






一、前言
1、Hadoop集群框架搭建(学过,但是没有现成的)
2、python(机器学习)
3、Spark(没有)
4、Flume(没有)
5、Sqoop(没有接触)
6、编程语言: SpringBoot(有)+echarts(数据可视化框架)
二、大数据概述
1.1 百度百科:大数据,短期无法运用常规一些手段去及时处理海量数据,需要使用新型的技术进行处理。
1.2 大数据:
a、海量数据存储
b、海量数据分析(运算,处理)
1.3 大数据为了解决事物的未知性,给判断提供准确性
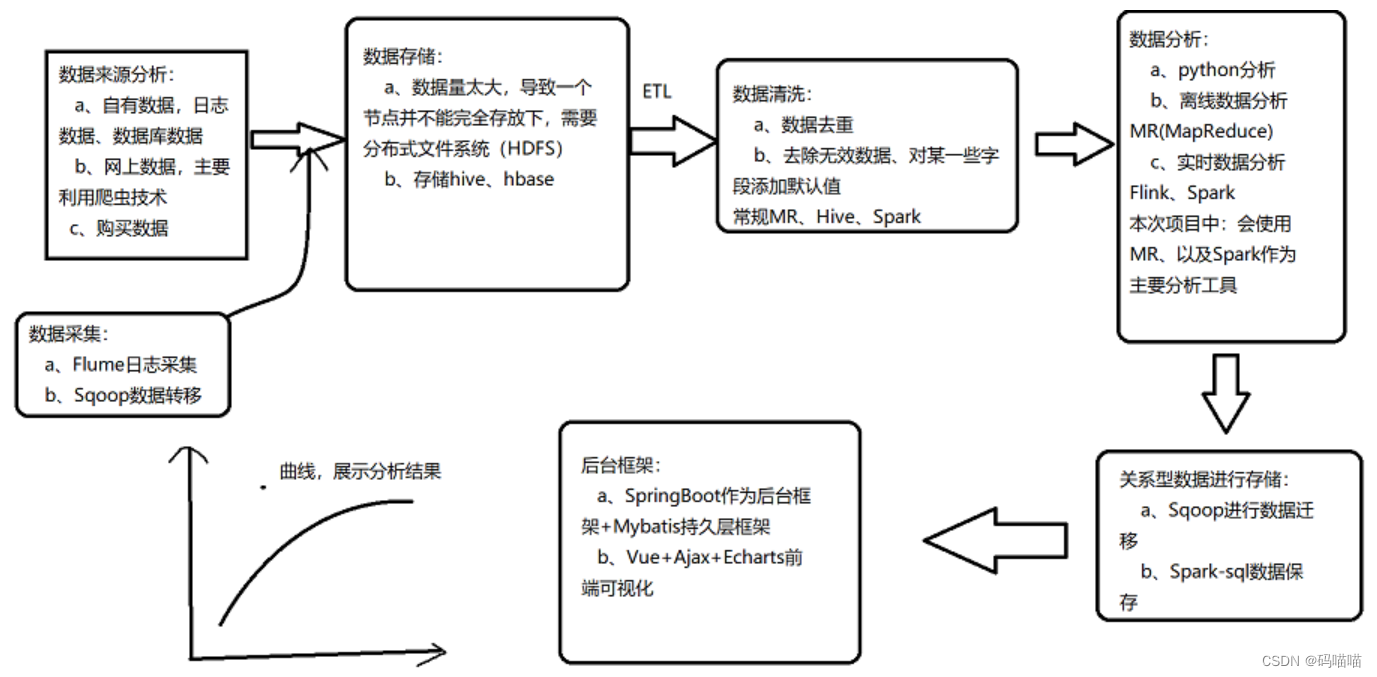
2.1 企业中大数据开发流程
2.2 大数据的开发工具包
1、链接:https://pan.baidu.com/s/1eg8poPxAN-sLBd53S9hJ1g
2、提取码:k54t

本次项目中会用到很多开发工具以及软件安装包:
a、操作系统,linux操作系统---centos7---最接近企业开发版本
b、远程连接工具-----finalshell远程连接工具
c、jdk1.8版本
d、数据采集工具Flum01.7版本、Sqoop
e、hadoop集群框架----hadoop2.7.3版本
f、kafka2.11版本
g、Vmware虚拟机
h、spark2.1.1版本
i、flink-1.10.2版本
j、idea开发工具、Maven作jar管理项目创建
2.3 大数据环境搭建
2.3.1 虚拟机安装和配置
1 虚拟机(Virtual Machine)指通过软件模拟的具有完整硬件系统功能的、运行在一个完全隔离环境中的完整计算机系统。
2 在实体计算机中能够完成的工作在虚拟机中都能够实现。
3 在计算机中创建虚拟机时,需要将实体机的部分硬盘和内存容量作为虚拟机的硬盘和内存容量。每个虚拟机都有独立的CMOS、硬盘和操作系统,可以像使用实体机一样对虚拟机进行操作.
4 总结:虚拟机具有独立内存、硬盘容量、cup,是一个完整计算机系统,具有优点,如果在使用虚拟机的过程中,出现损坏,或者故障,只需要还原虚拟机设备,就会释放虚拟机资源,重新配置虚拟机,更加方便使用。



2.3.2 虚拟机创建
















2.3.3 搭建linux操作系统











2.3.4 远程连接
a、需要开辟22端口 -----ssh方式
b、固定的ip地址
配置一个固定的IP地址:
在linux操作系统中:所有的软件配置文件,都是以文件方式进行出现,也就意味着,配置一个固定ip地址需要一个网卡文件
/etc/sysconfig/network-scripts/ifcfg-ens33
vi /etc/sysconfig/network-scripts/ifcfg-ens33



重启网络:
service network restart
systemctl restart network.service
ip addr ----查询ip地址

ping www.baidu.com
使用netstat方式查看端口是否存在:
netstat -tln | grep 22

上述问题出现原因是因为,系统为纯净版的系统,需要手动安装
yum install net-tools -y



2.3.5 时间同步
时间同步:把时间跟某个服务器时间进行统一
阿里时间同步服务器:
ntp.aliyun.com
ntp1.aliyun.com
ntp2.aliyun.com
[root@hadoop1 ~]# ntpdate ntp.aliyun.com -bash: ntpdate: 未找到命令
解决方案:
[root@hadoop1 ~]# yum install ntp -y
[root@hadoop1 ~]# ntpdate ntp.aliyun.com
5 Dec 15:24:49 ntpdate[36743]: step time server 203.107.6.88 offset -28800.771257 sec [root@hadoop1 ~]# date
2022年 12月 05日 星期一 15:25:10 CST
2.3.6 ip地址映射主机名
[root@hadoop1 ~]# vi /etc/hosts
192.168.91.100 hadoop1 ------hadoop1为主机名
测试:
[root@hadoop1 ~]# ping hadoop1
PING hadoop1 (192.168.91.100) 56(84) bytes of data.
64 bytes from hadoop1 (192.168.91.100): icmp_seq=1 ttl=64 time=0.138 ms
2.3.7 安装和配置jdk环境变量
由于hadoop生态圈和spark生态圈都需要jvm支持,需要在linux操作系统中进行环境变量的配置 a、创建一个文件夹----存放软件
[root@hadoop1 ~]# mkdir /soft
b、上传jdk软件包到/soft文件夹中
[root@hadoop1 ~]# tar -zxvf /soft/jdk-8u162-linux-x64.tar.gz -C /opt
tar:常用于解压或者压缩操作
-z:解压文件的后缀名为.gz
-x:解压
-v:显示解压的过程
-f:表示目标文件
-C:表示解压后的位置
c、配置jdk环境变量 在linux操作系统中,环境变量
系统环境变量:/etc/profile
当前用户环境变量:~/bash_profile
[root@hadoop1 ~]# vi /etc/profile
#JDK的环境变量
export JAVA_HOME=/opt/jdk1.8.0_162
export PATH=$JAVA_HOME/bin:$PATH:$HOME/bin
d、生效环境变量
[root@hadoop1 ~]# source /etc/profile
e、测试环境变量是否配置成功
[root@hadoop1 ~]# java -version
java version "1.8.0_162"
Java(TM) SE Runtime Environment (build 1.8.0_162-b12)
Java HotSpot(TM) 64-Bit Server VM (build 25.162-b12, mixed mode)
2.3.8 虚拟机克隆和配置
由于项目中所采用为集群模式,需要多台节点,克隆多台虚拟以供使用
准备:关闭克隆虚拟机




