






一,初识Elasticsearch
1.1 概述
想认识ES(Elasticsearch)我们首先认识一下Lucence。 Lucene是一个Java语言的搜索引擎类库,是Apache公司的顶级项目,有DougCutting于1999年研发。大家可能会有疑问,这是个什么玩意,它跟ES有什么关系,它是一个Java语言的搜索引擎类库,所谓的类库就是就可以把它理解成是一套api的工具包,也就是用来实现搜索引擎的工具包。注意哦,它不是一个完整的搜索引擎,它只是一同api工具包帮我们实现搜素引擎的,那为什么我们不自己实现,要用Lucene呢。
Lucene官方地址:Apache Lucene - Welcome to Apache Lucene
这是因为这套工具包他有很多的优势,首先就是易扩展,也就是它的代码编码风格比较好,方便扩展一些更高级的功能。其次,最重要的是性能非常好,Lucene在做数据处理的时候采用了倒排索引的方式。因此目前主流的Java语言的搜索引擎都是基于Lucene来实现的,包括Solr,也包括接下来要学习的Elasticsearch。
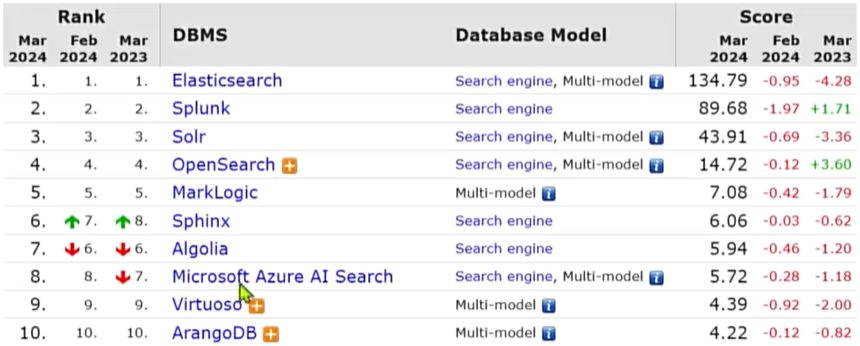
搜索引擎技术排名
- ElasticSeach:开源的分布式搜索引擎
- Splunk:商业项目
- Solr:Apache的开源搜索引擎
- 2004年Shay Banon基于Lucene开发了Compass
- 2010年Shay Banon重写了Compass,取名为Elasticsearch。
- Elasticsearch具备下列优势:
- 支持分布式,可水平扩展提
- 供Restful接口,可被任何语言调用
官方地址:Elastic — The Search AI Company | Elastic (目前最新的版本是:8.x.x)
注意:目前国内企业里面主流的还是6.x和7.x版本,我们接下去学习的也是7.x的版本
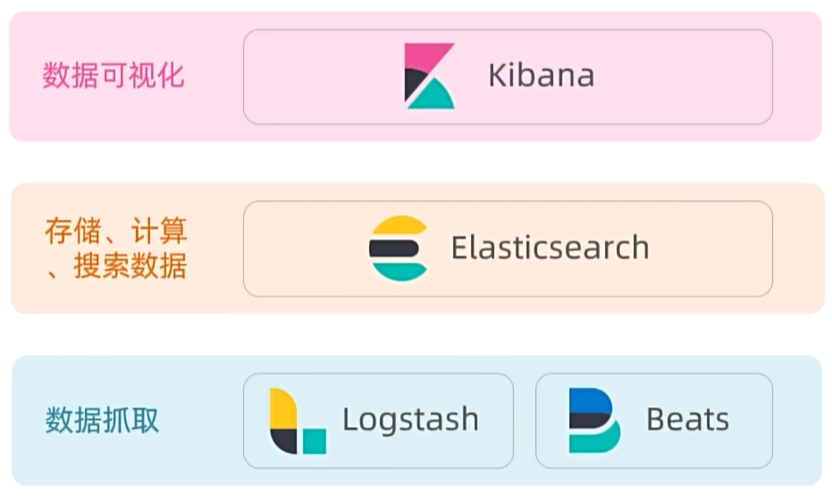
Elasticsearch随着技术的不断发展,它有一套完整的技术栈。
Elasticsearch结合Kibana、Logstash、Beats,是一整套技术栈,被叫做ELK。被广泛应用在日志数据分析、实时监控等领域。
1.2 安装
我们安装的内容包括2部分:
- elasticsearch:存储、搜索和运算
- kibana:图形化展示(帮助我们操作ES比较方便)
1.2.1 安装Elasticsearch
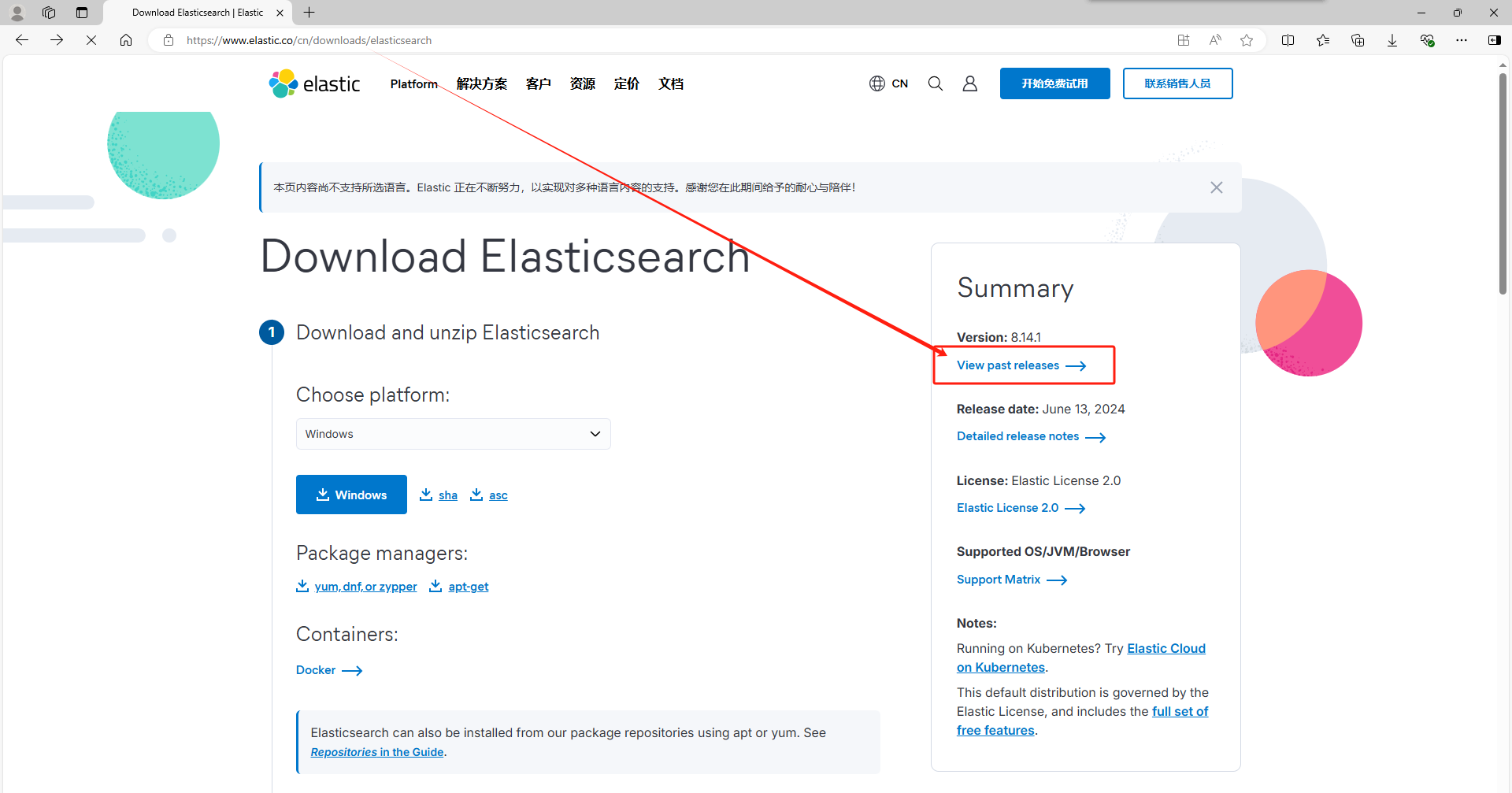
1)下载安装包
1.首先进入官网,点击view past release查看过去版本
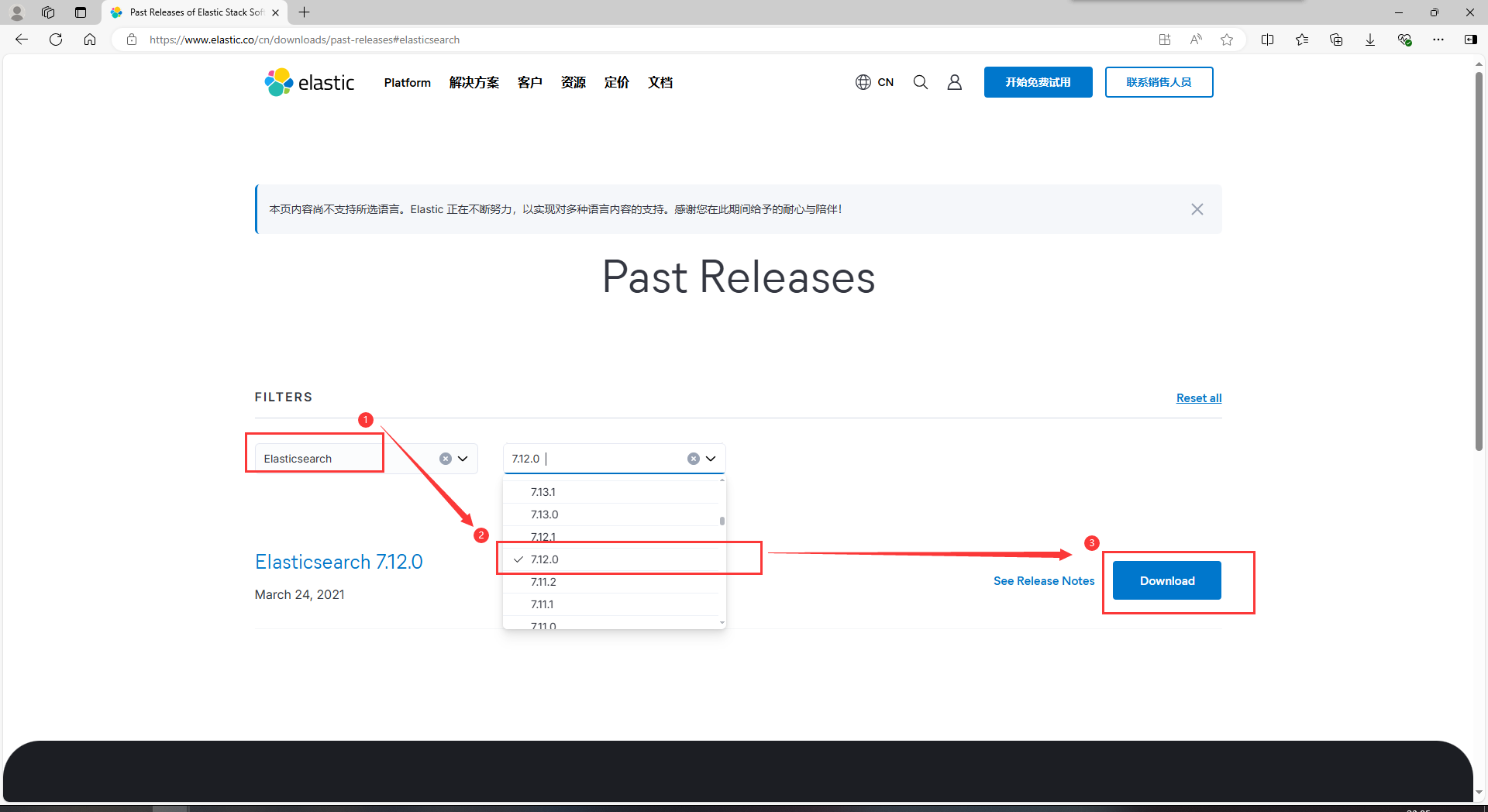
2.选择下载Elasticsearch,选择需要的版本号,点击Download下载
3.选择需要下载的操作系统,我这边是下载了windows和linux的安装包
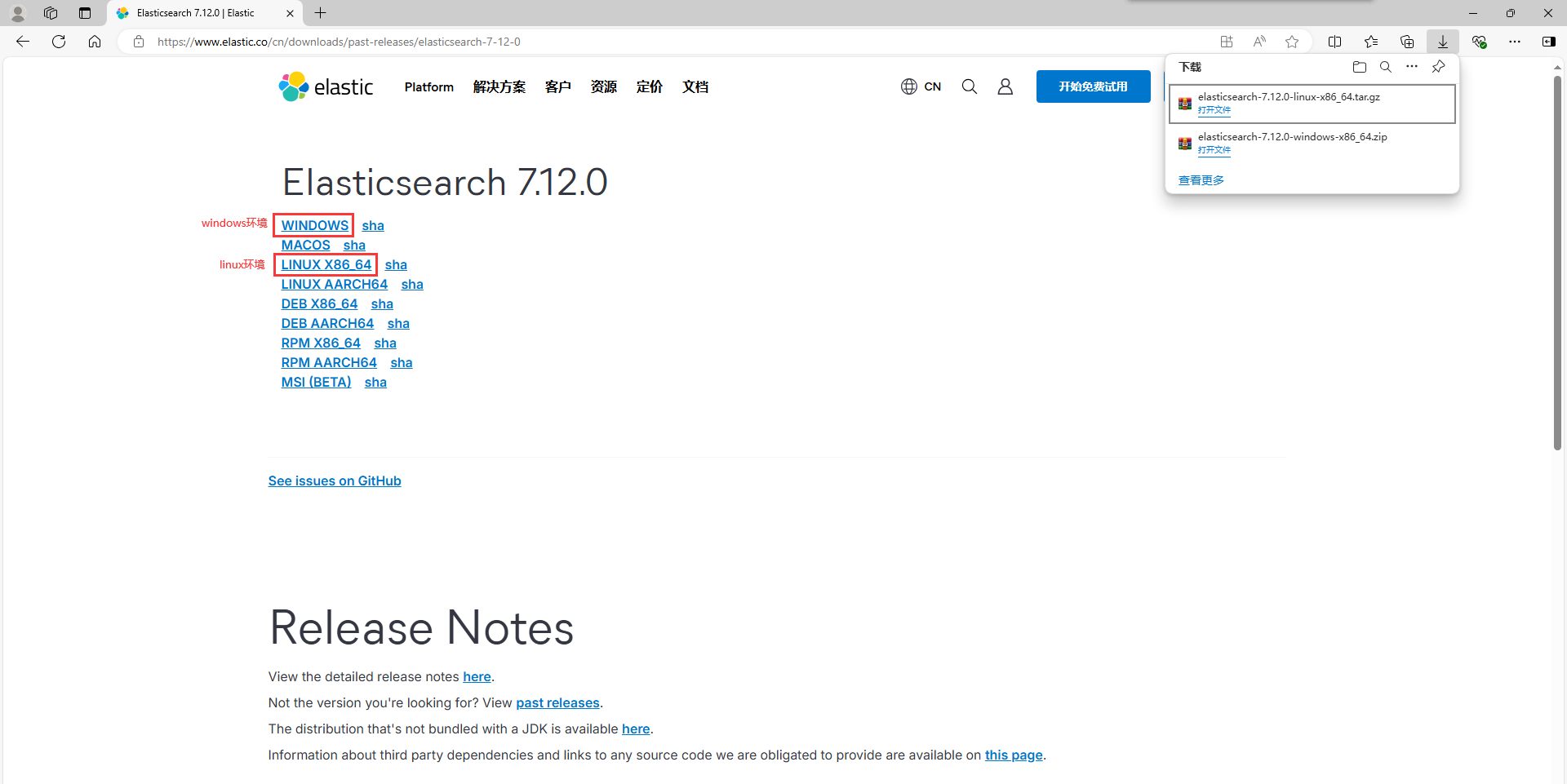
2)基于Windows安装
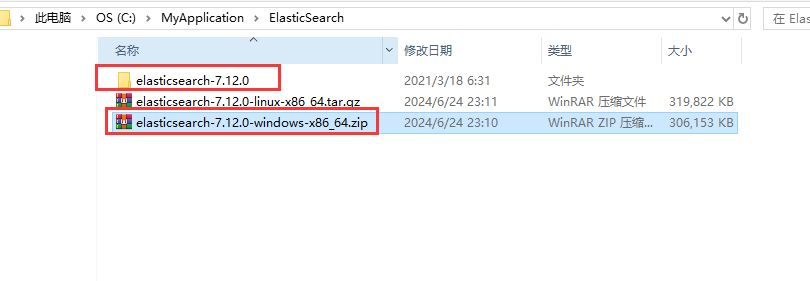
1.解压下载好的ES安装包
