的行。

3.非聚集索引
非聚集索引类似于书中的索引。
非聚集索引具有完全独立于数据行的结构,使用非聚集索引不用将物理数据页中的数据按列排序。非聚集索引的叶节点存储了组成非聚集索引的关键字值和行定位器。
如果索引时没有指定索引类型,默认情况下为非聚集索引。
每个表最多可以创建249个非聚集索引。
最好在唯一值较多的列上创建非聚集索引。
非聚集索引与聚集索引一样有 B 树结构,但是有两个重大差别:
(1)数据行不按非聚集索引键的顺序排序和存储。
(2)非聚集索引的叶层不包含数据页。 相反,叶节点包含索引行。
非聚集索引可以在有聚集索引的表、堆集或索引视图上定义。
在 SQL Server 2005 中,非聚集索引中的行定位器有两种形式:
(1)如果表是堆集(没有聚集索引),行定位器就是指向行的指针。
(2)如果表有聚集索引,或者索引在索引视图上,则行定位器就是行的聚集索引键。

4.扩展盘区空间的管理
索引分配映射(IAM)页映射数据库文件中由堆集或索引使用的扩展盘区。对于任何具有ntext、text和image类型的列的表,IAM页还映射分配给这些类型的页链的扩展盘区。每个对象对每个包含扩展盘区的文件都至少有一个IAM。
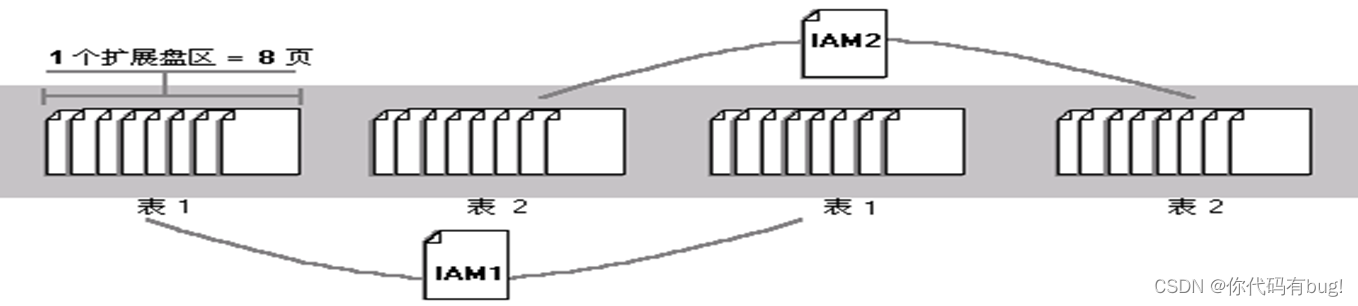
IAM页按需要分配给每个对象,在文件内随机定位。Sysindexes.dbo.FirstIAM指向对象的IAM首页,该个对象的所有IAM 页用链条链接在一起。
IAM 页的页首说明IAM所映射的扩展盘区范围的起始扩展盘区。IAM中还有大位图,位图内的每个位代表一个扩展盘区。
6.2 索引类型
1、复合索引:一个索引包含了一个以上的列。最多可以有16个列复合到一个索引。复合索引允许某一列具有相同的值。
单列索引:对表中单列建立索引。
2、唯一索引:唯一索引可以确保索引列中不包含重复值。只有唯一性是数据本身特征时指定唯一索引才有意义。唯一索引不能完全等同于主键。如果某列包含多行NULL值,不能在该列上创建唯一索引。创建唯一索引要使用UNIQUE选项。
3、主键索引:表定义主键时自动创建主键索引,并且会自动创建聚集索引。创建聚集索引时,可以指定填充因子,以便在索引页上留出额外的间隙和保留一定百分比的空间,供将来表的数据行增加或更新时减少发生页拆分机会。创建时可以选项填充因子。
非主键索引是在非主键的属性列上创建的索引。
4、聚集索引:行的物理存储顺序与索引顺序完全相同,每个表只允许建立一个聚集索引。非聚集索引不改变数据行的物理存储顺序。
6.3 规划设计索引的一般原则
什么类型查询适合建立索引
(1)搜索符合特定搜索关键字值的行(精确匹配查询)。
(2)搜索其搜索关键字值为范围值的行(范围查询)。
(3)在表T1中搜索根据联接谓词与表T2中的某个行匹配的行。
(4)在不进行显式排序操作的情况下产生经排序的查询输出,尤其是经排序的动态游标。
(5)在不进行显式排序操作的情况下,按一种有序的顺序对行进行扫描,以允许基于顺序的操作,如合并联接。
(6)以优于表扫描的性能对表中所有的行进行扫描,性能提高是由于减少了要扫描的列集和数据总量。
(7)搜索插入和更新操作中重复的新搜索关键字值,以实施PRIMARY KEY和UNIQUE约束。
(8)搜索已定义了FOREIGN KEY约束的两个表之间匹配的行。
(9)使用LIKE比较进行查询时,如果模式以特定字符串如“abc%”开头进行了索引,使用索引则会提高效率。
其它索引设计准则
(1)一个表如果建有大量索引会影响INSERT、UPDATE和DELETE语句的性能 ;
(2)覆盖的查询可以提高性能。
(3)对小型表进行索引可能不会产生优化效果
(4)应使用SQL事件探查器和索引优化向导帮助分析查询,确定要创建的索引。
(5)可以在视图上指定索引。
(6)可以在计算列上指定索引。
索引的特征
在确定某一索引适合某一查询之后,可以自定义最适合具体情况的索引类型。索引特征包括:
(1)聚集还是非聚集
(2)唯一还是不唯一
(3)单列还是多列
(4)索引中的列顺序为升序还是降序
(5)覆盖还是非覆盖
还可以自定义索引的初始存储特征,通过设置填充因子优化其维护,并使用文件和文件组自定义其位置以优化性能。
在文件组上合理放置索引
默认情况下,索引创建在基表所在的文件组上,该索引即在该基表上创建。
如果表上有聚集索引,数据和该聚集索引将始终驻留在相同的文件组内。因此,可以在基表上创建一个聚集索引,指定另外一个文件组,在该文件组上新建索引(然后可以除去该索引,而只在新文件组内保留基表),从而将表从一个文件组移动到另一个文件组。
如果表的索引跨越多个文件组,则必须将所有包含该表及其索引的文件组一起备份,之后还必须创建事务日志备份。否则,只能备份索引的一部分,导致还原备份时无法恢复索引。
单个表或索引只能属于一个文件组,而不能跨越多个文件组。
索引优化建议
(1)将更新尽可能多的行的查询写入单个语句内,而不要使用多个查询更新相同的行。仅使用一个语句,就可以利用优化的索引维护。
(2)使用索引优化向导分析查询并获得索引建议。
(3)对聚集索引使用整型键。另外,在唯一列、非空列或 IDENTITY 列上创建聚集索引可以获得比较好的性能收益。
(4)在查询经常用到的所有列上创建非聚集索引。这可以最大程度地利用隐蔽查询。
(5)物理创建索引所需的时间在很大程度上取决于磁盘子系统 。
(6)检查列的唯一性。
(7)在索引列中要注意检查数据的分布情况。
6.4 索引的创建和删除
创建索引