再次进行上述操作:

分别在hadoop2和hadoop3进行以下操作:
打开hadoop2:


修改主机名:


重启虚拟机:

配置远程连接:


同步时间:
[root@hadoop2 ~]# ntpdate ntp.aliyun.com
5 Dec 16:17:34 ntpdate[2136]: step time server 203.107.6.88 offset -28800.935828 sec
在hadoop3中进行上述操作:

3台节点之间映射关系:
[root@hadoop1 ~]# vi /etc/hosts
192.168.91.100 hadoop1
192.168.91.101 hadoop2
192.168.91.102 hadoop3
[root@hadoop2 ~]# vi /etc/hosts
192.168.91.100 hadoop1
192.168.91.101 hadoop2
192.168.91.102 hadoop3
[root@hadoop3 ~]# vi /etc/hosts
192.168.91.100 hadoop1
192.168.91.101 hadoop2
192.168.91.102 hadoop3
测试:
[root@hadoop1 ~]# ping hadoop1
PING hadoop1 (192.168.91.100) 56(84) bytes of data.
64 bytes from hadoop1 (192.168.91.100): icmp_seq=1 ttl=64 time=0.050 ms
64 bytes from hadoop1 (192.168.91.100): icmp_seq=2 ttl=64 time=0.041 ms
^Z
[1]+ 已停止 ping hadoop1
[root@hadoop1 ~]# ping hadoop2
PING hadoop2 (192.168.91.101) 56(84) bytes of data.
64 bytes from hadoop2 (192.168.91.101): icmp_seq=1 ttl=64 time=0.704 ms
64 bytes from hadoop2 (192.168.91.101): icmp_seq=2 ttl=64 time=0.440 ms
^Z [2]+ 已停止 ping hadoop2
[root@hadoop1 ~]# ping hadoop3
PING hadoop3 (192.168.91.102) 56(84) bytes of data.
64 bytes from hadoop3 (192.168.91.102): icmp_seq=1 ttl=64 time=0.507 ms
64 bytes from hadoop3 (192.168.91.102): icmp_seq=2 ttl=64 time=0.474 ms
^Z
[3]+ 已停止 ping hadoop3

检查ip地址:
ip addr
查看ip地址是否匹配

检查无线网卡如果不存在


https://www.ccleaner.com/zh-cn

卸载vm,重新安装
2.3.9 Hadoop完全分布式搭建
| namenode | secondarynamenode | datanode | resourcemanager | nodemanager | |
| hadoop1 | √ | √ | √ | √ | |
| hadoop2 | √ | √ | √ | ||
| hadoop3 | √ | √ |
a、上传hadoop软件包到soft文件夹
b、解压Hadoop的软件包
[root@hadoop1 ~]# tar -zxvf /soft/hadoop-2.7.3.tar.gz -C /opt
c、配置hadoop的环境变量
[root@hadoop1 ~]# vi /etc/profile
export HADOOP_HOME=/opt/hadoop-2.7.3
export PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH:$HOME/bin
d、生效环境变量
[root@hadoop1 ~]# source /etc/profile
e、测试
[root@hadoop1 ~]# hadoop version
Hadoop 2.7.3
Subversion https://git-wip-us.apache.org/repos/asf/hadoop.git -r baa91f7c6bc9cb92be5982de4719c1c8af91ccff
Compiled by root on 2016-08-18T01:41Z
Compiled with protoc 2.5.0
From source with checksum 2e4ce5f957ea4db193bce3734ff29ff4
This command was run using /opt/hadoop-2.7.3/share/hadoop/common/hadoop-common-2.7.3.jar
hadoop配置文件讲解:
参考文档:https://hadoop.apache.org/
hadoop主要模块:
a、hadoop common:hadoop的通用模块,为其他模块提供支持
b、hdfs:hadoop分布式文件系统
c、hadoop yarn:hadoop资源调度平台
d、hadoop MapReduce:分布式计算框架
https://hadoop.apache.org/docs/r2.7.3/
修改hadoop配置文件:
[root@hadoop1 ~]# cd /opt/hadoop-2.7.3/etc/hadoop/
[root@hadoop1 hadoop]# vi hadoop-env.sh
export JAVA_HOME=/opt/jdk1.8.0_162
[root@hadoop1 hadoop]# vi core-site.xml
<configuration> <!-- namenode 默认通讯地址 --> <property> <name>fs.defaultFS</name> <value>hdfs://hadoop1:9000</value> </property> <!-- 整个集群基础路径 --> <property> <name>hadoop.tmp.dir</name> <value>/opt/tmp/hadoop</value> </property> </configuration> [root@hadoop1 hadoop]# vi hdfs-site.xml <configuration> <!-- hadoop块的备份数 --> <property> <name>dfs.replication</name> <value>3</value> </property> <!-- secondarynamenode http访问地址 --> <property> <name>dfs.namenode.secondary.http-address</name> <value>hadoop2:50090</value> </property> </configuration> [root@hadoop1 hadoop]# cp mapred-site.xml.template mapred-site.xml [root@hadoop1 hadoop]# vi mapred-site.xml <configuration> <!-- 整个集群运行框架是yarn --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration> [root@hadoop1 hadoop]# vi yarn-site.xml <configuration> <!-- 中间服务 shuffle --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration>[root@hadoop1 hadoop]# vi slaves
hadoop1
hadoop2
hadoop3
需要把配置好文件分发hadoop2、hadoop3节点上:
[root@hadoop1 ~]# scp /etc/profile hadoop2:/etc/profile
The authenticity of host 'hadoop2 (192.168.91.101)' can't be established.
ECDSA key fingerprint is SHA256:ETL5Iad3RarttSkJLbFPlEn/KKUBAnHyMcttoUZxhHM.
ECDSA key fingerprint is MD5:5f:31:bc:fa:0f:74:a7:55:9c:ec:59:94:bd:14:ca:5b.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'hadoop2,192.168.91.101' (ECDSA) to the list of known hosts. root@hadoop2's password:
profile
[root@hadoop1 ~]# scp /etc/profile hadoop3:/etc/profile
The authenticity of host 'hadoop3 (192.168.91.102)' can't be established.
ECDSA key fingerprint is SHA256:ETL5Iad3RarttSkJLbFPlEn/KKUBAnHyMcttoUZxhHM.
ECDSA key fingerprint is MD5:5f:31:bc:fa:0f:74:a7:55:9c:ec:59:94:bd:14:ca:5b.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'hadoop3,192.168.91.102' (ECDSA) to the list of known hosts. root@hadoop3's password: profile
[root@hadoop1 ~]# scp -r /opt/hadoop-2.7.3 hadoop2:/opt/
[root@hadoop1 ~]# scp -r /opt/hadoop-2.7.3 hadoop3:/opt/
分别在hadoop1、hadoop2、hadoop3中关闭防火墙
[root@hadoop1 ~]# systemctl stop firewalld
[root@hadoop2 ~]# systemctl stop firewalld
[root@hadoop3 ~]# systemctl stop firewalld
在hadoop1中进行格式化namenode
[root@hadoop1 ~]# hadoop namenode -format
2.3.10 三个节点中配置免密
分别在hadoop1、hadoop2、hadoop3中依次进行以下操作
[root@hadoop1 ~]# ssh-keygen -t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (/root/.ssh/id_rsa):
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /root/.ssh/id_rsa.
Your public key has been saved in /root/.ssh/id_rsa.pub.
The key fingerprint is:
SHA256:7rTCj+LqM95Gk1nUniyf1Yy0NM1W7FAPR6slCTvDYGo root@hadoop1
The key's randomart image is:
+---[RSA 2048]----+
| . o + ++.o|
| . + * B o+.|
| . E + % = o.|
| + + + = = |
| + oSo . |
| = .o |
| . o o |
| o.o o+ . |
| o+*o..o+ |
+----[SHA256]-----+
[root@hadoop2 ~]# ssh-keygen -t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (/root/.ssh/id_rsa):
Created directory '/root/.ssh'.
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /root/.ssh/id_rsa. Y
our public key has been saved in /root/.ssh/id_rsa.pub.
The key fingerprint is:
SHA256:C3azvXal3IjmRmD/FClkEmxzS17X8TMOCWRV/0OgvSM root@hadoop2
The key's randomart image is:
+---[RSA 2048]----+
| ....+.o.+.|
| = * = + +|
| . O + * +o|
| o + o = +|
| o.So E + o.|
| . o =o o o .|
| o..= = |
| =.* . |
| =o. |
+----[SHA256]-----+
[root@hadoop3 ~]# ssh-keygen -t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (/root/.ssh/id_rsa):
Created directory '/root/.ssh'. Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /root/.ssh/id_rsa.
Your public key has been saved in /root/.ssh/id_rsa.pub.
The key fingerprint is:
SHA256:iswVFWqHXhN4BaIT2mMD0EwfAc8KC+hw41lVbK5sGFg root@hadoop3
The key's randomart image is:
+---[RSA 2048]----+
|.=+.+.o+*+. |
|. oBE=.=+. |
|= +o% =++ |
|+=.*.* +.. |
|..+ +o.S |
| o.o+. |
| +.. |
| |
| |
+----[SHA256]-----+
分别在hadoop2和hadoop3中进行操作:
[root@hadoop2 ~]# cp .ssh/id_rsa.pub hadoop2_id_rsa.pub
[root@hadoop2 ~]# scp hadoop2_id_rsa.pub hadoop1:.ssh/
[root@hadoop3 ~]# cp .ssh/id_rsa.pub hadoop3_id_rsa.pub
[root@hadoop3 ~]# scp hadoop3_id_rsa.pub hadoop1:.ssh/
在hadoop1中:
[root@hadoop1 ~]# cd .ssh
[root@hadoop1 .ssh]# cat hadoop2_id_rsa.pub hadoop3_id_rsa.pub id_rsa.pub >> authorized_keys
分别把authorized_keys发送到hadoop2和hadoop3中
[root@hadoop1 .ssh]# scp authorized_keys hadoop2:.ssh/
root@hadoop2's password:
authorized_keys
[root@hadoop1 .ssh]# scp authorized_keys hadoop3:.ssh/
root@hadoop3's password:
authorized_keys
分别在hadoop1、hadoop2和hadoop3中进行权限设置
[root@hadoop1 ~]# chmod 700 .ssh
[root@hadoop1 ~]# chmod 600 .ssh/authorized_keys
[root@hadoop2 ~]# chmod 700 .ssh
[root@hadoop2 ~]# chmod 600 .ssh/authorized_keys
[root@hadoop3 ~]# chmod 700 .ssh/
[root@hadoop3 ~]# chmod 600 .ssh/authorized_keys
测试:
[root@hadoop1 ~]# ssh hadoop2 Last login: Tue Dec 6 17:09:08 2022 from 192.168.91.1 [root@hadoop2 ~]# exit
登出
Connection to hadoop2 closed.
[root@hadoop1 ~]# ssh hadoop3
Last login: Tue Dec 6 17:09:12 2022 from 192.168.91.1
[root@hadoop3 ~]# exit4 -bash: exit4: 未找到命令
[root@hadoop3 ~]# exit
登出 Connection to hadoop3 closed.
2.3.11 hadoop启动命令
[root@hadoop1 ~]# start-all.sh ---启动hadoop所有守护进程
在hadoop1:
[root@hadoop1 ~]# jps
54578 DataNode
56274 Jps
55315 ResourceManager
54314 NameNode
55471 NodeManager
hadoop2:
[root@hadoop2 ~]# jps
29076 SecondaryNameNode
29284 NodeManager
28842 DataNode
30090 Jps
hadoop3:
[root@hadoop3 ~]# jps
28786 DataNode
29154 NodeManager
30197 Jps
通过网页方式进行访问:
http://192.168.91.100:50070