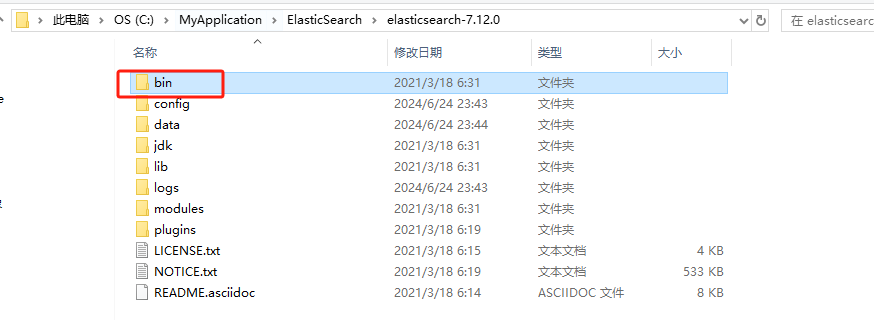
2.进入到bin目录下,双击执行elasticsearch.bat文件
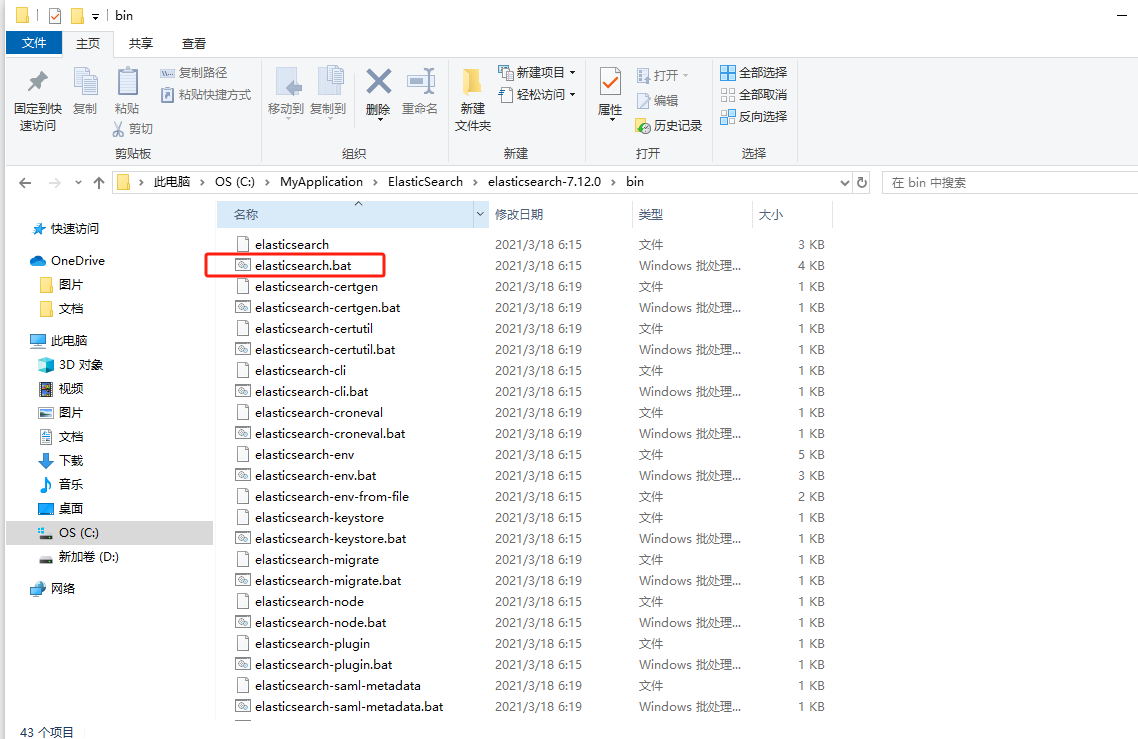
双击执行elasticsearch.bat文件之后,会弹出cmd窗口,等待启动完成。
3.访问浏览器出现如下内容,说明我们安装并启动成功了。
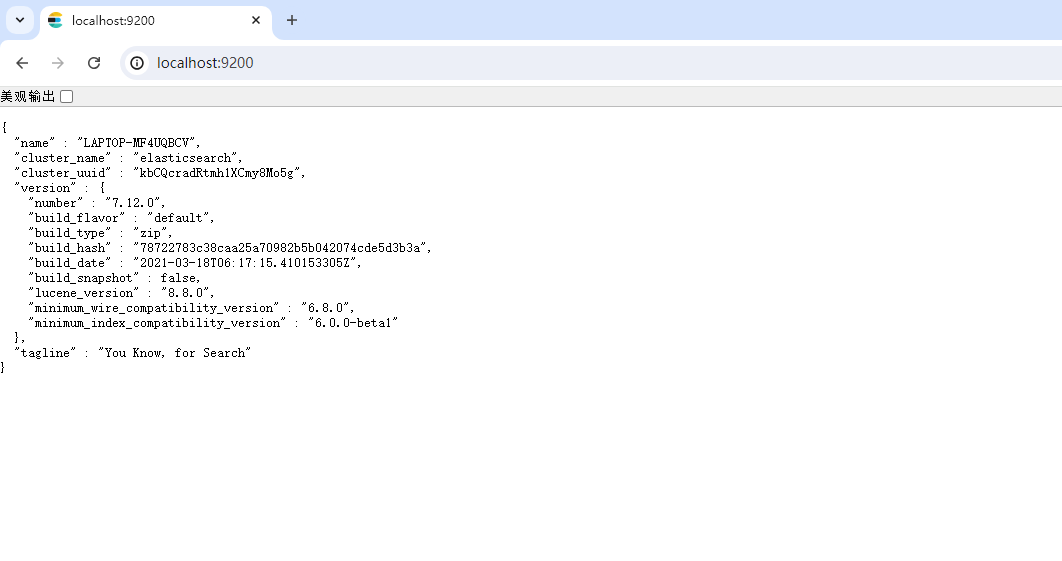
其中有两个端口号需要我们注意:
9300端口是Elasticsearch集群间组件的通信端口,9200端口为浏览器访问的http协议RESTful端口。
3)基于Liunx安装
注意;检查是否安装jdk。es7内嵌了jdk,如果使用自己的jdk,至少1.8以上,并配置JAVA_HOME环境变量;
1.将上面下载好的linux安装包上传到linux服务器

2.使用tar命令解压elasticseach安装包(我这边解压之后放在/opt目录下)
tar -zxvf elasticsearch-7.12.0-linux-x86_64.tar.gz -C /opt/
3.进入解压后的elasticsearch目录并创建数据存放目录:

cd /opt/elasticsearch-7.12.0
mkdir data
4.修改config/elasticsearch.yml
取消以下注释项:
cluster.name: my-application #集群名称
node.name: node-1 #节点名称
#数据和日志的存储目录
path.data: /opt/elasticsearch-7.1.1/data
path.logs: /opt/elasticsearch-7.1.1/logs
#设置绑定的ip,设置为0.0.0.0以后就可以让任何计算机节点访问到了
network.host: 0.0.0.0
http.port: 9200 #端口
#设置在集群中的所有节点名称,这个节点名称就是之前所修改的,当然你也可以采用默认的也行,目前是单机,放入一个节点即可
cluster.initial_master_nodes: ["node-1"]

修改完毕后,:wq 保存退出vim
5、添加用户用来启动elasticsearch
创建用户因为安全问题,Elasticsearch 不允许 root 用户直接运行,所以要创建新用户,在 root 用户中创建新用户
useradd elasticsearch
passwd elasticsearch不能使用root账户去启动elasticsearch,要不然会报下面的错误:
org.elasticsearch.bootstrap.StartupException: java.lang.RuntimeException: can not run elasticsearch as root
at org.elasticsearch.bootstrap.Elasticsearch.init(Elasticsearch.java:163) ~[elasticsearch-7.12.0.jar:7.12.0]
at org.elasticsearch.bootstrap.Elasticsearch.execute(Elasticsearch.java:150) ~[elasticsearch-7.12.0.jar:7.12.0]
