







数据集地址:链接:https://pan.baidu.com/s/1kqhVPOqV5vklYYIFVAzAAA
提取码:3ch6
新建项目
====
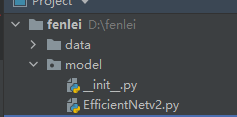
新建一个图像分类的项目,在项目的跟目录新建文件夹model,用于存放EfficientNetV2的模型代码,新建EfficientNetV2.py,将【图像分类】用通俗易懂代码的复现EfficientNetV2,入门的绝佳选择(pytorch)_AI浩-CSDN博客 复现的代码复制到里面,然后在model文件夹新建__init__.py空文件,model的目录结构如下:
在项目的根目录新建train.py,然后在里面写训练代码。
导入所需要的库
=======
import torch.optim as optim
import torch
import torch.nn as nn
import torch.nn.parallel
import torch.optim
import torch.utils.data
import torch.utils.data.distributed
import torchvision.transforms as transforms
import torchvision.datasets as datasets
from torch.autograd import Variable
from model.EfficientNetv2 import efficientnetv2_s
设置全局参数
======
设置BatchSize、学习率和epochs,判断是否有cuda环境,如果没有设置为cpu。
设置全局参数
modellr = 1e-4
BATCH_SIZE = 64
EPOCHS = 20
DEVICE = torch.device(‘cuda’ if torch.cuda.is_available() else ‘cpu’)
图像预处理
=====
在做图像与处理时,train数据集的transform和验证集的transform分开做,train的图像处理出了resize和归一化之外,还可以设置图像的增强,比如旋转、随机擦除等一系列的操作,验证集则不需要做图像增强,另外不要盲目的做增强,不合理的增强手段很可能会带来负作用,甚至出现Loss不收敛的情况。
数据预处理
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
])
transform_test = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
])
读取数据
====
使用Pytorch的默认方式读取数据。数据的目录如下图:
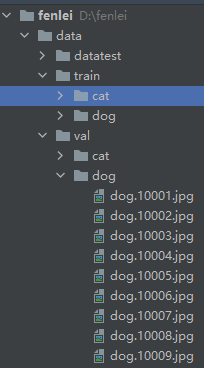
训练集,取了猫狗大战数据集中,猫狗图像各一万张,剩余的放到验证集中。
读取数据
dataset_train = datasets.ImageFolder(‘data/train’, transform)
print(dataset_train.imgs)
对应文件夹的label
print(dataset_train.class_to_idx)
dataset_test = datasets.ImageFolder(‘data/val’, transform_test)
对应文件夹的label
print(dataset_test.class_to_idx)
导入数据
train_loader = torch.utils.data.DataLoader(dataset_train, batch_size=BATCH_SIZE, shuffle=True)
test_loader = torch.utils.data.DataLoader(dataset_test, batch_size=BATCH_SIZE, shuffle=False)
设置模型
====
使用CrossEntropyLoss作为loss,模型采用efficientnetv2_s,由于没有Pytorch的预训练模型,我们只能从头开始训练。更改最后一层的全连接,将类别设置为2,然后将模型放到DEVICE。优化器选用Adam。
实例化模型并且移动到GPU
criterion = nn.CrossEntropyLoss()
model = efficientnetv2_s()
num_ftrs = model.classifier.in_features
model.classifier = nn.Linear(num_ftrs, 2)
model.to(DEVICE)
选择简单暴力的Adam优化器,学习率调低
optimizer = optim.Adam(model.parameters(), lr=modellr)
def adjust_learning_rate(optimizer, epoch):
“”“Sets the learning rate to the initial LR decayed by 10 every 30 epochs”“”
modellrnew = modellr * (0.1 ** (epoch // 50))
print(“lr:”, modellrnew)
for param_group in optimizer.param_groups:
param_group[‘lr’] = modellrnew
设置训练和验证
=======
定义训练过程
def train(model, device, train_loader, optimizer, epoch):
model.train()
sum_loss = 0
total_num = len(train_loader.dataset)
print(total_num, len(train_loader))
for batch_idx, (data, target) in enumerate(train_loader):
data, target = Variable(data).to(device), Variable(target).to(device)
output = model(data)
loss = criterion(output, target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
print_loss = loss.data.item()
sum_loss += print_loss
if (batch_idx + 1) % 50 == 0:
print(‘Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}’.format(
epoch, (batch_idx + 1) * len(data), len(train_loader.dataset),
-
- (batch_idx + 1) / len(train_loader), loss.item()))
ave_loss = sum_loss / len(train_loader)
print(‘epoch:{},loss:{}’.format(epoch, ave_loss))
#验证过程
def val(model, device, test_loader):
model.eval()
test_loss = 0
correct = 0
total_num = len(test_loader.dataset)
print(total_num, len(test_loader))
with torch.no_grad():
for data, target in test_loader:
data, target = Variable(data).to(device), Variable(target).to(device)
output = model(data)
loss = criterion(output, target)
_, pred = torch.max(output.data, 1)
correct += torch.sum(pred == target)
print_loss = loss.data.item()
test_loss += print_loss
correct = correct.data.item()
acc = correct / total_num
avgloss = test_loss / len(test_loader)
print(‘\nVal set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n’.format(
avgloss, correct, len(test_loader.dataset), 100 * acc))
训练
for epoch in range(1, EPOCHS + 1):
adjust_learning_rate(optimizer, epoch)
train(model, DEVICE, train_loader, optimizer, epoch)
val(model, DEVICE, test_loader)
torch.save(model, ‘model.pth’)
完成上面的代码后就可以开始训练,点击run开始训练,如下图:

