






 本文详细介绍了去噪扩散概率模型DDPM,包括其原理(从噪声生成图像)、网络结构(基于Unet的参数化马尔可夫链),以及代码实现中的关键模块如正弦位置编码、注意力机制和ResidualBlock。DDPM展示了在图像生成中的潜力,未来可能应用在更多数据模式和机器学习系统中。
本文详细介绍了去噪扩散概率模型DDPM,包括其原理(从噪声生成图像)、网络结构(基于Unet的参数化马尔可夫链),以及代码实现中的关键模块如正弦位置编码、注意力机制和ResidualBlock。DDPM展示了在图像生成中的潜力,未来可能应用在更多数据模式和机器学习系统中。
去噪扩散概率模型DDPM
paper:https://arxiv.org/abs/2006.11239
目录
扩散模型与其它主流生成模型的对比如下所示:

原理介绍
扩散模型:从噪声(采样自简单的分布)生成目标数据样本。
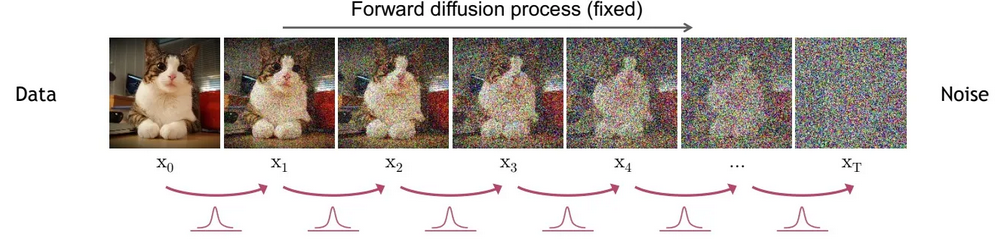
扩散模型包括两个过程:前向过程(forward process)和反向过程(reverse process),前向过程又称为扩散过程(diffusion process),是对一张图像逐渐添加高斯噪音直至变成随机噪音。而反向生成过程是去噪音过程,从一个随机噪音开始逐渐去噪音直至生成一张图像。
前向和反向过程都是一个参数化的马尔可夫链(Markov chain),其中反向过程可用于生成数据样本(作用类似GAN中的生成器,只不过GAN生成器会有维度变化,而DDPM的反向过程没有维度变化)。

到
:前向,逐步加噪的前向过程,噪声是已知的。从原始图片逐步加噪到纯噪声。
到
:反向,将随机噪声还原为输入。该过程需要学习一个去噪过程,直到还原一张图片。
前向过程
前向过程是加噪的过程,前向过程中图像只和上一时刻的
有关。原始数据x0,扩散T步,每一步都对上一时刻的数据xt-1加噪音。可以视为马尔科夫过程:
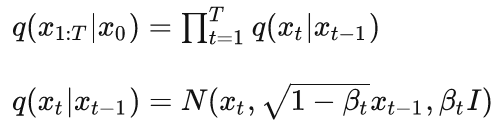
是预先定义好的每一步的方差,对于扩散模型,称不同step的方差设定为variance schedule或者noise schedule。由时间1~T递增。
扩散过程的一个重要特性是可以直接基于原始数据x0来对任意t步的xt进行采样:![]() 。
。
根据以上公式,可以通过重参数化采样得到:
![]()
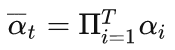
推导得到x0和xt的关系:
![]()
推导过程:
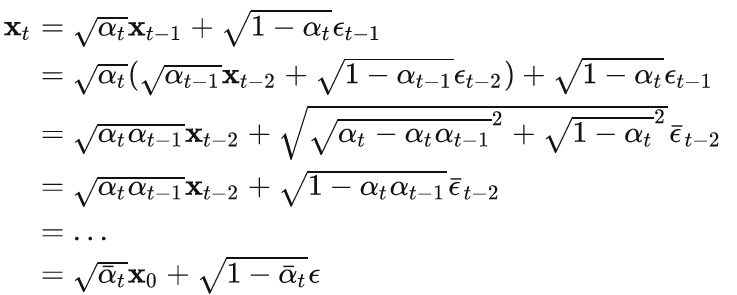
逆向过程
逆向过程是去噪的过程,也是生成数据的过程。如果知道反向过程的每一步的真实分布![]() ,就可以通过随机噪声
,就可以通过随机噪声逐步生成一张真实图像。

