






目录
索引
一 概念
# 索引,使用索引可快速访问数据库表中的特定信息。索引是对数据库表中一列或多列的值进行排序的一种结构。 在关系数据库中,索引是一种与表有关的数据库结构,它可以使对应于表的SQL语句执行得更快。索引的作用相当于图书的目录,可以根据目录中的页码快速找到所需的内容。
二优点和缺点
# 优点
- 1.创建唯一性索引,保证数据库表中每一行数据的唯一性
- 2.大大加快数据的检索速度,这也是创建索引的最主要的原因
- 3.减少磁盘IO(向字典一样可以直接定位)
# 缺点
- 1.创建索引和维护索引要耗费时间,这种时间随着数据量的增加而增加
- 2.索引需要占用额外的物理空间
- 3.当对表中的数据进行增加、删除和修改的时候,索引也要动态的维护,降低了数据的维护速度
三 索引类型
# 普通(Normal):
也叫非唯一索引,是最普通的索引,没有任何的限制。
# 唯一(Unique):
唯一索引要求键值不能重复。另外需要注意的是,主键索引是一种特殊的唯一索引,它还多了一个限制条件,要求键值不能为空。主键索引用 primay key创建。
# 全文(Fulltext):
针对比较大的数据,比如我们存放的是消息内容,有几 KB 的数 据的这种情况,如果要解决like 查询效率低的问题,可以创建全文索引。只有文本类型 的字段才可以创建 全文索引,比如 char、varchar、text。
# 聚合索引:
由多个字段共同组成的索引。
四 索引优化
1. 尽量避免在字段开头模糊查询,会导致数据库引擎放弃索引进行全表扫描
SELECT * FROM user WHERE name LIKE '%用%' -- 优化方式:尽量在字段后面使用模糊查询 SELECT * FROM user WHERE name LIKE '用%'
如果需求是要在前面使用模糊查询,使用MySQL内置函数INSTR(str,substr) 来匹配,作用类似于java中的indexOf()
2. 尽量避免使用in 和not in,会导致引擎走全表扫描
SELECT * FROM user WHERE id IN (2,3) -- 优化方式:如果是连续数值,可以用between代替 SELECT * FROM user WHERE id BETWEEN 2 AND 3
3. 尽量避免使用 or,会导致数据库引擎放弃索引进行全表扫描
select * from user WHERE id = 1 or id = 3 -- 优化方式:可以用union(且)代替or select * from user WHERE id = 1 UNION select * from user WHERE id = 3
4. 尽量避免进行null值的判断,会导致数据库引擎放弃索引进行全表扫描
select * from user WHERE age is null -- 优化方式:可以给字段添加默认值0,对0值进行判断 select * from user WHERE age = 0
5.尽量避免在where条件中等号的左侧进行表达式、函数操作,会导致数据库引擎放弃索引进行全表扫描
可以将表达式、函数操作移动到等号右侧 ( 不建议这样写会造成运行效率降低 )
-- 全表扫描 SELECT * FROM user WHERE age/10 = 9 -- 走索引 SELECT * FROM user WHERE age = 10*9
6. 当数据量大时,避免使用where 1=1的条件。通常为了方便拼装查询条件,我们会默认使用该条件,数据库引擎会放弃索引进行全表扫描
SELECT name, age, pwd FROM user and 1=1 -- 优化方式:用代码拼装sql时进行判断,没 where 条件就去掉 where,有where条件就加 and SELECT name, age, pwd FROM user WHERE 1 and 1
7. 查询条件不能用 < > 或者 !=
使用索引列作为条件进行查询时,需要避免使用<>或者!=等判断条件。要去java进行判断,不能对数据库进行操作
8. where条件仅包含复合索引非前置列
如下:复合(联合)索引包含a1,b2,c3三列,但SQL语句没有包含索引前置列"a1",按照MySQL联合索引的最左匹配原则,不会走联合索引
-- 创建联合索引 create index user_index on user (name,age,pwd) -- 这种方式是不会走索引的 select name,age,pwd from user where age=123 and pwd='312'
9. 隐式类型转换造成不使用索引
如下SQL语句由于索引对列类型为varchar,但给定的值为数值,涉及隐式类型转换,造成不能正确走索引。
select name from table where name = 123;
事务
# 如果一个包含多个步骤的业务操作,被事务管理,那么这些操作要么同时成功,要么同时失败
# 事务的四大特征:ACID
原子性:是不可分割的最小操作单位,要么同时成功,要么同时失败。
持久性:当事务提交或回滚后,数据库会持久化的保存数据。
隔离性:多个事务之间。相互独立。
一致性:事务操作前后,数据总量不变
函数
1 字符串
-
说明
| 函数 | 功能 |
|---|---|
| concat(s1,s2,...sn) | 字符串拼接,将 s1,s2 ,sn 拼接成一个字符串 |
| lower(str) | 将字符串 全部转为小写 |
| upper(str) | 将字符串 全部转为大写 |
| lpad(str,n,pad) | 左填充,用字符串pad对 的左边进行填充,达到 个字符串长度 |
| rpad(str,n,pad) | 右填充,用字符串pad对 的左边进行填充,达到 个字符串长度 |
| trim(str) | 去掉字符串头部和尾部的空格 |
| sbustring(str,start,len) | 返回从字符串 str从start位置起的len个长度 |
-
案例
select CONCAT('a','b','c')

