







文件
1、打开文件
open("文件路径","打开方式")打开一个文件
第一个参数是一个字符串, 表示要打开的文件路径
第二个参数是一个字符串, 表示打开方式. 其中 r 表示按照读方式打开. w表示按照写方式打开. a表示追加写方式打开.
如果打开文件成功, 返回一个文件对象. 后续的读写文件操作都是围绕这个文件对象展开.
如果打开文件失败(比如路径指定的文件不存在),就会抛出异常。
f = open("E:/test/test.txt", "r")
print(f) # <_io.TextIOWrapper name='E:/test/test.txt' mode='r' encoding='cp936'>
print(type(f)) # <class '_io.TextIOWrapper'>
# 当文件不存在时
# 报这个错
FileNotFoundError: [Errno 2] No such file or directory: 'E:/test/test.txt'
open的返回值,是一个文件对象,如何理解?
文件的内容,是在硬盘上的,此处的文件对象,则是内存上的一个变量。
后续读写文件操作,都是拿着这个文件对象来进行操作的。
此处的文件对象就像一个"遥控器"一样。
计算机中,也把这样的远程操控的“遥控器"称为"句柄" (handler)。
2、关闭文件
f.close()
文件在打开完之后,使用完了之后,也就一定要关闭!
打开文件,其实是在申请一定的系统资源,不再使用文件的时候,资源就应该及时释放。
“有借有还再借不难”(图书馆的书是有限的!!!)
否则就可能造成文件资源泄露,进一步的导致其他部分的代码无法顺利打开文件了。
正是因为一个系统的资源是有限的,因此一个程序能打开的文件个数,也是有上限的!
flist = []
count = 0
while True:
