







前提:由于最近需要在原有Flink CEP的基础上,实现动态加载CEP规则的需求,因此想到了通过自定义动态CEP算子以及自定义动态pattern加载的算子协调器实现规则的更新。
因此在开发同时记录一下Flink数据处理的过程。
VERSION:FLINK 1.14.3
1.1. StreamExecutionEnvironment
在每个flink程序开发的时候,都会有一行这样的语句:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();具体做了什么,现在点到源码里看一下。
public static StreamExecutionEnvironment getExecutionEnvironment(Configuration configuration) {
return Utils.resolveFactory(threadLocalContextEnvironmentFactory, contextEnvironmentFactory)
.map(factory -> factory.createExecutionEnvironment(configuration))
.orElseGet(() -> StreamExecutionEnvironment.createLocalEnvironment(configuration));
}这里会通过工厂类获取到StreamExecutionEnvironment。
-
- 当本地IDE运行时创建的是LocalEnvironment
- 命令行启动时CliFrontend会对上下文进行初始化
StreamExecutionEnvironmentFactory factory =
conf -> {
Configuration mergedConfiguration = new Configuration();
mergedConfiguration.addAll(configuration);
mergedConfiguration.addAll(conf);
return new StreamContextEnvironment(
executorServiceLoader,
mergedConfiguration,
userCodeClassLoader,
enforceSingleJobExecution,
suppressSysout);
};
initializeContextEnvironment(factory);
protected static void initializeContextEnvironment(StreamExecutionEnvironmentFactory ctx) {
contextEnvironmentFactory = ctx;
threadLocalContextEnvironmentFactory.set(contextEnvironmentFactory);
}1.2. env.addSource
在程序开始都会通过addSource获取源数据,返回DataStreamSource<?>。
private <OUT> DataStreamSource<OUT> addSource(
final SourceFunction<OUT> function,
final String sourceName,
@Nullable final TypeInformation<OUT> typeInfo,
final Boundedness boundedness) {
......
TypeInformation<OUT> resolvedTypeInfo =
getTypeInfo(function, sourceName, SourceFunction.class, typeInfo);
......
final StreamSource<OUT, ?> sourceOperator = new StreamSource<>(function);
return new DataStreamSource<>(
this, resolvedTypeInfo, sourceOperator, isParallel, sourceName, boundedness);
}这里主要目的就是创建了StreamSource作为算子(将function赋给父类AbstractUdfStreamOperator),同时初始化并返回DataStreamSource(初始化了父类DataStream的environment和transformation)。
transformation是一个转换对象,后续所有的算子最终都会转换成一个transformation
1.3. transform
程序中调用map,filter,keyby等等算子进行逻辑处理,其实都是flink的transform操作。
以map为例:
public <R> SingleOutputStreamOperator<R> map(
