







目录
用总人数的平均值作为阈值,只保留人数大于平均值的城市的前5名
我们常说的用户偏好分析是一种分析方向,它基于用户属性和行为等数据,可以分析用户对于某些产品、服务或特征的喜好程度。通过用户偏好分析,品牌可以更好地了解目标客户群体的需求和行为特点,从而制定契合度更高的产品策略、宣传策略等。
TGI是一种衡量和对比不同用户群体偏好程度的方法,具有逻辑清晰、计算便捷的特点,被广泛应用于各类用户偏好分析之中,而且效果都还不错。
TGI
TGI = 目标群体中具有某一特征的群体所占比列 / 总体中具有相同特征的群体所占比例 * 100
用来反映目标群体在特定研究范围内强势或者弱势的程度.
假设我们要研究A公司的脱发TGI,则对应的3个核心要素如下:
-
某一特征:我们想要分析的某种行为或者状态,这里是脱发或者受脱发困扰的状态。
-
总体:我们研究的所有对象,即A公司所有人。
-
目标群体:总体中我们感兴趣的一个分组。
假设我们关注的分组是数据部,那么目标群体就是数据部。
-
TGI公式中的分子“目标群体中具有某一特征的群体所占比例”可以理解为“数据部脱发人数占数据部的比例”
-
假设数据部有15人,其中有9人受脱发困扰,那么数据部脱发人数占比就是9/15,即60%。
-
-
分母“总体中具有相同特征的群体所占比例”,等同于“全公司受脱发困扰人数占公司总人数的比例”。
-
假设公司共500人,有120人受脱发困扰,那么这个比例就是24%。
-
-
数据部脱发TGI为 60% / 24% × 100=250。其他部门脱发TGI的计算逻辑是一样的,为本部门脱发人数占比/公司脱发人数占比×100。
TGI具体数值是围绕100这个值来解读的:
-
TGI=100,表示目标群体和总体在某特征或行为上的表现相同。
-
TGI>100,表示目标群体在某特征或行为上的表现高于总体,具有较高的偏好程度,数值越大偏好越强。
-
TGI<100,表示目标群体在某特征或行为上的表现低于总体,具有较低的偏好程度,数值越小偏好越弱。
刚才的例子中,数据部脱发TGI是250,远远高于100,看来在该公司做数据工作的人脱发风险较高。
导入数据
import pandas as pd
# 1 加载数据
df = pd.read_excel("../data/j_PreferenceAnalysis.xlsx")
print(df.info())
