






因为当时手头的VPN用不了了,所以就看的B站一个up的视频。在这里链接贴一下,01. Introduction to Computation_哔哩哔哩_bilibili。(2004版本)
叠个甲先:本人非计算机专业,理解可能有偏差,大家谅解。学这个课也是因为大佬推荐这个课,所以才学的。惭愧惭愧。
还有,由于本人理解程度有限,有些英语单词我很难以准确的中文术语替换,所以可能有时候采取中夹英的表达方式。此外我认为,这种方式除了便于我写笔记、方便各位朋友阅读,也可能更加便于各位今后学术交流等等,所以还望大家理解。by the way,我本人还是非常爱国,热爱汉语的。
另外,吐槽下,教授讲课真的快,嘴巴跟借来的一样,幸好有Lecture Notes可以看,不然我直接gg。
Lecture 1 Introduction of Computation
介绍了Scheme语言,以及一些基本的概念。
Language Elements
permitives、combinations、abstractions.
permitives(最简单结构——我们在这之上构建所有其他计算结构
其中最简单的就是self-evaluating expression,即其值是对象或表达式本身的事物。包括数字(numbers)、字符串(strings)以及布尔值(Booleans)
数字包括:整数、实数和科学记数法数字。
字符串是字符序列,包括数字和特殊字符,全部用双引号分隔。它们代表符号数据,而不是数字数据。
布尔值表示 true 和 false 的逻辑值。它们代表逻辑数据,而不是符号或数字数据。

当我们有了这样的primitives,我们还需要操作它们的过程,这就是+-*/以及其他的运算过程了。
对数字:+、-、*、/、>、<、>=、<=
对字符串:string-length、string=?
对布尔值:就是我们熟悉的and、or、not(留个疑问,会不会还有xor这样的。后面学到了再回来)
值得一提的是,这些名称(+、-等)本身就是一个表达式,他们的值就是一个个built-in procedure,代表的就是计算机内部执行+法的实际过程。
这之后,我们就能够使用数字(或者其他类型)和对应的计算过程构建一个新的self-evaluating表达式了。比如(+ 1 2),结果是3
Combination
既然已经有了permitives以及简单的表达式,那么如何使用他们构建复杂的表达式就是下一个问题了。
我们将用更简单的表达式构造更大的表达式的方式的组合方法。
最基本的combination格式:(+ 1 2)
一个左括号、一个过程名称、然后是一些其他的表达式(1、2),最后是一个右括号。
对于任何一个combination,我们可以以任意顺序的计算其中的子表达式的值,然后对后面的子表达式apply第一个值(也就是过程,like +、-......)。这里我使用了apply,是因为课程中老师专门对于apply做了解释,对于简单的内置程序(本例子就是简单的built-in程序),意味着只采用底层硬件实现并执行相对应的过程,像加减乘除等。
那么很容易想到,combination也是可以嵌套的,你可以在第二个以及以后的表达式中使用任意的combination,甚至于,第一个过程的名称也可以是自己新定义的,而它的定义也是一个combination。而为了计算任意深度的combination,我们只需递归地应用这些规则——首先获取子表达式的值,然后将过程应用于参数,并进一步简化表达式即可。
例如:(+(*2 3) 4) → 10。
为了获取第一个表达式的值,我们获取 + 的值(通过查找)和 4,因为它是自求值。因为中间的子表达式本身就是一个combination,所以在完成计算之前,我们应用相同的规则来获取值 6。最后计算最外层的,得到10
abstraction
那么到现在为止,我们有了primitives(数字以及built-in procedures)以及它们构成的combination。对于复杂的combination,我们只能一次次的写出它的完整表达式。为了简化这一过程,我们给某些表达式一个名称作为对它们的抽象(abstraction),这样我们就可以引用该名称(作为abstraction),而不用每次都写出复杂的表达式。
在Scheme中,我们执行abstraction的标准方法是使用称为定义的特定表达式。它的特定形式如下:
(define name 表达式)
一个左括号(像以前一样),后跟关键字define,后跟一个用作名称的表达式(通常是一些字母和其他字符的序列),后跟一个其值与该名称关联的表达式,最后是一个右括号。
PS:最后一个表达式也可以是一些计算过程,比如built-in procedures
这种表达方式是special form,之所以说是special是由于它使用不同的evaluate规则:我们只读取第二个表达式的名称而不是evaluate它,然后将它和第三个表达式的值进行pair。另外,abstraction自身的值(也就是这个表达式return的值)是unspecified(undefined)
那么一旦我们有能力为值命名,我们还需要有能力将值取回。这很容易。要获取Scheme中名称的值,我们只需在我们创建的表中查找名称的配对即可。因此,如果我们评估表达式分数,我们只需查找在该表中定义分数时所做的关联(在本例中为 23),然后返回该值。如下图 
请注意,我们对built-in primitives也是这样做的(+、*)。
如果我们将名称“+”赋予Scheme,它会查找该符号的关联,在本例中是内置的加法过程,并且该过程实际上作为值返回...
具体复杂的abstraction我就不举例了,课程上老师也有举例子,不难理解,所以我也就不赘述了。
abstraction的意义:
请注意,上面讲的abstraction在我们的系统中创建了一个非常好的循环。我们现在可以创建复杂的表达式,给它们一个名称,然后通过使用该名称,将整个表达式视为primitives。我们可以通过名称引用该表达式,因此可以编写涉及这些名称的新复杂表达式,为结果表达式命名,并将其视为新的原语primitives,等等。通过这种方式,我们可以将复杂性隐藏在名称背后,并在我们的语言中创建新的原始元素(primitive elements)。
关于evaluation rule的简单总结