1.创建索引的方法
利用Transact-SQL语句中的CREATE INDEX命令创建索引。
语法格式:
CREATE [UNIQUE] [CLUSTERED| NONCLUSTERED ]
INDEX 索引名
ON 数据表名|视图名( 字段名 [ ASC | DESC ] [ ,...n ] )
[WITH
[PAD_INDEX]
[[,]FILLFACTOR=填充因子]
[[,]IGNORE_DUP_KEY]
[[,]DROP_EXISTING]
[[,]STATISTICS_NORECOMPUTE]
[[,]SORT_IN_TEMPDB]]
[ ON 文件组名]
举个例子:教学管理数据库表的索引设计
| 列名 | 聚集索引 | 唯一索引 | 非聚集索引 | 是否主键 |
| STUDENT.SNO | √ | √ | √ | |
| STUDENT.SNAME | √ | |||
| COURSE.CNAME | √ | √ | ||
| TEACHER.TNAME | √ | √ | √ |
利用SQL中的CREATE INDEX命令创建索引
USE 教学管理
GO
CREATE UNIQUE CLUSTERED INDEX IX_学号 ON 学生表(学号)
WITH (pad_index=ON,fillfactor=100)
--上述命令关于学生表.学号建立了升序惟一性聚集索引,索引名为IX_学号,填充因子为100。例 为数据库“教学管理”中数据表关于课程表.课名降序建立唯一索引IX_课程表_课名。
USE 教学管理
GO
CREATE UNIQUE INDEX IX_课程表_课名 ON 课程表(课名 DESC) 例 为数据库“教学管理”中数据表关于教师表.姓名升序建立非聚集和非唯一索引IX_教师表_姓名。
USE 教学管理
GO
CREATE INDEX IX_教师表_姓名 ON 教师表 (姓名 ASC) 例 为数据库“教学管理”中数据表关于选课表.学号降序,选课表.开课号升序建立组合惟一索引IX_学号_开课号,填充因子为90,在插入数据时,可以忽略重复的值。如果已经存在IX_学号_开课号索引,则先删除后重建。
USE 教学管理
GO
CREATE UNIQUE INDEX IX_学号_开课号 ON 选课表(学号 DESC,开课号 ASC)
WITH(
PAD_INDEX=ON, --保持索引开放的空间
FILLFACTOR=90, --填充因子90
IGNORE_DUP_KEY=ON, --忽略重复键值
DROP_EXISTING=ON) --如果存在IX_学号_开课号索引则删除,如果不存在,则提示错误中断索引创建例 为数据库“教学管理”中数据表关于选课表.成绩降序建立非聚集索引IX_选课表_成绩。
USE 教学管理
GO
IF EXISTS (SELECT name FROM sysindexes WHERE name='IX_选课表_成绩')
DROP INDEX 选课表.IX_选课表_成绩
--如果存在IX_选课表_成绩索引删除
CREATE NONCLUSTERED INDEX IX_选课表_成绩 ON 选课表(成绩 DESC) 删除索引
2.删除索引的方法
利用SQL语句中的DROP INDEX命令删除索引。
语法形式:
DROP INDEX 索引名[,…n]
举个例子:
使用SQL命令删除索引IX_选课表_成绩
USE 教学管理
GO
DROP INDEX 选课表.IX_选课表_成绩 6.5 查询中的执行计划
查看查询执行计划
执行
SELECT 学号, 姓名 FROM 学生表 ORDER BY 姓名 按Ctrl+L或者在“查询”菜单上选择“显示估计的执行计划”显示这个查询的执行计划。 
索引和未索引执行计划的比较
1. 检验堆结构
先创建一个学生表_备份表。再将学生表里数据拷贝过来,则学生表_备份表因为没有定义主键,也没有索引,所以是一个堆结构。
在执行之前按“Ctrl+M”或在“查询”菜单中选择“包括实际的执行计划”来包括实际的执行计划。然后执行查询学生表_备份表。 
2. 检验聚集索引
CREATE UNIQUE CLUSTERED INDEX CLIDX_学生表_备份_ID ON 学生表_备份(学号) 执行前面执行过的SELECT语句来检验区别。
可以看出,这里的SQL Server不再使用表扫描。 
3. 检验非聚集索引
堆 如果表没有聚集索引,SQL Server将在非聚集索引的叶子级存储一个指向物理行的指针(文件id、页id合页中的行id)。在这种情况下,SQL Server通过查询索引进而依据指针指向来获取行的方式查找一个特定的行。
聚集索引 当一个聚集索引存在的时候,SQL Server会在非聚集索引的叶子级将此行的聚集索引的键存储为指针。如果SQL Server要根据非聚集索引获取一行,会在非聚集索引中进行查找,找出合适的聚集键,然后再通过聚集索引来获取行。
执行以下查询:
SELECT * FROM 学生表_备份 order by 身份证号 由于身份证号列没有索引,因此SQL Server执行了一次聚集索引操作,主要操作用到了排序上。 
为了加速这个查询,SQL Server需要身份证号列有一个索引。由于在学生表_备份表上已经定义了一个聚集索引,因此必须使用非聚集索引。
CREATE INDEX CLIDX_学生表_备份_身份
ON 学生表_备份(身份证号) 执行前一个SELECT语句并按“Ctrl+L”来显示估计的执行计划。