print('---------------------------')
df.head()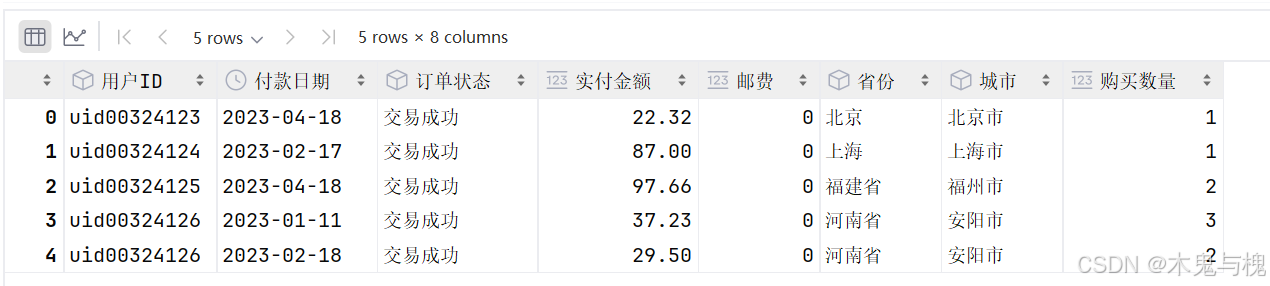
就我们产品线和历史数据来看,单次购买超过50元的就算高客单的客户了
对应TGI计算的三个核心要素分别如下。
-
特征:高客单,即客户单次购买超过50元。
-
目标群体:各个城市,这里我们可以分别计算出所有城市用户的高客单价偏好。
-
总体:计算涉及的所有用户。
求每个用户的平均实付金额
# 2 求每个用户的平均实付金额
# 2.1 求每个用户的平均实付金额 gb_user
gb_user = df.groupby(['省份', '城市', '用户ID'])['实付金额'].mean().reset_index()
# 2.2 起别名 '省份', '城市', '用户ID', '平均每次支付金额'
gb_user.columns = ['省份', '城市', '用户ID', '平均每次支付金额']
gb_user.head()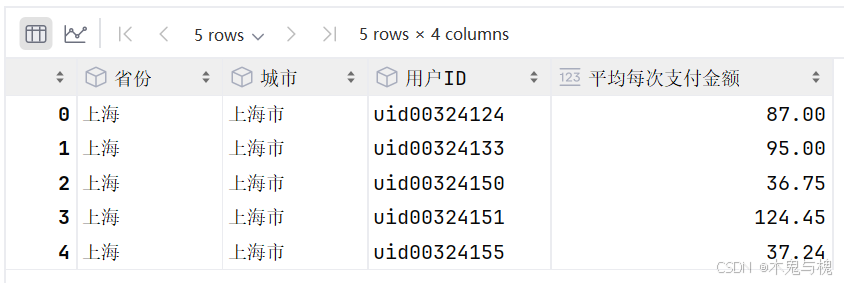
增加一列显示客单价类别
# 3 增加一列显示客单价类别
# 3.1 方式一
# def get_kdj(x):
# if x > 50:
# return "高客单价"
# else:
# return "低客单价"
#
# gb_user['客单价类型'] = gb_user['平均每次支付金额'].apply(get_kdj)
#
# gb_user.head()
# 3.2 方式二
gb_user['客单价类别'] = gb_user['平均每次支付金额'].apply(lambda x: "高客单价" if x>50 else "低客单价")
gb_user.head()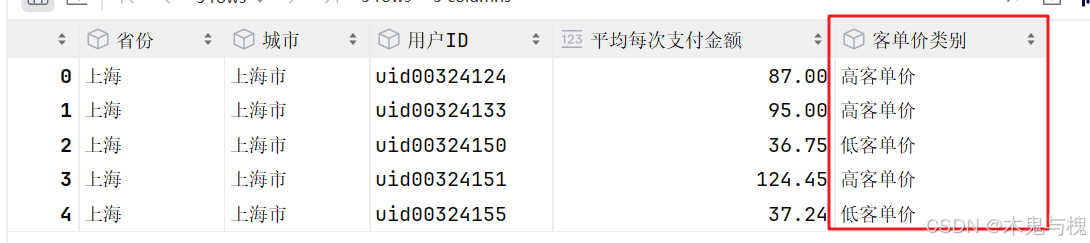
求每个城市 不同客单价类别的人数
# 4 求每个城市 不同客单价类别的人数
# 4.1 先筛选出需要的列 "省份", "城市", "用户ID", "客单价类别"
gb_user = gb_user[["省份", "城市", "用户ID", "客单价类别"]]
# 4.2 使用透视表 求每个城市 不同客单价类别的人数
tgi = pd.pivot_table(data=gb_user, index=["省份", "城市"], columns="客单价类别", aggfunc="count").reset_index()
