









目录
1.3.2、csr (客户端渲染) 【不依赖任何流量或后台管理】
跳转链接 : NodeJs_01 _ 学习笔记
跳转链接 : NodeJs_03 _ 学习笔记
跳转链接 : NodeJs_04 _ 学习笔记
目标
- 搭建静态 web 服务器
- 接受 get 或 post 数据
- 设置好图片浏览器缓存
一、web 服务器
1.1、介绍
Web 服务器一般指的是网站服务器,是指驻留因特网上某一台或 N 台计算机的程序,可以处理浏览器等 Web 客户端的请求并返回相应响应,目前最主流的三个 Web 服务器是 Apache、 Nginx 、IIS、Tomcat 。

请求:
请求行、请求头、请求体( (如常用的请求动作中的 GET 就没有请求体) , POST请求 有 )
响应:
响应行、响应头、响应体( 内容:用户不需要打开控制台就能看到的东西 )

1.2、服务器相关概念
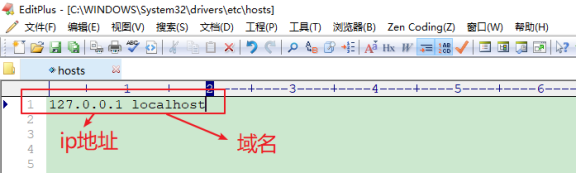
- ip 地址或域名 ( 主机 )
ip 地址:IP 地址就是互联网上每台计算机的唯一地址,因此 IP 地址具有唯一性。在开发期间,自己的电脑既是一台服务器,也是一个客户端,可以在本机浏览器中输入 127.0.0.1 进行访问。
域名:尽管 IP 地址能够唯一地标记网络上的计算机,但 IP 地址是一长串数字,不直观,而且不便于记忆,于是人们又发明了另一套字符型的地址方案,叫 域名地址 。IP 地址和域名是一一对应的关系,这份对应关系存放在一种叫做域名服务器 ( DNS ) 的电脑中。在开发测试期间, 127.0.0.1 对应的域名是 localhost 。

如果本地 localhost 无法使用,则是因为 本机中的 hosts 文件中没有匹配上 ip 地址
- 网络协议 ( 内置模块 http )
网络上的计算机之间交换信息, 就像我们说话用某种语言一样,在网络上的各台计算机之间也有一种语言,这就是 网络协议 ,不同的计算机之间必须使用相同的网络协议才能进行通信。如:TCP ( 传输层 , 一般用于做服务器 , 安全)、UDP ( 广播 )、HTTP ( 应用层 )、FTP 等等。
- 端口
服务器的端口号就像是现实生活中的门牌号一样。通过门牌号,外卖员就可以准确把外卖
送到你的手中。同样的道理,在一台电脑中,可以运行 N 多个 web 服务。每个 web 服务都对应一个唯一的端口号。客户端发送过来的网络请求,通过端口号,可以被准确地交给对应的 web 服务进行处理。1-1024 系统保留,不要用。最多为 65535
端口 ( 1-1024 系统保留,1024 之后的 80 => http / 443 => nginx
22 => ssh 20/21 => ftp 3306 => mysql )
注:服务器上的 端口号 是不可以重复的,必须是独一无二
http 服务默认端口号为 80 https 默认端口号 443
1.3、页面渲染模式
1.3.1、ssr ( 服务器端渲染 )
ssr ( Server Side Rendering ) :传统的渲染方式,由服务端把渲染的完整的页面响应给客户端。这样减少了一次客户端到服务端的一次 http 请求,加快相应速度,一般用于首屏的性能优化。
( 在服务器端既有数据 , 又进行整合 , 然后返回给客户端是个完整的 html )
优缺点:
1、利用 SEO(搜索引擎)( 利于提升排名 )
2、页面渲染时间短 , 响应速度快 ( 好比如 : 你点的外卖 , 可以直接吃 )
3、服务器压力过大
1.3.2、csr (客户端渲染) 【不依赖任何流量或后台管理】
CSR ( Client Side Rendering ):是一种目前流行的渲染方式,页面由 js 渲染,js 运行于浏览器端,所以称客户端渲染。( Vue / React : 把渲染的东西放到客户端 , 而服务器端只提供数据 )
( 一般应用于自媒体 ) ( 在服务器端创造数据 , 然后在客户端渲染 )
优缺点:
1、前后端并行开发,开发速度提升 ( 后端无需布局 , 只需提供 "数据" , 前端无需担心后端给的是什么语言 , 只需要有一个接口就可以显示)
2、首屏渲染时间比较长(首屏加载速度慢)( 好比如 : 你点的菜品 , 需要自己再加工 )
3、不利于 SEO ( 因为 SEO 要做 正则匹配 , 而我们的客户端渲染是通过 JS 动态生成渲染出来的 )
如何知道一个网站是服务器端渲染还是客户端渲染 ?
进入一个网站 => 右键查看源代码 => 你能看到源代码的 html 结构的 => 就是服务器端渲染
看不到完整的 html 结构的 => 就是客户端渲染
服务器端渲染 ( ssr )
数据处理
视图渲染
客户端渲染 ( csr )
数据处理
1.4、创建 web 服务
NodeJs 是通过官方提供的 http 模块来创建 web 服务器的模块。通过几行简单的代码,就能轻松的手写一个 web 服务,从而对外提供 web 服务 。
- 创建 web 服务基本步骤