http://192.168.91.100:8088 ----yarn

2.3.12 Flume安装和配置
在企业中,经常需要在多个节点中进行采集数据,推介使用FLume进行数据采集,本节课主要内容讲解flume基础配置和简单应用
a、上传flume安装包
b、解压flume安装包
[root@hadoop1 ~]# tar -zxvf /soft/apache-flume-1.7.0-bin.tar.gz -C /opt
c、配置flum的环境变量
[root@hadoop1 ~]# vi /etc/profile
#Flume的环境变量
export FLUME_HOME=/opt/apache-flume-1.7.0-bin
export PATH=$JAVA_HOME/bin:$FLUME_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH:$HOME/bin
d、生效flume的环境变量
[root@hadoop1 ~]# source /etc/profile
e、测试 [root@hadoop1 ~]# flume-ng version
Flume 1.7.0
Source code repository: https://git-wip-us.apache.org/repos/asf/flume.git
Revision: 511d868555dd4d16e6ce4fedc72c2d1454546707
Compiled by bessbd on Wed Oct 12 20:51:10 CEST 2016
From source with checksum 0d21b3ffdc55a07e1d08875872c00523
2.4 Windows开发环境配置
2.4.1 jdk安装和环境变量配置
jdk选用版本----jdk1.8



配置jdk环境变量:
选择此电脑---->右键----->属性------>高级系统设置----->环境变量

追加到path路径下

测试:
win键+r 输入cmd进入dos命令窗口:
C:\Users\error>java -version
java version "1.8.0_151"
Java(TM) SE Runtime Environment (build 1.8.0_151-b12)
Java HotSpot(TM) 64-Bit Server VM (build 25.151-b12, mixed mode)
2.4.2 Maven安装和环境变量配置
解压Maven的安装包:


选择此电脑---->右键----->属性------>高级系统设置----->环境变量

追加path路径下:

测试:
win键+r键输入cmd
C:\Users\error>mvn -v
Apache Maven 3.0.5 (r01de14724cdef164cd33c7c8c2fe155faf9602da; 2013-02-19 21:51:28+0800)
Maven home: D:\apache-maven-3.0.5\bin\..
Java version: 1.8.0_151, vendor: Oracle Corporation
Java home: C:\Program Files\Java\jdk1.8.0_151\jre
Default locale: zh_CN, platform encoding: GBK
OS name: "windows 10", version: "10.0", arch: "amd64", family: "dos"
2.4.3 IDAE开发工具安装和配置











2.4.4 IDEA集成Maven开发环境

2.5 Spark环境搭建
a、上传spark软件包linux操作系统
b、解压Spark软件包
[root@hadoop1 ~]# tar -zxvf /soft/spark-2.1.1-bin-hadoop2.7.tgz -C /opt
c、配置Spark的环境变量
[root@hadoop1 ~]# vi /etc/profile
#Spark的环境变量
export SPARK_HOME=/opt/spark-2.1.1-bin-hadoop2.7
export PATH=$JAVA_HOME/bin:$SPARK_HOME/bin:$FLUME_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH:$HOME/bin
d、修改spark配置文件
[root@hadoop1 conf]# pwd
/opt/spark-2.1.1-bin-hadoop2.7/conf
修改spark的启动文件:
[root@hadoop1 conf]# cp spark-env.sh.template spark-env.sh
[root@hadoop1 conf]# vi spark-env.sh
export JAVA_HOME=/opt/jdk1.8.0_162
修改slaves文件:
[root@hadoop1 conf]# cp slaves.template slaves
[root@hadoop1 conf]# vi slaves
hadoop1
hadoop2
hadoop3
把配置Spark发送到hadoop2、hadoop3节点上:
[root@hadoop1 ~]# scp -r /opt/spark-2.1.1-bin-hadoop2.7 hadoop2:/opt/
[root@hadoop1 ~]# scp -r /opt/spark-2.1.1-bin-hadoop2.7 hadoop3:/opt/
把系统配置文件也发送到hadoop2、hadoop3节点上:
[root@hadoop1 ~]# scp /etc/profile hadoop2:/etc/profile
profile 100% 2183 1.7MB/s 00:00
[root@hadoop1 ~]# scp /etc/profile hadoop3:/etc/profile
profile
分别在hadoop2和hadoop3上执行source
[root@hadoop1 ~]# cd /opt/spark-2.1.1-bin-hadoop2.7/sbin/
[root@hadoop1 ~]# cd /opt/spark-2.1.1-bin-hadoop2.7/sbin/
[root@hadoop1 sbin]# ./start-all.sh
starting org.apache.spark.deploy.master.Master, logging to /opt/spark-2.1.1-bin-hadoop2.7/logs/spark-root-org.apache.spark.deploy.master.Master-1-hadoop1.out
hadoop2: starting org.apache.spark.deploy.worker.Worker, logging to /opt/spark-2.1.1-bin-hadoop2.7/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-hadoop2.out
hadoop3: starting org.apache.spark.deploy.worker.Worker, logging to /opt/spark-2.1.1-bin-hadoop2.7/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-hadoop3.out
hadoop1: starting org.apache.spark.deploy.worker.Worker, logging to /opt/spark-2.1.1-bin-hadoop2.7/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-hadoop1.out