at org.elasticsearch.cli.EnvironmentAwareCommand.execute(EnvironmentAwareCommand.java:75) ~[elasticsearch-7.12.0.jar:7.12.0]
at org.elasticsearch.cli.Command.mainWithoutErrorHandling(Command.java:116) ~[elasticsearch-cli-7.12.0.jar:7.12.0]
at org.elasticsearch.cli.Command.main(Command.java:79) ~[elasticsearch-cli-7.12.0.jar:7.12.0]
at org.elasticsearch.bootstrap.Elasticsearch.main(Elasticsearch.java:115) ~[elasticsearch-7.12.0.jar:7.12.0]
at org.elasticsearch.bootstrap.Elasticsearch.main(Elasticsearch.java:81) ~[elasticsearch-7.12.0.jar:7.12.0]
Caused by: java.lang.RuntimeException: can not run elasticsearch as root
at org.elasticsearch.bootstrap.Bootstrap.initializeNatives(Bootstrap.java:101) ~[elasticsearch-7.12.0.jar:7.12.0]
at org.elasticsearch.bootstrap.Bootstrap.setup(Bootstrap.java:168) ~[elasticsearch-7.12.0.jar:7.12.0]
at org.elasticsearch.bootstrap.Bootstrap.init(Bootstrap.java:397) ~[elasticsearch-7.12.0.jar:7.12.0]
at org.elasticsearch.bootstrap.Elasticsearch.init(Elasticsearch.java:159) ~[elasticsearch-7.12.0.jar:7.12.0]
![]()

6、给elasticsearch用户添加权限:
chown -R 用户名:用户名 文件(目录)名(root权限使用此命令)
chown -R elasticsearch:elasticsearch /opt/elasticsearch-7.12.0![]()
7、修改/etc/security/limits.conf
vim /etc/security/limits.conf
# 在文件末尾中增加下面内容
# 每个进程可以打开的文件数的限制
* soft nofile 65536
* hard nofile 131072![]()

重新登录系统配置生效,检验方法:
ulimit -Hn