由于这些求值的想法非常重要,所以让我们再看一下表达式求值时会发生什么。
请记住,我们的目标是捕获表达式中的计算,并使用这些表达式来计算值。我们已经描述了表达式的形式以及如何计算表达式的值。当我们考虑第二阶段时,我们可以区分出两个不同的世界,或者两种不同的方式来看待评估过程中发生的情况。
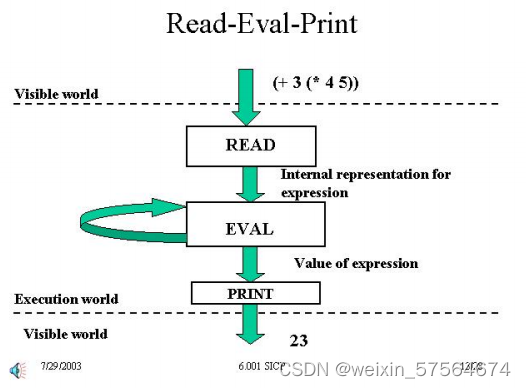
一个世界就是可见的世界(visible world)。这就是当我们在计算机上键入表达式并要求其执行计算并生成一些打印结果时所看到的结果。那个世界下面是执行世界(execution world)——就是计算机内发生的事情(我们将在本学期后面看到更多关于此的细节),包括如何表示对象以及如何进行实际的评估机制。我们希望了解这两个世界如何相互作用,以合并语义规则来确定表达式的值。
下面是课程上老师对于这个过程的描述:
当一个表达式从我们的可见世界输入计算机时,它首先由一种称为读取器(READ)的机制进行处理,该机制将该表达式转换为适合计算机的内部形式。
然后将该表格传递给称为评估器(EVAL)的流程。这封装了我们的求值规则,并将表达式简化为其值。
请注意,如果表达式是复合表达式,则这可能涉及求值规则的递归应用,正如我们在嵌套算术表达式中看到的那样。
然后结果被传递到打印过程(PRINT),该过程将其转换为人类可读的形式,并将其输出到屏幕上。
然后是具体的两个例子:
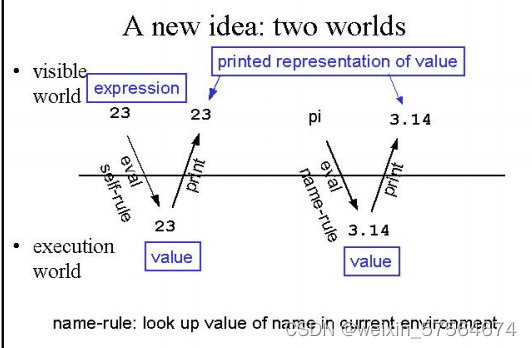
例如,假设我们在计算机中输入表达式 23,并询问其值。计算机基本上可以识别这是什么类型的表达式(在本例中为self-evaluating),因此应用self-evaluating表达式的规则。这会导致表达式转换为其自身的内部表示形式,在本例中是相同数字的某种二进制表示形式。对于self-evaluating表达式,值就是表达式本身,因此计算机只需将该值返回给打印过程,该过程将结果打印在屏幕上供我们查看。
第二种primitive是某事物的名称,通常通过evaluating (define)表达式来创建。请记住,这样的定义在我们称为环境的结构中创建了名称和值的配对。当我们要求计算机计算 pi 等表达式时,它会识别表达式的类型(名称),并应用名称规则。这会导致计算机在内部查找环境中该名称的配对或关联,并返回该值作为表达式的值。这将被传递给打印过程,该过程将结果打印在屏幕上。请注意,该值的内部表示可能与打印出来供我们看到的不同。
那么对于special forms呢?
好吧,我们看到的第一个是定义。这里规则是不同的。我们首先将evaluate规则应用于定义的第二个子表达式。
一旦确定了该值,我们就采用第一个子表达式(不进行求值)并在称为环境的结构中创建该名称和计算值的配对。
由于define表达式的目标是创建此配对,因此我们并不真正关心定义表达式本身的值。它仅用于创建配对的副作用。因此,通常我们将定义表达式返回的值保留为未指定
那么回到abstraction
假如我们有这样一句:(define fred +),会发生什么?
在尝试后发现,(+ 1 2)和(fred 1 2)的值是相同的,看起来似乎fred也变成了+。那么实际上它是这样吗?是的。那么为什么呢?
嗯,规则确实解释了这一点。define表达式表示将名称 fred 与 + 的值配对。请注意,+只是一个名称,它恰好是在Scheme启动时创建的。我们看到,它的值是一个过程,用于加法的内部过程。因此,define 表达式为 fred 创建了一个与加法的绑定。
因此,当我们evaluate combination时,我们的规则要求获取子表达式的值,因此使用名称规则评估名称 fred,以获得加法过程。然后将其应用于数字的值以生成显示的结果。
如果我询问与这些内置名称之一关联的值,我的规则会解释会发生什么。由于这是一个名称,因此会在环境中查找其值。在这种情况下,该值是乘法过程的某种内部表示,例如,指向执行乘法的内部算术单元部分的指针。该值作为该表达式的值返回,然后打印过程显示结果,显示该过程在机器中所处位置的某种表示。主要问题是查看该符号是否具有与其关联的值,在本例中是一个原始过程。
总结
因此,到目前为止,我们所看到的是利用primitive data和procedure的方法、创建combination的方法以及为事物命名(abstraction)的方法。在下一节中,我们将转向捕获过程中常见模式的想法。
Lecture 2 Scheme Basic
回顾
在上一讲中,我们开始研究编程语言Scheme,目的是了解该语言如何为描述过程和过程提供基础,从而理解控制复杂过程的计算隐喻。在本讲座中,我们将了解如何用我们的语言创建过程抽象(procedural abstraction),以及如何使用这些抽象来描述和捕获计算过程。
上节课我们提到了使用abstraction捕获built-in procedure,那么这节课就是主要围绕如何使用abstraction捕获我自己定义的一些procedures。
lambda表达式
在Scheme中,我们有一个特定的表达式来捕获过程。它称为 lambda 表达式。
形式为:一个左括号,关键字 lambda,后跟一定数量的括在括号内的符号,后跟一个或多个合法表达式,最后跟一个右括号。
例子: ( lambda ( x ) ( * x x ) )
紧跟在 lambda 后面的一组符号(即例子中的( x ))称为 lambda 的形式参数。随后的表达式(* x x )我们称为过程的body。这是我们想要捕获的计算过程的特定模式(理解成表达式就可以了)。 
这个lambda表达式实际上就创建了一个过程,一个求平方的过程。通过evaluate lambda 表达式返回的值是它捕获的实际过程process或者说procedure。该过程中包含一组形式参数,以及一个捕获过程通用模式的主体,作为这些形式参数的函数。
创建完成之后,我们就可以像使用built-in procedure一样使用这个过程了(即应用于combination的第一个元素的位置)。
procedural abstraction
当然,马上我们会发现,每次使用完整的lambda表达式都要写出完整的表达式非常麻烦,那么我们就想要采取naming abstraction(也就是lecture1中的abstraction)来对于我们创建的lambda过程用一个名称来关联或者说配对(pair)