f = open("E:/test/test.txt", "r")
flist.append(f)
count += 1
print(f'打开文件的个数:{count}')
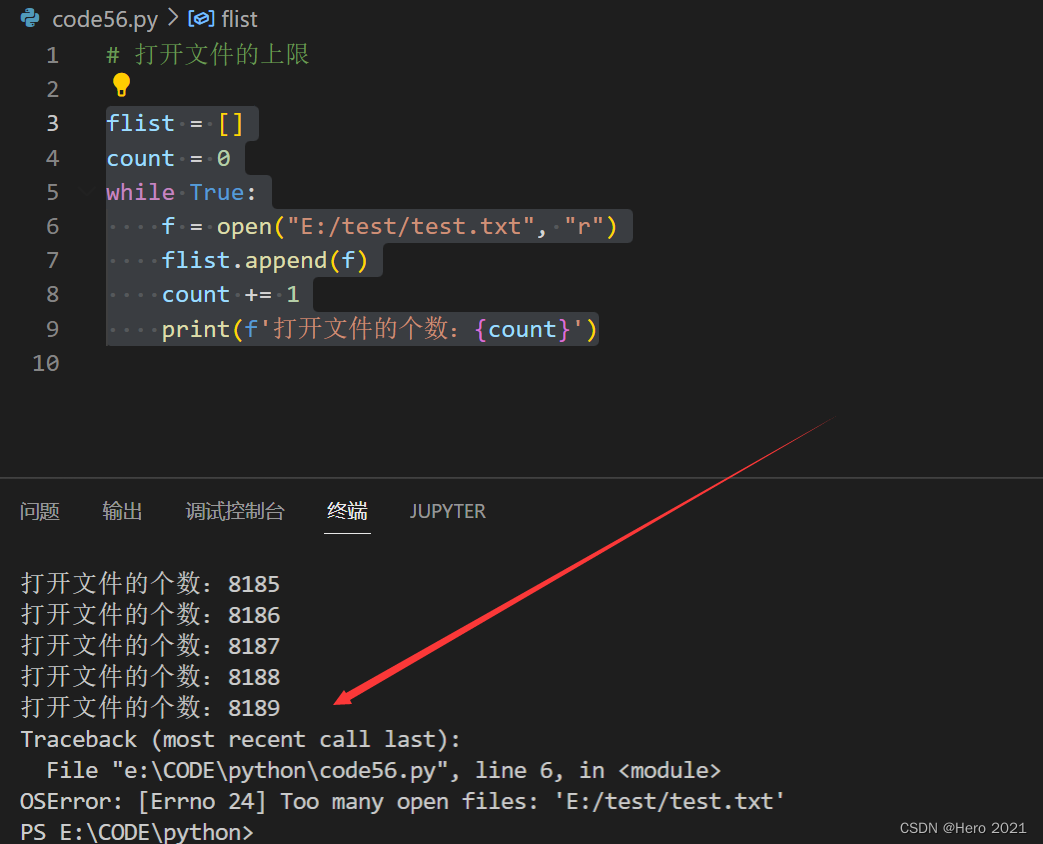
打开文件的个数:8189
在系统中,是可以通过一些设置项,来配置能打开文件的最大数目的
但是无论配置多少,都不是无穷无尽的,就需要记得要及时关闭,释放资源
flist = []
count = 0
while True:
f = open("E:/test/test.txt", "r")
flist.append(f)
f.close()
count += 1
print(f'打开文件的个数:{count}')
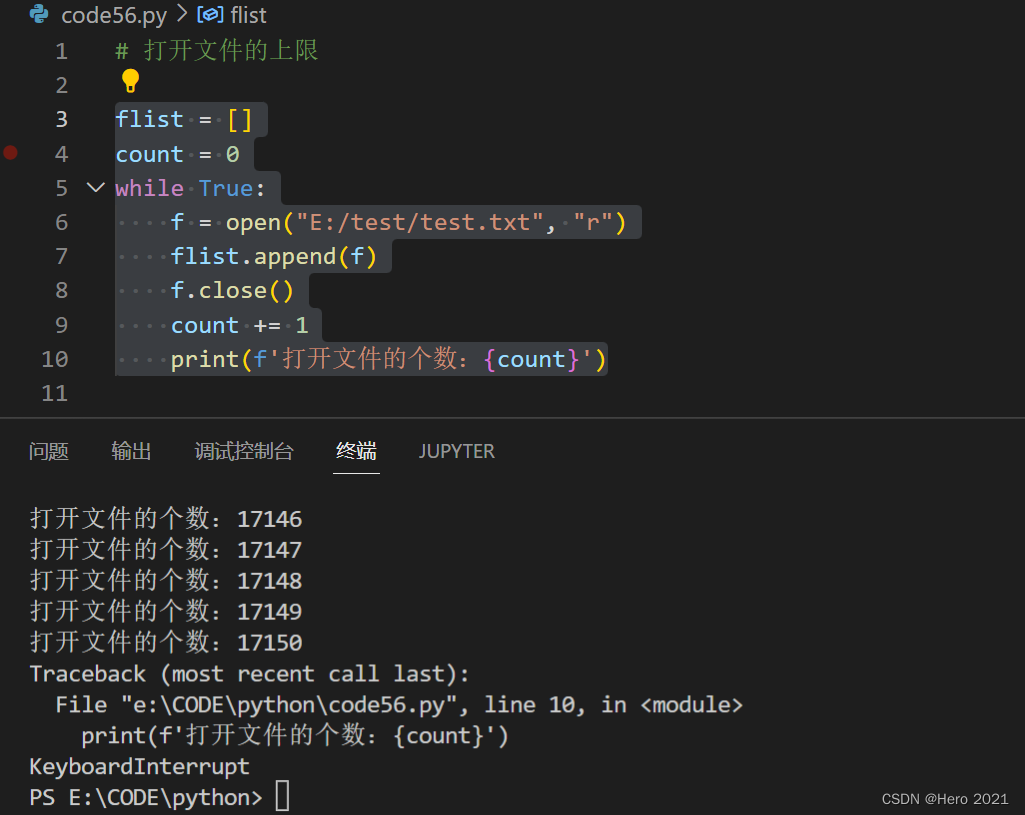
8189+ 3=>8192=>2的13次方! 使用二进制来表示数据的 。(0,1,2)
在程序猿眼里,1000不是一个很整齐的数字。
1024(2的十次方)这才是一个比较整齐的数字!
因此计算机里的很多数据都是按照2的多少次方这样的方式来表示的
每个程序在启动的时候,都会默认打开三个文件:标准输入、标准输出、标准错误
Python有一个重要的机制,垃圾回收机制(GC),自动的把不使用的变量,给进行释放
虽然Python给了我们一个后手,让我们一定程度的避免上述问题,但是也不能完全依赖,自动释放机制,因为自动释放不一定及时,因此还是要尽量手动释放,万无一失
3、写文件
write直接写
# write 写文件
f = open("E:/test/test.txt", 'w')
f.write("hello")
f.close()
写文件的时候,需要使用w的方式打开.如果是r方式打开,则会抛出异常。
如果是使用w方式打开,会清空掉文件原有的内容!