ulimit -Sn8、编辑/etc/sysctl.conf文件,在最后添加一行
vim /etc/sysctl.conf
# 在文件中增加下面内容
# 一个进程可以拥有的VMA(虚拟内存区域)的数量,默认值为65536
vm.max_map_count=655360
![]()

9、执行命令,使其立即生效
/sbin/sysctl -p10、启动成功:
# 登录刚才新建的elasticsearch用户
su elasticsearch
# 进入elasticsearch安装目录,启动elasticsearch
cd /opt/elasticsearch-7.12.0
./bin/elasticsearch后台启动:
./bin/elasticsearch -d
11、测试(等待ES启动成功之后测试)
curl http://localhost:9200
出现如下内容,说明我们安装并启动成功了。
4)出现问题解决
有些兄弟可能会出现启动失败
- Elasticsearch 是使用 java 开发的,且 7.8 版本的 ES 需要 JDK 版本 1.8 以上,默认安装包带有 jdk 环境,如果系统配置 JAVA_HOME,那么使用系统默认的 JDK,如果没有配置使用自带的 JDK,一般建议使用系统配置的 JDK。
1.2.2 安装Kibana
kibana是es数据的前端展现,数据分析时,可以方便地看到数据。作为开发人员,可以方便访问es。提供了Dev Tools界面,向plsql一样支持代码提示,让我们向es发送请求操作的时候更方便。
1)下载安装包
注意:kibana下载的版本一定要和ES的版本一样否者会出错
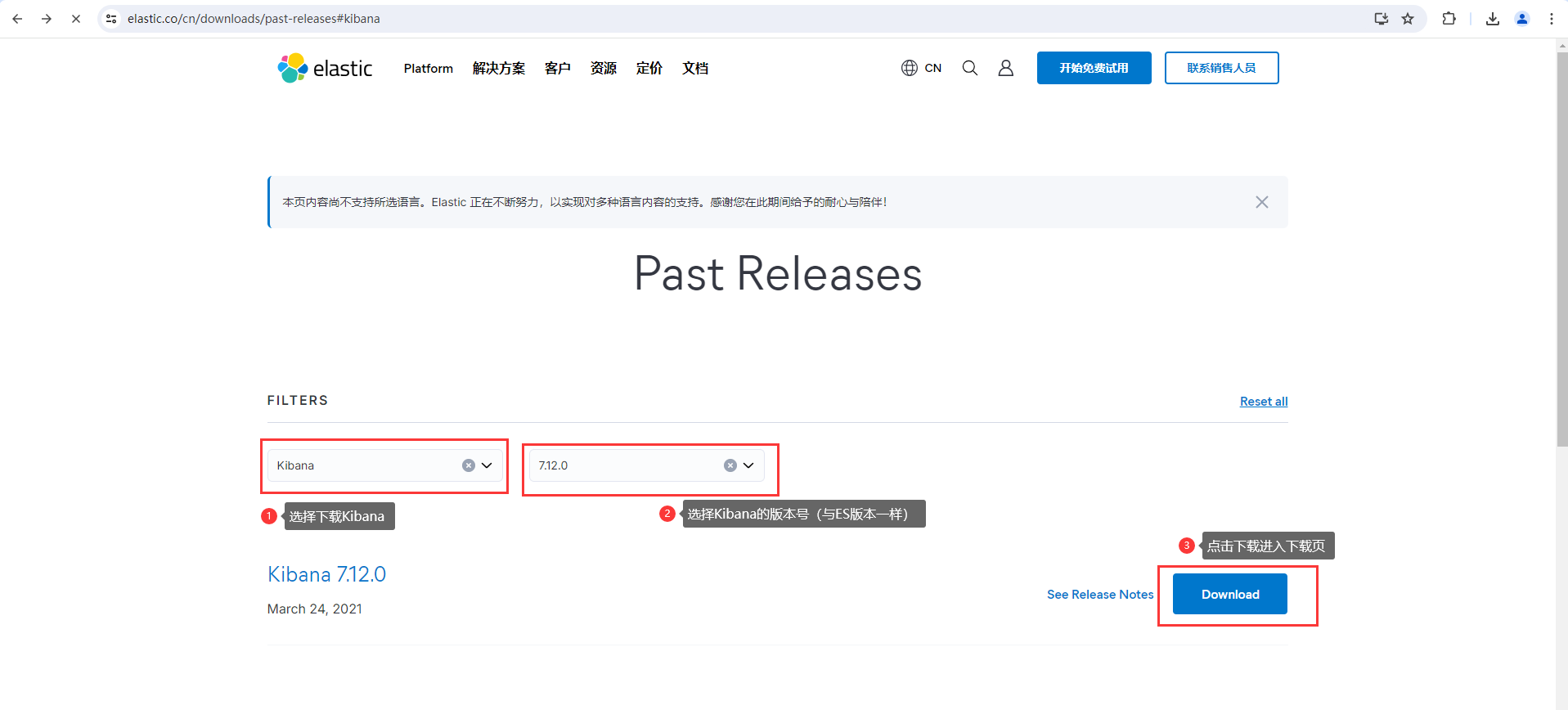
1.还是和下载ES一样进入ES官网下载,点击view past release查看过去版本
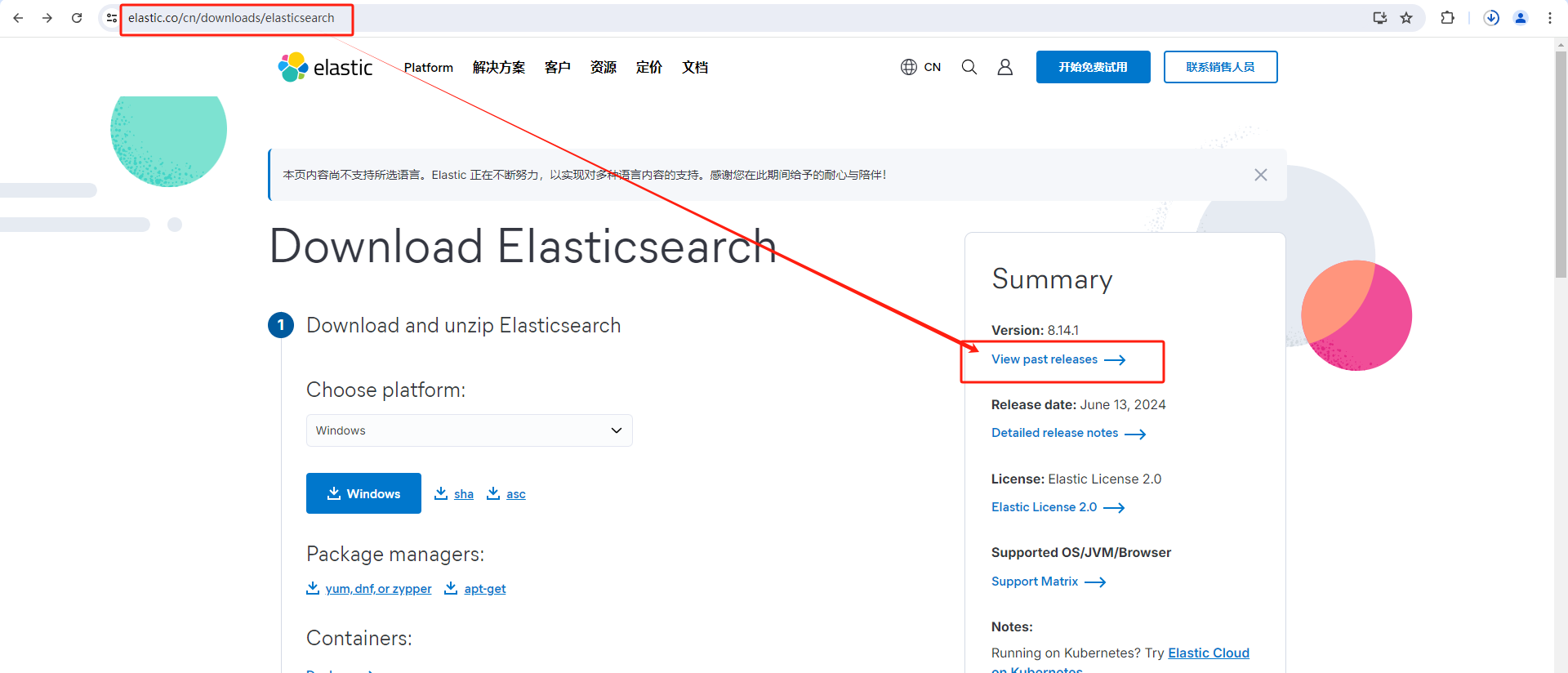
2.选择下载Kibana安装包和版本,点击Download进入下载页
3.选择需要下载的操作系统,我这边是下载了windows和linux的安装包。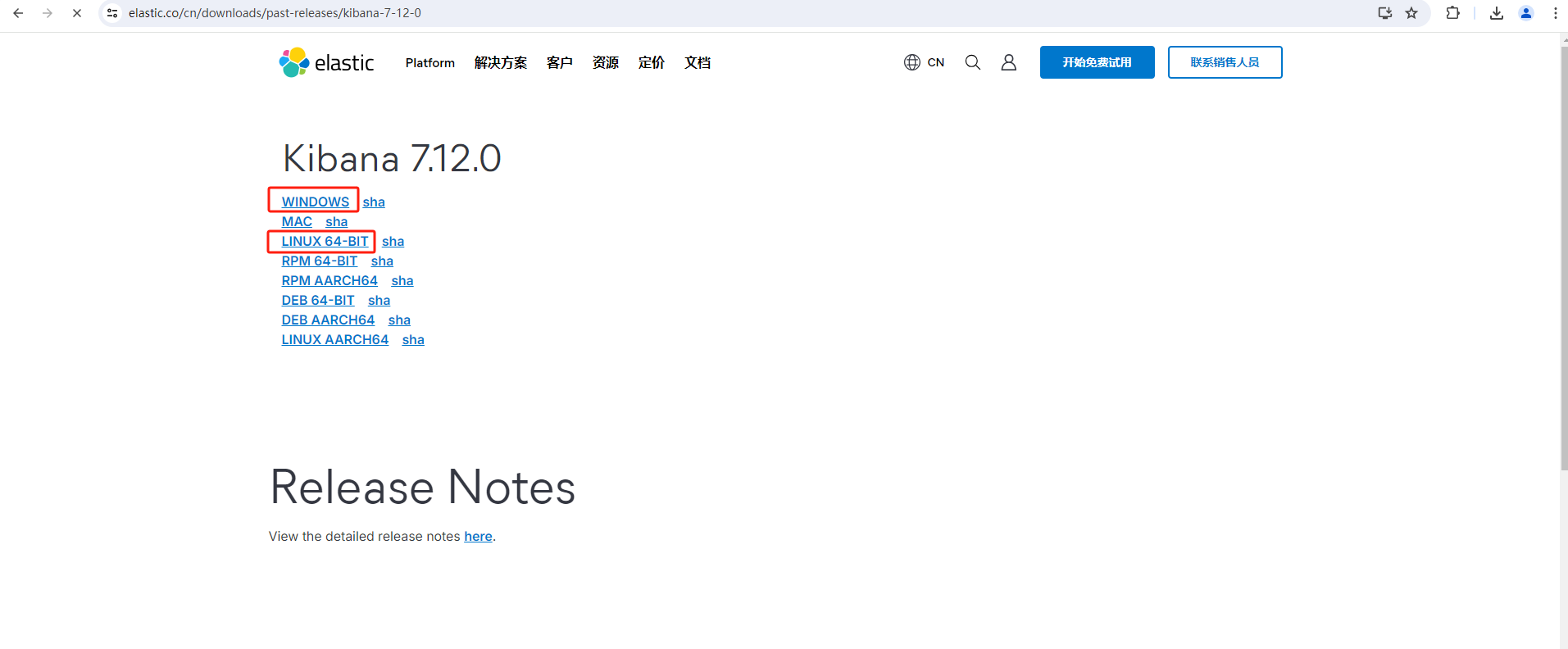
2)基于Windows安装
1.解压下载好的Kibana安装包
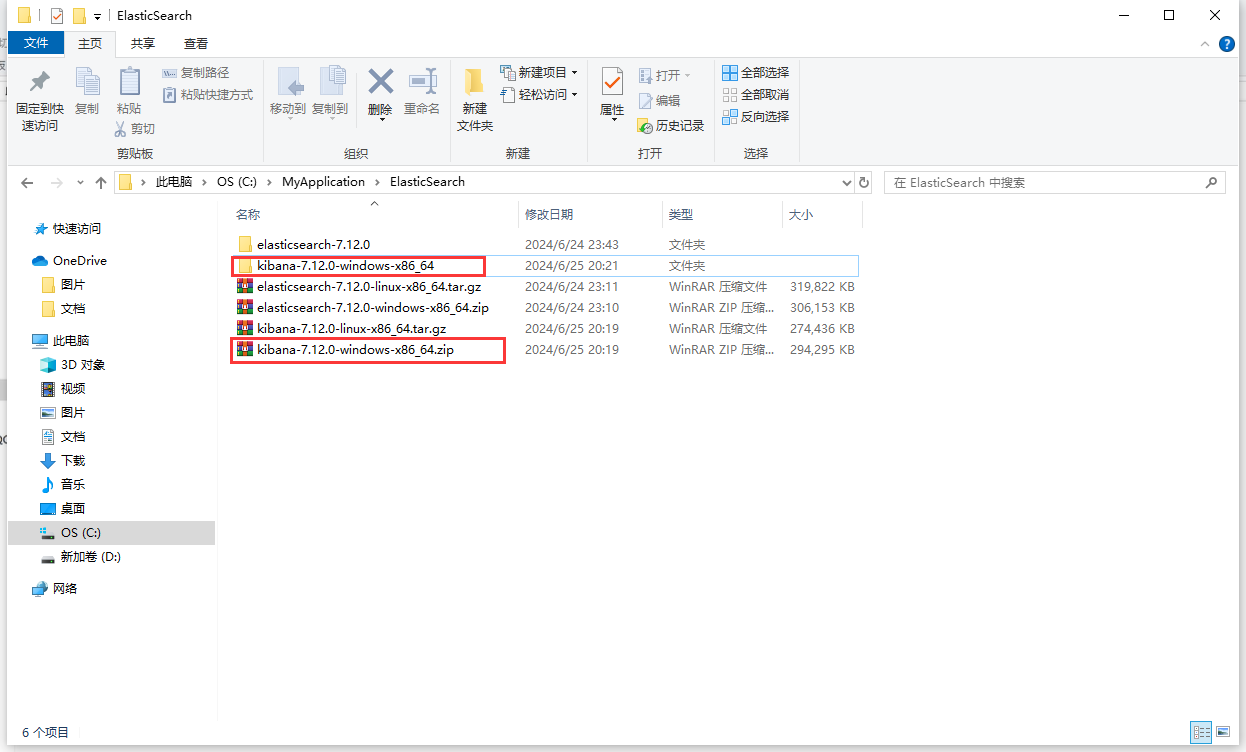
2.进入Kibana的config文件夹下,打开kibana.yml配置文件
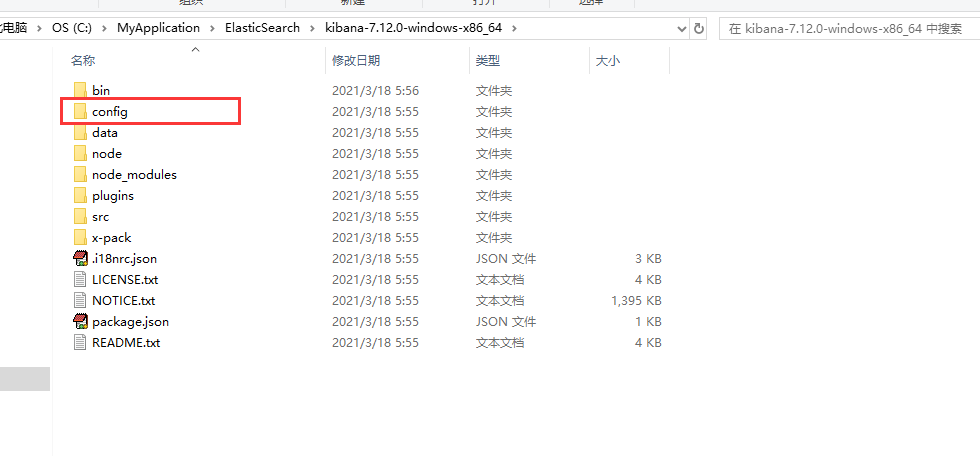
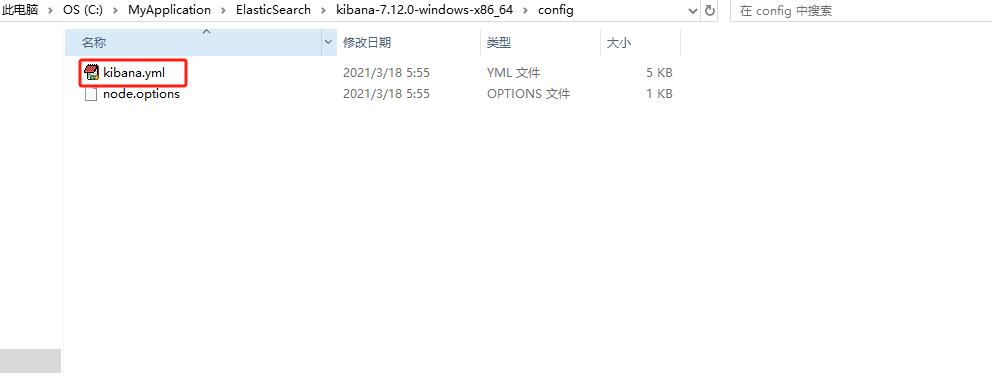
3.找到文件的后一行,将en替换成zh-CN,kibana默认是英文的我们将他替换成中文的。
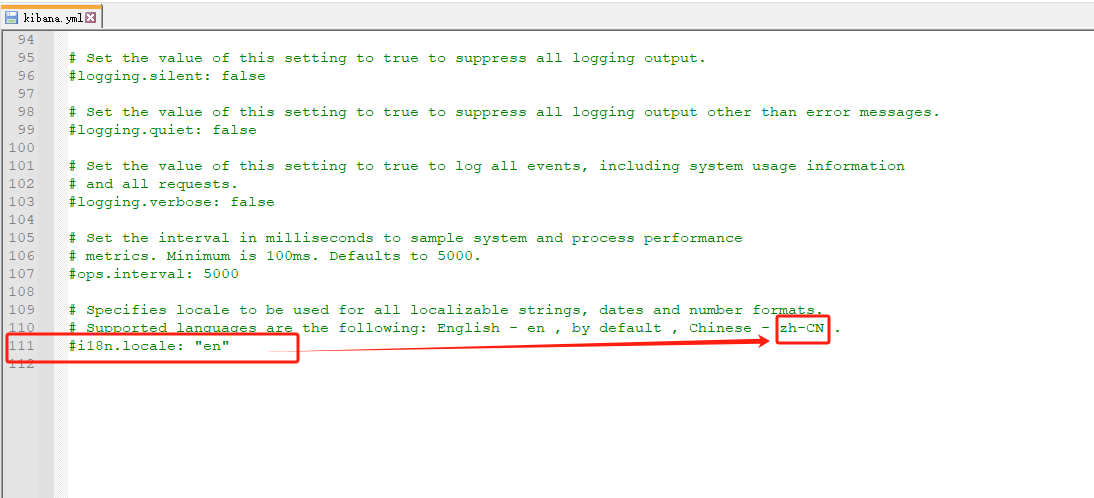 替换之后保存关闭文件,就可以了。
替换之后保存关闭文件,就可以了。 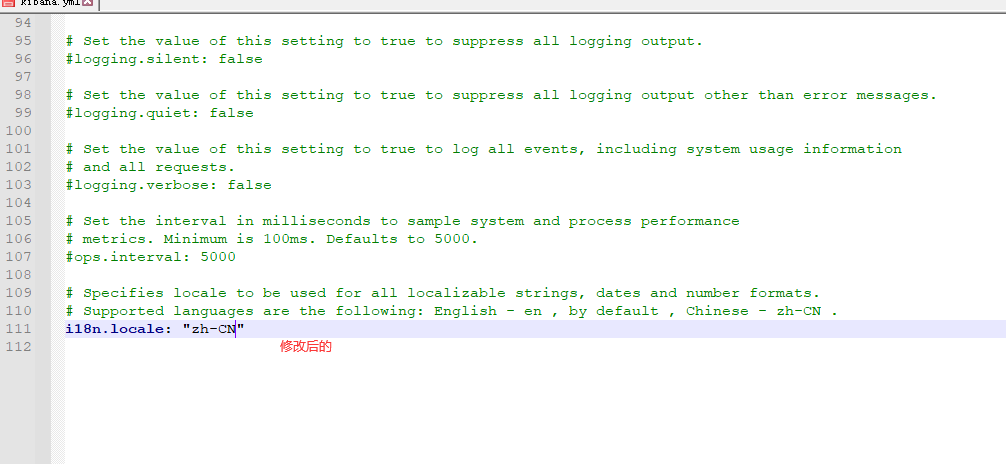
4.保存之后进入bin目录下,双击kibana.bat启动(启动KIbana之前ES要确保启动着)
等待启动完成,访问kibana默认端口是5601,打开浏览器访问localhost:5601
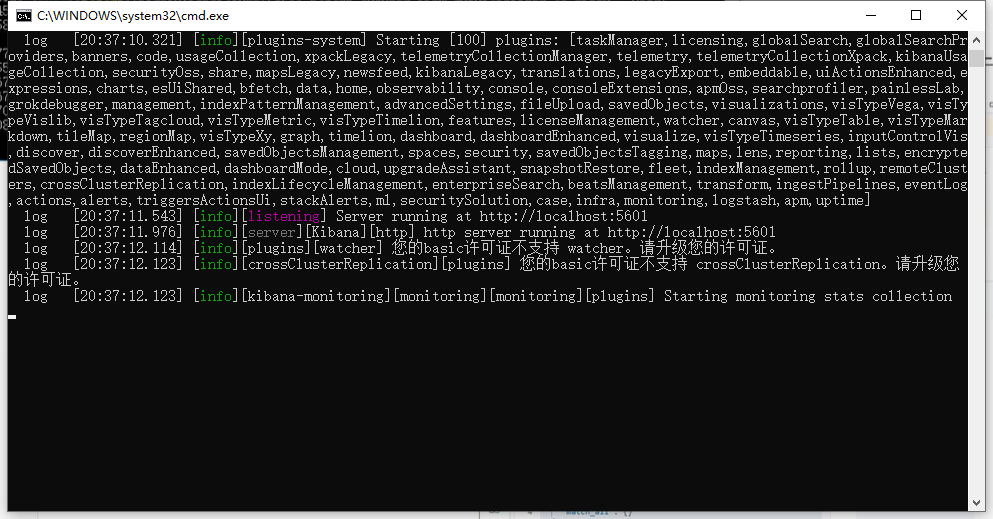
