| package com.okey.util;
import java.io.*;
import java.nio.ByteBuffer;
import java.nio.channels.FileChannel;
/**
* Created with Okey
* User: Okey
* Date: 13-3-14
* Time: 上午11:29
* 读取文件工具
*/
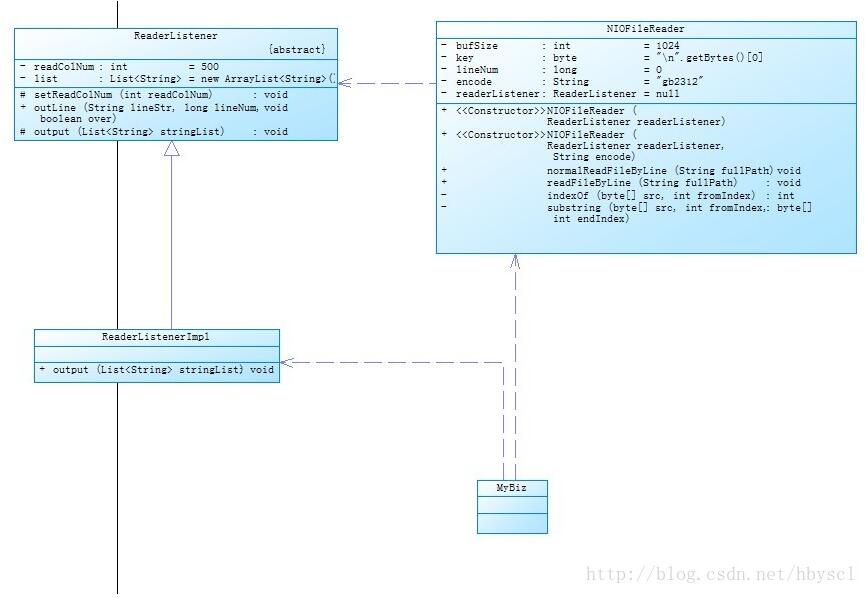
public class NIOFileReader {
// 每次读取文件内容缓冲大小,默认为1024个字节
private int bufSize = 1024;
// 换行符
private byte key = "\n".getBytes()[0];
// 当前行数
private long lineNum = 0;
// 文件编码,默认为gb2312
private String encode = "gb2312";
// 具体业务逻辑监听器
private ReaderListener readerListener;
/**
* 设置回调方法
* @param readerListener
*/
public NIOFileReader(ReaderListener readerListener) {
this.readerListener = readerListener;
}
/**
* 设置回调方法,并指明文件编码
* @param readerListener
* @param encode
*/
public NIOFileReader(ReaderListener readerListener, String encode) {
this.encode = encode;
this.readerListener = readerListener;
}
/**
* 普通io方式读取文件
* @param fullPath
* @throws Exception
*/
public void normalReadFileByLine(String fullPath) throws Exception {
File fin = new File(fullPath);
if (fin.exists()) {
BufferedReader reader = new BufferedReader(new InputStreamReader(new FileInputStream(fin), encode));
String lineStr;
while ((lineStr = reader.readLine()) != null) {
lineNum++;
readerListener.outLine(lineStr.trim(), lineNum, false);
}
readerListener.outLine(null, lineNum, true);
reader.close();
}
}
/**
* 使用NIO逐行读取文件
*
* @param fullPath
* @throws java.io.FileNotFoundException
*/
public void readFileByLine(String fullPath) throws Exception {
File fin = new File(fullPath);
if (fin.exists()) {
FileChannel fcin = new RandomAccessFile(fin, "r").getChannel();
try {
ByteBuffer rBuffer = ByteBuffer.allocate(bufSize);
// 每次读取的内容
byte[] bs = new byte[bufSize];
// 缓存
byte[] tempBs = new byte[0];
String line = "";
while (fcin.read(rBuffer) != -1) {
int rSize = rBuffer.position();
rBuffer.rewind();
rBuffer.get(bs);
rBuffer.clear();
byte[] newStrByte = bs;
// 如果发现有上次未读完的缓存,则将它加到当前读取的内容前面
if (null != tempBs) {
int tL = tempBs.length;
newStrByte = new byte[rSize + tL];
System.arraycopy(tempBs, 0, newStrByte, 0, tL);
System.arraycopy(bs, 0, newStrByte, tL, rSize);
}
int fromIndex = 0;
int endIndex = 0;
// 每次读一行内容,以 key(默认为\n) 作为结束符
while ((endIndex = indexOf(newStrByte, fromIndex)) != -1) {
byte[] bLine = substring(newStrByte, fromIndex, endIndex);
line = new String(bLine, 0, bLine.length, encode);
lineNum++;
// 输出一行内容,处理方式由调用方提供
readerListener.outLine(line.trim(), lineNum, false);
fromIndex = endIndex + 1;
}
// 将未读取完成的内容放到缓存中
tempBs = substring(newStrByte, fromIndex, newStrByte.length);
}
// 将剩下的最后内容作为一行,输出,并指明这是最后一行
String lineStr = new String(tempBs, 0, tempBs.length, encode);
readerListener.outLine(lineStr.trim(), lineNum, true);
} catch (Exception e) {
e.printStackTrace();
} finally {
fcin.close();
}
} else {
throw new FileNotFoundException("没有找到文件:" + fullPath);
}
}
/**
* 查找一个byte[]从指定位置之后的一个换行符位置
* @param src
* @param fromIndex
* @return
* @throws Exception
*/
private int indexOf(byte[] src, int fromIndex) throws Exception {
for (int i = fromIndex; i < src.length; i++) {
if (src[i] == key) {
return i;
}
}
return -1;
}
/**
* 从指定开始位置读取一个byte[]直到指定结束位置为止生成一个全新的byte[]
* @param src
* @param fromIndex
* @param endIndex
* @return
* @throws Exception
*/
private byte[] substring(byte[] src, int fromIndex, int endIndex) throws Exception {
int size = endIndex - fromIndex;
byte[] ret = new byte[size];
System.arraycopy(src, fromIndex, ret, 0, size);
return ret;
}
}
| 





















 1799
1799











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









