







 文章介绍了作者提供的一份全面的Linux运维学习资料,旨在帮助程序员系统性地提升技能,包括从入门到进阶的课程,覆盖广泛的知识点,以及配套的实践项目和资源更新计划。
文章介绍了作者提供的一份全面的Linux运维学习资料,旨在帮助程序员系统性地提升技能,包括从入门到进阶的课程,覆盖广泛的知识点,以及配套的实践项目和资源更新计划。
先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前在阿里
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新Linux运维全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。

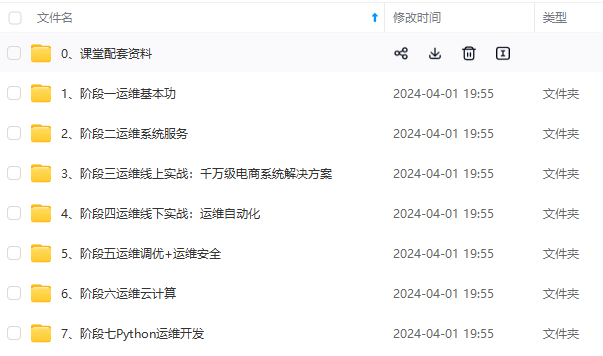
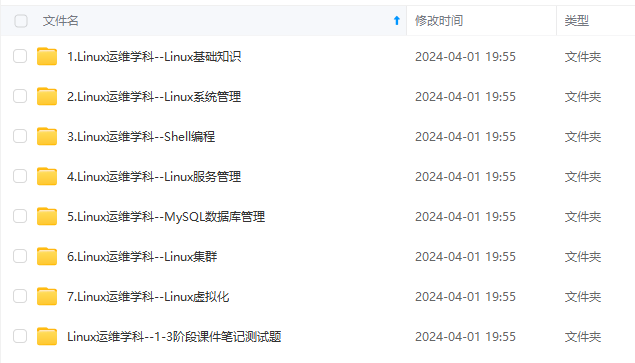
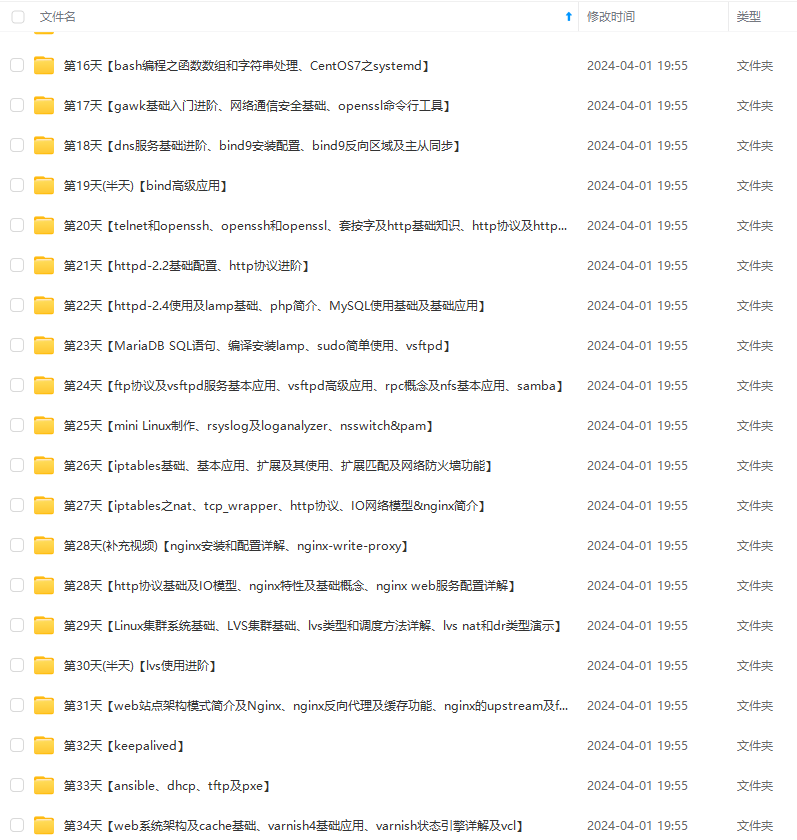
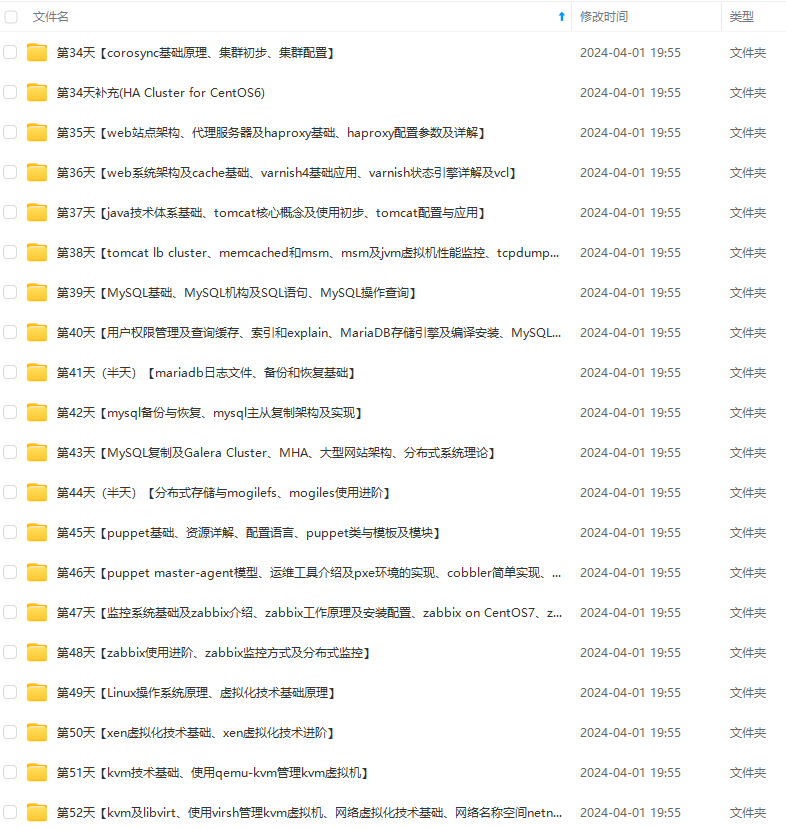
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上运维知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
echo
root@ubuntu:~# a=“hello,world”
root@ubuntu:~# echo a
a
root@ubuntu:~# echo &a
[1] 3091
a: command not found
[1]+ Done echo
root@ubuntu:~# echo $a
hello,world
root@ubuntu:~#
vim文本编辑器
最基本用法
vi somefile.4
1 首先会进入“一般模式”,此模式只接受各种快捷键,不能编辑文件内容
2 按i键,就会从一般模式进入编辑模式,此模式下,敲入的都是文件内容