2.6 搭建一下Windows--spark的开发环境
安装scala工具包
scala-2.11.0.msi-----自行安装
配置scala环境变量
选择此电脑---右键-----属性-----高级系统设置------环境变量

追加到path路径下:

win键+r键 输入cmd
C:\Users\error>scala
Welcome to Scala version 2.11.0 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_151).
Type in expressions to have them evaluated.
Type :help for more information. scala> 16*16
res0: Int = 256
idea安装scala插件:


创建一个scala项目:





三、大数据技术应用
3.1 Flume的应用
3.1.1 Flume的初体验
https://flume.apache.org/releases/content/1.11.0/FlumeUserGuide.html -----flume的官方文档

flume本质:一个agent,表示一个代理,相当于一个JVM
agent是由多个组件组成,常用的组件有source、channel、sink
source:数据源组件------主要用于采集数据
channel:管道的组件-----缓冲池
sink:下沉组件---------目的地
类比生活中真实事物------自来水场(source)--------管道(channel)---------家中水龙头(下沉)
上述案例中:以webserver产生日志数据作为数据源------使用内存(文件)作为channel------数据下沉hdfs中,hdfs作为的sink
需求:
采集sockt产生数据,把数据下沉到日志中
source:socket
channel:memory
sink:logger(日志)
准备工作:
[root@hadoop1 ~]# yum install nc -y
小测试:
开启一个服务端:
[root@hadoop1 ~]# nc -l 55555
客户端连接上了服务端:
[root@hadoop1 ~]# nc hadoop1 55555
flume进行数据采集----相当于是服务端:
[root@hadoop1 ~]# mkdir /flume-run
编写flume执行案例:
[root@hadoop1 ~]# vi /flume-run/nc-memory-logger.conf
# a1表示agent别名,分别定义source、channel、sinks
a1.sources = r1
a1.sinks = k1
a1.channels = c1# 详细配置source
a1.sources.r1.type = netcat
a1.sources.r1.bind = hadoop1
a1.sources.r1.port = 44444# 详细配置sink
a1.sinks.k1.type = logger# 详细配置管道
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100# 绑定source和channel,绑定sink和channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
执行flume的数据采集文件:
[root@hadoop1 ~]# flume-ng agent -n a1 -c /opt/apache-flume-1.7.0-bin/conf/ -f /flume-run/nc-memory-logger.conf -Dflume.root.logger=INFO,console
-n:表示agent的名称
-c:表示flume配置
-f:表示执行flume文件
-D: 表示Java属性配置信息
2022-12-06 19:15:53,140 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 68 65 6C 6C 6F 20 66 6C 75 6D 65 hello flume }
2022-12-06 19:15:58,032 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 68 65 6C 6C 6F 20 6E 63 hello nc }
2022-12-06 19:16:00,688 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 68 65 6C 6C 6F 20 68 61 64 6F 6F 70 hello hadoop }客户端:
[root@hadoop1 ~]# nc hadoop1 44444
hello flume
OK
hello nc
OK
hello hadoop
OK
3.1.2 企业开发中----离线数据采集
日志类型数据,不需要立马得出结论。可以通过设置定时器方式,定时进行采集
模拟企业开发中,定时采集案例:
定时采集数据到hdfs上
数据源:采集整个文件夹方式----dir
管道:内存----memory
下沉:hdfs分布式文件系统上
a、创建一个文件夹----用来存放采集时需要文件数据
[root@hadoop1 ~]# kill -9 101330 ----杀死进程
[root@hadoop1 ~]# mkdir /web_log
[root@hadoop1 ~]# vi /web_log/a.log
hello,java,hello,hadoop
hello,linux,java,c
hello,linux,c,hadoop
hadoop,spark,linux
[root@hadoop1 ~]# vi /web_log/b.log
hello,c
java,linux,hadoop
spark,c,python
java,c,python
需求把上述两个日志文件数据采集到hdfs上。
[root@hadoop1 ~]# vi /flume-run/dir-memory-hdfs.conf
# a1表示agent别名,分别定义source、channel、sinks
a1.sources = r1
a1.sinks = k1
a1.channels = c1# 详细配置source
a1.sources.r1.type = spooldir
#需要采集文件夹位置
a1.sources.r1.spoolDir = /web_log/# 详细配置sink
a1.sinks.k1.type = hdfs
#需要采集文件到hfds中位置
a1.sinks.k1.hdfs.path = /flume/events/%Y-%m-%d
#防止采集时候出现大量小文件
a1.sinks.k1.hdfs.rollSize = 0
a1.sinks.k1.hdfs.rollCount = 0
#设置hdfs中文件类型
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.writeFormat = Text
#设置本地的时间戳
a1.sinks.k1.hdfs.useLocalTimeStamp = true# 详细配置管道
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100# 绑定source和channel,绑定sink和channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
执行文件:
[root@hadoop1 ~]# flume-ng agent -n a1 -c /opt/apache-flume-1.7.0-bin/conf/ -f /flume-run/dir-memory-hdfs.conf -Dflume.root.logger=INFO,console
测试:
[root@hadoop1 ~]# hadoop fs -cat /flume/events/2022-12-06/FlumeData.1670337504112
hello,java,hello,hadoop
hello,linux,java,c
hello,linux,c,hadoop
hadoop,spark,linux
hello,c
java,linux,hadoop
spark,c,python
java,c,python
3.1.3 企业开发中----实时数据采集
实时数据如何进行监控
模拟:
构建实时数据的文件:
[root@hadoop1 ~]# vi /tmp/gp.log ----空文件
需求数据会实时写入gp.log文件中,需要采集gp.log中实时数据
编辑flume采集文件:
[root@hadoop1 ~]# vi /flume-run/file-memory-logger.conf
# a1表示agent别名,分别定义source、channel、sinks
a1.sources = r1
a1.sinks = k1
a1.channels = c1# 详细配置source
a1.sources.r1.type = exec
# 实时去关注文件最后一行数据
a1.sources.r1.command = tail -F /tmp/gp.log# 详细配置sink
a1.sinks.k1.type = logger# 详细配置管道
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100# 绑定source和channel,绑定sink和channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
运行flume采集文件:
[root@hadoop1 ~]# flume-ng agent -n a1 -c /opt/apache-flume-1.7.0-bin/conf/ -f /flume-run/file-memory-logger.conf -Dflume.root.logger=INFO,console
测试:
[root@hadoop1 ~]# echo hello java >> /tmp/gp.log
[root@hadoop1 ~]# echo hello hadoop >> /tmp/gp.log
测试结果展示:
ava:95)] Event: { headers:{} body: 68 65 6C 6C 6F 20 6A 61 76 61 hello java }
2022-12-06 23:35:46,393 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 68 65 6C 6C 6F 20 68 61 64 6F 6F 70 hello hadoop }
3.2 第一个Maven项目





