






【具体功能】
向Excel文件指定Sheet中写入数据,同时不影响其他Sheet的值。
【说明】
对Sheet进行写入时,是覆盖式写入。例如:如果Sheet本来有10条记录,现在我要向其中写入5条记录,希望写入后这个Sheet中只有这5条记录。实际上并非如此,运行的结果是Sheet中仍然存在10条记录,其中前5条是我要写入的数据,后5条是原来后面的5条数据。
因此,如果不希望保留原有数据,应该先清空Sheet再写入;如果希望保留原有数据并在其后追加新数据,应该先将原有数据读出,将其与新数据拼接后再写入(本质上是清空后重新写入,并不是追加)。
【可能的报错】
IndexError: At least one sheet must be visible 或者 pandas._config.config.OptionError: "No such keys(s): 'io.excel.zip.reader'"
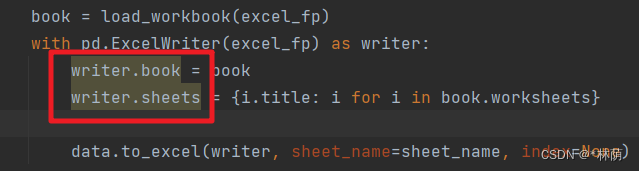
解决方法:pip install pandas==1.1.5。似乎是高版本pandas去掉了ExcelWriter的book和sheets属性导致的。
# -*- coding: utf-8 -*-
import os.path
from openpyxl import load_workbook
import pandas as pd
def writeExcel(data, excel_fp, sheet_name):
'''
将data写入excel文件的指定sheet中。覆盖式写入,使用前应清空sheet,否则可能导致尾部数据残留。
如果是要添加数据,应将sheet中的数据读出并与要添加的数据concat,再传入data。
:param data: 要写入的数据
:param excel_fp: excel文件路径
:param sheet_name: excel工作簿名称
:return: None。(操作Excel文件。)
'''
book = load_workbook(excel_fp)
with pd.ExcelWriter(excel_fp) as writer:
writer.book = book
writer.sheets = {i.title: i for i in book.worksheets}
data.to_excel(writer, sheet_name=sheet_name, index=None)
def clear(excel_fp, sheet_list): # 清空指定工作簿,保留表头
'''
清空excel的指定sheet,保留表头。本质是空值覆盖。
:param excel_fp: excel文件路径
:param sheet_list: 要清空的工作簿名称列表。
:return: None。清空工作簿
'''
# 删除过程
res = pd.DataFrame(columns=['工作簿', '剩余记录数'])
for sheet_name in sheet_list:
excel_data = pd.read_excel(excel_fp, sheet_name=sheet_name)
excel_index, excel_columns = excel_data.index, excel_data.columns
data = pd.DataFrame(data=None, columns=excel_columns, index=excel_index)
writeExcel(data, excel_fp, sheet_name)
res = pd.concat([res, pd.DataFrame(data=[[sheet_name, pd.read_excel(excel_fp, sheet_name=sheet_name).shape[0]]], columns=['工作簿', '剩余记录数'])], axis=0)
print(res)
if __name__ == '__main__':
work_path = '.\\test' # 工作目录路径
excel_name = '1班成绩表.xlsx' # 要操作的Excel文件名称
excel_fp = os.path.join(work_path, excel_name) # 要操作的Excel文件路径
sheet_name = '语文成绩'
# clear(excel_fp, ['语文成绩', '数学成绩']) # 清空这两张工作簿里面的数据
# 现在我想把2班语文成绩添加到1班语文成绩表中
data_1 = pd.read_excel(os.path.join(work_path, '1班成绩表.xlsx'), sheet_name='语文成绩') # 首先我要把两个班的语文成绩读出并拼起来
data_2 = pd.read_excel(os.path.join(work_path, '2班成绩表.xlsx'), sheet_name='语文成绩')
data = pd.concat([data_1, data_2], axis=0).reset_index(drop=True) # 拼接后记得重置一下索引
writeExcel(data, excel_fp, sheet_name)
print(pd.read_excel(excel_fp, sheet_name=sheet_name))
高版本pandas修改这两个属性时会变色提示。
![]()
这时运行的话会报错,第一次会报错IndexError: At least one sheet must be visible,然后Excel文件会损坏,再运行就报错pandas._config.config.OptionError: "No such keys(s): 'io.excel.zip.reader'"了。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