square实际上的值就是求平方(lambda)的过程。
那么到现在为止,lambda是我们的第二种special form(第一种是define)。同样的,我们也会关心lambda返回的值是什么?
lambda返回的值(还请看下图辅助理解):它标识这是一个通过评估 lambda 创建的过程,并指示它在机器内部的位置(即如何获取过程的参数和主体)。需要强调的是,evaluate lambda表达式会在执行世界(execution world)中创建一个实际的过程对象,并且该值实际上作为表达式的值返回。
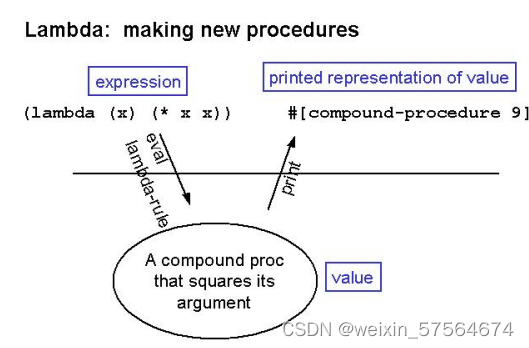
那么接下来就具体的看看如何使用lambda以及procedural abstraction吧。
1.创建了一个 lambda 表达式,该计算返回的值就是过程本身。请注意,该过程并未执行或运行(只是建立):此处没有以平方形式返回数值,而是将过程本身作为值返回。
2.使用procedure abstraction将lambda表达式与square配对。此时,这个define表达式返回的值是undefined,但是与它配对的是求平方的实际过程。
3.仔细看看(square 4)是如何evaluate的,该表达式是一个标准组合,因此我们只需获取子表达式的值(在下图中是4)即可。 Square 是一个名称,因此我们查找它的值,返回(lambda)过程。然后可以使用过程应用的标准规则将其应用于下一个子表达式的值,即将过程主体中各处的 x 替换为 4,然后使用相同的规则计算该新表达式。
4.同样的,也可以使用完整的 lambda 表达式来代替名称。在这种情况下,第一个子表达式的计算将创建过程,然后将其应用于第二个子表达式的值。
5.由于创建过程并为之命名非常常见,因此有一个语法糖(意思是含义相同,但形式更甜蜜)。