3.3 复习
a、hadoop完全分布式搭建
hadoop namenode -format -----不能多次格式化namenode
b、flume安装和配置
解压flume软件包、配置flume的环境变量、编写flume执行文件
c、flume在企业中常规应用
离线数据的采集和实时数据的采集
d、windows中配置开发环境
a、jdk环境变量配置
b、Maven环境变量的配置
c、idea安装和破解
d、idea继承Maven的开发环境
e、创建Maven项目
3.4 利用Java代码操作HDFS
Hadoop软件本身由java语言编写而成,可以说Hadoop跟Java是无缝对接。java中提供一套API可以用于操作的HDFS
在hdfs中提供很多操作文件系统命令:
创建文件夹
[root@hadoop1 ~]# hadoop fs -mkdir /linuxMkdir
删除文件夹
[root@hadoop1 ~]# hadoop fs -rmdir /linuxMkdir
上传一个文件到hdfs上:
[root@hadoop1 ~]# hadoop fs -put anaconda-ks.cfg /linuxMkdir
[root@hadoop1 ~]# hadoop fs -lsr /linuxMkdir
lsr: DEPRECATED: Please use 'ls -R' instead.
-rw-r--r-- 3 root supergroup 1257 2022-12-07 07:02 /linuxMkdir/anaconda-ks.cfg
下载一个文件到linux中:
[root@hadoop1 ~]# hadoop fs -get /linuxMkdir/anaconda-ks.cfg /tmp
根据上述命令,编写java代码:
准备工作:
添加hadoop相关依赖
Maven:
a、用于构建项目
b、管理jar包
c、项目打包、运行工作<dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>2.7.3</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-common</artifactId> <version>2.7.3</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-hdfs</artifactId> <version>2.7.3</version> </dependency>

解决方法:[root@hadoop1 ~]# hadoop fs -chmod -R 777 /
package org.tjcj.hdfs;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.io.IOException;
/**
* 主要用于操作hdfs
*/
public class HDFSUtil {
//文件系统
private static FileSystem fileSystem;
static{//静态代码块主要作用用于实例化fileSystem
//获取当前的hadoop开发环境
Configuration conf = new Configuration();
//设置文件系统类型
conf.set("fs.defaultFS","hdfs://192.168.91.100:9000");
if(fileSystem == null){
try {
fileSystem = FileSystem.get(conf);
} catch (IOException e) {
e.printStackTrace();
}
}
}
/**
* 创建一个文件夹方法
* @param path
*/
public static void createDir(String path) throws IOException {
boolean flag = false;
if (!fileSystem.exists(new Path(path))){//如果文件夹不存在
flag = fileSystem.mkdirs(new Path(path));
}
if(flag){
System.out.println("文件夹已经创建成功。。。");
}else{
System.out.println("文件夹已经存在。。。。");
}
}
/**
* 删除文件夹以及文件
* @param path
*/
public static void delete(String path) throws IOException {
boolean flag = false;
if(fileSystem.exists(new Path(path))){
flag = fileSystem.delete(new Path(path),true);
}
if(flag){
System.out.println("文件或者文件夹已经删除");
}else{
System.out.println("文件或者文件夹不存在");
}
}
/**
* 上传到hdfs上
* @param srcPath
* @param destPath
* @throws IOException
*/
public static void uploadFile(String srcPath,String destPath) throws IOException {
fileSystem.copyFromLocalFile(false,true,new Path(srcPath),new Path(destPath));
System.out.println("文件上传成功!!!");
}
public static void downloadFile(String srcPath,String destPath) throws IOException {
fileSystem.copyToLocalFile(false,new Path(srcPath),new Path(destPath),true);
System.out.println("文件下载成功");
}
public static void main(String[] args) throws IOException {
// createDir("/javaMkdir");
// delete("/javaMkdir");
// uploadFile("D:\\data\\input\\lol.txt","/javaMkdir");
downloadFile("/javaMkdir/lol.txt","D:\\");
}
}
3.5 MapReduce----wordcount
简单的编程模型:
map:利用核心思想,并行处理
reduce:聚合,把map端输出的信息做一个统计
引入依赖:
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-common</artifactId>
<version>2.7.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>2.7.3</version>
</dependency>代码:
package org.tjcj.mr;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
/**
* 单词计数
*/
public class WordCount {
public static class MyMapper extends Mapper<LongWritable,Text,Text,LongWritable>{
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//1、拿到一行数据
String line = value.toString();
//2、根据,进行切割
String [] splits = line.split(",");
//3、写出到shuffle阶段
for (String split : splits) {
context.write(new Text(split),new LongWritable(1)); //[hadoop,1]
}
}
}
public static class MyReducer extends Reducer<Text,LongWritable,Text,LongWritable>{
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
long count=0;
for (LongWritable value : values) {
count+=value.get();
}
context.write(key,new LongWritable(count));
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
//获取当前hadoop开发环境
Configuration configuration = new Configuration();
configuration.set("fs.defaultFS","hdfs://192.168.91.100:9000");
//创建MapReduce任务
Job job = Job.getInstance(configuration);
//设置执行的主类
job.setJarByClass(WordCount.class);
//设置Mapper
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
//设置Reducer
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
//设置输入路径
FileInputFormat.addInputPath(job,new Path("/flume/events/2022-12-06/FlumeData.1670337504112"));
//设置输出路径
FileOutputFormat.setOutputPath(job,new Path("/mr/out/out1"));
//提交任务
System.out.println(job.waitForCompletion(true)?"success!!!":"failed!!!");
}
}[root@hadoop1 ~]# hadoop fs -cat /mr/out/out1/part-r-00000
c 5
hadoop 4
hello 5
java 4
linux 4
python 2
spark 2
wordcount:单词计数,统计单词出现次数,利用shuffle阶段特性:
a、合并key值相同
b、根据key值进行自然排序
c、根据key值跟reduce个数求模,分配到不同的reduce中
3.6 TopN问题热卖榜,topn类似问题,可以使用MapReduce做处理
接着上午案例:统计大学中,学科所修次数,统计排名靠前学科(统计前三学科)
package org.tjcj.mr;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
import java.util.TreeMap;
/**
* 统计学科排名
*/
public class TopN {
public static class MyMapper extends Mapper<LongWritable,Text,Text,LongWritable>{
private TreeMap<Long,String> treeMap = new TreeMap<>();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//1、获取一行数据
String line = value.toString();//c 5
//2、切分字符串
String [] splits = line.split("\t");
treeMap.put(Long.parseLong(splits[1]),splits[0]);
}
/**
* 整个MapReduce中只调用一次
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void cleanup(Context context) throws IOException, InterruptedException {
while(treeMap.size()>3){
treeMap.remove(treeMap.firstKey());