这样我们就启动安装成功了
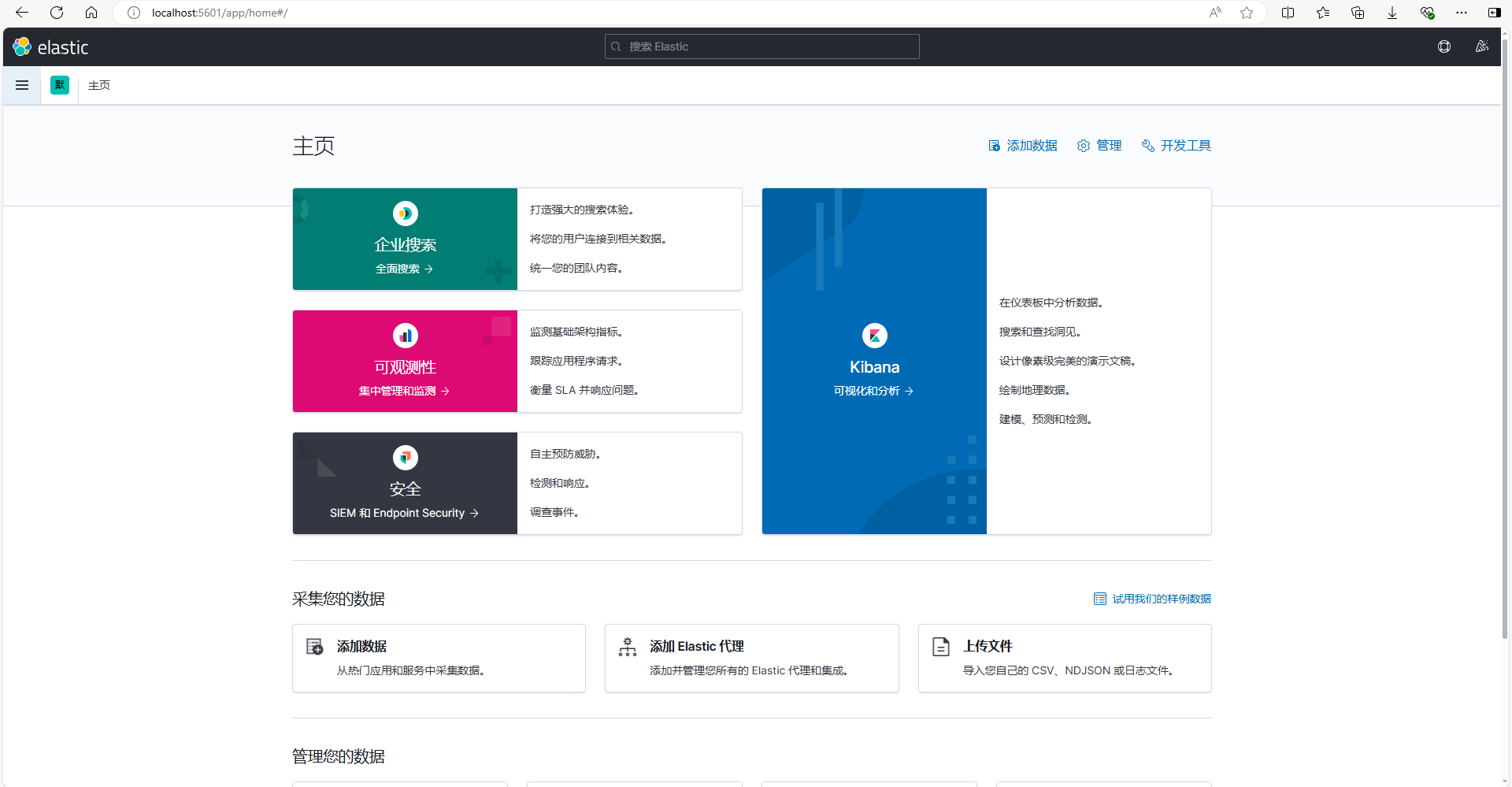
我们可以点开开发工具,有了开发工具我们就可以进行对ES的访问了
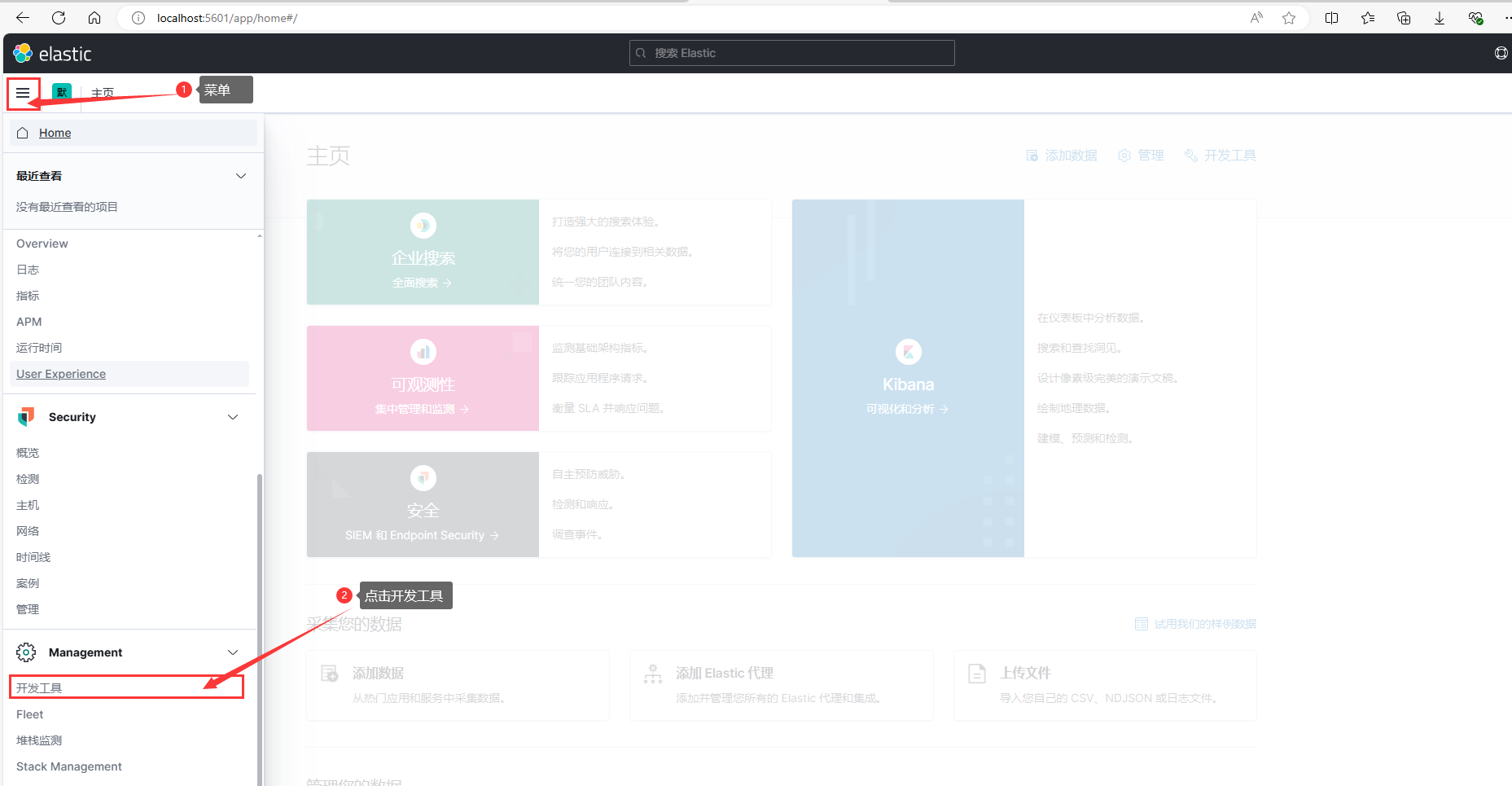
访问 GET / 相当于我们通过浏览器访问ES的http://lcoalhsot:9200返回的结果一样
这里请求的时候省略了http://localhost:9200,有kibana帮我们补充
1.2.3 安装Postman
如果直接通过浏览器向 Elasticsearch 服务器发请求,那么需要在发送的请求中包含HTTP 标准的方法,而 HTTP 的大部分特性且仅支持 GET 和 POST 方法。所以为了能方便地进行客户端的访问,可以使用 Postman 软件
Postman 是一款强大的网页调试工具,提供功能强大的 Web API 和 HTTP 请求调试。软件功能强大,界面简洁明晰、操作方便快捷,设计得很人性化。Postman 中文版能够发送任何类型的 HTTP 请求 (GET, HEAD, POST, PUT..),不仅能够表单提交,且可以附带任意类型请求体。
1)基于Windows安装
进入官网下载地址,点击Windows 64-bit下载安装包,安装很简单一直下一步即可,这里就不再演示了。
postman界面
1.3 倒排索引
倒排索引就是数据的一种检索方式,这种方式跟传统数据库的检索方式是相反的,所以称为倒排索引,传统数据库(如MySQL)采用正向索引。
1.3.1 正向索引
| id(索引) | content |
|---|---|
| 1 | 小米手机 |
| 2 | 华为手机 |
| 3 | 华为小米充电器 |
| 4 | 小米手环 |
| ... | ... |
我们就可以通过id去快速查询到我们的内容,之所以检索是比较快的,是因为我们将文章编号设置为主键同时生成主键索引,然后通过主键索引快速关联到存储的信息。这么这个索引我们称为正向索引。
可是,如果我们想要查询内容中包含那些词汇,这个时候就比较麻烦了,因为我们需要做模糊查询,模糊查询需要将每条数据都遍历,效率就明显差了很多。所以这就要我们换种方式来将数据和索引关联,这就需要用到倒排索引。
ES在做倒排索引存储的时候也会给每一个文档的id建立索引。
1.3.2 倒排索引
倒排索引中有两个非常重要的概念:
-
文档(
Document):用来搜索的数据,其中的每一条数据就是一个文档。例如一个网页、一个商品信息 -
词条(
Term):对文档数据或用户搜索数据,利用某种算法分词,得到的具备含义的词语就是词条。例如:我是中国人,就可以分为:我、是、中国人、中国、国人这样的几个词条
ES在存储的时候会将文档进行分词,保存成一个特殊的结构,文章表分词之后如下。
| 词条(索引) | 文档id |
|---|---|
| 小米 | 1,3,4 |
| 手机 | 1,2 |
| 华为 | 2,3 |
| 充电器 | 3 |
| 手环 | 4 |
id为1,3,4的数据都包含“小米”词条,id为1,2的数据都包含“手机”词条,以此类推。所有的文档全部进行分词得到所有的词条,词条数量是有限的而且唯一,那么这个时候就可以这些词条建立唯一索引。