The Value of A Lambda Expression is A Procedure

为了更好的理解The Value of A Lambda Expression is A Procedure这句话,我们仔细看看上图这个lambda。
语法(如顶部所示)由三部分组成。
有一个关键字 lambda,它标识表达式的类型。
该表达式的第一个参数位置是过程的形式参数。这是一个列表(或括在一组括号中的一系列名称)。在本例中,该过程采用两个参数,我们将其称为 x 和 y。请注意,过程可以有任意数量的参数,包括零个(在这种情况下,我们将使用 () 作为参数列表),并且该参数确定在应用过程时必须将多少个参数传递给过程。
第二个参数的位置决定了过程的主体,即要被命名的计算过程。它可以是任何有效的方案表达式。请注意,创建过程时不会计算此表达式。它只是作为模式存储起来。仅当该程序应用于某些合法组合时才对其进行evaluate。
那么现在,不难看出, lambda 表达式的值是一个过程对象。它只是过程的某种内部表示,包括有关形式参数和主体或计算模式的信息。
some examples of describing processes in procedures
那么到目前为止,我们已经学习了大部分基本元素(primitives)了。我们将继续添加一些更特殊的形式,并引入一些额外的内置过程,但我们现在有足够的语言元素来开始推理过程,特别是使用过程来描述计算过程。
那么让我们看一些在过程中描述流程的示例。

事实上,这三个表达式都只是一个计算过程的特定实例:将值乘以自身的过程,或“平方”的过程。因此,我们可以通过为计算模式中随实例变化而变化的部分命名来capture这一点,并且将该名称标识为形式参数;然后将该计算模式capture作为 lambda 表达式的body,以及一组形式参数,所有这些都在 lambda 表达式内。(我也有想过换一个更加简洁的表述,但是思来想去,可能还是这个表达比较好,没有损失老师想要表达的意思。这个表述虽然复杂,但是其中的意思非常容易理解。如果有不明白,静下心来多看几遍就理解了)
那么下面就看一个更加复杂的计算模式吧!