}
for (Long aLong : treeMap.keySet()) {
context.write(new Text(treeMap.get(aLong)),new LongWritable(aLong));
}
}
}
public static class MyReducer extends Reducer<Text,LongWritable,Text,LongWritable>{
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
for (LongWritable value : values) {
context.write(key,value);
}
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
//获取当前hadoop开发环境
Configuration configuration = new Configuration();
configuration.set("fs.defaultFS","hdfs://192.168.91.100:9000");
//创建MapReduce任务
Job job = Job.getInstance(configuration);
//设置执行的主类
job.setJarByClass(TopN.class);
//设置Mapper
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
//设置Reducer
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
//设置输入路径
FileInputFormat.addInputPath(job,new Path("/mr/out/out1/part-r-00000"));
//设置输出路径
FileOutputFormat.setOutputPath(job,new Path("/mr/out/out2"));
//提交任务
System.out.println(job.waitForCompletion(true)?"success!!!":"failed!!!");
}
}[root@hadoop1 ~]# hadoop fs -cat /mr/out/out2/part-r-00000
hello 5
linux 4
spark 2
有瑕疵,如何避免出现
package org.tjcj.mr;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
import java.util.TreeMap;
/**
* 统计学科排名
*/
public class TopN {
public static class MyMapper extends Mapper<LongWritable,Text,Text,LongWritable>{
private TreeMap<String,String> treeMap = new TreeMap<>();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//1、获取一行数据
String line = value.toString();//c 5
//2、切分字符串
String [] splits = line.split("\t");
//生成新的key
String newKey=splits[1]+"-"+Math.random();
System.out.println(newKey);
treeMap.put(newKey,splits[0]);
}
/**
* 整个MapReduce中只调用一次
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void cleanup(Context context) throws IOException, InterruptedException {
while(treeMap.size()>3){
treeMap.remove(treeMap.firstKey());
}
for (String s : treeMap.keySet()) {
String [] str = s.split("-");
context.write(new Text(treeMap.get(s)),new LongWritable(Long.parseLong(str[0])));
}
}
}
public static class MyReducer extends Reducer<Text,LongWritable,Text,LongWritable>{
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
for (LongWritable value : values) {
context.write(key,value);
}
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
//获取当前hadoop开发环境
Configuration configuration = new Configuration();
configuration.set("fs.defaultFS","hdfs://192.168.91.100:9000");
//创建MapReduce任务
Job job = Job.getInstance(configuration);
//设置执行的主类
job.setJarByClass(TopN.class);
//设置Mapper
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
//设置Reducer
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
//设置输入路径
FileInputFormat.addInputPath(job,new Path("/mr/out/out1/part-r-00000"));
//设置输出路径
FileOutputFormat.setOutputPath(job,new Path("/mr/out/out3"));
//提交任务
System.out.println(job.waitForCompletion(true)?"success!!!":"failed!!!");
}
}运行结果:
[root@hadoop1 ~]# hadoop fs -cat /mr/out/out3/part-r-00000
c 5
hadoop 4
hello 5
3.7 数据清洗数据清洗第一步:数据去重
[root@hadoop1 web_log]# cat a.log.COMPLETED b.log.COMPLETED >>c.log
[root@hadoop1 web_log]# cat a.log.COMPLETED b.log.COMPLETED >>c.log
[root@hadoop1 web_log]# cat a.log.COMPLETED b.log.COMPLETED >>c.log
[root@hadoop1 web_log]# cat a.log.COMPLETED b.log.COMPLETED >>c.log
原始文件:
[root@hadoop1 web_log]# cat c.log
hello,java,hello,hadoop
hello,linux,java,c
hello,linux,c,hadoop
hadoop,spark,linux
hello,c
java,linux,hadoop
spark,c,python
java,c,python
hello,java,hello,hadoop
hello,linux,java,c
hello,linux,c,hadoop
hadoop,spark,linux
hello,c
java,linux,hadoop
spark,c,python
java,c,python
hello,java,hello,hadoop
hello,linux,java,c
hello,linux,c,hadoop
hadoop,spark,linux
hello,c
java,linux,hadoop
spark,c,python
java,c,python
hello,java,hello,hadoop
hello,linux,java,c
hello,linux,c,hadoop
hadoop,spark,linux
hello,c
java,linux,hadoop
spark,c,python
java,c,python
hello,java,hello,hadoop
hello,linux,java,c
hello,linux,c,hadoop
hadoop,spark,linux
hello,c
java,linux,hadoop
spark,c,python
java,c,python
上述文件中存在很多重复文件,需求对重复文件进行去重工作:
[root@hadoop1 ~]# hadoop fs -put /web_log/c.log /linuxMkdir/
[root@hadoop1 ~]# hadoop fs -chmod -R 777 /linuxMkdir/
package org.tjcj.mr;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
/**
* 数据去重
*/
public class DupMR {
public static class MyMapper extends Mapper<LongWritable,Text,Text,NullWritable>{
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
context.write(value,NullWritable.get());
}
}
public static class MyReducer extends Reducer<Text,NullWritable,Text,NullWritable>{
@Override
protected void reduce(Text key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException {
context.write(key,NullWritable.get());
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
//获取当前hadoop开发环境
Configuration configuration = new Configuration();
configuration.set("fs.defaultFS","hdfs://192.168.91.100:9000");
//创建MapReduce任务
Job job = Job.getInstance(configuration);
//设置执行的主类
job.setJarByClass(DupMR.class);
//设置Mapper
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(NullWritable.class);
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
//设置输入路径
FileInputFormat.addInputPath(job,new Path("/linuxMkdir/c.log"));
//设置输出路径
FileOutputFormat.setOutputPath(job,new Path("/mr/out/out5"));
//提交任务
System.out.println(job.waitForCompletion(true)?"success!!!":"failed!!!");
}
}[root@hadoop1 ~]# hadoop fs -cat /mr/out/out5/part-r-00000
hadoop,spark,linux
hello,c
hello,java,hello,hadoop
hello,linux,c,hadoop
hello,linux,java,c
java,c,python
java,linux,hadoop
spark,c,python
作业:
统计2020年中ban选英雄排名前五的
思路:
a、统计英雄ban选的次数
b、统计排名前五