DDPM使用神经网络![]() 拟合逆向过程
拟合逆向过程![]() 。
。
将反向过程也定义为一个马尔卡夫链,由一系列用神经网络参数化的高斯分布来组成:
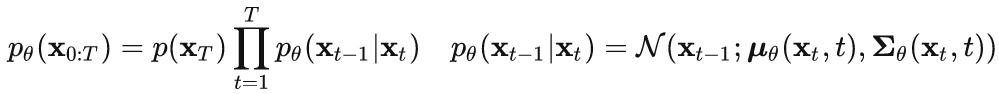
![]() 为参数化的高斯分布,均值和方差由训练的网络
为参数化的高斯分布,均值和方差由训练的网络![]() 和
和![]() 给出。扩散模型得到这些训练好的网络,构成了最终的生成模型。
给出。扩散模型得到这些训练好的网络,构成了最终的生成模型。
网络结构
论文的源代码采用Unet实现![]() 的预测,整个训练过程其实就是在训练Unet网络的参数。
的预测,整个训练过程其实就是在训练Unet网络的参数。
Unet职责
在前向过程还是反向过程,都是根据当前的样本和时间t预测噪声。
Gaussion Diffusion职责
前向过程:从1到T的时间采样一个时间t,生成一个随机噪声加到图片上,从Unet获取预测噪声,计算损失后更新Unet梯度。
反向过程:先从正态分布随机采样和训练样本一样大小的纯噪声图片,从T-1到0逐步重复以下步骤:从xt还原xt-1。
训练
优化目标:让网络预测的噪音和真实的噪音一致。

Algorithm1:Training
- 随机选择一个训练样本
- 从1~T中随机选取一个时间 t
- 随机产生噪音,计算当前所产生的带噪音数据
- 输入网络预测噪音,计算产生的噪音和预测的噪音的L2损失,计算梯度,更新权重。
- 重复以上步骤,直到网络Unet训练完成。
训练步骤中每个模块的交互如下图:

训练完成,进行采样:从一个随机噪音开始,并用训练好的网络预测噪音,然后计算条件分布的均值,然后用均值加标准差乘以一个随机噪音,直至t=0,完成新样本的生成。

Algorithm2:Sampling
- 从标准正态分布采样出一个随机噪音x。从T,...,1重复以下步骤:
- 从标准正态分布采样z,为重参数化做准备
- 根据模型求出
,结合xt和采样得到z利用重参数化技巧,得到xt-1
- 循环结束后返回x0
采样步骤中每个模块的交互如下图:

模型设计
扩散模型的核心就在于训练噪音预测模型,由于噪音和原始数据是同维度的,所以可以选择AutoEncoder架构来作为噪音预测模型。DDPM所采用的模型是一个基于residual block和attention block的U-Net模型。如下所示:

其中encoder分成不同的stages,每个stage都包含下采样模块来降低特征的空间大小(H和W)。decoder和encoder相反,是将encoder压缩的特征逐渐恢复。U-Net在decoder模块中还引入了skip connection,即concat了encoder中间得到的同维度特征,这有利于网络优化。
DDPM所采用的U-Net每个stage包含2个residual block,而且部分stage还加入了self-attention模块增加网络的全局建模能力。 另外,扩散模型其实需要的是个噪音预测模型,实际处理时,可以增加一个time embedding(类似transformer中的position embedding)来将timestep编码到网络中,从而只需要训练一个共享的U-Net模型。具体地,DDPM在各个residual block都引入了time embedding,如上图所示。
代码实现
代码主要分为以下几块:Unet、GaussianDiffusion、 TrainerUnet
1. Unet
网络结构如图:

