






JVM作用
负责将字节码加载到内存中(运行时数据区)
负责存储数据
把字节码翻译为机器码,执行
垃圾回收
JVM组成部分
1.类加载器(负责加载字节码文件)
2.运行时数据区(存储运行时数据,堆,java虚拟机栈(运行java自己的方法),方法区,程序计数器,本地方法栈)
3.执行引擎(更加的底层,把字节码翻译为机器码)
4.本地方法接口
5.垃圾回收
类加载器
作用:负责从硬盘或者网络中加载字节码信息,加载到内存中(运行时数据区的方法中)
类加载的过程
加载:
使用io读取字节码文件
转换并存储,为每一个类创建一个Class类的对象
储存在方法区中
链接:(验证,准备,解析)
验证: 对字节码文件格式进行验证,文件是否被污染.
对基本的语法格式进行验证.
准备: 为静态的变量进行内存分配
public static int value = 123;value 在准备阶段后的初始值是 0,而不是 123
静态常量在编译期间就初始化
解析: 将符号引用转为直接引用.
将字节码中的表现形式,转为内存中表现(内存地址)
初始化
类的初始化,为类中的定义的静态变量进行赋值
public static int value = 123;value 在初始化阶段后值是 123.
类什么时候会被加载(初始化)
1.在类中运行main方法
2.创建对象
3.使用类中的静态变量,静态方法
4.反射 Class.forName("类的地址");
5.子类被加载
以下两种情况类不会被初始化:
static final int b = 20; 编译期间赋值的静态常量
System.out.println(User.b);
User[] users = new User[10]; 作为数组类型
类加载器
具体的负责加载类的一些代码
1.引导类加载器,用从c/c++语言开发的,jvm底层的开发语言,负责加载java核心类库。与java语言无关。
2.扩展类加载器:java语言编写的,由 sun.misc.Launcher$ExtClassLoader 实现,继承ClassLoader类. 从 JDK 系统安装目录的 jre/lib/ext 子目录(扩展目录)下加载类库 。
3.应用程序类加载器
Java语言编写的,由sun.misc.Launcher$AppClassLoader实现,派生于ClassLoader类。
4.自定义类加载器
双亲委派机制
加载一个类时,先委托给父类加载器加载,如果父加载器没有找到,继续向上级委托,直到引导类加载器.父级找到就返回,父级如果最终没有找到,就委派给子级加载器,最终没有找到,报ClassNotFoundException再向下一层层寻找,为了确保先加载系统类
双亲委派机制,是java提供的类加载的规范,但不是强制不能改变的.
我们可以通过自定义的类加载器,改变加载方式.
打破双亲委派机制
可以通过继承ClassLoader类,重写loadClass/findClass方法,实现自定义的类加载
典型的tomcat中,加载部署在tomcat中的项目时,就使用的是自己的类加载器
运行时数据区
1.程序计数器
是一块很小的内存空间,用来记录每个线程运行的指令位置,是线程私有的,每个线程都拥有一个程序计数器,生命周期与线程一致是运行时数据区中,唯一一个不会出现内存溢出的空间,运行速度最快.
2.本地方法栈
用来运行本地方法的区域
是线程私有
空间大小可以调整
可能会出现栈溢出
3.java栈
基本作用特征:
栈是运行单位,管理方法的调用运行
是用来运行java方法的区域.
可能会出现栈溢出.
是线程私有的.
运行原理:
先进后出的结构
最顶部的称为当前栈帧,
栈帧结构:
一个栈帧包含:
局部变量表(存储在方法中声明的变量)
操作数栈(实际计算运行)
动态链接
void A(){
B();//B方法的地址
}
方法返回地址
4.堆
基本作用特征
是存储空间,用来存储对象,是内存空间最大的一块儿区域,
在jvm启动时就被创建,大小可以调整(jvm调优)
本区域是存在垃圾回收的.是线程共享的区域
堆空间的分区:
年轻代(新生区/新生代)
伊甸园区(对象刚刚创建存储在此区域)
幸存者1区
幸存者2区
老年代(老年区)
为什么要分区
可以根据对象的存活的时间放在不同的区域,可以区别对待.
频繁回收年轻代,较少回收老年代.