3 编辑完成之后,按Esc键退出编辑模式,回到一般模式;
4 再按:,进入“底行命令模式”,输入wq命令,回车即可
常用快捷键
一些有用的快捷键(在一般模式下使用):
a 在光标后一位开始插入
A 在该行的最后插入
I 在该行的最前面插入
gg 直接跳到文件的首行
G 直接跳到文件的末行
dd 删除一行
3dd 删除3行
yy 复制一行
3yy 复制3行
p 粘贴
u undo
v 进入字符选择模式,选择完成后,按y复制,按p粘贴
ctrl+v 进入块选择模式,选择完成后,按y复制,按p粘贴
shift+v 进入行选择模式,选择完成后,按y复制,按p粘贴
查找并替换
1 显示行号
:set nu
2 隐藏行号
:set nonu
3 查找关键字
:/you ## 效果:查找文件中出现的you,并定位到第一个找到的地方,按n可以定位到下一个匹配位置(按N定位到上一个)
4 替换操作
😒/sad/bbb 查找光标所在行的第一个sad,替换为bbb
:%s/sad/bbb 查找文件中所有sad,替换为bbb
拷贝/删除/移动/更换文件名字
cp somefile.1 /home/hadoop/
rm /home/hadoop/somefile.1
rm -f /home/hadoop/somefile.1
mv /home/hadoop/somefile.1 …/
mv a.txt b.txt //把a.txt更名为b.txt
打包压缩
1、gzip压缩
gzip a.txt
2、解压
gunzip a.txt.gz
gzip -d a.txt.gz
3、bzip2压缩
bzip2 a
4、解压
bunzip2 a.bz2
bzip2 -d a.bz2
5、打包:将指定文件或文件夹
tar -cvf bak.tar ./aaa
将/etc/password追加文件到bak.tar中
tar -rvf bak.tar /etc/password
6、解压
tar -xvf bak.tar
7、打包并压缩
tar -zcvf a.tar.gz aaa/
8、解包并解压缩(重要的事情说三遍!!!)
