






国产数据库加速进入核心系统,传统同步工具却频频“掉链子”。本系列文章聚焦 OceanBase、GaussDB、TDSQL、达梦等主流信创数据库,逐一拆解其日志机制与同步难点,结合 TapData 的实践经验,系统讲解从 CDC 捕获到实时入仓(Doris、StarRocks、ClickHouse 等)的完整链路构建方案,为工程师提供切实可行的替代路径与最佳实践。
本篇任务:GaussDB → StarRocks / Doris
背景:国产数据库陆续上线生产,实时同步链路成新痛点
随着信创进程的推进,国产数据库已从非核心系统试点转向全面生产落地。以 GaussDB、OceanBase、TDSQL、达梦等为代表的国产数据库,已在金融、政务、电信等关键行业大规模部署,成为企业核心业务系统的数据承载平台。
与此同时,“上云 + 实时数仓”的数据架构趋势日益强化,企业对准实时同步能力的需求持续增长。无论是运营分析、风险监控,还是客户行为洞察,数据从源库同步到数据仓库或其他下游系统的时效性,已成为业务响应速度的核心指标。
然而,OGG(Oracle GoldenGate)、Attunity、SharePlex 等曾广泛使用的数据同步工具,早已停止对类似新兴数据库的支持。这些工具最初设计用于主流国际数据库系统,无法适配国产数据库的日志结构或提供 CDC(Change Data Capture)能力。这直接导致:
- 企业原有的 ETL、实时同步、实时入仓等任务难以继续搭建
- 数据链路断裂,影响业务连续性与实时数据能力的构建
国产数据库的崛起,正在倒逼同步链路的技术演进:如何在缺乏传统工具支持的情况下,构建面向新型数据源的完整实时同步方案,成为当前数据库架构设计中的核心挑战。本篇将以 GaussDB 为例,详细讲解如何构建信创数据库的实时同步链路。
GaussDB 数据同步的关键技术挑战
将 GaussDB 的数据变更同步至实时数仓(如 StarRocks / Doris)并非简单的数据移动,而是涉及日志解析、数据一致性、类型兼容性及故障恢复等复杂问题。以下是构建该链路必须面对的核心参数与控制点:
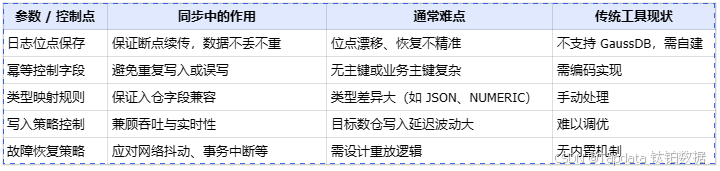
基于以上关键控制点,GaussDB 的数据同步面临以下具体技术挑战:
-
日志解析复杂化
GaussDB 的 WAL(Write-Ahead Logging)日志格式虽然与 PostgreSQL 类似,但存在差异化解析规则,需要针对性适配,无法直接复用传统 PostgreSQL 的同步机制。 -
缺乏公开接口支撑
GaussDB 官方未提供完整的增量日志解析 API,需要进行二进制日志的反序列化与 checkpoint 管理,增加了开发与运维的复杂度。 -
数据一致性保障压力大
在高并发环境下,如何处理乱序写入、重复写入、幂等控制成为保证链路正确性的核心问题,要求同步系统具备细粒度事务处理与数据校验能力。 -
实时性要求高,兼容性要求严苛
下游如 StarRocks、Doris 等新一代数仓,对数据到达延迟要求秒级,且要求字段类型、结构高度兼容,进一步加剧了同步链路设计的技术门槛。
小结
传统数据同步工具在面对 GaussDB 这类新型国产数据库时,普遍缺乏基础支撑能力,无法满足日志捕获、数据一致性控制、实时入仓等核心要求。构建可靠链路,需要在增量解析、链路调度、故障恢复等各个环节进行系统性的重构和优化。
TapData 的实时同步链路能力与技术实现
面对 GaussDB 到 StarRocks / Doris 的实时同步需求,TapData 设计并实现了从日志捕获、数据清洗、顺序保障到 下游高性能写入的完整链路,能够在完全国产化的软硬件环境下稳定运行。
自研 CDC 引擎
TapData 自主研发的 CDC(Change Data Capture)引擎支持对 GaussDB 的增量日志(WAL)进行解析,核心能力包括:
日志捕获
:通过逻辑复制槽(logical slot)持续拉取增量变更数据。
- 断点恢复:结合位点管理机制,支持故障后的精准续传,避免数据丢失或重复写入。
- 事务顺序与幂等控制:识别事务边界,解决并发写入导致的乱序和重复问题,确保下游数据一致性。
- 国产环境兼容性:该引擎已适配麒麟、统信 UOS 等国产操作系统,并在飞腾、鲲鹏等主流国产服务器上通过兼容性测试,可稳定运行于信创软硬件环境。
内置 StarRocks / Doris Connector
为了满足 GaussDB 的数据入仓等特定需求,TapData 提供了内置的数据连接器(如 StarRocks / Doris Connector),具备以下特性:
- 宽表支持:自动适配 StarRocks / Doris 的宽表建模特性,提升多维分析效率并降低查询复杂度。
- 字段映射与类型转换:内置字段映射规则,兼容 GaussDB 与 StarRocks / Doris 之间的数据类型差异,支持 JSON、DECIMAL、NUMERIC 等复杂字段的自动转换。
- 批量写入与合并策略:支持多种写入策略,包括 insert 和类 upsert 行为(基于 Primary Key 模型),支持insert_or_update 及 merge 策略,用户可根据业务需求灵活选择。
- 物化视图触发:支持物化视图自动刷新机制,在数据写入后提升查询性能和响应速度。
- 国产软硬件支持:Connector 同样通过国产操作系统和硬件的兼容性验证,支持在国产化环境下的大规模数据写入。
TapData 构建 GaussDB → StarRocks / Doris 的完整链路结构
TapData 的链路设计遵循模块化、可视化、灵活调优的原则,支持用户根据实际业务需求进行调整。
链路组成模块