6.6 索引使用中的维护
维护索引的统计信息
例 显示指定索引的统计信息
USE 教学管理
GO
DBCC SHOW_STATISTICS(学生表_备份,CLIDX_学生表_备份_身份)
--显示学生表_备份上CLIDX_学生表_备份_身份索引的统计信息
GO例 更新指定表的索引统计信息
USE 教学管理
GO
UPDATE STATISTICS 学生表 --更新学生表student的所有索引的统计
GO例 对指定数据库中所有表的索引统计进行更新
USE 教学管理
GO
EXECUTE sp_updatestats维护索引碎片
索引碎片有两类:内部碎片和外部碎片。
内部碎片:当索引页里还有空间可利用时,出现的碎片是内部碎片;内部碎片意味着索引占据了比他实际需要还要多的空间。在创建索引时指定一个较低的填充因子,就会产生内部碎片。
外部碎片:当数据页的逻辑顺序和物理顺序不匹配的时候,或者一个表的存储区不连续时,出现的碎片就是外部碎片。
索引碎片的检测:DBCC SHOWCONTIG
[例]查看教学管理数据库中学生表_备份表的CLIDX_学生表_备份_身份索引碎片信息。
USE 教学管理
GO
DBCC SHOWCONTIG(学生表_备份,CLIDX_学生表_备份_身份)写在最后,
因本系列文章主要为复习,故重点关注数据库概念知识与理论知识,涉及使用对象资源管理器操作数据库的内容就不再赘述,笔记仅作为参考,若读者发现内容有误请私信指正,谢谢~















 2398
2398











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