检测你的服务器是否启动成功 :
Windows 中 :
( 1 ) 通过 360 查看 :


( 2 ) 通过 命令行 查看 :

( 3 ) 浏览器内输入你监听的地址 => localhost:8000/

显示出来 " 处理程序 "


http 响应 :

Apizza 插件 :

http 请求 :

// 创建一个http服务 -- http服务是被动的,而且它还是http1.x无状态的,连接一但断开就不认识
// 引入http模块
const http = require('http')
// 创建http服务实例
const server = http.createServer()
// 监听客户端请求
// req 请求对象,获取客户端所发送过来的所有的数据 行头体
// res 响应对象,返回数据给请求客户端 行头体
server.on('request', (req, res) => {
res.send = function (data) {
if (typeof data != 'object') {
if (typeof data != 'string') {
data += ''
}
res.setHeader('content-type', 'text/html;charset=utf-8')
res.end(data)
} else {
if (data instanceof Buffer) { // 原型链查找
res.setHeader('content-type', 'text/html;charset=utf-8')
res.end(data)
} else {
res.setHeader('content-type', 'application/json;charset=utf-8')
res.end(JSON.stringify(data))
}
}
/* if (typeof data == 'string' || data instanceof Buffer) {
res.setHeader('content-type', 'text/html;charset=utf-8')
res.end(data)
} else {
res.setHeader('content-type', 'application/json;charset=utf-8')
res.end(JSON.stringify(data))
} */
}
// 响应状态码
// res.statusCode = 404
// 响应头
// res.setHeader('content-type', 'text/plain;charset=utf-8')
// res.setHeader('content-type', 'text/html;charset=utf-8')
// res.setHeader('content-type', 'application/json;charset=utf-8')
// // 响应体 end它只接受 Buffer或string类型
// // res.end('<h3>你好Web服务器</h3>')
// res.end(JSON.stringify({ id: 1, name: 'aaa' }))
res.send(123)
// res.send({ id: 1, name: 'bbb' })
})
// 监听的端口号
// 服务器一般不会有一个网卡,是多块网卡,如果你此处写具体的ip,则对应的网卡入口才能被访问到服务
// 如果参数2不写,则获取的ip地址会以ipv6的形式返回,不直观,现在用的是ipv4
server.listen(3000, '0.0.0.0', () => console.log('server start ...'))// 引入http模块
const http = require('http')
// url处理
const url = require('url')
// 创建http服务实例
const server = http.createServer()
// 监听客户端请求
// req 请求对象,获取客户端所发送过来的所有的数据 行头体
// res 响应对象,返回数据给请求客户端 行头体
server.on('request', (req, res) => {
// 获取客户端请求相关信息
// 请求的pathname
// 解构赋值 query get请求参数
// let { pathname, query:get } = url.parse(req.url, true)
let { pathname, query } = url.parse(req.url, true)
// console.log(pathname, query);
// 请求动作
// console.log(req.method);
// 请求头
// console.log(req.headers['user-agent']);
// 获取当前请求ip地址
// console.log(req.socket.remoteAddress);
// 请求时间
// console.log(new Date());
res.setHeader('content-type', 'text/html;charset=utf-8')
res.end('你好世界')
})
// 监听的端口号
// 服务器一般不会有一个网卡,是多块网卡,如果你此处写具体的ip,则对应的网卡入口才能被访问到服务
// 如果参数2不写,则获取的ip地址会以ipv6的形式返回,不直观,现在用的是ipv4
server.listen(3000, '0.0.0.0', () => console.log('server start ...'))