数据流动路径

核心控制逻辑
- 乱序恢复:基于事务 ID 的排序机制,确保写入顺序正确。
- 缓冲与批处理:支持数据缓冲区与写入批次调优,兼顾实时性与吞吐。
- 多数据管道支持:允许并行同步多个业务域的数据,实现链路扩展性。
- 信创兼容:链路所有组件已通过国产操作系统及硬件兼容性验证,支持在信创环境下稳定运行,目标数据库节点亦已完成兼容性测试,适配金融、政务等关键行业要求。
可视化链路编排

TapData 提供拖拽式的链路编排界面,用户可通过 UI 快速构建和调整数据同步链路。每个任务节点的功能与状态一目了然,同时支持参数调整、链路监控及错误追踪,降低了工程复杂度,提高了运维效率。
小结
通过自研 CDC 引擎与内置 Connector 的深度整合,TapData 能够在国产数据库 GaussDB 与新一代实时数仓之间建立高可靠、高兼容、低延迟的数据同步链路,同时满足信创环境下对软硬件兼容性的严格要求,有效解决传统同步工具在性能、写入策略和国产化支持方面的技术难题。
实战案例:某金融客户构建 GaussDB → StarRocks 实时分析数仓
客户背景与需求:该客户为国内大型金融机构,近期将部分核心业务数据库迁移至 GaussDB,并规划构建新的审计分析平台。平台要求实现业务数据的近实时同步,并通过 StarRocks 构建支撑自定义 BI 报表的高并发分析引擎,满足日常审计与数据分析需求。
数据链路设计
- 链路目标:
日志(GaussDB WAL)→ TapData → 实时宽表(StarRocks)→ 自定义 BI 报表 - 替代方案:
新链路成功替代原有 OGG + Kafka + Flink 方案,整体架构更轻量,运维复杂度显著降低。
实现效果
- 实现 T+0 近实时同步,覆盖超过 30 张表。
- StarRocks 查询性能显著提升,数据延迟从分钟级压缩至秒级以下,满足金融核心系统的低延迟分析需求。
- 通过 TapData 的可视化链路配置与监控功能,降低了链路部署与维护的技术门槛。
最佳实践建议
在实施过程中,结合业务需求与链路特性,总结出以下最佳实践:
- 宽表建模 + 物化视图加速:简化查询逻辑,提高响应速度。
- 字段命名统一标准:减少同步过程中的字段映射错误,便于后期维护。
- 启用 TapData 的链路状态监控与自动重试机制:提升链路的容错能力。
- StarRocks 分区与分桶设计:结合业务逻辑进行合理建模,提升查询效率并降低资源消耗。
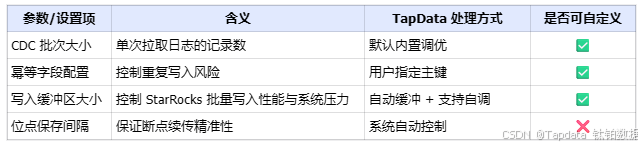
高级设置项与可调参数(供架构评估参考)
虽然 TapData 封装了大部分复杂操作,但对于性能敏感或有定制需求的场景,以下参数可作为架构设计和调优的重要参考:
小结
本案例展示了在缺乏传统工具支持的环境下,如何通过 TapData 构建 GaussDB → StarRocks 的高性能实时分析链路,不仅满足了高实时性与一致性要求,同时显著简化了工程实现的复杂度,并验证了最佳实践的有效性。
总结与展望
随着 GaussDB 等国产数据库在核心业务系统中的广泛应用,传统同步工具(如 OGG、Attunity、SharePlex)在数据源支持上的缺位,直接导致企业在构建信创数据链路时需要重新寻找可行的新方案。
本次实践中,通过 TapData 的日志捕获、数据清洗、顺序保障及写入能力,高效、低成本实现了 GaussDB 到实时数仓的高并发低延迟数据链路,并在生产环境中验证了其高可靠性与扩展性,支撑了自定义 BI 分析的落地。
此外,TapData 针对信创数据库的数据源支持能力正在持续扩展,链路的稳定性、一致性控制及对国产软硬件的兼容性也在不断提升,能够满足金融、政务等关键行业的生产级同步需求。
次回预告
TDSQL for MySQL → ClickHouse 实时链路实践
将在下一篇中深入解析腾讯云 TDSQL for MySQL 的增量日志捕获难点、与 ClickHouse 的数据类型兼容策略,以及如何通过 TapData 构建高吞吐低延迟的数据链路,满足复杂查询场景的性能需求。


















 976
976

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