MapFunction<T, R> mapper, TypeInformation<R> outputType) {
return transform("Map", outputType, new StreamMap<>(clean(mapper)));
}outputType中包含了当前算子的输入类型以及输出类型。
StreamMap是常用的算子中的一种,自定义MapFunction时也是调用了不同类下的userFunction.map
public class StreamMap<IN, OUT> extends AbstractUdfStreamOperator<OUT, MapFunction<IN, OUT>>
implements OneInputStreamOperator<IN, OUT> {
private static final long serialVersionUID = 1L;
public StreamMap(MapFunction<IN, OUT> mapper) {
super(mapper);
chainingStrategy = ChainingStrategy.ALWAYS;
}
@Override
public void processElement(StreamRecord<IN> element) throws Exception {
output.collect(element.replace(userFunction.map(element.getValue())));
}
}其他常用的算子类还有:

public <R> SingleOutputStreamOperator<R> transform(
String operatorName,
TypeInformation<R> outTypeInfo,
OneInputStreamOperator<T, R> operator) {
return doTransform(operatorName, outTypeInfo, SimpleOperatorFactory.of(operator));
}SimpleOperatorFactory.of(operator)是通过静态工厂设计方法,创建一个Simple算子的工厂,后续在流转换时会从工厂中获取对应的算子。
protected <R> SingleOutputStreamOperator<R> doTransform(
String operatorName,
TypeInformation<R> outTypeInfo,
StreamOperatorFactory<R> operatorFactory) {
transformation.getOutputType();
// 创建一个 OneInputTransformation 实例,用于描述输入转换和输出操作
OneInputTransformation<T, R> resultTransform =
new OneInputTransformation<>(
this.transformation,
operatorName,
operatorFactory,
outTypeInfo,
environment.getParallelism());
@SuppressWarnings({"unchecked", "rawtypes"})
SingleOutputStreamOperator<R> returnStream =
new SingleOutputStreamOperator(environment, resultTransform);
getExecutionEnvironment().addOperator(resultTransform);
return returnStream;
}最终创建OneInputTransformation实例,通过addOperator将当前算子对应的transform添加到StreamExecutionEnvironment下的List<Transformation<?>> transformations中。
其余算子操作都是这个流程,将算子操作 -> 算子对象 -> 算子类工厂 -> Transformation -> 添加到list中。
1.4. dataStream.addSink
大部分程序中会通过addSink将数据发送到其他系统,在流调用addSink时,其实都是使用的父类dataStream中的addSink方法。
DataStream及其子类,其中DataStream、KeyedStream和SingleOutputStreamOperator都是常见的流的接收类型。
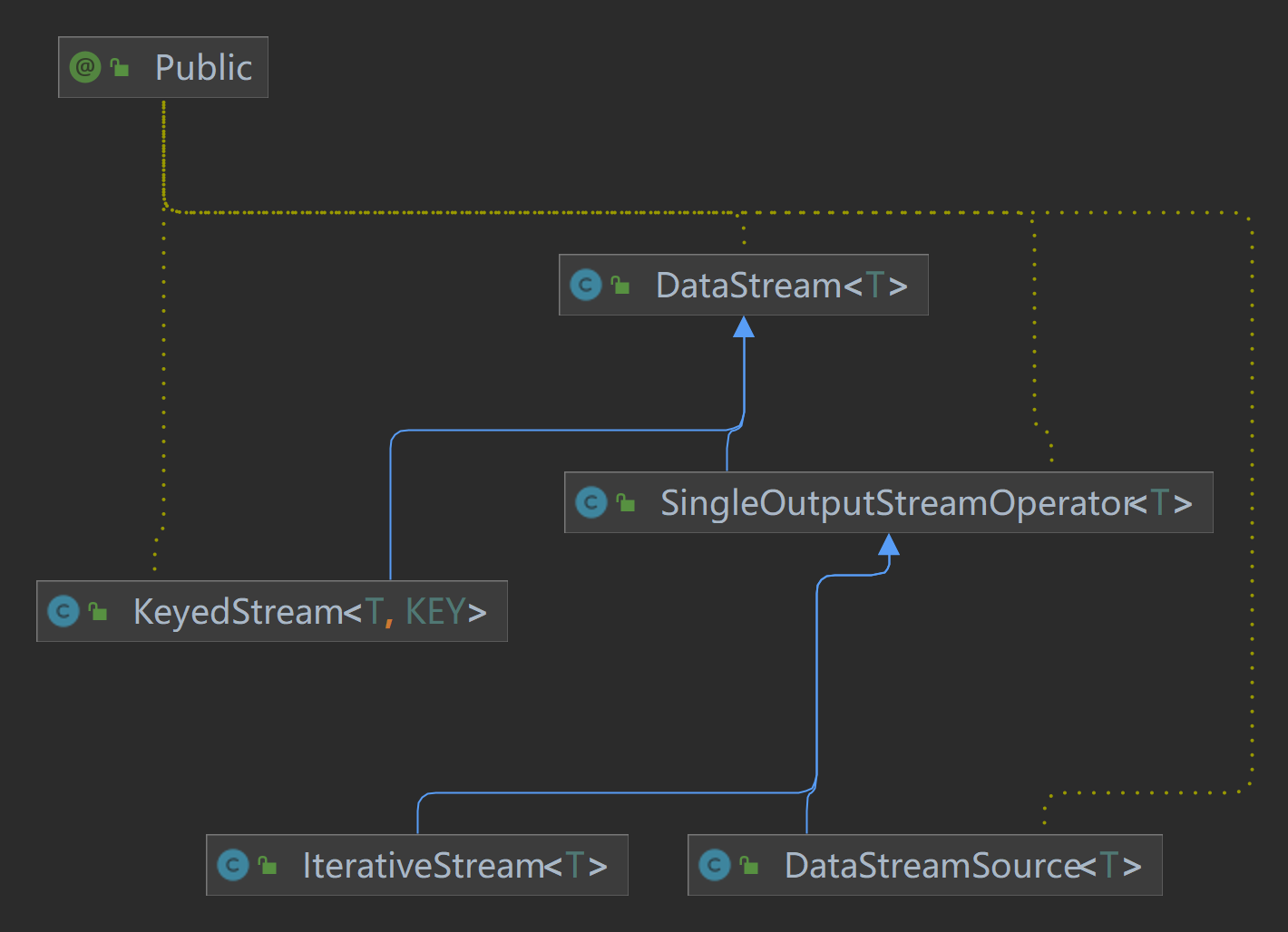
public DataStreamSink<T> addSink(SinkFunction<T> sinkFunction) {
......