我们会发现,倒排索引是根据词条查询主键id,这样就可以找到id对应的内容了,因此我们根据词条去检索的速度也会非常快。
1.3.3 总结
什么是文档和词条?
- 每一条数据就是一个文档
- 对文档中的内容分词,得到的词语就是词条
什么是正向索引?
- 基于文档id创建索引。根据id查询快,但是查询词条时必须先找到文档,而后判断是否包含词条
什么是倒排索引?
- 对文档内容分词,对词条创建索引,并记录词条所在文档的id。查询时先根据词条查询到文档id,而后根据文档id查询文档(两次检索都有走索引,所以速度就快很多)
1.4 IK分词器
Elasticsearch的关键就是倒排索引,而倒排索引依赖于对文档内容的分词,而分词则需要高效、精准的分词算法,IK分词器就是这样一个中文分词算法。
英文的分词是相对比较简单的,因为英文语句里面天然的就按照空格把一个一个单词分开,所以利用空格切割就很容易进行分词,当中文不一样,中文的一句话里面字与字之间是没有任何的间隔的,所以要对中文进行分词需要对语义进行分析,但是中文的含义是变化多端的,同样的一句话用不同的分法它的含义就不一样。比如“你方便吗”这句话如果短句不同,分词方式不同它的含义就会变化。
通常我们会去使用国人写的分词器,其中最知名,最常用的分词就是IK分词器,那么接下来我们就一起来学习IK分词器的使用。
1.4.1 安装IK分词器
1)下载安装包
1. 进入下载页面,点击release查看更多版本,选择与ES一样的版本号

2.点击版本号。选择与ES一样的版本号,我这边是7.12.0版本的
3.点击下载安装包,安装包不大,下载还是挺快的
2)基于Windows安装
Ik分词器的安装很简单,只需要解压放到ES的插件目录下即可
1.将安装包的内容解压到一个文件夹下
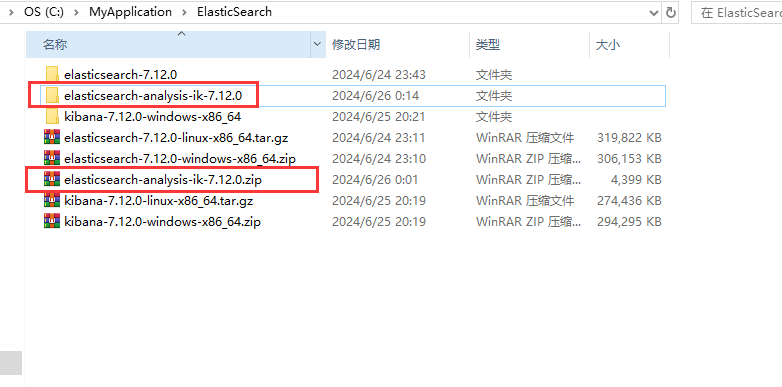
这是ik分词器下的内容
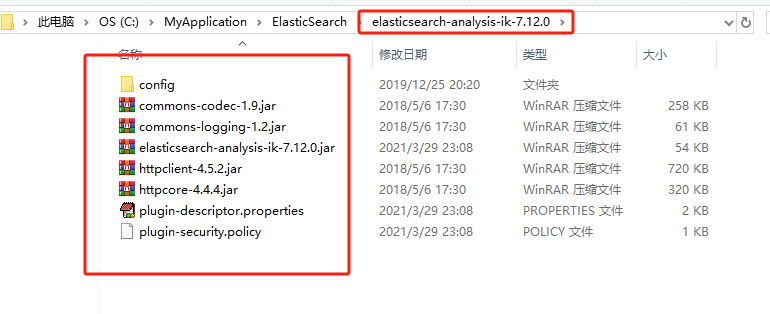
将解压后的ik分词器放到ES的插件plugins目录下,然后重启ES服务和Kibana服务
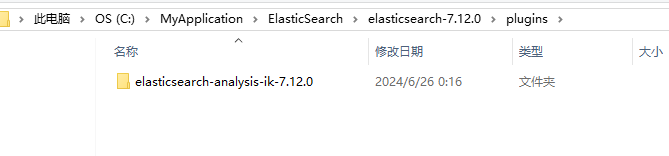
再次启动的时候,可以看到ES加载了IK分词器,这样就安装成功了
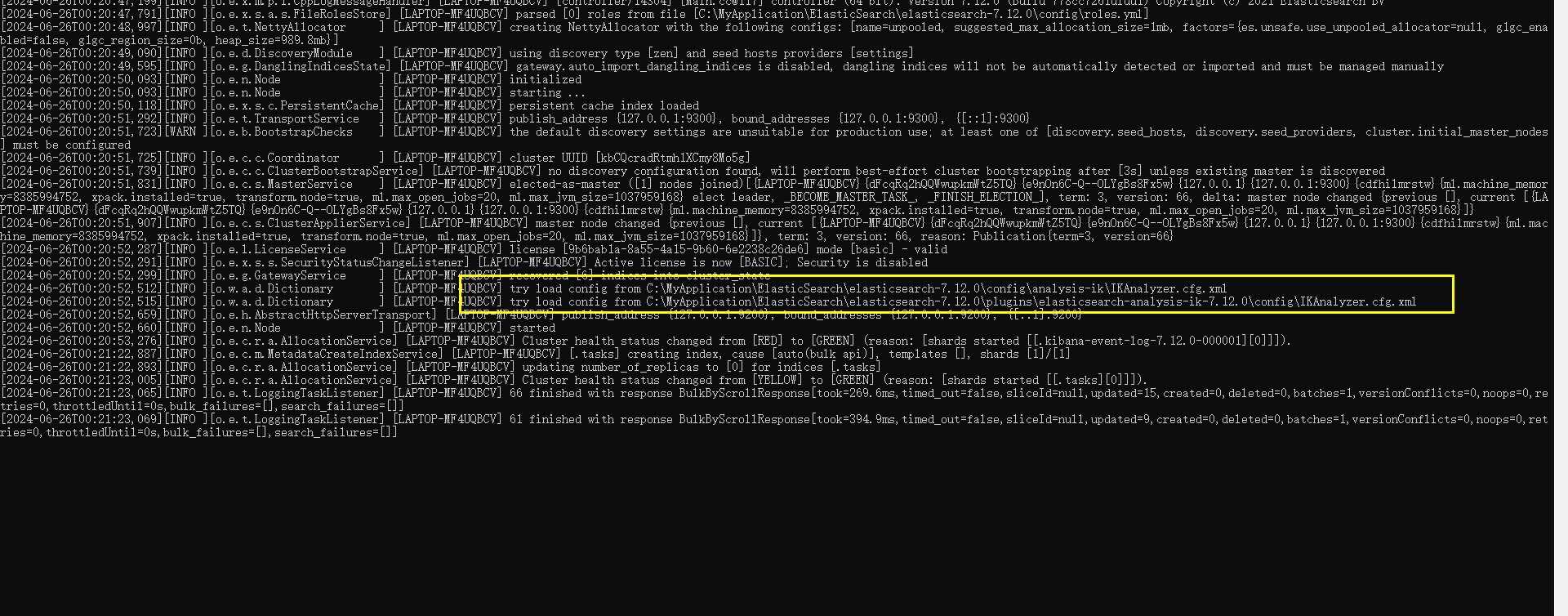
3)使用Ik分词器
IK分词器包含两种模式:
-
ik_smart:智能语义切分 -
ik_max_word:最细粒度切分
我们在Kibana的DevTools上来测试分词器,首先测试Elasticsearch官方提供的标准分词器:
POST /_analyze
{
"analyzer": "standard",
"text": "Java程序员太棒啦"
}语法说明:
- POST:请求方式
- /_analyze:请求路径,这里省略了http://localhsot:9200,有kibana帮我们补充
- 请求参数,json分隔:
- analyzer:分词器类型,这里是默认的standard分词器
- text:要分词的内容
打开kibana的开发工具(Dev Tools),点击运行。
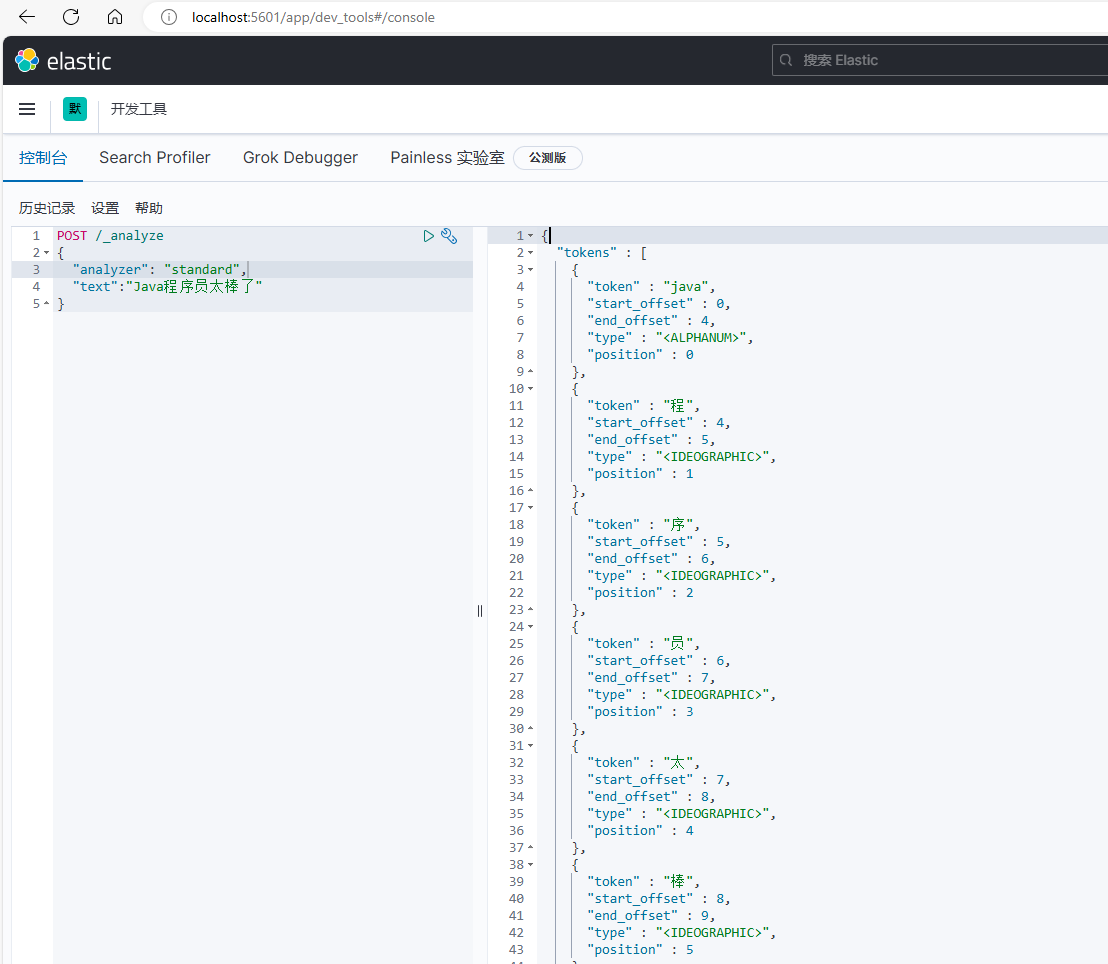
可以看到,标准分词器智能1字1词条,无法正确对中文做分词。
