






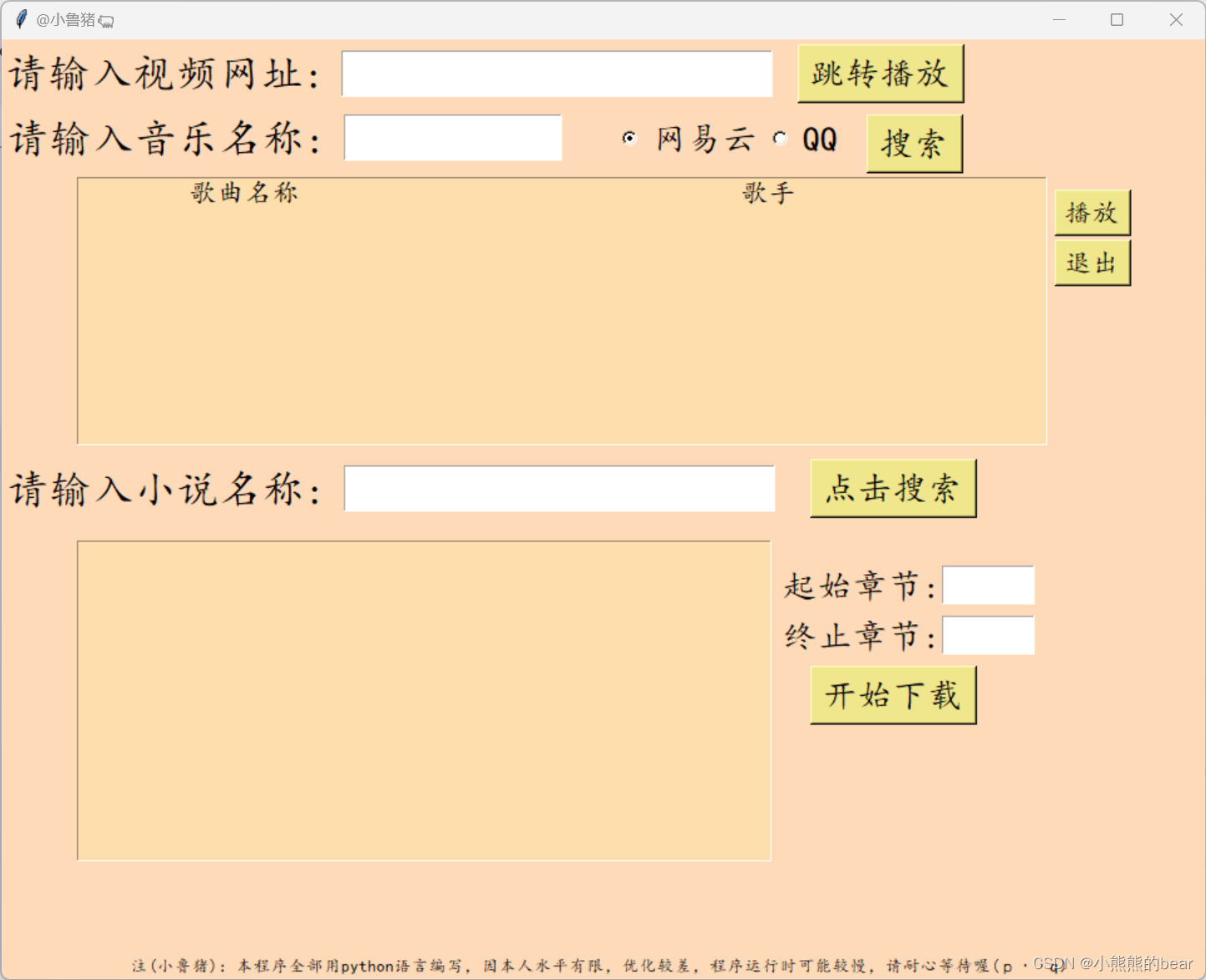
截图如下:
import time
from tkinter import *
from selenium import webdriver
from selenium.webdriver.chrome.options import Options # => 引入Chrome的配置
from lxml import etree
# 配置
ch_options = Options()
# ch_options.add_argument("--headless") # => 为Chrome配置无头模式
'''
jsonplayer :https://jx.jsonplayer.com/player/?url=
ok :https://okjx.cc/?url=
BL :https://svip.bljiex.cc/?v= yzmplayer-icon yzmplayer-play-icon
首先采用json解析,若失败,其次选用ok解析,若失败返回报错
'''
def shipin_bofang():
global wb
url = shipin_entry.get()
j_url = "https://jx.jsonplayer.com/player/?url=" + url
o_url = "https://okjx.cc/?url=" + url
try:
wb = webdriver.Chrome()
wb.get(j_url)
time.sleep(1)
wb.find_element_by_xpath('//div[@class = "yzmplayer-danmaku"]').click()
wb.find_element_by_xpath('//button[@id = "lottie-full"]').click()
except:
try:
s.set('')
print('已切换线路进行解析')
wb.get(o_url)
iframe1 = wb.find_element_by_xpath('//iframe')
wb.switch_to.frame(iframe1)
iframe2 = wb.find_element_by_xpath('//iframe')
wb.switch_to.frame(iframe2)
iframe3 = wb.find_element_by_xpath('//iframe')
wb.switch_to.frame(iframe3)
wb.find_element_by_xpath('//button[@id = "bofang"]').click()
wb.find_element_by_xpath('//button[@data-balloon = "全屏"]/span').click()
except:
s.set("解析失败")
# 创建图形化视频界面
root = Tk()
root.title("@小鲁猪🐖")
root.config(bg='peachpuff')
root.geometry('960x750')
root.rowconfigure(1, minsize=4)
root.columnconfigure(1, minsize=4)
font = ("楷体", 25)
s = StringVar()
# 电影注意事项 text='注意:由于不同的网络情况可能有延迟,多刷新几次即可@_@'
# 视频标签和输入框的设置
shipin_label = Label(root, text='请输入视频网址:', font=font, bg='peachpuff', justify=LEFT)
shipin_entry = Entry(root, font=font, fg='blue', justify=LEFT, textvariable=s)
shipin_label.grid(row=2, column=0)
shipin_entry.grid(row=2, column=1, padx=10)
shipin_bofang_button = Button(root, text='跳转播放', font=('楷体', 20), bg='khaki', fg='black', justify=CENTER,
command=lambda: shipin_bofang())
shipin_bofang_button.grid(row=2, column=10, padx=10)
'''
解析音乐
网易:https://sunpma.com/other/musicss/?name=victory&type=netease
QQ:https://sunpma.com/other/musicss/?name=victory&type=qq
'''
class Music:
wb1 = webdriver.Chrome(chrome_options=ch_options)
def music_sousuo(self):
name = music_entry.get()
music_url_0 = f'https://music.liuzhijin.cn//?name={name}&type=netease'
music_url_1 = f'https://music.liuzhijin.cn//?name={name}&type=qq'
a = var.get()
if a == 0:
self.wb1.get(music_url_0)
time.sleep(6)
et = etree.HTML(self.wb1.page_source)
singer_name = et.xpath('//div[@class = "aplayer-list"]/ol/li/span[4]/text()')
music_name = et.xpath('//div[@class = "aplayer-list"]/ol/li/span[3]/text()')