创建对象,在堆内存中分布
1.新创建的对象,都存储在伊甸园区
2.当垃圾回收时,将伊甸园中垃圾对象直接销毁,将存活的对象,移动到幸存者1区,
3.之后创建的新对象还是存储在伊甸园区,再次垃圾回收到来时,将伊甸园中的存活对象移动到幸存者2区,
同样将幸存者1区的存活对象移动到幸存者2区,每次保证一个幸存者区为空的,相互转换.
4.每次垃圾回收时,都会记录此对象经历的垃圾回收次数,当一个对象经历过15次回收,仍然存活,就会被移动到老年代
垃圾回收次数,在对象头中有一个4bit的空间记录 最大值只能是15,
5.老年区回收次数较少,当内存空间不够用时,才会去回收老年代.
堆空间的配置比例
默认的新生代与老年代的比例: 1:2 可以通过 -XX:NewRatio=2 进行设置
如果项目中生命周期长的对象较多,就可以把老年代设置更大.
在新生代中,伊甸园和两个幸存者区比例: 8:1:1
可以通过-XX:SurvivorRatio=8 进行设置
对象垃圾回收的年龄 -XX:MaxTenuringThreshold=<N>
分代收集思想 Minor GC、Major GC、Full GC
对年轻代进行垃圾回收称为 Minor GC /yong GC 是频繁进行的回收
对老年代进行垃圾回收称为 Major GC / old gc 回收的次数较少
Full GC 整堆收集 尽量避免
System.gc();时 程序员几乎不用
老年区空间不足
方法区空间不足
堆空间的参数设置
官方文档
https://docs.oracle.com/javase/8/docs/technotes/tools/unix/java.html
字符串常量池
在jdk7之后,将字符串常量池的位置从方法区转移到了堆空间中,
因为方法区的回收在整堆收集时发生,回收频率低,
堆空间回收频率高.
5.方法区
作用: 主要用来存储加载的类信息, 以及即时编译期编译后的信息, 以及运行时常量池
特点: 在jvm启动时创建,大小也是可以调整, 是线程共享,也会出现内存溢出.
方法区,堆,栈交互关系
方法区存储类信息(元信息)
堆中存储创建的对象
栈中存储对象引用
方法区大小设置
-XX:MetaspaceSize 设置方法区的大小
windows jdk默认的大小是21MB
也可以设置为-XX:MaxMetaspaceSize 的值是-1,级没有限制. 没有限制 就可以使用计算机内存
可以将初始值设置较大一点,减少了FULL GC发生
方法区的内部结构
类信息
以及即时编译期编译后的信息,
以及运行时常量池(指的就是类中各个元素的编号)
方法区的垃圾回收
在FULL GC时方法区发生垃圾回收.
主要是回收类信息, 类信息回收条件比较苛刻,满足以下3点即可:
1.在堆中,该类及其子类的对象都不存在了
2.该类的类加载器不存在了
3.该类的Class对象不存在了
也可以认为类一旦被加载就不会被卸载了.
特点总结
程序计数器,java栈,本地栈是线程私有的
程序计数器不会出现内存溢出
java栈,本地栈,堆,方法区可能会出现内存溢出
java栈,本地栈,堆,方法区大小是可以调整的
堆,方法区是线程共享的,是会出现垃圾回收的
本地方法接口
什么是本地方法
用native关键字修饰的方法称为一个本地方法, 没有方法体.
hashCode();
为什么用本地方法
java语言需要与外部的环境进行交互(例如需要访问内存,硬盘,其他的硬件设备),直接访问操作系统的接口即可.
java的jvm本身开发也是在底层使用到了C语言
执行引擎
作用: 将加载到内存中的字节码(不是直接运行的机器码), 解释/编译为不同平台的机器码.
.java ---编译-->.class 在开发期间,由jdk提供的编译器(javac)进行源码编译 (前端编译)
.class(字节码)----解释/编译---> 机器码 (后端编译,在运行时,由执行引擎完成的)
解释器: 将字节码逐行解释执行, 效率低
编译器(JIT just in time 即时编译器): 将字节码编译,缓存起来,执行更高效, 不会立即使用编译器
将一些频繁执行的热点代码进行编译,并缓存到方法区中,以后执行效率提高了.