面试时可能会问你 : 为什么第一次请求会有两个请求回来 ?
 => 原因 : 因为 ico 是所有的服务器都会主动 , 自动去请求这个 ico 图片
=> 原因 : 因为 ico 是所有的服务器都会主动 , 自动去请求这个 ico 图片
1.5、静态资源服务器
- 实现思路
客户端请求的每个资源 uri 地址,作为在本机服务器指定目录中的 文件。通过相关模块进行读取文件中数据进行响应给客户端,从而实现 静态服务器 。

实现步骤 ①、导入需要的模块 const http = require('http') const fs = require('fs') const path = require('path') const url = require('url') ②、使用 http 模块创建 web 服务器 const server = http.createServer() ③、将资源的请求 uri 地址 映射 为文件的存放 路径 // 事件监听 server.on('request', (req, res) => { // 得到请求的 uri let pathname = req.url pathname = pathname === '/' ? '/index.html' : pathname if (pathname !== '/favicon.ico') { // 请求静态地址 let filepath = path.join(__dirname, 'public', pathname) } }) ④、读取文件内容并响应给客户端 fs.readFile(filepath, (err, data) => { if (err) { res.statusCode = 500 res.end('服务器内部错误') }else{ res.end(data) } })
利用 fs 读取磁盘中真实存在的文件,把文件内容从通过响应体的形式,返回到浏览器中显示
映射关系
url 地址 和 本机磁盘中的路径的 映射
/ url 中的 根 ===》 磁盘中的路径 此路径称为 网站根目录
解析 url 地址 pathname query => req.url
url 模块 { pathname, query } = url.parse( req.url, true )根据 pathname 进行,磁盘中文件的映射对应,如果存在则读取文件响应,如果不存在则读指定的 404 文件,返回

http 静态服务器 :
http - ajax :
http - img :
http - api :