StreamSink<T> sinkOperator = new StreamSink<>(clean(sinkFunction));
DataStreamSink<T> sink = new DataStreamSink<>(this, sinkOperator);
getExecutionEnvironment().addOperator(sink.getLegacyTransformation());
return sink;
}可以看到addSink和doTransform目的一样,都是将当前操作作为算子构建出transform放到list中,记录所有要执行的转换操作,以map时实例化的OneInputTransformation为例:
public OneInputTransformation(
Transformation<IN> input,
String name,
StreamOperatorFactory<OUT> operatorFactory,
TypeInformation<OUT> outputType,
int parallelism) {
super(name, outputType, parallelism);
this.input = input;
this.operatorFactory = operatorFactory;
}指定了当前Transformation的上游Transformation以及当前Transformation的算子工厂
protected static Integer idCounter = 0;
public static int getNewNodeId() {
idCounter++;
return idCounter;
}
public Transformation(String name, TypeInformation<T> outputType, int parallelism) {
this.id = getNewNodeId();
this.name = Preconditions.checkNotNull(name);
this.outputType = outputType;
this.parallelism = parallelism;
this.slotSharingGroup = Optional.empty();
}另外指定了父类Transformation中的一些信息,其中 NodeId 是从0开始递增,后续也会Stream Graph的NodeId。
总的来说,在编写flink程序的时候,就已经完成了流环境以及每个算子的一些初始化操作
1.5. env.execute()
env.execute是用来启动执行一个Flink程序的主要方法,方法内有两步操作
public JobExecutionResult execute() throws Exception {
return execute(getStreamGraph());
}getStreamGraph():获取stream Graph
execute:执行stream Graph
1.6. stream Graph
public StreamGraph getStreamGraph(boolean clearTransformations) {
// 将 transformations 算子列表转换生成 StreamGraph
final StreamGraph streamGraph = getStreamGraphGenerator(transformations).generate();
// 如果指定了清除转换列表,则清除
if (clearTransformations) {
transformations.clear();
}
return streamGraph;
}点到generate看一下。
public StreamGraph generate() {
// 通过执行配置、检查点配置、保存点配置初始化 stream graph
streamGraph = new StreamGraph(executionConfig, checkpointConfig, savepointRestoreSettings);
streamGraph.setEnableCheckpointsAfterTasksFinish(
configuration.get(ExecutionCheckpointingOptions.ENABLE_CHECKPOINTS_AFTER_TASKS_FINISH));
// 是否以批模式执行
shouldExecuteInBatchMode = shouldExecuteInBatchMode();
configureStreamGraph(streamGraph);
// 已经转换过的
alreadyTransformed = new HashMap<>();
// 对每个注册的转换进行转换操作
for (Transformation<?> transformation : transformations) {
transform(transformation);
}
streamGraph.setSlotSharingGroupResource(slotSharingGroupResources);
// 设置细粒度全局流交换模式
setFineGrainedGlobalStreamExchangeMode(streamGraph);
// 禁用不对齐检查点支持的流边
for (StreamNode node : streamGraph.getStreamNodes()) {
if (node.getInEdges().stream().anyMatch(this::shouldDisableUnalignedCheckpointing)) {
for (StreamEdge edge : node.getInEdges()) {
edge.setSupportsUnalignedCheckpoints(false);
}
}
}
final StreamGraph builtStreamGraph = streamGraph;
// 清理资源
alreadyTransformed.clear();
alreadyTransformed = null;
streamGraph = null;
return builtStreamGraph;
}初始化了StreamGraph并做了检查点等配置,这里主要看一下transform是如何处理每个转换操作的。
private Collection<Integer> transform(Transformation<?> transform) {
...... // 一些资源配置操作,先略过,主要看是如何处理transform的
// 获取特定类型转换的翻译器
final TransformationTranslator<?, Transformation<?>> translator =