3.8 处理英雄联盟数据案例
代码:
第一步,统计ban选英雄的次数
package org.tjcj.mr;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
/**
* 统计英雄ban选次数
*/
public class BanMR1 {
public static class MyMapper extends Mapper<LongWritable,Text,Text,LongWritable>{
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//1、拿到一行数据
String line = value.toString();
if(!line.contains("agt")){//去除第一行数据
//2、根据\t,进行切割
String [] splits = line.split("\t");
//3、写出到shuffle阶段
for (int i=10;i<15;i++) {//找到ban选英雄
context.write(new Text(splits[i]),new LongWritable(1)); //[hadoop,1]
}
}
}
}
public static class MyReducer extends Reducer<Text,LongWritable,Text,LongWritable>{
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
long count=0;
for (LongWritable value : values) {
count+=value.get();
}
context.write(key,new LongWritable(count));
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
//获取当前hadoop开发环境
Configuration configuration = new Configuration();
configuration.set("fs.defaultFS","hdfs://192.168.91.100:9000");
//创建MapReduce任务
Job job = Job.getInstance(configuration);
//设置执行的主类
job.setJarByClass(BanMR1.class);
//设置Mapper
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
//设置Reducer
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
//设置输入路径
FileInputFormat.addInputPath(job,new Path("/javaMkdir/lol.txt"));
//设置输出路径,输出路径一定要确保不存在
FileOutputFormat.setOutputPath(job,new Path("/mr/out/out6"));
//提交任务
System.out.println(job.waitForCompletion(true)?"success!!!":"failed!!!");
}
}
[root@hadoop1 ~]# hadoop fs -cat /mr/out/out6/part-r-00000
Aatrox 93
Akali 123
Alistar 7
Aphelios 545
Ashe 71
Aurelion Sol 10
Azir 268
Bard 178
Blitzcrank 42
Braum 92
Caitlyn 81
。。。
第二步,选取ban选英雄排名前五的
package org.tjcj.mr;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
import java.util.TreeMap;
/**
* 统计英雄ban选的排名
*/
public class BanMR2 {
public static class MyMapper extends Mapper<LongWritable,Text,Text,LongWritable>{
private TreeMap<Long,String> treeMap = new TreeMap<>();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//1、获取一行数据
String line = value.toString();//c 5
//2、切分字符串
String [] splits = line.split("\t");
treeMap.put(Long.parseLong(splits[1]),splits[0]);
}
/**
* 整个MapReduce中只调用一次
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void cleanup(Context context) throws IOException, InterruptedException {
while(treeMap.size()>5){
treeMap.remove(treeMap.firstKey());
}
for (Long aLong : treeMap.keySet()) {
context.write(new Text(treeMap.get(aLong)),new LongWritable(aLong));
}
}
}
public static class MyReducer extends Reducer<Text,LongWritable,Text,LongWritable>{
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
for (LongWritable value : values) {
context.write(key,value);
}
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
//获取当前hadoop开发环境
Configuration configuration = new Configuration();
configuration.set("fs.defaultFS","hdfs://192.168.91.100:9000");
//创建MapReduce任务
Job job = Job.getInstance(configuration);
//设置执行的主类
job.setJarByClass(BanMR2.class);
//设置Mapper
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
//设置Reducer
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
//设置输入路径
FileInputFormat.addInputPath(job,new Path("/mr/out/out6/part-r-00000"));
//设置输出路径
FileOutputFormat.setOutputPath(job,new Path("/mr/out/out8" ));
//提交任务
System.out.println(job.waitForCompletion(true)?"success!!!":"failed!!!");
}
}
运行结果:
[root@hadoop1 ~]# hadoop fs -cat /mr/out/out8/part-r-00000
Aphelios 545
Kalista 460
LeBlanc 474
Sett 602
Varus 469
3.9 统计2020年春季赛中,LPL赛区中,拿到一血队伍的胜率分析:
条件春季赛,lpl赛区
package org.tjcj.mr;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
/**
* 统计拿到1血队伍的胜率
*/
public class WinFirstBlod {
public static class MyMapper extends Mapper<LongWritable,Text,Text,Text>{
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//1、拿到一行数据
String line = value.toString();
if(!line.contains("agt") && line.contains("Spring") && line.contains("LPL")){//根据要求进行数据的筛选
//2、切分数据
String [] splits = line.split("\t");
int firstBlood = Integer.parseInt(splits[24]);
if(firstBlood==1){//拿过1血队伍
context.write(new Text("FirstBlood"),new Text(splits[16]+","+firstBlood));
}
}
}
}
public static class MyReducer extends Reducer<Text,Text,Text,LongWritable>{
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
long sum=0;//统计拿一血队伍总次数
long win=0;//拿到1血且胜利情况
for (Text value : values) {
String line =value.toString();
String [] str = line.split(",");
int result=Integer.parseInt(str[0]);
if(result==1){//队伍获胜了
win++;
}
sum++;
}
context.write(new Text("拿1血队伍的胜率"),new LongWritable(win*100/sum));
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
//获取当前hadoop开发环境
Configuration configuration = new Configuration();
configuration.set("fs.defaultFS","hdfs://192.168.91.100:9000");
//创建MapReduce任务
Job job = Job.getInstance(configuration);
//设置执行的主类
job.setJarByClass(WinFirstBlod.class);
//设置Mapper
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
//设置Reducer
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
//设置输入路径
FileInputFormat.addInputPath(job,new Path("/javaMkdir/lol.txt"));
//设置输出路径
FileOutputFormat.setOutputPath(job,new Path("/mr/out/out9"));
//提交任务
System.out.println(job.waitForCompletion(true)?"success!!!":"failed!!!");
}
}[root@hadoop1 ~]# hadoop fs -cat /mr/out/out9/part-r-00000
拿1血队伍的胜率 63
加入日志依赖:
<!--添加日志-->
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>log4j属性文件:
log4j.rootLogger=INFO,console
log4j.additivity.org.apache=true
# 控制台(console)
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.Threshold=INFO
log4j.appender.console.ImmediateFlush=true
log4j.appender.console.Target=System.err
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=[%-5p] %d(%r) --> [%t] %l: %m %x %n3.10 MapReduce的小测试
案例:
1、统计2020年全年度,击杀榜排名前五的队伍
2、统计2020年全年度,RED的胜率
3、分别统计lck、lpl赛区拿五杀的队伍
3.11 Spark中Wordcount案例
[root@hadoop1 ~]# spark-shell -----进入scala编程界面
scala> sc.textFile("/web_log/c.log") -----获取一个文件 hello,java
scala> res0.flatMap(_.split(",")) -------hello java
scala> res1.map((_,1)) -------<hello,1>
scala> res2.reduceByKey(_+_) -------根据key值进行合并,value值进行相加
scala> res3.sortBy(_._2,false) -------根据值进行排序
scala> res4.collect -------把数据变成数组
res6: Array[(String, Int)] = Array((hello,25), (c,25), (linux,20), (java,20), (hadoop,20), (python,10), (spark,10))
scala> res6.foreach(println) -------打印数据
(hello,25)
(c,25)
(linux,20)
(java,20)
(hadoop,20)
(python,10)
(spark,10)
上述案例可以写一起:
scala> sc.textFile("/web_log/c.log").flatMap(_.split(",")).map((_,1)).reduceByKey(_+_).collect.foreach(println)
(python,10)
(hello,25)
(linux,20)
(java,20)
(spark,10)
(hadoop,20)
(c,25)
3.12 Windows下Spark的开发环境
spark依赖:
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.1.1</version>
</dependency>wordcount案例:
package org.tjcj
import org.apache.spark.{SparkConf, SparkContext}
/**
* Spark中经典案例
*/
object WordCount {
def main(args: Array[String]): Unit = {
//1、获取SparkContext对象
val conf = new SparkConf().setAppName("WordCount").setMaster("local[*]")
val sc = new SparkContext(conf)
//2、WordCount核心代码
sc.textFile("D:\\a.txt").flatMap(_.split(",")).map((_,1)).reduceByKey(_+_).
sortBy(_._2,false).collect().foreach(println)
}
}3.13 Spark中RDD
RDD:弹性分布式数据集-------封装一些功能
Spark提供很多便于用户直接操作方法------RDD(弹性分布式数据集)
RDD特性:
1.RDD可以看做是⼀些列partition所组成的
2.RDD之间的依赖关系
3.算⼦是作⽤在partition之上的
4.分区器是作⽤在kv形式的RDD上
5.partition提供的最佳计算位置,利于数据处理的本地化即计算向数据移动⽽不是移动数据(就近原则)
RDD中弹性:
存储的弹性:内存与磁盘的
⾃动切换容错的弹性:数据丢失可以
⾃动恢复计算的弹性:计算出错重试机制
分⽚的弹性:根据需要重新分⽚
3.13.1 RDD创建
集群中创建:
利用集合方式进行创建------->Array、List
scala> val a = Array(1,2,3,4)
a: Array[Int] = Array(1, 2, 3, 4)
scala> val b = List(1,2,3,4)
b: List[Int] = List(1, 2, 3, 4)
方式一:
scala> sc.parallelize(a)
res0: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at parallelize at <console>:27
方式二:
scala> sc.makeRDD(b)