1.1 正弦位置编码
DDPM每步训练是随机采样一个时间,为了让网络知道当前处理的是一系列去噪过程中的哪一个step,我们需要将当前t编码并传入网络之中,DDPM使用的Unet是time-condition Unet。
类似于Transformer的positional embedding,DDPM采用正弦位置编码(Sinusoidal Positional Embeddings),既需要位置编码有界又需要两个时间步长之间的距离与句子长度无关。为了满足这两点标准,一种思路是使用有界的周期性函数,而简单的有界周期性函数很容易想到sin和cos函数。
class SinusoidalPosEmb(nn.Cell):
def __init__(self, dim):
super().__init__()
half_dim = dim // 2
emb = math.log(10000) / (half_dim - 1)
emb = np.exp(np.arange(half_dim) * - emb)
self.emb = Tensor(emb, mindspore.float32)
self.Concat = _get_cache_prim(ops.Concat)(-1)
def construct(self, x):
emb = x[:, None] * self.emb[None, :]
emb = self.Concat((ops.sin(emb), ops.cos(emb)))
return embDDPM的Unet有ResidualBlock和Attention Module
1.2 Attention
Attention的本质是从人类视觉注意力机制中获得灵感。大致是我们视觉在感知东西的时候,一般不会是一个场景从到头看到尾每次全部都看,而往往是根据需求观察注意特定的一部分。具体可以参考博客:TheLongGoodbye:浅谈Attention机制的理解
class Attention(nn.Cell):
def __init__(self, dim, heads=4, dim_head=32):
super().__init__()
self.scale = dim_head ** -0.5
self.heads = heads
hidden_dim = dim_head * heads
self.to_qkv = _get_cache_prim(Conv2d)(dim, hidden_dim * 3, 1, pad_mode='valid', has_bias=False)
self.to_out = _get_cache_prim(Conv2d)(hidden_dim, dim, 1, pad_mode='valid', has_bias=True)
self.map = ops.Map()
self.partial = ops.Partial()
self.bmm = BMM()
self.split = ops.Split(axis=1, output_num=3)
self.softmax = ops.Softmax(-1)
def construct(self, x):
b, c, h, w = x.shape
qkv = self.split(self.to_qkv(x))
q, k, v = self.map(self.partial(rearrange, self.heads), qkv)
q = q * self.scale
sim = self.bmm(q.swapaxes(2, 3), k)
attn = self.softmax(sim)
out = self.bmm(attn, v.swapaxes(2, 3))
out = out.swapaxes(-1, -2).reshape((b, -1, h, w))
return self.to_out(out)1.3 Residual Block
是ResNet的核心模块,可以防止网络退化。
class Residual(nn.Cell):
"""残差块"""
def __init__(self, fn):
super().__init__()
self.fn = fn
def construct(self, x, *args, **kwargs):
return self.fn(x, *args, **kwargs) + x扩散模型
要提前根据设计的noise schedule来计算一些系数,并实现一些扩散过程和生成过程:
class GaussianDiffusion:
def __init__(
self,
timesteps=1000,
beta_schedule='linear'
):
self.timesteps = timesteps
if beta_schedule == 'linear':
betas = linear_beta_schedule(timesteps)
elif beta_schedule == 'cosine':
betas = cosine_beta_schedule(timesteps)
else:
raise ValueError(f'unknown beta schedule {beta_schedule}')
self.betas = betas
self.alphas = 1. - self.betas
self.alphas_cumprod = torch.cumprod(self.alphas, axis=0)
self.alphas_cumprod_prev = F.pad(self.alphas_cumprod[:-1], (1, 0), value=1.)
# calculations for diffusion q(x_t | x_{t-1}) and others
self.sqrt_alphas_cumprod = torch.sqrt(self.alphas_cumprod)
self.sqrt_one_minus_alphas_cumprod = torch.sqrt(1.0 - self.alphas_cumprod)
self.log_one_minus_alphas_cumprod = torch.log(1.0 - self.alphas_cumprod)
self.sqrt_recip_alphas_cumprod = torch.sqrt(1.0 / self.alphas_cumprod)
self.sqrt_recipm1_alphas_cumprod = torch.sqrt(1.0 / self.alphas_cumprod - 1)
# calculations for posterior q(x_{t-1} | x_t, x_0)
self.posterior_variance = (
self.betas * (1.0 - self.alphas_cumprod_prev) / (1.0 - self.alphas_cumprod)
)
# below: log calculation clipped because the posterior variance is 0 at the beginning
# of the diffusion chain
self.posterior_log_variance_clipped = torch.log(self.posterior_variance.clamp(min =1e-20))
self.posterior_mean_coef1 = (
self.betas * torch.sqrt(self.alphas_cumprod_prev) / (1.0 - self.alphas_cumprod)
)
self.posterior_mean_coef2 = (
(1.0 - self.alphas_cumprod_prev)
* torch.sqrt(self.alphas)
/ (1.0 - self.alphas_cumprod)
)
# get the param of given timestep t
def _extract(self, a, t, x_shape):
batch_size = t.shape[0]
out = a.to(t.device).gather(0, t).float()