capture这种计算模式的较好方法是认识到实际上有两件事正在发生。一是平方事物的子模式。另一种是在较大的模式内使用两个不同的平方进行加法运算。
因此,我们可以在其自己的过程中捕获两个个模式,并使用其自己的参数和主体。
( define (square ( lambda x ) ( * x x ) ) )
( define pythagoras ( lambda ( x y ) ( sqrt ( + ( square x ) (square y ) ) ) ) )为什么这是capture模式的较好方法?主要原因是,通过将模式分解为更小的模块,我们将计算的各个部分隔离在单独的抽象中。然后这些模块可以被其他计算重复使用。特别是,square的想法可能在其他地方有价值,因此在其自己的程序中捕获它,然后在更大的程序中使用是有意义的。
同样,通过这样做,我们创建了更易于阅读的代码,因为我们使用简单的名称来捕捉正方形的想法,并抑制不必要的细节。通过这样做,我们将过程的使用与其实际实现的细节隔离开来.
下面是另外一种分的更细的capture方法。本质上,我们做了几件事:我们确定了可以有效隔离的模块或计算过程的部分;然后我们在它们自己的程序抽象中捕获了它们(square和sum-square);最后我们创建了一个程序来控制各个模块之间的交互(pythagoras)。当然,我们可以以递归方式在每个模块中应用此过程。
(define (square ( lambda x ) ( * x x ) ) )
(define sum-square ( lambda (x y) ( + (square x) (square y) ) ) )
(define pythagoras (lambda ( x y ) (sqrt ( sum-square x y ) ) ) ) A more complex example——将procedural abstraction应用于第一讲中的平方根guess
具体的猜测流程如下图所示

构建代码的第一步就是在运行过程中确定一些好的模块或者阶段。
而在这一个问题中,是我们如何判断guess是否足够好来停止猜测,如果不够好,那么如何创造新的guess,以及如何让进程使用新的guess代替旧的guess。
下面是一种rather naive(相当幼稚)的方法。
(define close-enou? (lambda (guess x) (<(abs(-(square guess)x))0.001))) \\abs是返回结果的绝对值,我们只需要测量它是否很小即可
\\创造新的guess,需要将G和X/G取平均,划分为两步,求X/G,求平均
(define average (lambda (x y) (/(+ x y)2))) \\平均
(define improve (lambda (guess x) (average guess (/ x guess)))) \\更新guess
\\需要做出决定,即guess是否足够小。
(if (close-enou? G x) G (improve G x))
\\自动循环,sqrt-loop
(define sqrt-loop (lambda (G x) (if (close-enou? G x) G (sqrt-loop (improve G x) x))))
\\主程序sqrt,设定初始guess=1
(define sqrt (lambda x (sqrt-loop 1.0 x)))可以看到使用了名为if的新的special form。需要有三个子表达式,其具体形式为:(if (predicate) (consequence) (alternative)),当predicate的值为真,返回consequence的值,当为假,返回alternative的值
这里老师留下了一个问题:“为什么我们说if格式是一种special sorm而不是一种程序呢?下节课之后你应当能够回答这个问题”,那么就等我学到下节课再回来回答吧~
那么现在我们已经实现了大部分功能了,还差就是程序自动循环迭代guess。自动循环的模块我们把它命名为sqrt-loop.
(有兴趣的读者可以自己对于(sqrt 2)进行简单的过程推导。不难但是比较繁琐,所以我就不赘述了,有疑问的,大家可以评论区讨论,我看到了也会尽量回答~)
正如我们在第一讲中看到的那样,我们目前来说不能确定这个程序会正确发展?在下一讲中,我们将介绍一个用于跟踪表达式求值的形式模型,特别是涉及过程应用的表达式。然而现在,我们可以稍微非正式地逐步完成计算步骤。
Summarize
总而言之,我们已经看到我们可以使用过程的思想来捕获计算过程:通过找到过程的良好组件或模块;在其自己的程序中捕获每一个;然后决定如何控制整个计算过程。在下一讲中,我们将回到这个想法,研究将问题分解为这些步骤的不同方法。
PS:大家下期见~















 134
134











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