select LOWER('ABC')
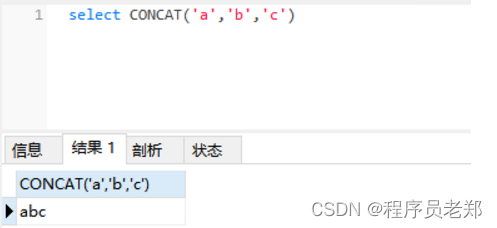
select UPPER('abc')

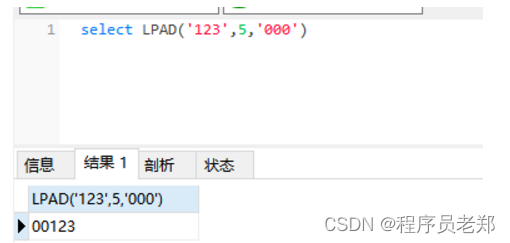
select LPAD('123',5,'000')
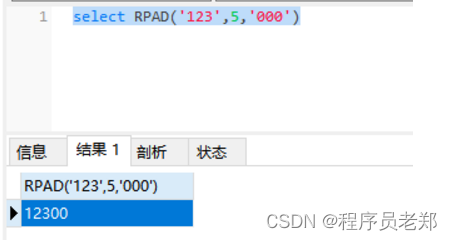
select RPAD('123',5,'000')
select TRIM(' aa ')

select SUBSTRING('18035185213',3,4)

2 数值函数
| 函数 | 功能 |
|---|---|
| ceil(x) | 向上取整 |
| floor(x) | 向下取整 |
| mod(x,y) | 返回 x/y的模 |
| rand() | 返回 0~1内的随机数 |
| round(x,y) | 求参数 的四舍五入的值,保留 位小数 |
select ceil(0.3)
select floor(1.3)
select mod(5,3)
select rand()
select round(3.567,2)
3 日期函数
| 函数 | 功能 |
|---|---|
| curdate() | 返回当前日期 |
| curtime() | 返回当前时间 |
| now() | 返回当前日期和时间 |
| year(date) | 获取指定 date的年份 |
| monty(date) | 获取指定 date的月份 |
| day(date) | 获取指定 date的日期 |
| date_add(date,interval expr type) | 返回一个日期 时间值加上一个时间间隔 |
| datediff(date1,date2) | 返回时间date1和时间date2之间的天数 |
select day(now())
select day('2023-07-12 14:28:40')
select DATE_ADD(now(),interval '-1' month)
select DATEDIFF("2023-06-12 23:59:59","2022-06-12 00:31:22")
视图
E—R图
1.找实体、2.找属性,3找关系
一个实体类对应一张表
三大范式
1.第一范式:目标是确保每列的原子性,分到最小数据单元。
2.第二范式:每张表只描述一个实体。
3.第三范式:任何非主属性不依赖于其他非主属性。















 10万+
10万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