del singer_name[3:]
del music_name[3:]
#打印数据
print(singer_name)
for i in range(3):
music_text.insert(f'{i+2}.0', f'\t{music_name[i]}\t\t\t\t\t{singer_name[i]}\n')
else:
self.wb1.get(music_url_1)
time.sleep(3)
et = etree.HTML(self.wb1.page_source)
singer_name = et.xpath('//div[@class = "aplayer-list"]/ol/li/span[4]/text()')
music_name = et.xpath('//div[@class = "aplayer-list"]/ol/li/span[3]/text()')
del singer_name[3:]
del music_name[3:]
for i in range(3):
music_text.insert(f'{i + 2}.0', f'\t{music_name[i]}\t\t\t\t\t{singer_name[i]}\n')
def music_bofang(self):
self.wb1.find_element_by_xpath('//button[@class = "aplayer-icon aplayer-icon-play"]').click()
def music_stop(self):
self.wb1.get('https://sunpma.com/other/musicss')
music = Music()
# 创建图形化音乐界面
var = IntVar()
music_label = Label(root, text="请输入音乐名称: ", font=font, bg='peachpuff') # 音乐label
music_entry = Entry(root, font=font, fg='blue', width=10, justify=CENTER) # 音乐名字输入框
rd1 = Radiobutton(root, text='网易云', font=('楷体', 20), bg='peachpuff', variable=var, value=0)
rd2 = Radiobutton(root, text='QQ', font=('楷体', 20), bg='peachpuff', variable=var, value=1)
music_sousuo_button = Button(root, text='搜索', font=('楷体', 20), bg='khaki', fg='black', justify=CENTER,
command=lambda: music.music_sousuo())
# 创建多行文本框
music_text = Text(width=70, height=10, font=('楷体', 16), bg='navajowhite')
# 创建播放按钮
music_bofang_button = Button(root, text='播放', font=('楷体', 16), bg='khaki', fg='black', justify=CENTER,
command=lambda: music.music_bofang())
music_stop_button = Button(root, text='退出', font=('楷体', 16), bg='khaki', fg='black', justify=CENTER,
command=lambda: music.music_stop())
rd1.place(x=490, y=60)
rd2.place(x=610, y=60)
music_sousuo_button.place(x=690, y=60)
music_label.place(x=1, y=60)
music_entry.place(x=273, y=60)
music_text.place(x=60, y=110)
music_text.insert('1.0', '\t歌曲名称\t\t\t\t\t歌手\n')
music_bofang_button.place(x=840, y=120)
music_stop_button.place(x=840, y=160)
# 定义获取文本的类和各类变量
zhangjie_name = [] # 各章名称
zhangjie_url = [] # 各章url
url = ''
class Txt:
wb = webdriver.Chrome(chrome_options=ch_options)
# 获取对应小说的url
def get_url(self):
global url
try:
self.wb.get(f'http://www.81zw.com.cn/dfhdfhdfhfhddfh.php?ie=gbk&q={txt_entry.get()}')
time.sleep(2)
et = etree.HTML(self.wb.page_source)
url_list = et.xpath('//div[@class = "type_show"]//h4/a/text()')
for i in url_list:
if i == txt_entry.get():
txt_text.insert('1.0', '搜索成功 ヾ(≧▽≦*)o!\n')
else:
continue
n = url_list.index(txt_entry.get()) + 1
url = 'http://www.81zw.com.cn' + et.xpath(f'//div[@class = "type_show"]/div[{n}]//h4/a/@href')[0]
except:
self.get_url()