tar -zxvf a.tar.gz
解压到/usr/下
tar -zxvf a.tar.gz -C /usr
9、查看压缩包内容
tar -ztvf a.tar.gz
zip/unzip
10、打包并压缩成bz2
tar -jcvf a.tar.bz2
11、解压bz2
tar -jxvf a.tar.bz2
常用查找命令的使用
1、查找可执行的命令所在的路径:
which ls
2、查找可执行的命令和帮助的位置:
whereis ls
3、从某个文件夹开始查找文件
find / -name “hadooop*”
find / -name “hadooop*” -ls
4、查找并删除
find / -name “hadooop*” -ok rm {} ;
find / -name “hadooop*” -exec rm {} ;
5、查找用户为hadoop的文件
find /usr -user hadoop -ls
6、查找用户为hadoop的文件夹
find /home -user hadoop -type d -ls
7、查找权限为777的文件
find / -perm -777 -type d -ls
8、在指定目录不分大小写查找某个文件
find ./sound/ -iname ft56Q.c
9、显示命令历史
history
grep命令
最常用的-全字匹配
grep -wrn weiqifa ./sound/
查找 某个字符串但是不在指定文件夹查找
grep -E “http” ./ -R --exclude-dir=./sound/
grep -E “http” . -R --exclude-dir={.git,res,bin}
排除扩展名为 java 和 js 的文件
grep -E “http” . -R --exclude=*.{java,js}
1 基本使用
查询包含hadoop的行
grep hadoop /etc/password
grep aaa ./*.txt
2 cut截取以:分割保留第七段
root@ubuntu:~/kernel_rk3399_yan4_dev/kernel# grep dsl /etc/passwd | cut -d: -f7
/bin/bash
root@ubuntu:~/kernel_rk3399_yan4_dev/kernel# grep dsl /etc/passwd
dsl❌1000:1000:dsl,:/home/dsl:/bin/bash
root@ubuntu:~/kernel_rk3399_yan4_dev/kernel#
3 查询不包含hadoop的行
grep -v hadoop /etc/passwd
4 正则表达包含hadoop
grep ‘hadoop’ /etc/passwd
5 正则表达(点代表任意一个字符)
grep ‘h.*p’ /etc/passwd
6 正则表达以hadoop开头
grep ‘^hadoop’ /etc/passwd
7 正则表达以hadoop结尾
grep ‘hadoop$’ /etc/passwd
规则:
. : 任意一个字符
a* : 任意多个a(零个或多个a)
a? : 零个或一个a
a+ : 一个或多个a
.* : 任意多个任意字符
. : 转义.
o{2} : o重复两次
查找不是以#开头的行
grep -v ‘^#’ a.txt | grep -v ‘^$’
以h或r开头的
grep ‘1’ /etc/passwd
不是以h和r开头的
grep ‘[hr]’ /etc/passwd
不是以h到r开头的
grep ‘[h-r]’ /etc/passwd
**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**[需要这份系统化的资料的朋友,可以点击这里获取!](https://bbs.csdn.net/topics/618542503)**
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
hr ↩︎















 1442
1442











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