程序启动后,先使用解释器立即执行,省去了编译时间
程序运行一段时间后,对热点编译缓存,提高后续执行效率
采用的解释器和编译器结合的方案.
垃圾回收
概述
java是支持自动垃圾回收,有些语言不支持需要手动.
自动垃圾回收不是java语言首创的
垃圾回收关系的问题:
哪些区域需要回收 堆 方法区
什么时候回收
如何回收
java的自动垃圾回收经过长时间的发展,已经非常强大.
什么样的对象是垃圾
在运行过程中,没有被任何引用 指向的对象,被称为垃圾对象.
为什么需要 GC
如果不及时清理这些垃圾对象,会导致内存溢出.
在回收时,还可以将内存碎片进行整理.(数组必须是连续空间的)
内存溢出和内存泄漏
内存溢出: 经过垃圾回收后,内存中仍然无法存储新创建的对象,内存不够用溢出.
内存泄漏: IO流 close jdbc连接 close 没有关闭,生命周期很长的对象, 一些已经不用的对象,但是垃圾回收器不能判定为垃圾,这些对象就默默的占用的内存,称为内存泄漏,大量的此类对象存在,也是导致内存溢出的原因.
自动内存管理
好处: 解放程序员, 对内存管理更合理,自动化.
不好的: 对程序员管理内存的能力降低了, 解决问题能力变弱了, 不能调整垃圾回收的机制
垃圾回收相关算法
标记阶段
作用: 判断对象是否是垃圾对象, 是否有引用指向对象.
相关的标记算法: :引用计数算法和可达性分析算法
引用计数算法(在现代的jvm中并没有被使用).
有个计数器来记录对象的引用数量
String s1 = new String("aaa");
String s2 = s1; //有两个引用变量指向aaa对象
s2 = null; -1
s1 = null; -1
缺点:
需要维护计数器,占用空间,频繁操作需要时间开销
无法解决循环引用问题. 多个对象之间相互引用,没有其他外部引用指向他们,计数器都不为0,不能回收,产生内存泄漏.例如:循环引用,例如A中引用B,B中引用A,导致对象一直存在,无法销毁
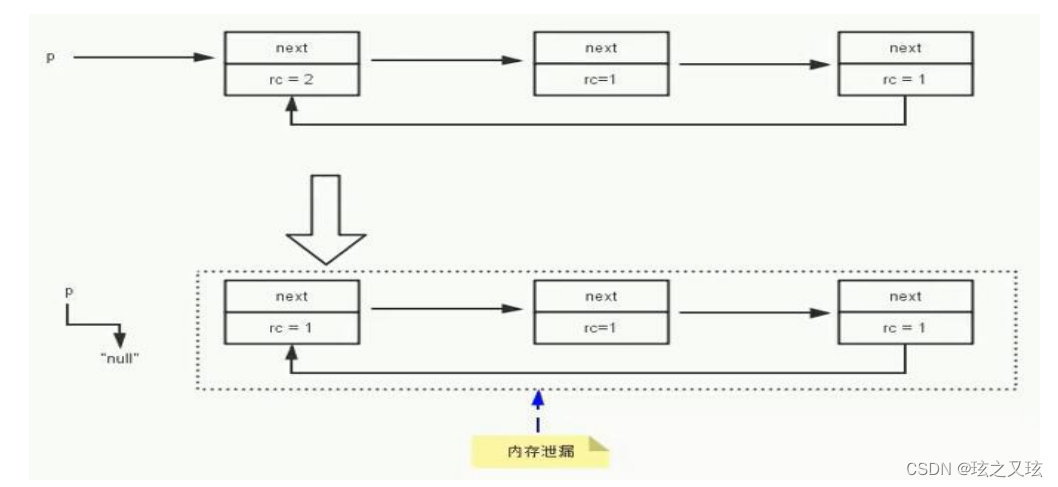
可达性分析算法/根搜索算法
实现思路: 从一些为根对象(GCRoots)的对象出发去查找,与根对象直接或间接连接的对象就是存活对象,不与根对象引用链连接的对象就是垃圾对象.