(TransformationTranslator<?, Transformation<?>>) translatorMap.get(transform.getClass());
Collection<Integer> transformedIds;
// 如果存在合适的翻译器,则使用翻译器进行转换;否则使用旧版转换方式
if (translator != null) {
transformedIds = translate(translator, transform);
} else {
transformedIds = legacyTransform(transform);
}
// 如果尚未将转换操作放入已转换映射中,则将其添加进去
if (!alreadyTransformed.containsKey(transform)) {
alreadyTransformed.put(transform, transformedIds);
}
return transformedIds;
}translatorMap在static代码块中进行了初始化,以map为例获取到的是OneInputTransformationTranslator,直接看一下translator.translateForStreaming(transform, context)内部是做了什么。
protected Collection<Integer> translateInternal(
final Transformation<OUT> transformation,
final StreamOperatorFactory<OUT> operatorFactory,
final TypeInformation<IN> inputType,
@Nullable final KeySelector<IN, ?> stateKeySelector,
@Nullable final TypeInformation<?> stateKeyType,
final Context context) {
checkNotNull(transformation);
checkNotNull(operatorFactory);
checkNotNull(inputType);
checkNotNull(context);
final StreamGraph streamGraph = context.getStreamGraph();
final String slotSharingGroup = context.getSlotSharingGroup();
final int transformationId = transformation.getId();
final ExecutionConfig executionConfig = streamGraph.getExecutionConfig();
streamGraph.addOperator(
transformationId, // nodeid
slotSharingGroup, // 共享槽
transformation.getCoLocationGroupKey(),
operatorFactory, // 算子工厂
inputType, // 上游的 transform
transformation.getOutputType(), // 下游的 transform
transformation.getName()); // 算子名
if (stateKeySelector != null) {
TypeSerializer<?> keySerializer = stateKeyType.createSerializer(executionConfig);
streamGraph.setOneInputStateKey(transformationId, stateKeySelector, keySerializer);
}
int parallelism =
transformation.getParallelism() != ExecutionConfig.PARALLELISM_DEFAULT
? transformation.getParallelism()
: executionConfig.getParallelism();
streamGraph.setParallelism(transformationId, parallelism);
streamGraph.setMaxParallelism(transformationId, transformation.getMaxParallelism());
final List<Transformation<?>> parentTransformations = transformation.getInputs();
checkState(
parentTransformations.size() == 1,
"Expected exactly one input transformation but found "
+ parentTransformations.size());
// 获取上游的 Transformation ,从已转换的Transformation里找到对应的id
for (Integer inputId : context.getStreamNodeIds(parentTransformations.get(0))) {
// 将每个父ID到当前Transformation的边关系添加到图中
streamGraph.addEdge(inputId, transformationId, 0);
}
// 返回当前的 节点ID
return Collections.singleton(transformationId);
}这里通过streamGraph.addOperator将每个Transformation添加到了streamGraph,在内部创建了StreamNode,并且将StreamNode添加到StreamNode集合中。
另外通过streamGraph.addEdge,从以完成转换的map中获取到上游Transformation的Ids,将上游Id和当前Id的边关系添加到streamGraph中,最终将Transformation和NodeId添加到已转换的Transformation集合中。
总结一下,在generate过程中主要是将每个Transformation实例成streamNode,两个Node之间的上下游关系实例成streamEdge,同时设置了每个Node的资源配置,上下游序列化方式,检查点等配置项。
个人总结可能会有理解不到位的地方,欢迎指正~















 2074
2074

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