我们再测试ik分词器:
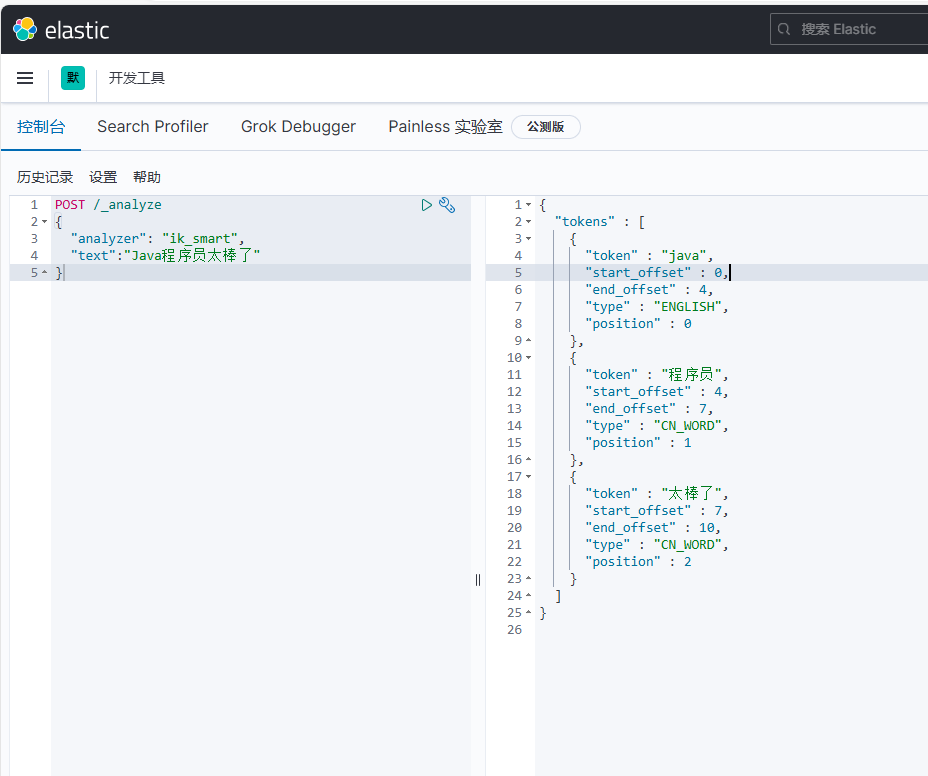
可以看到按照中文语义一个词一个词分的
4)拓展词典
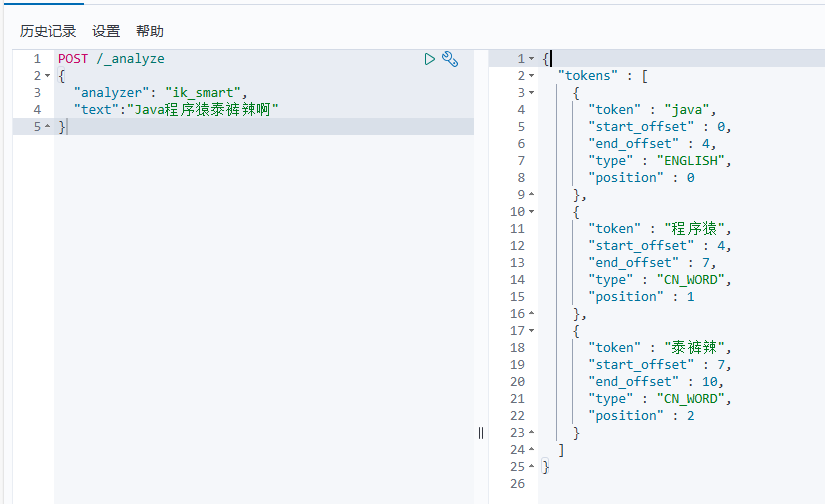
随着互联网的发展,“造词运动”也越发的频繁。出现了很多新的词语,在原有的词汇列表中并不存在。比如:“程序猿”,“泰裤辣” 等。
IK分词器无法对这些词汇分词,测试一下:
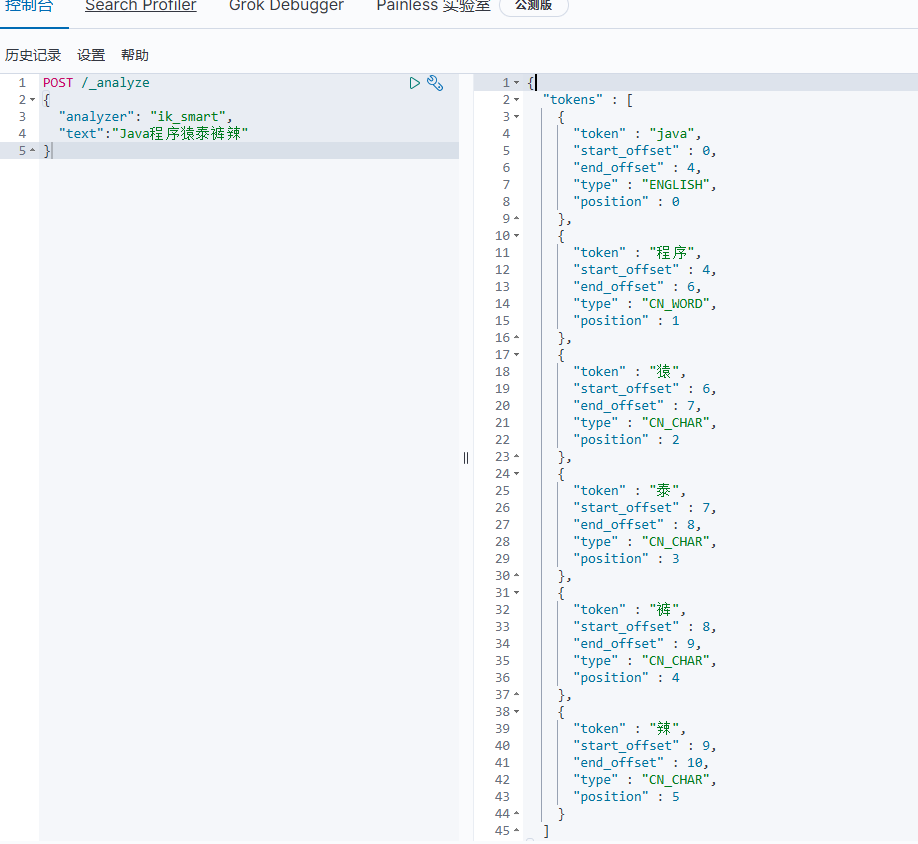
可以看到,程序猿 和 泰裤辣 都无法正确分词。
所以要想正确分词,IK分词器的词库也需要不断的更新,IK分词器提供了扩展词汇的功能。
1.打开Ik分词器config目录下的IKAnalyzer.cfg.xml文件
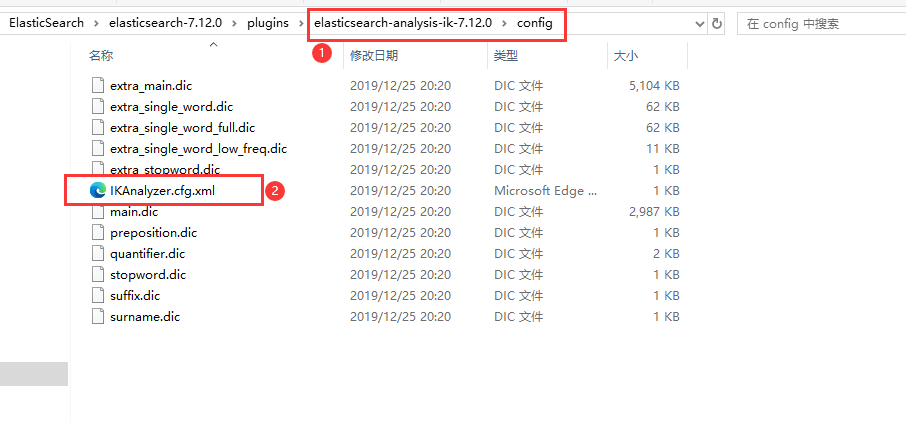
2.在 KAnalyzer.cfg.xml 里面添加扩展字典的文件和停止词字典的文件,停止词就是不需要分词的词语。
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 前边的key值是固定的-->
<entry key="ext_dict">ext.dic</entry>
<!--用户可以在这里配置自己的扩展停止词字典 前边的key值是固定的-->
<entry key="ext_stopwords">stopword.dic</entry>
<!-- <entry key="remote_ext_dict">words_location</entry> -->
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>
3.在IK分词器的config目录新建一个ext.dic,可以参考config目录下的stopword.dic停止词文件这个文件是自带,复制一个配置文件进行修改。
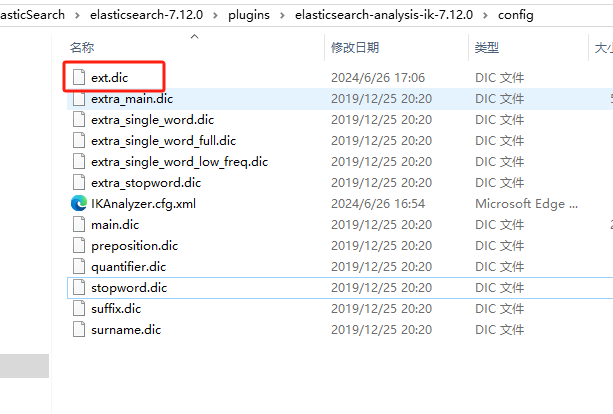
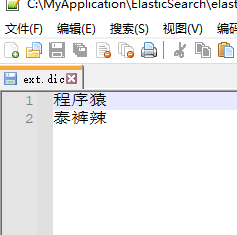
保存文件,重启ES服务.
再次测试,可以发现程序猿和泰裤辣都正确分词了:
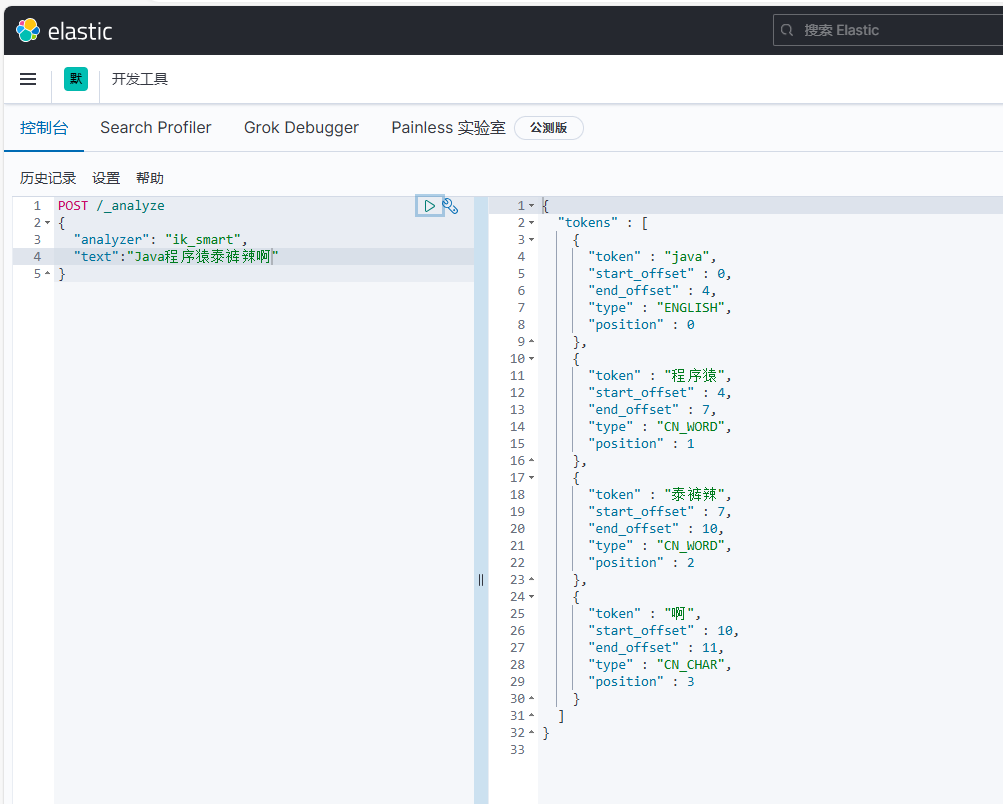 上边的分词结果“啊”也被分词了,向这种语气词分词无意义,我们可以加到stopword.dic停止词字典里面。保存文件重启ES服务
上边的分词结果“啊”也被分词了,向这种语气词分词无意义,我们可以加到stopword.dic停止词字典里面。保存文件重启ES服务

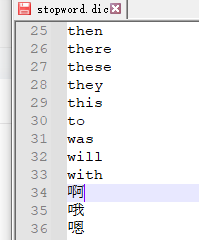
再次测试,可以发现“啊”就没有在分词结果里,因为被我们停止了。
5)总结
分词器的作用是什么?
创建倒排索引时,对文档分词
用户搜索时,对输入的内容分词
IK分词器有几种模式?
ik_smart:智能切分,粗粒度
ik_max_word:最细切分,细粒度
IK分词器如何拓展词条?如何停用词条?
利用config目录的IkAnalyzer.cfg.xml文件添加拓展词典和停用词典
在词典中添加拓展词条或者停用词条
1.5 ES基础概念