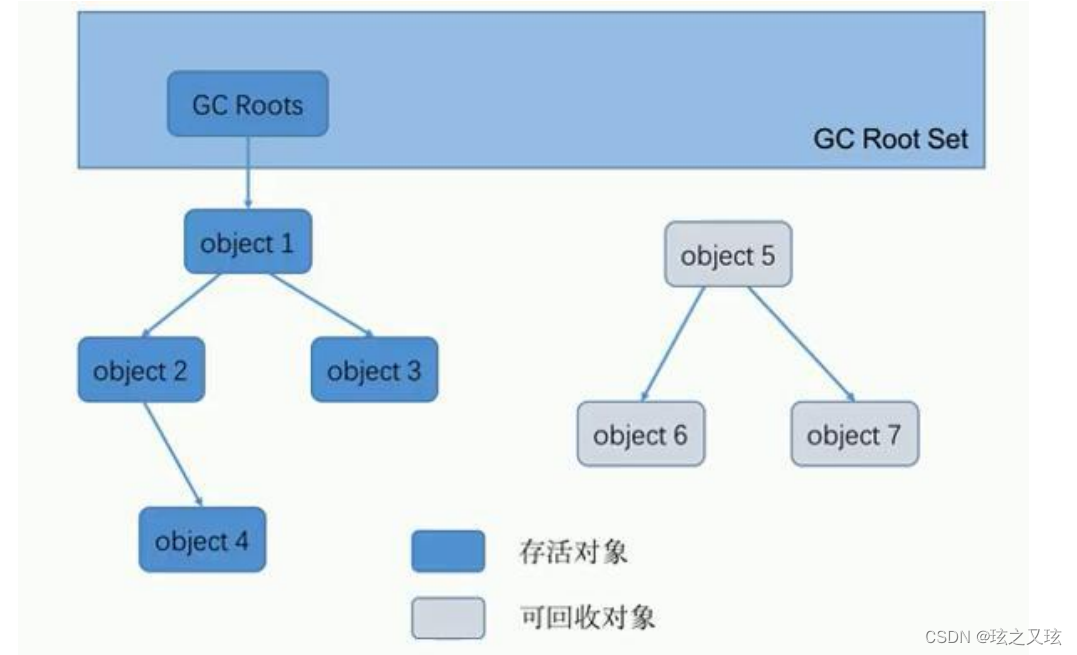
GC Roots 可以是哪些元素?
在虚拟机栈中被使用的.
在方法中存储的静态成员指向的对象
作为同步锁使用的 synchronized
在虚拟机内部使用的对象
对象的 finalization 机制
当一个对象被标记为垃圾后,在真正被回收之前,会调用一次Object类中finalize(). 是否还有逻辑需要进行处理.
自己不要在程序中调用finalize(),留给垃圾回收器调用.
有了finalization机制的存在,在虚拟机中把对象状态分为3种:
1.可触及的 不是垃圾,与根对象连接的
2.可复活的 判定为垃圾了,但是还没有调用finalize(),(在finalize()中对象可能会复活)
3.不可触及的: 判定为垃圾了,finalize()也被执行过了,这种就是必须被回收的对象
public class CanReliveObj {
public static CanReliveObj obj;//类变量,属于 GC Root
//此方法只能被调用一次
@Override
protected void finalize() throws Throwable {
//super.finalize();
System.out.println("调用当前类重写的finalize()方法");
obj = this;//当前待回收的对象在finalize()方法中与引用链上的一个对象obj建立了联系
}
public static void main(String[] args) {
try {
obj = new CanReliveObj();
// 对象第一次成功拯救自己
obj = null;
System.gc();//调用垃圾回收器,触发FULL GC 也不是调用后立刻就回收的,因为线程的执行权在操作系统
System.out.println("第1次 gc");