tgi.head()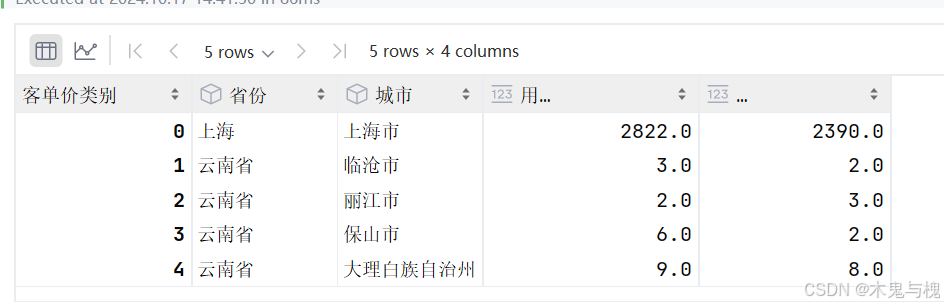
计算总人数,高客单价占比
# 5 计算 总人数,高客单价占比
# 5.1 求 总人数
# gb_user['用户ID']['高客单价']
tgi['总人数'] = tgi['用户ID']['高客单价'] + tgi['用户ID']['低客单价']
# 5.2 求 高客单价占比
tgi['高客单价占比'] = tgi['用户ID']['高客单价'] / tgi['总人数']
tgi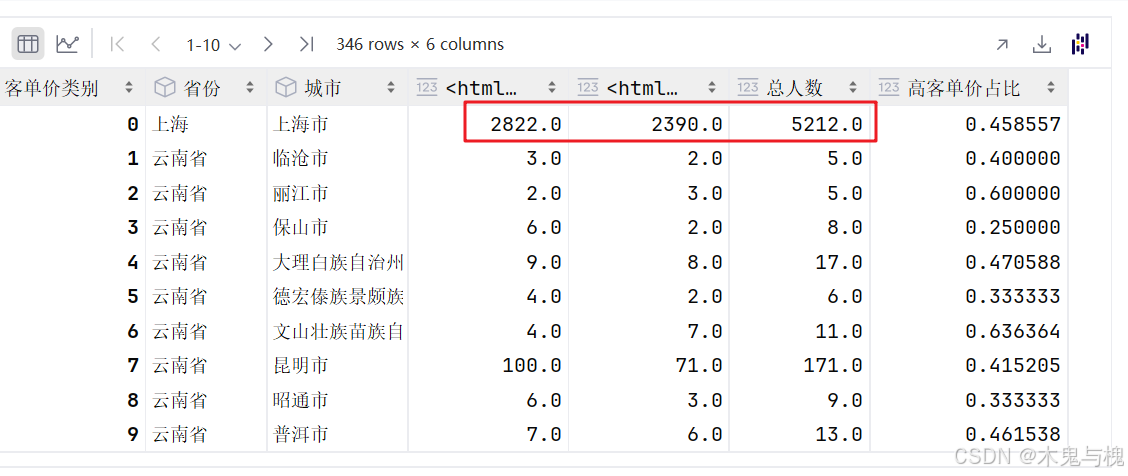
删除空值
# 6 删除空值
tgi.dropna()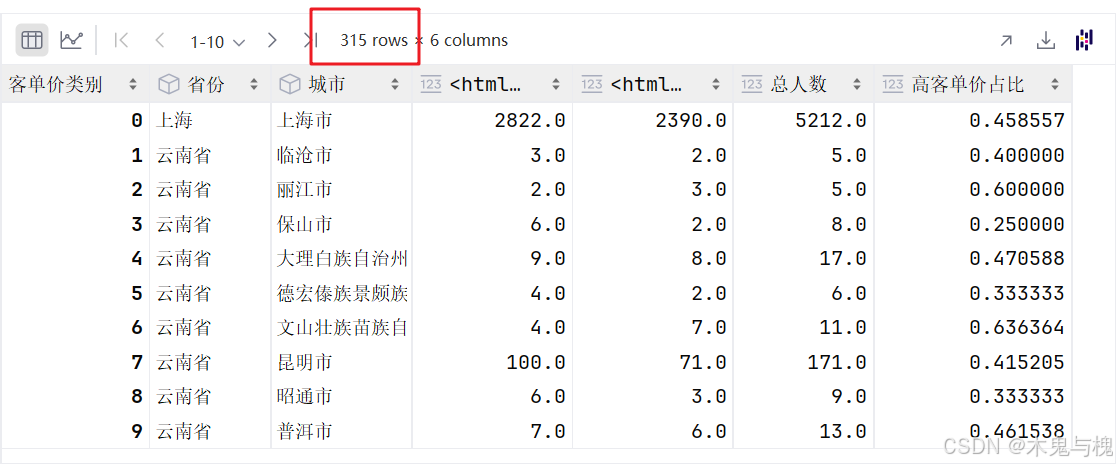
统计总人数中高客单人群
# 7 统计总人数中高客单人群的比例 = 高客单价总人数 / 总人数
total_percent = tgi['用户ID']['高客单价'].sum() / tgi['总人数'].sum()
total_percent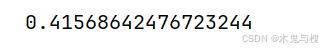
计算TGI的值
# 8 计算 TGI 的值
# 8.1 求 高客单价TGI = 局部占比 / 整体占比 * 100
tgi['高客单价TGI'] = tgi['高客单价占比'] / total_percent * 100
# 8.2 排序 按 高客单价TGI
tgi.sort_values("高客单价TGI", ascending=False).head()
用总人数的平均值作为阈值,只保留人数大于平均值的城市的前5名
TGI能够显示偏好的强弱,但很容易让人忽略具体的样本量大小,而小样本量往往意味着波动极大,一不小心TGI就飙升到前面,这是需要格外注意的
# 用总人数的平均值作为阈值,只保留总人数大于平均值的城市
tgi[tgi['总人数']>tgi['总人数'].mean()].sort_values("高客单价TGI", ascending=False).head()


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