a追加写
# write 写文件
f = open("E:/test/test.txt", 'a')
f.write("world")
# f.write("world\n")
f.close()
会在末尾追加写入内容
可以加入\n换行
如果文件对象已经被关闭工那么意味着系统中和该文件相关的内存资源已经释放了.强行去写,就会出异常。
4、读文件
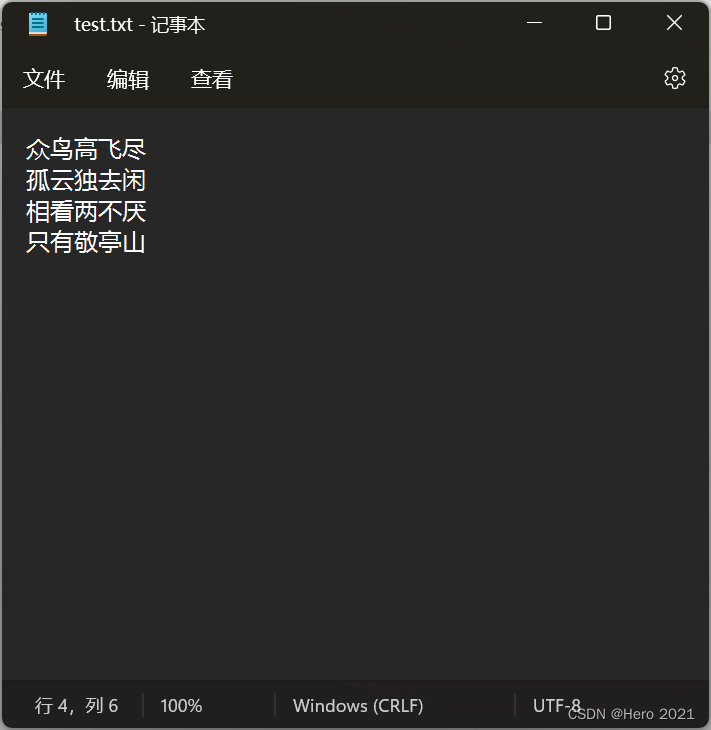
先预准备一些文本
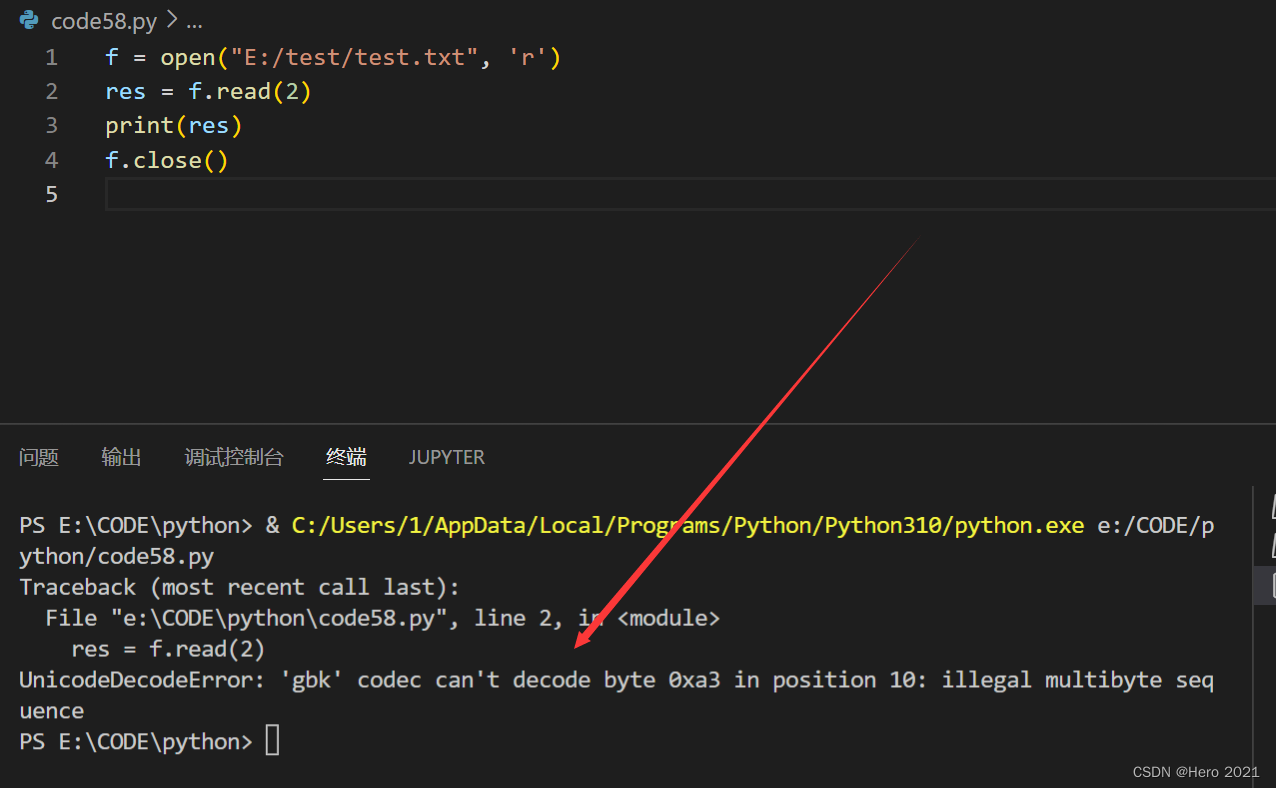
read来读取文件,指定读几个字符
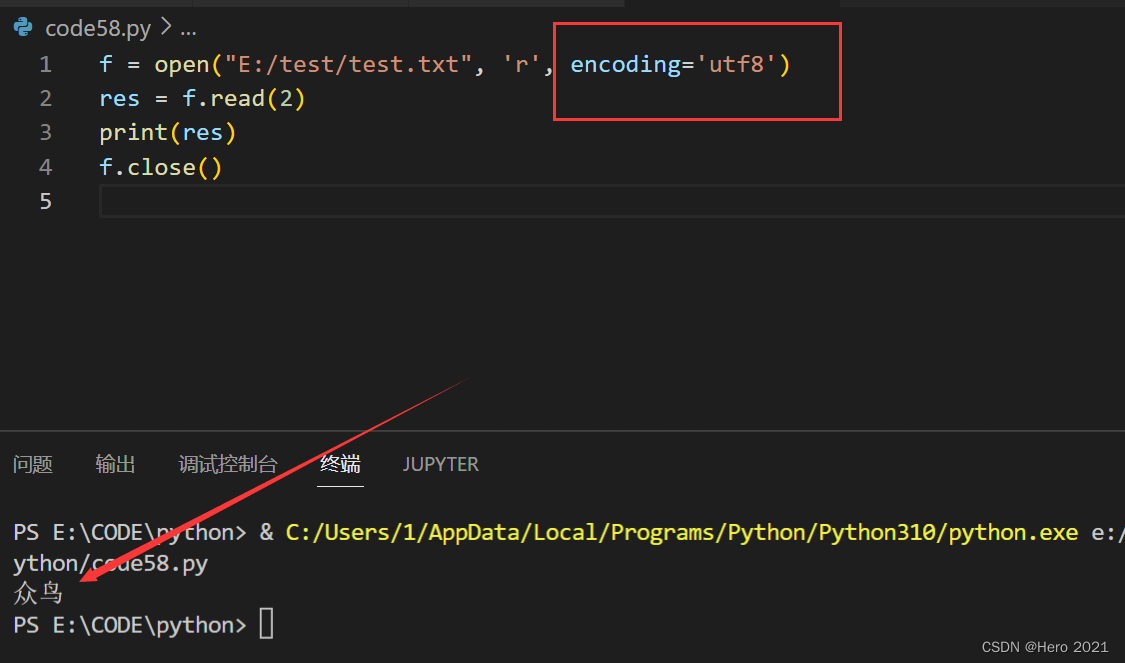
f = open("E:/test/test.txt", 'r')
res = f.read(2)
print(res)
f.close()
当文件内容存在中文的时候, 读取文件内容不一定就顺利:
计算机表示中文的时候, 会采取一定的编码方式, 我们称为 “字符集”
所谓 “编码方式” , 本质上就是使用数字表示汉字,我们知道, 计算机只能表示二进制数据. 要想表示英文字母, 或者汉字, 或者其他文字符号, 就都要通过编码。
最简单的字符编码就是 ascii,使用一个简单的整数就可以表示英文字母和阿拉伯数字.
但是要想表示汉字, 就需要一个更大的码表,一般常用的汉字编码方式, 主要是 GBK 和 UTF-8
必须要保证文件本身的编码方式, 和 Python 代码中读取文件使用的编码方式匹配, 才能避免出现上述问题.