// 因为Finalizer线程优先级很低,暂停2秒,以等待它
Thread.sleep(2000);
if (obj == null) {
System.out.println("obj is dead");
} else {
System.out.println("obj is still alive");
}
System.out.println("第2次 gc");
// 下面这段代码与上面的完全相同,但是这次自救却失败了
obj= null;
System.gc();
// 因为Finalizer线程优先级很低,暂停2秒,以等待它
Thread.sleep(2000);
if (obj == null) {
System.out.println("obj is dead");
} else {
System.out.println("obj is still alive");
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}
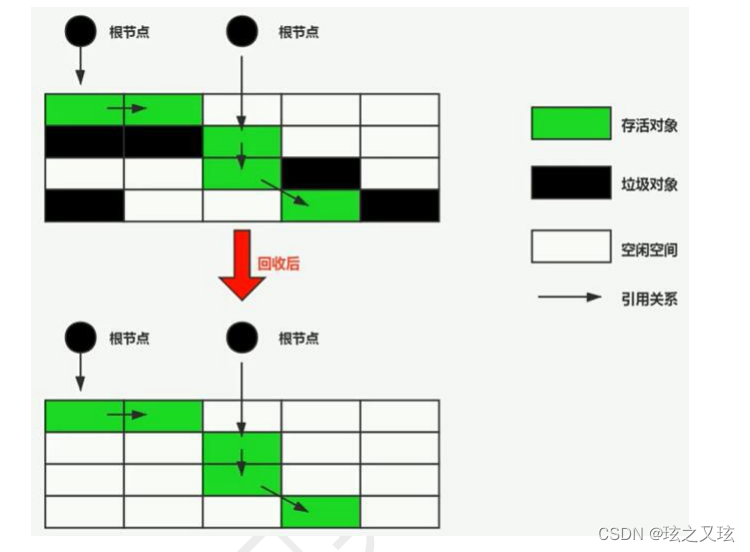
}标记--复制算法:
将内存分为大小相等的两份空间, 把当前使用的空间中存活的对象 复制到另一个空间中, 将正在使用的空间中垃圾对象清除.
优点: 减少内存碎片
缺点: 如果需要复制的对象数量多,效率低.
适用场景: 存活对象少 新生代适合使用标记复制算法
标记-清除算法
清除不是真正的把垃圾对象清除掉,
将垃圾对象地址维护到一个空闲列表中,后面有新对象到来时,覆盖掉垃圾对象即可.
特点:
实现简单
效率低,回收后有碎片产生
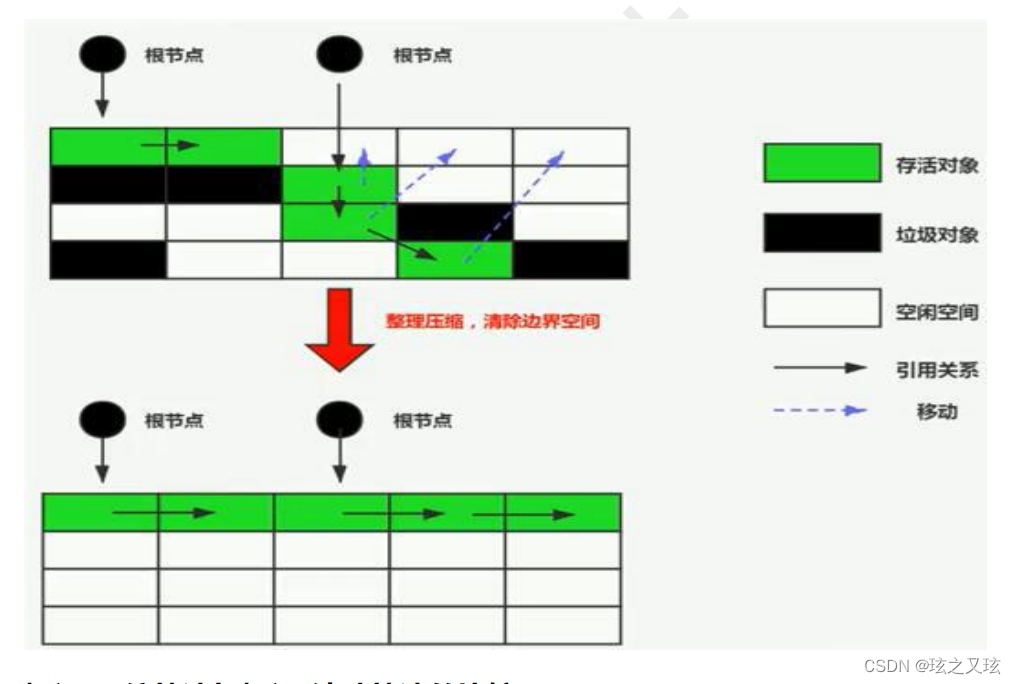
标记-压缩算法(标记-整理)
老年代不在使用复制算法,标记算法可以使用但有缺点,所以通过改变,从而使用新的算法
垃圾回收器
垃圾收集器是垃圾回收的实际实现者,垃圾回收算法是方法论.
