







本篇主要讲解Pandas库的语法
一、查看数据
1.使用pandas打开CSV文件,请输出你看到的前6行数据
import pandas as pd
df = pd.read_csv('Nowcoder.csv',dtype=object)
#打开文件时需要添加dtype=object,防止年份信息读取为小数
print(df.head(6))
#print(Nowcoder.head()) 括号为空时,默认显示前5行数据2.不需要输出全部数据,请直接告诉我们这个数据集的大小,即行数与列数
import pandas as pd
df = pd.read_csv('Nowcoder.csv',dtype=object)
print(df.shape) 请注意这里的shape是没有带()的,类似的,df.info,df.size,df.dtypes也是
3.查看第10行的用户的全部信息
import pandas as pd
df = pd.read_csv('Nowcoder.csv', dtype=object)
print(df.iloc[9])索引是从0开始的,第十行是9
loc更适合于基于标签的索引和切片,而iloc更适合基于数字的索引和切片
4.查看第10~20行的用户的'Language'列的信息
import pandas as pd
Nowcoder = pd.read_csv('Nowcoder.csv',sep=',',dtype=object)
# print(Nowcoder['Language'].iloc[10:21])
# print(Nowcoder['Language'].loc[10:20])
# print(Nowcoder.iloc[10:21,5])
print(Nowcoder.loc[10:20,'Language'])5.牛牛想要获取该文件中每一列的列名,以及该文件包含了多少位用户的数据,请你帮他输出一下
import pandas as pd
data = pd.read_csv('Nowcoder.csv',sep=',',dtype = object)
print(list(data.columns))
print(data.shape[0])二、数据筛选
1.如果你想知道这份数据是不是所有列的信息都是有数据的,有没有哪些列的数据没有补全,请输出每列信息是否有为空值
import pandas as pd
Nowcoder = pd.read_csv('Nowcoder.csv',sep=',',dtype=object)
print(~Nowcoder.all())
#print(Nowcoder.isna().any())
#print(Nowcoder.isnull().all())
2.想知道哪些人经常使用Python这门语言,并且他们的其他信息是怎么样的,该怎么输出?
print(df.loc[df['Language'] == 'Python'])
print(df[df['Language'] == 'Python'])
print(df.query('Language=="Python"'))
#Python用户的成就值
print(df[df['Language']=='Python']['Achievement_value'])3.输入描述:
数据集直接从当前目录下的Nowcoder.csv文件中读取。
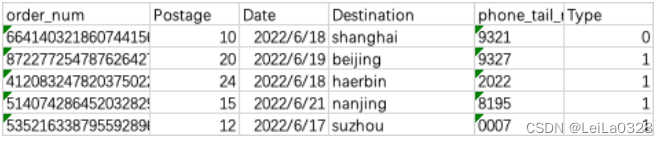
输出描述:
输出该数据集中日期为2022/6/18且类型为1的快递的目的地信息,包括行号。
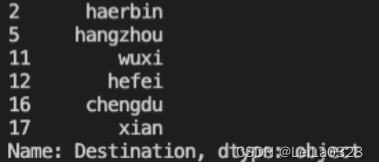
import pandas as pd
df = pd.read_csv('Nowcoder.csv',sep=',',dtype=object)
con = df[(df['Date'] == '2022/6/18') & (df['Type'] == '1')]
print(con['Destination'])三、分组合并
1.输入描述:数据集直接从当前目录下的Order.csv文件中读取。
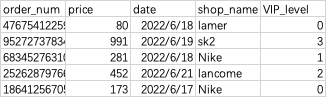
输出描述:首先输出各个等级的会员都平均消费了多少,不用处理小数位保留。
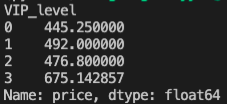
然后输出各个等级的会员光顾了多少家不同的店铺数量。
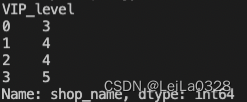
import pandas as pd
df = pd.read_csv('Order.csv',sep=',')
print(df.groupby(by=['VIP_level'])['price'].mean())
print(df.groupby(by=['VIP_level'])['shop_name'].value_counts())import pandas as pd
data=pd.read_csv("./Order.csv",dtype=object)
# 按照VIP等级分组
res= data.groupby("VIP_level")
# 输出每个VIP等级的消费均值
print(res.price.mean())
# 输出每个VIP等级去过的不同店个数
print(res.shop_name.nunique())2.数据集直接从当前目录下的Tk.csv文件和Shop.csv中读取。
Tk.csv

Shop.csv

输出描述:
输出粉丝数大于10000的用户消费过的店铺,输出包括行号。
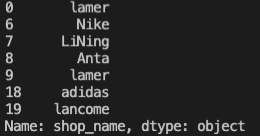
import pandas as pd
Tk = pd.read_csv('Tk.csv',sep=',')
Shop = pd.read_csv('Shop.csv',sep=',')
total_merge = pd.merge(Tk,Shop,on='ID')
print(total_merge.query('Fans>10000')['shop_name'])3.数据集直接从当前目录下的Order.csv文件中读取。
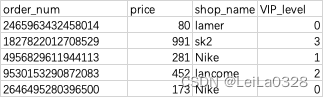
输出描述:
输出店铺的名字及各自的总销售额,按照销售额排序。
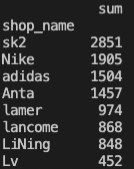
import pandas as pd
t1=pd.read_csv('Order.csv',sep=',')
#注意,agg中的聚合会替代被聚合列作为列名,故输出那里的排序是按 sum 进行排序
t2=t1.groupby(by='shop_name')['price'].agg(['sum'])
#True和False 注意都要首字母大写
print(t2.sort_values(by='sum',ascending=False))
















 2371
2371

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









