







*和 + 限定符都是贪婪的,因为它们会尽可能多的匹配文字,只有在它们的后面加上一个 ? 就可以实现非贪婪或最小匹配。

定位符
\b:匹配一个单词边界,即字与空格间的位置
\B:非单词边界匹配
\b 字符的位置是非常重要的。如果它位于要匹配的字符串的开始,它在单词的开始处查找匹配项。如果它位于字符串的结尾,它在单词的结尾处查找匹配项。
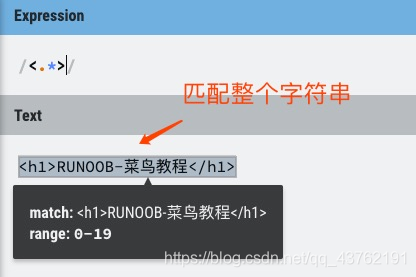
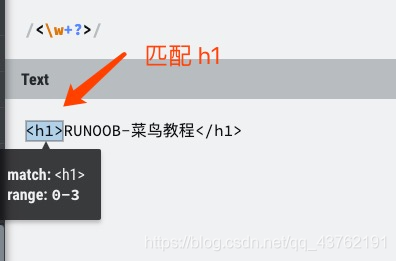
下面的表达式匹配单词 Chapter 的开头三个字符,因为这三个字符出现在单词边界后面:
/\bCha/
下面的表达式匹配单词 Chapter 中的字符串 ter,因为它出现在单词边界的前面:
/ter\b/
修饰符
下表列出了正则表达式常用的修饰符:

存在即合理嘛。
使用方式如下:

元字符串
\d:匹配一个数字字符。等价于 [0-9]。
\D:匹配一个非数字字符。等价于 [^0-9]。
\w:匹配字母、数字、下划线。等价于’[A-Za-z0-9_]'。
\W:匹配非字母、数字、下划线。等价于 ‘[^A-Za-z0-9_]’。
运算符优先级
下表从最高到最低说明了各种正则表达式运算符的优先级顺序:
首先,先调用模块re。
先给个模板函数吧
def get_re(re_rule,text):
t = re.search(re_rule, text)
if t:
#t = t.group(1)
return t
else:
print(“没有获取到有效内容”)
return t
应该能看得懂怎么用吧,我就不写注释啦。
现在让我们对着这个模板看:
re.search方法
re.search 扫描整个字符串并返回第一个成功的匹配。
re.search(pattern, text, flags=0)
参数释义:
pattern:正则规则
text:待处理文本
flags:修饰符
这个修饰符嘛,就上面那块儿大小写啊啥的。
匹配成功re.search方法返回一个匹配的对象,否则返回None。
re.group(s)方法
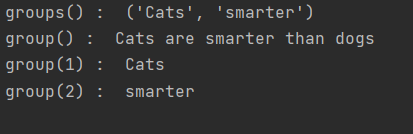
我们可以使用group(num) 或 groups() 匹配对象函数来获取匹配表达式。
group(num=0):匹配的整个表达式的字符串,group() 可以一次输入多个组号,在这种情况下它将返回一个包含那些组所对应值的元组。
groups():返回一个包含所有小组字符串的元组,从 1 到 所含的小组号。
import re
line = “Cats are smarter than dogs”
searchObj = re.search(r’(.) are (.?) .*', line, re.M | re.I)
if searchObj:
print("groups() : ", searchObj.groups())
print("group() : ", searchObj.group())
print("group(1) : ", searchObj.group(1))
print("group(2) : ", searchObj.group(2))
你悟到了吗?
re.sub方法
re.sub用于替换字符串中的匹配项。
sub(pattern, repl, string, count=0, flags=0)
repl: 替换的字符串,可以是函数
string: 要被查找替换的字符串
count: 模式匹配后替换的最大次数,默认0表示替换所有的匹配,可选
演示一下啊,替换掉某些不该出现的字符:
import re
content = “do something fuck you”
rs = re.sub(r’fuck’, “*”, content)
print(rs)
这个太小儿科了啊,呐,前面说,这个repl可以是函数,是怎么肥四呢?
学过C语言的就知道这不就是函数指针嘛。
def calcWords(matched):
num = len(matched.group())
return str(num * ‘*’)
content = “do something fuck you”
rs = re.sub(r’fuck’, calcWords, content)
print(rs)
看这个函数,可能要有不少人犯嘀咕了,这个calcWords函数里面的参数matched是哪里来的?
据我大胆猜测啊,本来应该是这么写的:
def calcWords(partten,content):
num = len(serch(partten,content).group())
return str(num * ‘*’)
content = “do something fuck you”
rs = re.sub(r’fuck’, calcWords, content)
//pattern和content全部沦为calcWords的参数,这就是函数指针
print(rs)
不过Python嘛,一贯的简短,所以就写成了上面那样。
findall方法
在字符串中找到正则表达式所匹配的所有子串,并返回一个列表,如果没有找到匹配的,则返回空列表。
findall(pattern,string)
小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数初中级Java工程师,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新Java开发全套学习资料》送给大家,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。


由于文件比较大,这里只是将部分目录截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频
如果你觉得这些内容对你有帮助,可以添加下面V无偿领取!(备注Java)

最后
看完美团、字节、腾讯这三家的面试问题,是不是感觉问的特别多,可能咱们又得开启面试造火箭、工作拧螺丝的模式去准备下一次的面试了。
开篇有提及我可是足足背下了1000道题目,多少还是有点用的呢,我看了下,上面这些问题大部分都能从我背的题里找到的,所以今天给大家分享一下互联网工程师必备的面试1000题。
注意不论是我说的互联网面试1000题,还是后面提及的算法与数据结构、设计模式以及更多的Java学习笔记等,皆可分享给各位朋友
互联网工程师必备的面试1000题
而且从上面三家来看,算法与数据结构是必备不可少的呀,因此我建议大家可以去刷刷这本左程云大佬著作的《程序员代码面试指南 IT名企算法与数据结构题目最优解》,里面近200道真实出现过的经典代码面试题。
,是不是感觉问的特别多,可能咱们又得开启面试造火箭、工作拧螺丝的模式去准备下一次的面试了。
开篇有提及我可是足足背下了1000道题目,多少还是有点用的呢,我看了下,上面这些问题大部分都能从我背的题里找到的,所以今天给大家分享一下互联网工程师必备的面试1000题。
注意不论是我说的互联网面试1000题,还是后面提及的算法与数据结构、设计模式以及更多的Java学习笔记等,皆可分享给各位朋友
[外链图片转存中…(img-pMQ8OAaA-1711168333722)]
互联网工程师必备的面试1000题
而且从上面三家来看,算法与数据结构是必备不可少的呀,因此我建议大家可以去刷刷这本左程云大佬著作的《程序员代码面试指南 IT名企算法与数据结构题目最优解》,里面近200道真实出现过的经典代码面试题。
[外链图片转存中…(img-hZHP5JZR-1711168333722)]


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









