最近在学习java处理xml,本文主要是记录如何用用org.dom4j.Document对xml解析,并获取对应结点和对应结点的数据
//1、创建一个Dom4j框架提供的解析器对象
SAXReader saxReader = new SAXReader();
//2、使用saxReader对象把需要解析的XML文件读成一个Document对象
Document doucument = saxReader.read("E:\\myExercitation\\src\\xmlTestDemo.xml");
//3、从文档对象中解析XML文件的全部数据
Element root = doucument.getRootElement();
System.out.println(root.getName());
//4、获取根元素下的全部一级子元素
List<Element> elementList = root.elements("user");//获取指定的名称为user的全部一级子元素
//List<Element> elementList = root.elements();//获取根元素下的全部一级子元素
for (Element element : elementList) {
System.out.println(element.getName());
}
//5、获取当前元素下的某个子元素
Element people = root.element("curtData");
System.out.println(people.getText());
//如果下面有很多子元素user,默认获取第一个
Element user = root.element("user");
System.out.println(user.elementText("name"));
//6、获取元素的属性信息
System.out.println(user.attributeValue("userId"));
Attribute id = user.attribute("userId");
System.out.println(id.getName());
System.out.println(id.getValue());
List<Attribute> attributes = user.attributes();
for (Attribute attribute : attributes) {
System.out.println(attribute.getName() + "=" + attribute.getValue());
}
//7、如何获取全部的文本内容
System.out.println(user.elementText("name"));
System.out.println(user.elementText("sex"));
System.out.println(user.elementText("省份"));
System.out.println(user.elementTextTrim("data"));
System.out.println(user.elementText("dataParam"));
System.out.println(user.elementTextTrim("dataParam"));//取出文本去掉空格
Element data = user.element("dataParam");
System.out.println(data.getText());
System.out.println(data.getTextTrim());//取出文本去除前后空格
可粘贴以上代码到main方法中进行测试,其中saxReader.read("E:\\myExercitation\\src\\xmlTestDemo.xml");中的路劲名要换成你自己本地有xml文件的路径,

在这里我在我本地创建了一个xml文件,其中内容为
<?xml version="1.0" encoding="GBK" ?>
<!--以上抬头声明必须放在第一行,必须有-->
<!--根标签只能有一个-->
<req>
<user userId="1" info="重要">
<name>新亭</name>
<gender>男</gender>
<省份>广州</省份>
<data>3 < 2 && 5 > 4</data>
<dataParam>
<![CDATA[
3 < 2 && 5 > 4
]]>
</dataParam>
</user>
<curtData>curtData数据</curtData>
<curtData2>curtData2数据</curtData2>
<user userId="2" info="不重要">
<name>新亭2</name>
<gender>男</gender>
<省份>东莞</省份>
<data>3 < 2 && 5 > 4</data>
<dataParam>
<![CDATA[
3 < 2 && 5 > 4
]]>
</dataParam>
</user>
</req>
复制创建好的xml文件路径替换axReader.read("E:\\myExercitation\\src\\xmlTestDemo.xml");中的路径名称便可
代码运行的结果如下:
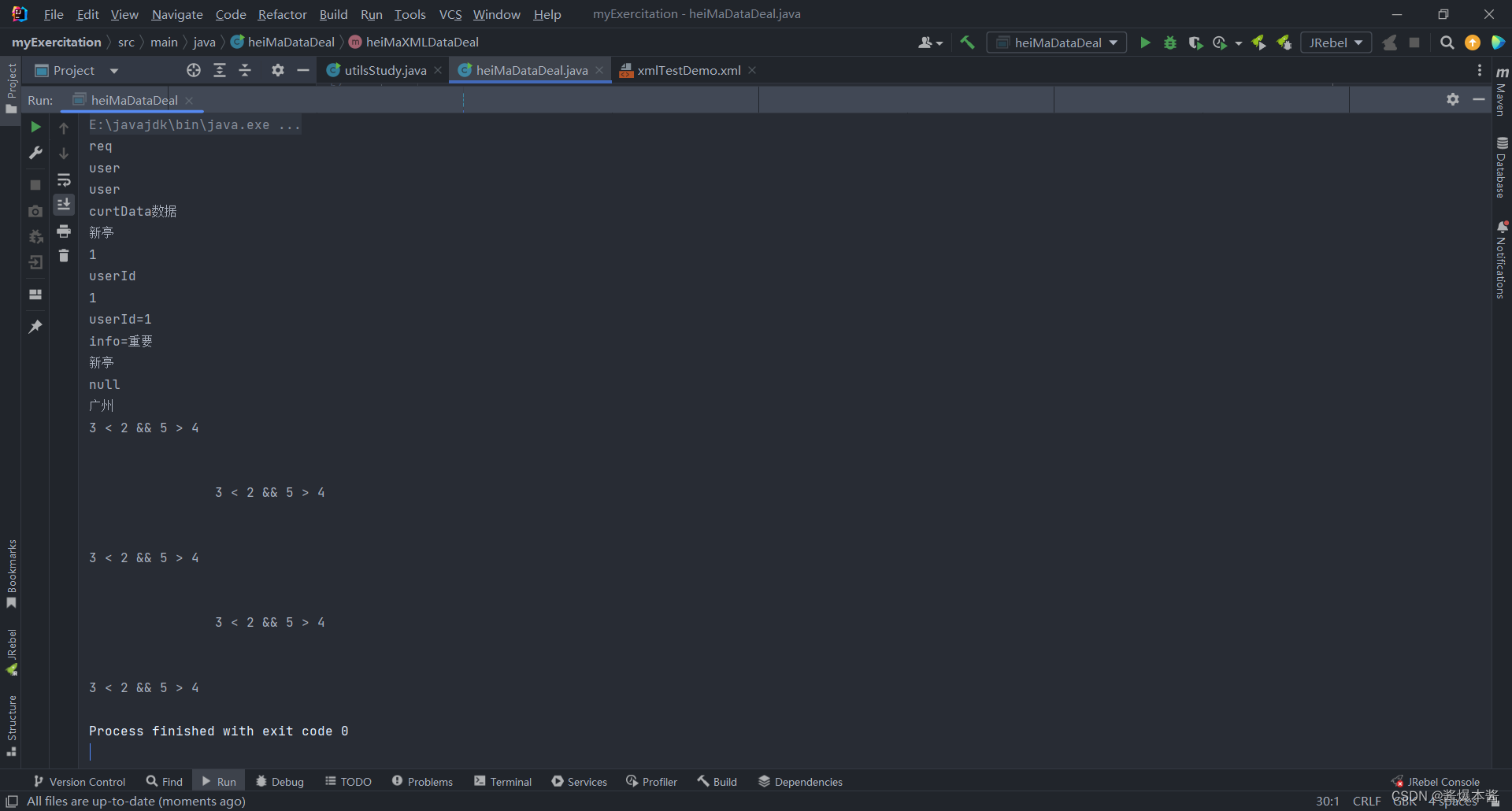
至此,本文结束,本文只为记录学习!!!





















 240
240











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