// 引入http模块
const http = require('http')
// 路径
const path = require('path')
const fs = require('fs')
// url处理
const url = require('url')
// 静态服务器网站根目录 网址中的 / => 实际路径中的public目录
const webRoot = path.resolve('./public')
// mimeType 头信息
/* const mimeType = {
'.html': 'text/html;charset=utf-8',
'.jpg': 'image/jpeg'
} */
const mimeType = require('./utils/mime')
// 创建http服务实例
const server = http.createServer()
server.on('request', (req, res) => {
// 请求的pathname
let { pathname, query } = url.parse(req.url, true)
// 不是网站中的图标才处理
if ('/favicon.ico' != pathname) {
// 路径连接 访问的文件真实路径地址
let filepath = path.join(webRoot, pathname)
// 判断路径中文件是否存在
if (fs.existsSync(filepath)) { // 文件存在
// 文件扩展名
let extname = path.extname(filepath).slice(1) || 'html'
try {
res.setHeader('content-type', mimeType[extname])
} catch (error) {
res.setHeader('content-type', mimeType['html'])
}
res.end(fs.readFileSync(filepath))
} else {
res.statusCode = 404
res.setHeader('content-type', 'text/html;charset=utf-8')
res.end('页面丢了')
}
}
})
// 监听的端口号
server.listen(3000, '0.0.0.0', () => console.log('server start ...'))1.6、get 数据获取
get 数据通过 地址栏 使用 query 方式进行传递的数据 例 ?id=1&name=zhangsan
// 引入 http 模块
const http = require('http');
const url = require('url');
// 创建 web 实例
http.createServer((req, res) => {
// 获取地址栏中 query 数据
let { query } = url.parse(req.url, true);
console.log(query);
}).listen(8080)url 模块 { pathname, query } = url.parse(request.url, true)
pathname 请求的 url 路径 对应到服务器中的具体的位置
query 获取的 get 数据
// 引入 http 模块
const http = require('http')
// 获取 url 地址中的参数
const url = require('url')
// 创建 web 实例
const server = http.createServer((req, res) => {
// get 数据的获取 req.url 并且使用 url 模块
// ?r=/home => home 页面
// let { pathname, query } = url.parse(req.url, true)
let { pathname, query: { r = '/web' } } = url.parse(req.url, true)
res.end(r)
})
server.listen(3000, '0.0.0.0', () => console.log('server start...')) 
1.7、post 数据获取
表单数据多数为 post 进行提交到 服务器端 。
使用了异步解决 , 解决异步又使用了回调 , 提供了两个方法 data 和 end
表单数据多数为 post 进行提交到服务器端。 -- nodejs 当作数据流来接受
// 引入 http 模块
const http = require('http');
// 把 query 字符串转为对象
const queryString = require('querystring');
// 创建 web 实例
http.createServer((req, res) => {
let data = '';
// 数据接受中
req.on('data', res => {
data += res
});
// 数据传输结束了 接受到的所有数据
req.on('end', () => {
// post 数据
let post = queryString.parse(data)
console.log(post);
});
}).listen(8080)
// 引入 http 模块 const http = require('http') // 获取 url 地址中的参数 const url = require('url') // 把 query 字符串转为对象 const querystring = require('querystring') // 创建 web 实例 http.createServer((req, res) => { // 接受 post 数据 if ('POST' === req.method) { // 数据容器 let postData = '' // post x-www-form-urlencoded 数据流 // 数据已经开发接受到了 req.on('data', buffer => postData += buffer) // 数据接受完毕 req.on('end', () => { // 接受完毕后,响应 let json = JSON.stringify(querystring.parse(postData)) res.end(json) }) } else { res.end('ok') } }).listen(3000, '0.0.0.0', () => console.log('server start...'))


案例 : 表单登陆
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>表单登陆</title>
</head>
<body>
<!-- <form action="/login" method="POST" enctype="multipart/form-data"> -->
<form action="/login" method="POST">
<div>
<label>
账号:
<input type="text" name="username">
</label>
</div>
<div>
<button type="submit">进入系统</button>
</div>
</form>
</body>
</html>// 引入 http 模块
const http = require('http')
// 获取url地址中的参数
const url = require('url')
const path = require('path')
const actions = require('./actions')
// 指定当前网站的根目录
let webRoot = path.resolve('./public')
// 创建web实例
http.createServer((req, res) => {
// 获取pathname和get请求数据
let { pathname, query } = url.parse(req.url, true)
// 拼接请求方法 大写转换小写
let fn = req.method.toLowerCase() + 'fn'
// 给请求对象添加额外属性,让它能向下传递
req.pathname = pathname
req.query = query
req.webRoot = webRoot
if ('/favicon.ico' !== pathname) {
try {
actions[fn](req, res)
} catch (error) {
res.end('服务没有办法操作了')
}
}
}).listen(3000, '0.0.0.0', () => console.log('server start...'))
1.8、浏览器缓存
浏览器缓存类型
- 强缓存
强缓存生效时的状态码为 200 , 无论你是否读缓存