# 根据输入获取小说对应的起始终止章节名称和url
def get_url_name(self):
global zhangjie_name
global zhangjie_url
self.wb.get(url)
time.sleep(1)
et = etree.HTML(self.wb.page_source)
'''
首先得到总url,在处理
'''
zhangjie_url_0 = et.xpath('//div[@class = "listmain"]/dl/dd/a/@href')
zhangjie_name = et.xpath('//div[@class = "listmain"]/dl/dd/a/text()')
del zhangjie_url_0[int(txt_end_entry.get()):]
del zhangjie_url_0[0:int(txt_start_entry.get()) - 1]
del zhangjie_name[int(txt_end_entry.get()):]
del zhangjie_name[0:int(txt_start_entry.get()) - 1]
for i in range(len(zhangjie_url_0)):
zhangjie_url.append(f'http://www.81zw.com.cn{zhangjie_url_0[i]}')
# 获取章节内容并保存
def get_text(self):
self.get_url_name()
n = 0
for i in zhangjie_url:
self.wb.get(i)
time.sleep(3)
et = etree.HTML(self.wb.page_source)
zhangjie_text0 = et.xpath('//div[@id = "content"]/text()')
zhangjie_text = []
for j in zhangjie_text0:
a = ''.join(j).strip()
zhangjie_text.append(a)
with open(f'{txt_entry.get()}.txt', 'a+', encoding='utf-8') as f:
f.write(zhangjie_name[n])
f.write('\n')
for i in zhangjie_text:
if i != '':
f.write(i)
f.write('\n')
txt_text.insert(f'{n + 2}.0', f'{zhangjie_name[n]}爬取完成\n')
n = n + 1
t = Txt()
# 创建小说下载界面
txt_label = Label(root, text="请输入小说名称: ", font=font, bg='peachpuff')
txt_entry = Entry(root, font=font, fg='blue', width=20, justify=CENTER)
txt_sousuo_button = Button(root, text='点击搜索', font=('楷体', 20), bg='khaki', fg='black', justify=CENTER,
command=lambda: t.get_url())
txt_text = Text(width=50, height=12, font=('楷体', 16), bg='navajowhite')
txt_start_label = Label(root, text="起始章节: ", font=('楷体', 20), bg='peachpuff')
txt_end_label = Label(root, text="终止章节: ", font=('楷体', 20), bg='peachpuff')
txt_start_entry = Entry(root, font=('楷体', 20), fg='blue', width=5, justify=CENTER)
txt_end_entry = Entry(root, font=('楷体', 20), fg='blue', width=5, justify=CENTER)
txt_xiazai_button = Button(root, text='开始下载', font=('楷体', 20), bg='khaki', fg='black', justify=CENTER,
command=lambda: t.get_text())
warn = Label(root,
text='注(小鲁猪):本程序全部用python语言编写,因本人水平有限,优化较差,程序运行时可能较慢,请耐心等待喔(p・・q)',
font=('楷体', 10)
, bg='peachpuff')
warn.place(x=100, y=730)
txt_label.place(x=1, y=340)
txt_entry.place(x=273, y=340)
txt_sousuo_button.place(x=645, y=335)
txt_text.place(x=60, y=400)
txt_start_label.place(x=620, y=420)
txt_start_entry.place(x=750, y=420)
txt_end_label.place(x=620, y=460)
txt_end_entry.place(x=750, y=460)
txt_xiazai_button.place(x=645, y=500)
def _quit():
music.wb1.quit()
root.quit()
root.destroy()
root.protocol("WM_DELETE_WINDOW", _quit)
root.mainloop()


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









