







 本文详细介绍了Cache的三种映射方式:直接映射、全相联映射和组相联映射,包括各自的优缺点和实际应用。直接映射简化了硬件设计但可能导致冲突;全相联映射提供更高的利用率和更低的冲突概率,但实现复杂;组相联映射是两者的折中方案。同时,文中通过例题展示了如何计算不同映射方式下的地址格式,并讨论了Cache命中率和平均访问时间的计算方法。
本文详细介绍了Cache的三种映射方式:直接映射、全相联映射和组相联映射,包括各自的优缺点和实际应用。直接映射简化了硬件设计但可能导致冲突;全相联映射提供更高的利用率和更低的冲突概率,但实现复杂;组相联映射是两者的折中方案。同时,文中通过例题展示了如何计算不同映射方式下的地址格式,并讨论了Cache命中率和平均访问时间的计算方法。
目录
cache的直接映射、组相联映射的地址格式
直接映射
直接映射是最简单的地址映射方式,它的硬件简单,成本低,地址变换速度快,而且不涉及替换算法问题。
但是这种方式不够灵活,Cache的存储空间得不到充分利用,每个主存块只有一个固定位置可存放,容易产生冲突,使Cache效率下降,因此只适合大容量Cache采用。
即使Cache中别的存储空间空着也不能占用,因此这两个块会不断地交替装入Cache中,导致命中率降低。
全相联映射
全相联映射方式比较灵活,主存的各块可以映射到Cache的任一块中,Cache的利用率高,块冲突概率低,只要淘汰Cache中的某一块,即可调入主存的任一块。
但是,由于Cache比较电路的设计和实现比较困难,这种方式只适合于小容量Cache采用。
需要存储tag来区分,tag可以理解为主存块的index,方便查找。
组相联映射
主存和Cache都分组,主存中一个组内的块数与Cache中的分组数相同,组间采用直接映射,组内采用全相联映射。
也就是说,将Cache分成2^u组,每组包含2^v块,主存块存放到哪个组是固定的,至于存到该组哪一块则是灵活的。
即主存的某块只能映射到Cache的特定组中的任意一块。主存的某块b与Cache的组k之间满足以下关系:k=b%(2^u)
组相联结构Cache是前两种方法的折中方案,适度兼顾二者的优点,尽量避免二者的缺点,因而得到普遍采用。
例题计算
6.某计算机的Cache与主存采用直接映射方式, Cache存储器容量为32块,主存容量为4096块,每块64字,按字编址。具体说明检索地址841H单元内容的过程。
主存容量4096=2^12 即内存地址=12
字地址=log2 64=6
行号=cache的块号=log2 32=5
标记位=内存地址-行号=12-5=7
检索地址841H 转换为二进制100001000001B 此时位数为12位,需补0
所以地址为000001 00001 000001B
标记位=1D,行号=1D,字地址=1D
首先定位到cache的第一块,标记1与cache该行的标记在比较器中比较,如果相同则命中,按字地址从该块中读取第一个字送CPU,否则,去主存中读。
7.一个组相联Cache由64行组成,每组4行。主存包含8K个块,每块256字。请表 示内存地址的格式。
字地址=log2 256=8
用cache的行除以路数 64/4=16=2^4 即组号=4
主存地址=log2 8*1024=13
标记位=主存地址-组号=13-4=9
主存标记 组号 块内地址 9位 4位 8位
cache命中率
h:cache命中率次数
Nc: cache完成存取的次数
Nm:主存完成存取的次数

平均访问时间:
ta:cache/主存系统的平均访问时间
tc:命中时cache的访问时间(即cache存取周期)
tm:未命中时主存的访问时间(包括访问cache未命中的时间和未命中后访问主存的时间,即主存存取周期)

访问效率:
r:主存慢于cache的倍率,![]()
访问效率e:cache访问时间与平均访问时间的比值。从表达式中可以看出,![]() 且
且,所以
![]() ,命中率h越高,r+(1-r)h 访问效率越高
,命中率h越高,r+(1-r)h 访问效率越高

例题
假设CPU执行某段程序时,cache完成存取的次数1900次,主存完成存取的次数100次。已知:Cache的存取周期为50ns,主存的存取周期为250ns。求命中率,Cache-主存系统的平均访问时间和效率。
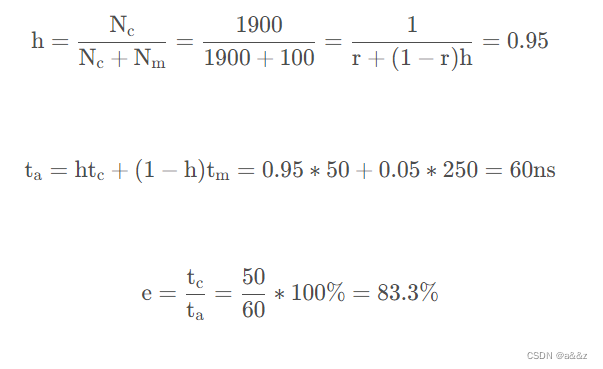



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