out = out.reshape(batch_size, *((1,) * (len(x_shape) - 1)))
return out
# forward diffusion (using the nice property): q(x_t | x_0)
def q_sample(self, x_start, t, noise=None):
if noise is None:
noise = torch.randn_like(x_start)
sqrt_alphas_cumprod_t = self._extract(self.sqrt_alphas_cumprod, t, x_start.shape)
sqrt_one_minus_alphas_cumprod_t = self._extract(self.sqrt_one_minus_alphas_cumprod, t, x_start.shape)
return sqrt_alphas_cumprod_t * x_start + sqrt_one_minus_alphas_cumprod_t * noise
# Get the mean and variance of q(x_t | x_0).
def q_mean_variance(self, x_start, t):
mean = self._extract(self.sqrt_alphas_cumprod, t, x_start.shape) * x_start
variance = self._extract(1.0 - self.alphas_cumprod, t, x_start.shape)
log_variance = self._extract(self.log_one_minus_alphas_cumprod, t, x_start.shape)
return mean, variance, log_variance
# Compute the mean and variance of the diffusion posterior: q(x_{t-1} | x_t, x_0)
def q_posterior_mean_variance(self, x_start, x_t, t):
posterior_mean = (
self._extract(self.posterior_mean_coef1, t, x_t.shape) * x_start
+ self._extract(self.posterior_mean_coef2, t, x_t.shape) * x_t
)
posterior_variance = self._extract(self.posterior_variance, t, x_t.shape)
posterior_log_variance_clipped = self._extract(self.posterior_log_variance_clipped, t, x_t.shape)
return posterior_mean, posterior_variance, posterior_log_variance_clipped
# compute x_0 from x_t and pred noise: the reverse of `q_sample`
def predict_start_from_noise(self, x_t, t, noise):
return (
self._extract(self.sqrt_recip_alphas_cumprod, t, x_t.shape) * x_t -
self._extract(self.sqrt_recipm1_alphas_cumprod, t, x_t.shape) * noise
)
# compute predicted mean and variance of p(x_{t-1} | x_t)
def p_mean_variance(self, model, x_t, t, clip_denoised=True):
# predict noise using model
pred_noise = model(x_t, t)
# get the predicted x_0: different from the algorithm2 in the paper
x_recon = self.predict_start_from_noise(x_t, t, pred_noise)
if clip_denoised:
x_recon = torch.clamp(x_recon, min=-1., max=1.)
model_mean, posterior_variance, posterior_log_variance = \
self.q_posterior_mean_variance(x_recon, x_t, t)
return model_mean, posterior_variance, posterior_log_variance
# denoise_step: sample x_{t-1} from x_t and pred_noise
@torch.no_grad()
def p_sample(self, model, x_t, t, clip_denoised=True):
# predict mean and variance
model_mean, _, model_log_variance = self.p_mean_variance(model, x_t, t,
clip_denoised=clip_denoised)
noise = torch.randn_like(x_t)
# no noise when t == 0
nonzero_mask = ((t != 0).float().view(-1, *([1] * (len(x_t.shape) - 1))))
# compute x_{t-1}
pred_img = model_mean + nonzero_mask * (0.5 * model_log_variance).exp() * noise
return pred_img
# denoise: reverse diffusion
@torch.no_grad()
def p_sample_loop(self, model, shape):
batch_size = shape[0]
device = next(model.parameters()).device
# start from pure noise (for each example in the batch)
img = torch.randn(shape, device=device)
imgs = []
for i in tqdm(reversed(range(0, timesteps)), desc='sampling loop time step', total=timesteps):
img = self.p_sample(model, img, torch.full((batch_size,), i, device=device, dtype=torch.long))
imgs.append(img.cpu().numpy())
return imgs
# sample new images
@torch.no_grad()
def sample(self, model, image_size, batch_size=8, channels=3):
return self.p_sample_loop(model, shape=(batch_size, channels, image_size, image_size))
# compute train losses
def train_losses(self, model, x_start, t):
# generate random noise
noise = torch.randn_like(x_start)
# get x_t
x_noisy = self.q_sample(x_start, t, noise=noise)
predicted_noise = model(x_noisy, t)