elasticsearch中有很多独有的概念,与mysql中略有差别,但也有相似之处。
1.5.1 文档和字段
elasticsearch是面向文档(Document)存储的,可以是数据库中的一条商品数据,一个订单信息。文档数据会被序列化为json格式后存储在elasticsearch中:
数据库表
存储到ES之后的格式
{
"id": 1,
"title": "小米手机",
"price": 3499
}
{
"id": 2,
"title": "华为手机",
"price": 4999
}
{
"id": 3,
"title": "华为小米充电器",
"price": 49
}因此,原本数据库中的一行数据就是ES中的一个JSON文档;而数据库中每行数据都包含很多列,这些列就转换为JSON文档中的字段(Field)。
1.5.2 索引和映射
索引(index):相同类型的文档的集合
映射(mapping):索引中文档的字段约束信息,类似表的结构约束
随着业务发展,需要在es中存储的文档也会越来越多,比如有商品的文档、用户的文档、订单文档等等:

所有文档都散乱存放显然非常混乱,也不方便管理。因此,我们要将类型相同的文档集中在一起管理,称为索引(Index)。例如:



-
所有用户文档,就可以组织在一起,称为用户的索引;
-
所有商品的文档,可以组织在一起,称为商品的索引;
-
所有订单的文档,可以组织在一起,称为订单的索引;
因此,我们可以把索引当做是数据库中的表。
数据库的表会有约束信息,用来定义表的结构、字段的名称、类型等信息。因此,索引库中就有映射(mapping),是索引中文档的字段约束信息,类似表的结构约束。
1.5.3 mysql与elasticsearch
我们统一的把mysql与elasticsearch的概念做一下对比:
| MySQL | Elasticsearch | 说明 |
|---|---|---|
| Table | Index | 索引(index),就是文档的集合,类似数据库的表(table) |
| Row | Document | 文档(Document),就是一条条的数据,类似数据库中的行(Row),文档都是JSON格式 |
| Column | Field | 字段(Field),就是JSON文档中的字段,类似数据库中的列(Column) |
| Schema | Mapping | Mapping(映射)是索引中文档的约束,例如字段类型约束。类似数据库的表结构(Schema) |
| SQL | DSL | DSL是elasticsearch提供的JSON风格的请求语句,用来操作elasticsearch,实现CRUD |
那是不是说,我们学习了elasticsearch就不再需要mysql了呢?
并不是如此,两者各自有自己的擅长之处:
Mysql:擅长事务类型操作,可以确保数据的安全和一致性
Elasticsearch:擅长海量数据的搜索、分析、计算
因此在企业中,往往是两者结合使用:
对安全性要求较高的写操作,使用mysql实现
对查询性能要求较高的搜索需求,使用elasticsearch实现
两者再基于某种方式,实现数据的同步,保证一致性

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