- 协商缓存
协商缓存生效时则返回的http状态码为 304


强缓存 和 协商缓存 同时生效果,以强缓存为主,在设置时,一般两者都设置上。强缓存有失效时长,而协商缓存只要文件没有改变则不会失效。 ( 说白了 : 协商缓存是为了弥补强缓存失效过程那个间隙时你去访问的情况 , 防止访问时没有东西 , 就好比我的强缓存有效时长是一个小时 , 而你正好在一小时的失效时间点来访问 , 而这时候我还没有把新的缓存标识弄上去 , 客户就访问了 ; 而协商缓存就相当于一个动警 , 因为文件只要不改变 , 协商缓存就不失效 , 只有当你的文件修改了的时候 , 协商缓存才会失效 )



第二次不请求加载图片数据的话 , 可以节约资源 , 量一大 , 节约的资源可想而知 ,
现在所有的公司 , 所有的图片 , css , js 等, 都会设置上 , 只不过是时效可能稍有不同
一个问题 : 如何让强缓存失效呢 ?
破缓存方案 : 就是图片后面设置上 哈希值 ( 乱码值 ) => 好处 : 可以随机更换成与原来不一样的值
强缓存的坏处 : 你的文件改完 , 但是你的强缓存时效没有过期 , 它就不会有请求 , 不请求的话就无从知道你文件是否更改好了 , 那我们怎么知道更改了呢 ?? 就是我们把名字换掉就可以了
所以 我们 可以 加上一个 哈希值 , 那么我们的图片换了 , 我们就可以换一个 哈希值 , 哈希值变了 , 新的图片就会有新的缓存了

// 创建web服务 , 导入http模块
const http = require('http')
// 解析字符串后返回的 URL 对象,每个属性对应字符串的各个组成部分。
const url = require('url')
//fs模块提供了用于与文件进行交互相关方法
const fs = require('fs')
// path模块用于处理文件和目录(文件夹)的路径
const path = require('path')
const crypto = require('crypto')
// 定义静态网站根目录 / => public
const webRoot = path.resolve('./public')
// 创建web服务对象实例 -- 我的协议 http
http.createServer((req, res) => {
let { pathname, query } = url.parse(req.url, true)
// 设置缺省页面
pathname = pathname == '/' ? '/index.html' : pathname
// ? * + \w \d \s [] {} ()
if ('/favicon.ico' !== pathname) { // 有效的请求
let filepath = path.join(webRoot, pathname)
// 获取图片的扩展名
let extname = path.extname(pathname)
// 判断当前请求是图片,进行浏览器缓存设置
if (/\.(jpe?g|png|gif|ico|bmp)/.test(extname)) {// 图片
// 强缓存 -- 只要在服务器端通过响应头发送给浏览器就可以了 -- 返回的状态码为200
// 设置过期时间为1小时
res.setHeader('Expires', new Date(Date.now() + 3600 * 1000).toGMTString()) // http1.0
res.setHeader('Cache-Control', 'max-age=' + 3600) // http1.1
// 协商缓存 301 302 服务器端重定向 301永久重定向,302临时重定向
// 浏览和服务器端相互协商完成缓存,如果有缓存,返回304
// http1.0依赖于文件的修改时间,如果有修改,文件的修改时间就会改变
let stat = fs.statSync(filepath)
// 文件的修改时间
let mtime = new Date(stat.mtime).toGMTString()
res.setHeader('Last-Modified', mtime)
// http1.1协商缓存
// 依赖于当前文件的hash值来完成比对
let hashFileName = crypto.createHash('md5').update(fs.readFileSync(path.resolve(filepath))).digest('hex')
res.setHeader('Etag', hashFileName)
if (hashFileName == req.headers['if-none-match']) {
res.statusCode = 304
res.end('')
return;
}
if (mtime == req.headers['if-modified-since']) {
res.statusCode = 304
res.end('')
return;
}
}
// 响应体处理
fs.createReadStream(filepath).pipe(res)
}
}).listen(3000, '0.0.0.0')

图例 :


跳转链接 : NodeJs_01 _ 学习笔记
跳转链接 : NodeJs_03 _ 学习笔记
跳转链接 : NodeJs_04 _ 学习笔记
















 5773
5773











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