loss = F.mse_loss(noise, predicted_noise)
return loss主要函数:
- q_sample:实现从x0到xt的扩散过程;
- q_posterior_mean_variance:后验分布的均值和方差的计算公式;
- predict_start_from_noise:q_sample的逆过程,根据预测的噪音来生成x0;
- p_mean_variance:根据预测的噪音来计算
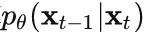 的均值和方差;
的均值和方差; - p_sample:单个去噪step;
- p_sample_loop:整个去噪音过程,即生成过程。
计算损失
基于Unet预测出noise,使用预测noise和真实noise计算损失:
def p_losses(self, x_start, t, noise, random_cond):
# 生成的真实noise
x = self.q_sample(x_start=x_start, t=t, noise=noise)
# if doing self-conditioning, 50% of the time, predict x_start from current set of times
if self.self_condition:
if random_cond:
_, x_self_cond = self.model_predictions(x, t)
x_self_cond = ops.stop_gradient(x_self_cond)
else:
x_self_cond = ops.zeros_like(x)
else:
x_self_cond = ops.zeros_like(x)
# model_out为基于U-net预测的pred_noise,此处self.model为Unet,ddpm默认预测目标是pred_noise。
model_out = self.model(x, t, x_self_cond)
if self.objective == 'pred_noise':
target = noise
elif self.objective == 'pred_x0':
target = x_start
elif self.objective == 'pred_v':
v = self.predict_v(x_start, t, noise)
target = v
else:
target = noise
# 计算损失值
loss = self.loss_fn(model_out, target)
loss = loss.reshape(loss.shape[0], -1)
loss = loss * extract(self.p2_loss_weight, t, loss.shape)
return loss.mean()采样
输出x_start,也就是原始图像,当sampling_time_steps< time_steps,用下方函数:
def ddim_sample(self, shape, clip_denoise=True):
batch = shape[0]
total_timesteps, sampling_timesteps, = self.num_timesteps, self.sampling_timesteps
eta, objective = self.ddim_sampling_eta, self.objective
# [-1, 0, 1, 2, ..., T-1] when sampling_timesteps == total_timesteps
times = np.linspace(-1, total_timesteps - 1, sampling_timesteps + 1).astype(np.int32)
# [(T-1, T-2), (T-2, T-3), ..., (1, 0), (0, -1)]
times = list(reversed(times.tolist()))
time_pairs = list(zip(times[:-1], times[1:]))
# 采样第一次迭代,Unet输入img为随机采样
img = np.random.randn(*shape).astype(np.float32)
x_start = None
for time, time_next in tqdm(time_pairs, desc='sampling loop time step'):
# time_cond = ops.fill(mindspore.int32, (batch,), time)
time_cond = np.full((batch,), time).astype(np.int32)
x_start = Tensor(x_start) if x_start is not None else x_start
self_cond = x_start if self.self_condition else None
predict_noise, x_start, *_ = self.model_predictions(Tensor(img, mindspore.float32),
Tensor(time_cond),
self_cond,
clip_denoise)
predict_noise, x_start = predict_noise.asnumpy(), x_start.asnumpy()
if time_next < 0:
img = x_start
continue
alpha = self.alphas_cumprod[time]
alpha_next = self.alphas_cumprod[time_next]
sigma = eta * np.sqrt(((1 - alpha / alpha_next) * (1 - alpha_next) / (1 - alpha)))
c = np.sqrt(1 - alpha_next - sigma ** 2)
noise = np.random.randn(*img.shape)
img = x_start * np.sqrt(alpha_next) + c * predict_noise + sigma * noise
img = self.unnormalize(img)
return img训练:
# train
epochs = 10
for epoch in range(epochs):
for step, (images, labels) in enumerate(train_loader):
optimizer.zero_grad()
batch_size = images.shape[0]
images = images.to(device)
# sample t uniformally for every example in the batch
t = torch.randint(0, timesteps, (batch_size,), device=device).long()
loss = gaussian_diffusion.train_losses(model, images, t)
if step % 200 == 0:
print("Loss:", loss.item())
loss.backward()
optimizer.step()总结
整个模型框架就可以描述为:
训练步骤: 通过目标函数训练一个生成噪音的模型
Inference (生成)步骤: 从标准高斯分布噪音中 ,用模型生成的噪音,一次次分离信号,直到得到我们想要的生成数据。
使用扩散模型提供了高质量的图像样本,发现了扩散模型和变分推理之间的联系,用于训练马尔可夫链、去噪分数匹配和退火朗之万动力学(以及扩展的基于能量的模型)、自回归模型和渐进有损压缩。由于扩散模型似乎对图像数据具有良好的归纳偏差,我们期待着研究它们在其他数据模式中的效用,以及作为其他类型的生成模型和机器学习系统的组件。
参考:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









