






目录
前言
手册目录:
软件下载及环境安装:
实习手册一(基于Tornado框架的接口响应服务)软件下载与环境配置
Tornado基本框架搭建:
实习手册二(基于Tornado框架的接口响应服务)Tornado基本框架的搭建
Tornado框架中日志的记录,路由的分发,接口的响应:
实习手册三(基于Tornado框架的接口响应服务)Tornado框架中日志的记录,路由的分发,接口的响应
本章目标:通过PyMySQL,SQLAlchemy在PyCharm中实现对数据的增删改查
Navicat of mysql
在使用python中的pymysql和sqlalchemy包来对数据库进行处理时,需要确保你的mysql服务处于开启状态(如何开启数据库可以查看实习手册一),并且通过navicat of mysql建立的连接能够成功连接到mysql服务。
使用navicat of mysql建立数据库连接的步骤如下:
1、新建连接
点击navicat界面左上方的Connection,选择MySQL

随后进入连接配置界面:

在配置界面中,你可以设置连接的名字,端口号,host等,Password就是你mysql服务的密码,配置好后可以先点击Test Connection来测试连接能否成功,测试连接成功后点击Save即可保存连接
2、开启连接,建立新的数据库和新的表
在navicat中,双击你保存的连接即可开启,前提是你在配置连接时勾选了Save password。
等待连接的图标由灰色变为绿色,便可以通过连接来对数据库进行操作了,这里我们需要新建一个用于测试的数据库,对连接点击鼠标右键,选中New Database。

然后对你的数据库命名后点击OK即可创建新的数据库,然后双击数据库待数据库图标变绿则说明已经连接成功,接下来便可以对数据库进行操作了。

当然,假如你拥有一定的数据库基础,也可以通过新建查询操作来创建数据库以及表。
我们在test1数据库中建立一个user表,如图所示:
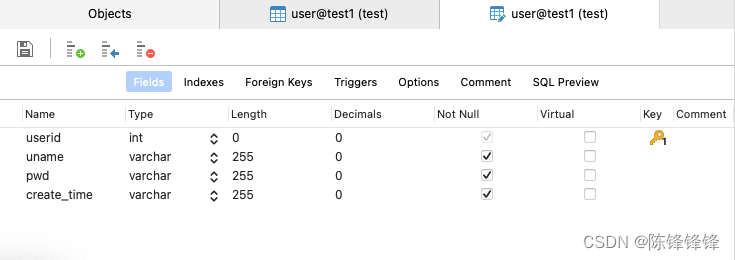
其中userid为主键,且默认自增,所有字段均不能为空。
PyMySQL
PyMySQL是python3.x版本中用于连接mysql服务器的一个库,python2中使用MySQLdb。
安装PyMySQL之前可以先在代码面板输入import pymysql来查看Python版本是否自带了PyMySQL包。
在PyCharm中安装PyMySQL有两种方法,一直接通过PyCharm提供的可视化界面进行安装,二是在PyCharm的terminal界面输入
pip3 install PyMySQLPyMySQL简易教程:
学过数据库的小伙伴了解一下就行,没有学习过数据库的需要先学习一下基本的SQL语言以及相关的数据库概念。pymysql主要是通过传入sql语句来对数据进行处理,优点是非常万能,缺点就是每次进行处理时都要打很长的一段sql语句,过程较繁杂,不够灵活简便。
举个例子:
import pymysql
# pymysql是根据游标对象cursor来对sql语句的处理的
class PyMySqlBase():
# 建立连接
conn = pymysql.connect(host="localhost", user='root', password=你的密码(字符串格式), db=数据库名称(字符串格式))
# 获取游标对象
cursor = conn.cursor()
# 类方法,同上,根据get_cursor方法来获取cursor对象
@classmethod
def get_cursor(cls):
return cls.cursor
# 获取cursor
cursor = PyMySqlBase.get_cursor()
# 向user表中插入用户名为felix,密码为123456,日期为2022/7/28的行,由于userid是自增,不用我们去对它进行插入
cursor.execute("insert into user(uname,pwd,create_time) values('felix','123456','2022/7/28')")
# commit操作,但凡涉及增删改(即数据库内数据发生了变化)的操作,都需要commit
PyMySqlBase.conn.commit()然后通过navicat查看user表:

可以看到,我们已经通过pymysql成功向user表中插入了一条新的数据。简而言之,pymysql的作用是使得我们可以通过python代码来对数据库进行操作。
SQLAlchemy
SQLAlchemy 是 Python 中一个通过 ORM 操作数据库的框架。
SQLAlchemy 对象关系映射器提供了一种方法,用于将用户定义的 Python 类与数据库表相关联,并将这些类(对象)的实例与其对应表中的行相关联。它包括一个透明地同步对象及其相关行之间状态的所有变化的系统,称为工作单元,以及根据用户定义的类及其定义的彼此之间的关系表达数据库查询的系统。
通俗点讲,SQLAlchemy相当于将繁杂冗长的sql语言,转化为了对应的方法,在对数据库进行操作时,我们只需要调用对应的方法,传递特定的参数即可。但是在使用SQLAlchemy之前,我们需要将对象模型与数据库表进行映射,即ORM,不了解的小伙伴可以看看这章:
ORM(Object Relational Mapping)框架
这里我们要对user表进行处理,因此要建立user表的对象模型:
class User(SqlAlBase.get_base()):
__tablename__ = 'user'
userid = Column(Integer, autoincrement=True, primary_key=True)
uname = Column(String(255))
pwd = Column(String(255))
create_time = Column(String(255))可以看到,user类中的每条属性都对应着user表中的每个字段。
接下来使用SQLAlchemy来对user表添加新的对象,完整代码如下:
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmaker
from sqlalchemy import MetaData
from sqlalchemy import Column, String, Integer
# URL用来作为SqlAlchemy创造引擎的url
# 格式为:"mysql+pymysql://root:你的mysql密码@localhost:端口号/数据库名字"
URL = "mysql+pymysql://root:你的密码@localhost:3306/test1"
# sqlalchemy是根据session对象来调用对应方法来对数据进行处理
class SqlAlBase():
engine = create_engine(URL)
base = declarative_base()
session = sessionmaker(bind=engine)()
metadata = MetaData()
# 类方法,不需要创建SqlAlBase对象即可调用,get_session方法用来获取session对象
@classmethod
def get_session(cls):
return cls.session
# 类方法,用来获取base
@classmethod
def get_base(cls):
return cls.base
class User(SqlAlBase.get_base()):
__tablename__ = 'user'
userid = Column(Integer, autoincrement=True, primary_key=True)
uname = Column(String(255))
pwd = Column(String(255))
create_time = Column(String(255))
session = SqlAlBase.get_session()
# 新建一个User对象,用户名为apple,密码为654321,日期为2022/7/28
newUser = User(uname='apple', pwd='654321', create_time='2022/7/28')
# 使用session对象的add方法向表中添加新的用户
session.add(newUser)
# commit方法
session.commit()然后通过navicat查看user表:

可以看到,我们已经成功添加了一条新数据,当然你还可以通过SQLAlchemy来对数据库进行其他的操作,这里不再赘述。
总结
pymysql与sqlalchemy都可以帮助我们实现用python代码来操作数据库的功能,两者各有千秋,需要结合实际的需求来选择使用,两者并不是完全对立的,下一章我们会将两者进行结合,实现sqlalchemy中方法的封装,来帮助我们更加方便地通过python代码来对数据库进行处理。















 1062
1062











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