验证
==
测试集存放的目录如下图:

第一步 定义类别,这个类别的顺序和训练时的类别顺序对应,一定不要改变顺序!!!!我们在训练时,cat类别是0,dog类别是1,所以我定义classes为(cat,dog)。
第二步 定义transforms,transforms和验证集的transforms一样即可,别做数据增强。
第三步 加载model,并将模型放在DEVICE里,
第四步 读取图片并预测图片的类别,在这里注意,读取图片用PIL库的Image。不要用cv2,transforms不支持。
import torch.utils.data.distributed
import torchvision.transforms as transforms
from torch.autograd import Variable
import os
from PIL import Image
classes = (‘cat’, ‘dog’)
transform_test = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
])
DEVICE = torch.device(“cuda:0” if torch.cuda.is_available() else “cpu”)
model = torch.load(“model.pth”)
model.eval()
model.to(DEVICE)
path=‘data/test/’
testList=os.listdir(path)
for file in testList:
img=Image.open(path+file)
img=transform_test(img)
img.unsqueeze_(0)
img = Variable(img).to(DEVICE)
out=model(img)
Predict
_, pred = torch.max(out.data, 1)
print(‘Image Name:{},predict:{}’.format(file,classes[pred.data.item()]))
运行结果:

其实在读取数据,也可以巧妙的用datasets.ImageFolder,下面我们就用datasets.ImageFolder实现对图片的预测。改一下test数据集的路径,在test文件夹外面再加一层文件件,取名为dataset,如下图所示:

然后修改读取图片的方式。代码如下:
import torch.utils.data.distributed
import torchvision.transforms as transforms
import torchvision.datasets as datasets
from torch.autograd import Variable
classes = (‘cat’, ‘dog’)
transform_test = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Python工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Python开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。






既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上前端开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以添加V:vip1024c 备注Python获取(资料价值较高,非无偿)

做了那么多年开发,自学了很多门编程语言,我很明白学习资源对于学一门新语言的重要性,这些年也收藏了不少的Python干货,对我来说这些东西确实已经用不到了,但对于准备自学Python的人来说,或许它就是一个宝藏,可以给你省去很多的时间和精力。
别在网上瞎学了,我最近也做了一些资源的更新,只要你是我的粉丝,这期福利你都可拿走。
我先来介绍一下这些东西怎么用,文末抱走。
(1)Python所有方向的学习路线(新版)
这是我花了几天的时间去把Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
最近我才对这些路线做了一下新的更新,知识体系更全面了。

(2)Python学习视频
包含了Python入门、爬虫、数据分析和web开发的学习视频,总共100多个,虽然没有那么全面,但是对于入门来说是没问题的,学完这些之后,你可以按照我上面的学习路线去网上找其他的知识资源进行进阶。

(3)100多个练手项目
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了,只是里面的项目比较多,水平也是参差不齐,大家可以挑自己能做的项目去练练。

(4)200多本电子书
这些年我也收藏了很多电子书,大概200多本,有时候带实体书不方便的话,我就会去打开电子书看看,书籍可不一定比视频教程差,尤其是权威的技术书籍。
基本上主流的和经典的都有,这里我就不放图了,版权问题,个人看看是没有问题的。
(5)Python知识点汇总
知识点汇总有点像学习路线,但与学习路线不同的点就在于,知识点汇总更为细致,里面包含了对具体知识点的简单说明,而我们的学习路线则更为抽象和简单,只是为了方便大家只是某个领域你应该学习哪些技术栈。

(6)其他资料
还有其他的一些东西,比如说我自己出的Python入门图文类教程,没有电脑的时候用手机也可以学习知识,学会了理论之后再去敲代码实践验证,还有Python中文版的库资料、MySQL和HTML标签大全等等,这些都是可以送给粉丝们的东西。

这些都不是什么非常值钱的东西,但对于没有资源或者资源不是很好的学习者来说确实很不错,你要是用得到的话都可以直接抱走,关注过我的人都知道,这些都是可以拿到的。
去打开电子书看看,书籍可不一定比视频教程差,尤其是权威的技术书籍。
基本上主流的和经典的都有,这里我就不放图了,版权问题,个人看看是没有问题的。
(5)Python知识点汇总
知识点汇总有点像学习路线,但与学习路线不同的点就在于,知识点汇总更为细致,里面包含了对具体知识点的简单说明,而我们的学习路线则更为抽象和简单,只是为了方便大家只是某个领域你应该学习哪些技术栈。
(6)其他资料
还有其他的一些东西,比如说我自己出的Python入门图文类教程,没有电脑的时候用手机也可以学习知识,学会了理论之后再去敲代码实践验证,还有Python中文版的库资料、MySQL和HTML标签大全等等,这些都是可以送给粉丝们的东西。
这些都不是什么非常值钱的东西,但对于没有资源或者资源不是很好的学习者来说确实很不错,你要是用得到的话都可以直接抱走,关注过我的人都知道,这些都是可以拿到的。















 28
28











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