Python3 中默认打开文件的字符集跟随系统, 而 Windows 简体中文版的字符集采用了 GBK, 所以,如果文件本身是 GBK 的编码, 直接就能正确处理。如果文件本身是其他编码(比如 UTF-8), 那么直接打开就可能出现上述问题。
此处我们使用的办法,是让代码按照encoding='utf8'来进行处理,相比于gbk, utf8是使用更广泛的编码方式
f = open("E:/test/test.txt", 'r', encoding='utf8')
- 按行来读取
更常见的需求,是按行来读取,最简单的办法,直接for循环
# 按行读取
f = open("E:/test/test.txt", 'r', encoding='utf8')
for line in f:
print(f"line= {line}")
f.close()
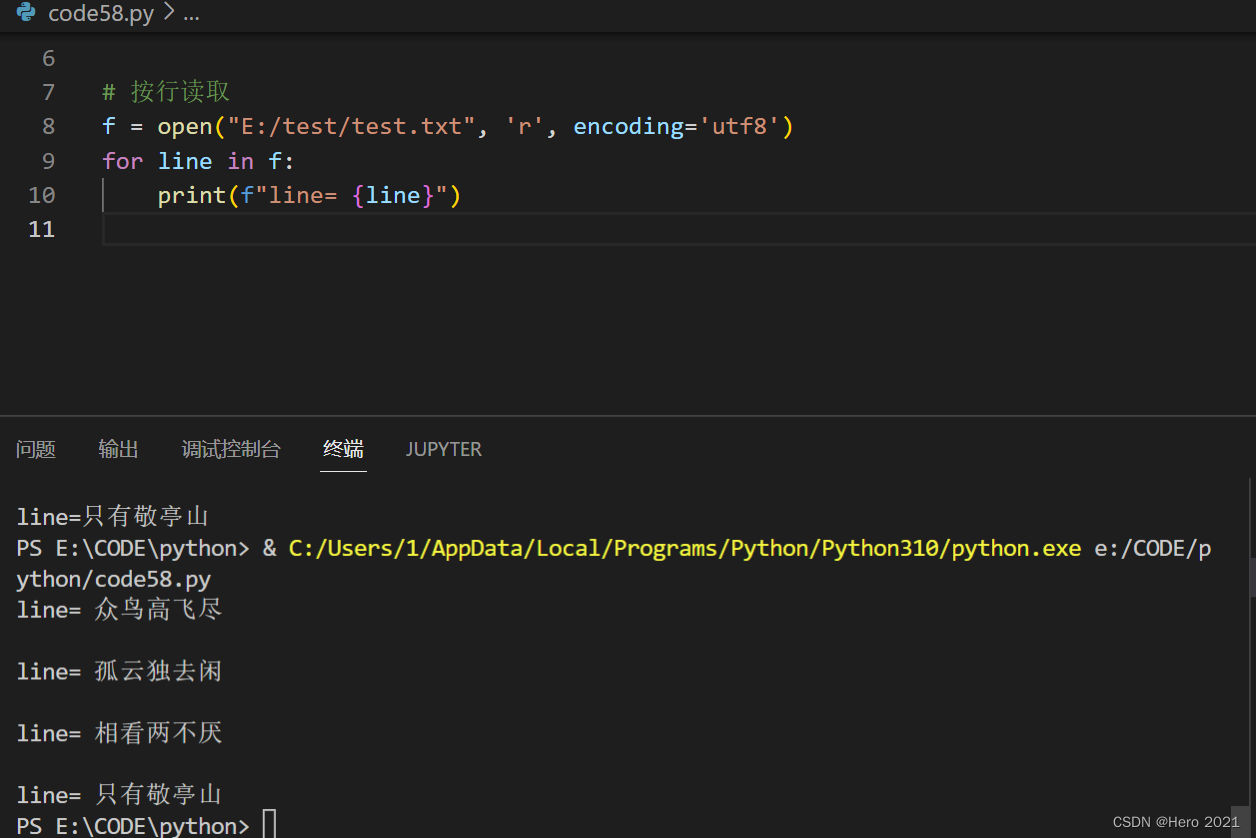
注意: 由于文件里每一行末尾都自带换行符, print 打印一行的时候又会默认加上一个换行符, 因此,打印结果看起来之间存在空行。
使用 print(f'line = {line}', end='') 手动把 print 自带的换行符去掉。
end参数就表示每次打印之后要在末尾加个啥默认是\n,修改成"也就是啥都不加!
- 使用
readlines()方法
直接把文件整个内容读取出来, 返回一个列表. 每个元素即为一行。
f = open("E:/test/test.txt", 'r', encoding='utf8')
lines = f.readlines()
print(lines)
f.close()
output:
['众鸟高飞尽\n', '孤云独去闲\n', '相看两不厌\n', '只有敬亭山']
5、使用上下文管理器
打开文件之后,是容易忘记关闭的。Python 提供了上下文管理器,来帮助程序猿自动关闭文件。
- 使用
with语句打开文件。 - 当
with内部的代码块执行完毕后,就会自动调用关闭方法。
with open("E:/test/test.txt", 'r', encoding='utf8') as f:
lines = f.readlines()
print(lines)
# 不必再写close()了
output:
['众鸟高飞尽\n', '孤云独去闲\n', '相看两不厌\n', '只有敬亭山']


























 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