垃圾回收器分类
按照线程数量:
单线程垃圾回收器:Serial ,Serial old
多线程垃圾回收器:Paraller
按照工作模式分为:
独占式:垃圾回收线程执行时,其他线程暂停
并发式:垃圾回收线程可以和用户线程同时执行
按照工作的内存区间:
年轻代垃圾回收器
老年代垃圾回收器
垃圾回收器的性能指标
暂停的时间
吞吐量
回收的速度
占用内存的大小
CMS垃圾回收器
Concurrent Mark Sweep 并发标记清除
支持垃圾回收线程与用户线程并发(同时)执行
初始标记: 独占式的暂停用户线程
并发标记: 垃圾回收线程与用户线程并发(同时)执行
重新标记: 独占式的暂停用户线程
并发清除: 垃圾回收线程与用户线程并发(同时)执行 进行垃圾对象的清除
优点: 可以作到并发收集
弊端: 使用标记清除算法,会产生内存碎片, 并发执行影响到用户线程,无法处理浮动垃圾
三色标记:
由于cms有并发执行过程,所以在标记垃圾对象时有不确定性.
所以在标记时,将对象分为3种颜色(3种状态)
黑色: 例如GCRoots 确定是存活的对象
灰色: 在黑色对象中关联的对象,其中还有未扫描完的, 之后还需要再次进行扫描
白色: 与黑色,灰色对象无关联的, 垃圾收集算法不可达的对象
标记过程:
1.先确立GCRoots, 把GCRoots标记为黑色
2.与GCRoots关联的对象标记为灰色
3.再次遍历灰色,灰色变为黑色,灰色下面有关联的对象,关联的对象变为灰色
4.最终保留黑色,灰色, 回收白色对象
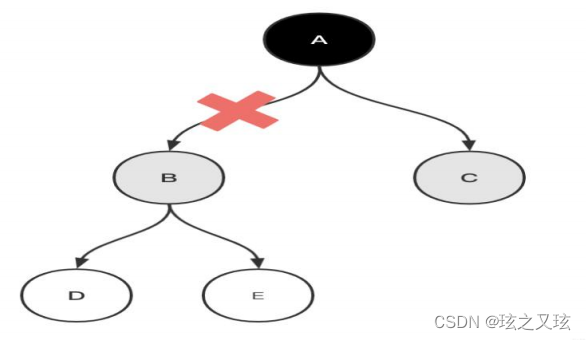
错标问题
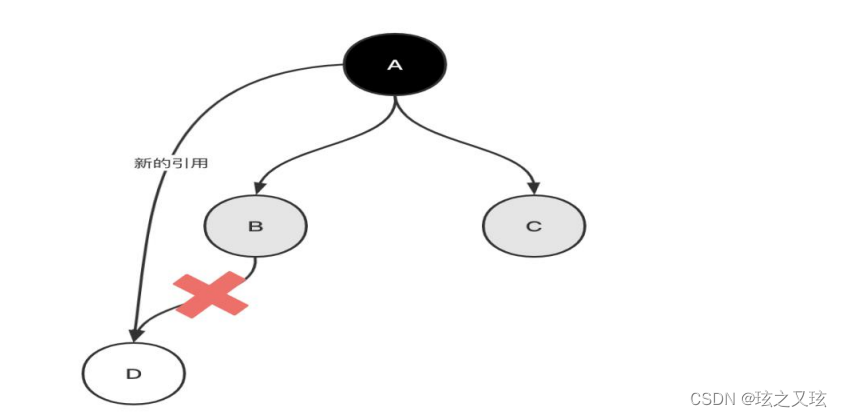
漏标问题
G1(Garbage-First) 垃圾优先
将堆内存各个区又分成较小的多个区域, 对这些个区域进行监测,对某个区域中垃圾数量大的区域优先回收.也是并发收集的.















 540
540











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