res1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[1] at makeRDD at <console>:27
需求:
a、res0整体值变为原来两倍
scala> res0.map(_*2).collect().foreach(println)
2
4
6
8
b、res1整体+1
scala> res1.map(_+1).collect().foreach(println)
2
3
4
5
scala> res1.map(_=>{"a"}).collect().foreach(println)
a
a
a
a
通过外部文件方式:
scala> sc.textFile("/web_log/c.log")
res11: org.apache.spark.rdd.RDD[String] = /web_log/c.log MapPartitionsRDD[9] at textFile at <console>:25
3.13.2 常用算子(RDD)
参考网站:http://homepage.cs.latrobe.edu.au/zhe/ZhenHeSparkRDDAPIExamples.html
按照字母自然顺序讲解常用算子:
collect------可以把RDD转换为数组
scala> val rdd = sc.makeRDD(Array(1,2,3,4))
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[10] at makeRDD at <console>:24
scala> rdd.collect()
res13: Array[Int] = Array(1, 2, 3, 4)
count------计数
scala> sc.textFile("/web_log/c.log")
res14: org.apache.spark.rdd.RDD[String] = /web_log/c.log MapPartitionsRDD[12] at textFile at <console>:25
scala> res14.count()
res15: Long = 40
distinct ----去重
scala> sc.textFile("/web_log/c.log").distinct()
res16: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[17] at distinct at <console>:25
scala> res16.count()
res17: Long = 8
first--------拿到第一行数据
scala> sc.textFile("hdfs://192.168.91.100:9000//javaMkdir/lol.txt")
res18: org.apache.spark.rdd.RDD[String] = hdfs://192.168.91.100:9000//javaMkdir/lol.txt MapPartitionsRDD[19] at textFile at <console>:25
scala> res18.first()
res19: String = " agt league split playoffs date game patch side team ban1 ban2 ban3 ban4ban5 gamelength result kills deaths assists doublekills triplekills quadrakills pentakills firstblood team kpm firstdragon dragons opp_dragons elementaldrakes opp_elementaldrakes infernals mountains clouds oceans dragons (type unknown) elders opp_elders firstherald heralds opp_heralds firstbaron barons opp_barons firsttower towers opp_towers firstmidtower firsttothreetowers inhibitors opp_inhibitors damagetochampions dpm damageshare damagetakenperminute damagemitigatedperminute wardsplaced wpm wardskilled wcpm controlwardsbought visionscore vspm totalgold earnedgold earned gpm earnedgoldshare goldspent gspd total cs minionkills monsterkills monsterkillsownjungle monsterkillsenemyjungle cspm goldat1...
filter -------filter过滤
scala> sc.textFile("hdfs://192.168.91.100:9000//javaMkdir/lol.txt")
res20: org.apache.spark.rdd.RDD[String] = hdfs://192.168.91.100:9000//javaMkdir/lol.txt MapPartitionsRDD[21] at textFile at <console>:25
scala> res20.filter(_.contains("agt")).collect().foreach(println)
agt league split playoffs date game patch side team ban1 ban2 ban3 ban4 ban5 gamelength result kills deaths assists doublekills triplekills quadrakills pentakills firstblood team kpm firstdragon dragons opp_dragons elementaldrakes opp_elementaldrakes infernals mountains clouds oceans dragons (type unknown) elders opp_elders firstherald heralds opp_heralds firstbaron barons opp_barons firsttower towers opp_towers firstmidtower firsttothreetowers inhibitors opp_inhibitors damagetochampions dpm damageshare damagetakenperminute damagemitigatedperminute wardsplaced wpm wardskilled wcpm controlwardsbought visionscore vspm totalgold earnedgold earned gpm earnedgoldshare goldspent gspd total cs minionkills monsterkills monsterkillsownjungle monsterkillsenemyjungle cspm goldat10 xpat10 csat10 opp_goldat10opp_xpat10 opp_csat10 golddiffat10 xpdiffat10 csdiffat10 goldat15 xpat15 csat15 opp_goldat15 opp_xpat15 opp_csat15 golddiffat15 xpdiffat15 csdiffat15
flatMap -----一行输入,n行输出
scala> sc.makeRDD(List("a","b","c")).flatMap(_*3).map((_,1)).collect().foreach(println)
(a,1)
(a,1)
(a,1)
(b,1)
(b,1)
(b,1)
(c,1)
(c,1)
(c,1)
foreach ------遍历
scala> sc.makeRDD(List("a","b","c")).foreach(x=>println(x+"--spark"))
a--spark
b--spark
c--spark
scala> sc.makeRDD(List("a","b","c")).foreach(println)
b
c
a
map --------变形
scala> sc.makeRDD(List('a','b','c')).map(_*2).collect().foreach(println)
194
196
198
max最大值:
scala> sc.makeRDD(List(1,2,3,4,5)).max()
res37: Int = 5
min最小值:
scala> sc.makeRDD(List(1,2,3,4,5)).min()
res38: Int = 1
reduceByKey-----根据key进行合并
scala> sc.makeRDD(List("java","linux","c","java","hadoop"))
res39: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[47] at makeRDD at <console>:25
scala> res39.map((_,1)).reduceByKey(_+_).collect().foreach(println)
(linux,1)
(java,2)
(hadoop,1)
(c,1)
saveAsTextFile-----把数据保存到某个位置
scala> res39.map((_,1)).reduceByKey(_+_).saveAsTextFile("/tmp/out1")
测试:
[root@hadoop1 tmp]# cd out1
[root@hadoop1 out1]# ls
part-00000 part-00001 _SUCCESS
[root@hadoop1 out1]# cat part-00000
(linux,1)
(java,2)
[root@hadoop1 out1]# cat part-00001
(hadoop,1)
(c,1)
sortBy------常用于排序工作
scala> res39.map((_,1)).reduceByKey(_+_).sortBy(_._1,false).collect().foreach(println)
(linux,1)
(java,2)
(hadoop,1)
(c,1)
scala> res39.map((_,1)).reduceByKey(_+_).sortBy(_._2,false).collect().foreach(println)
(java,2)
(linux,1)
(hadoop,1)
(c,1)
注意:false表示降序,true表示自然排序
take-----选取前几
scala> res39.map((_,1)).reduceByKey(_+_).sortBy(_._2,false).take(3)
res46: Array[(String, Int)] = Array((java,2), (linux,1), (hadoop,1))
top-----排名
scala> res39.map((_,1)).reduceByKey(_+_).sortBy(_._2,false).top(3)
res47: Array[(String, Int)] = Array((linux,1), (java,2), (hadoop,1))
3.13.3 统计ban选英雄需求:
统计lol,春季赛中,ban选英雄的排名前五英雄
package org.tjcj
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* 统计英雄联盟中ban选英雄排名前五的英雄
*/
object BanTop5 {
def main(args: Array[String]): Unit = {
//1、获取SparkContext对象
val conf:SparkConf = new SparkConf().setAppName("ban5").setMaster("local[*]")
val sc:SparkContext = new SparkContext(conf)
//2、获取一个RDD对象,通过外部文件方式获取RDD
val rdd:RDD[String] = sc.textFile("hdfs://192.168.91.100:9000/javaMkdir/lol.txt")
//3、过滤文件,找到需要处理的信息
val filterRDD:RDD[String] = rdd.filter(!_.contains("agt")).filter(_.contains("Spring"))
//4、对原始数据进行变形
val mapRDD = filterRDD.map(x=>{//x表示传入一行数据
var splits=x.split("\t")
var str=""
var i=10
while(i<15){
str+=splits(i)+","
i+=1
}
str.substring(0,str.length-1) //新的字符串
})
//5、亚平处理
val flatMapRDD = mapRDD.flatMap(_.split(","))
//6、变形
val mapRDD1 = flatMapRDD.map((_,1))
//7、统计
val reduceRDD = mapRDD1.reduceByKey(_+_)
//8、排序
val sortRDD = reduceRDD.sortBy(_._2,false)
//val修饰常量,var修饰变量
//9、取值
val array = sortRDD.take(5)
//10、转换保存
sc.makeRDD(array).repartition(1).saveAsTextFile("hdfs://192.168.91.100:9000/spark/out/out2")
}
}测试结果:
[root@hadoop3 ~]# hadoop fs -cat /spark/out/out2/part-00000
(Aphelios,385)
(Sett,331)
(LeBlanc,294)
(Senna,262)
(Zoe,251)
3.13.4 统计整个赛年中lck赛区,击杀榜排名前5队伍,(最终数据要求,IG,456)
package org.tjcj
import org.apache.spark.{SparkConf, SparkContext}
object KillTop5 {
def main(args: Array[String]): Unit = {
//1、获取SparkContext对象
val conf:SparkConf = new SparkConf().setAppName("ban5").setMaster("local[*]")
val sc:SparkContext = new SparkContext(conf)
val array = sc.textFile("hdfs://192.168.91.100:9000/javaMkdir/lol.txt").filter(!_.contains("agt")).
filter(_.contains("LCK")).map(x=>{
( x.split("\t")(9),Integer.parseInt(x.split("\t")(17))) //(team,kills)
}).reduceByKey(_+_).sortBy(_._2,false).take(5)
sc.makeRDD(array).map(x=>{
var str=""
str=x._1+","+x._2
str
}).repartition(1).saveAsTextFile("hdfs://192.168.91.100:9000/spark/out/out5")
}
}测试结果:
[root@hadoop3 ~]# hadoop fs -cat /spark/out/out5/part-00000
DRX,1367
Gen.G,1356
DAMWON Gaming,1268
T1,1231
Afreeca Freecs,1038
3.13.4 统计一下整个赛年中lpl赛区,死亡排行榜,排名前五队伍
package org.tjcj
import org.apache.spark.{SparkConf, SparkContext}
object DeathTop5 {
def main(args: Array[String]): Unit = {
//1、获取SparkContext对象
val conf:SparkConf = new SparkConf().setAppName("ban5").setMaster("local[*]")
val sc:SparkContext = new SparkContext(conf)
val array = sc.textFile("hdfs://192.168.91.100:9000/javaMkdir/lol.txt").filter(!_.contains("agt")).
filter(_.contains("LPL")).map(x=>{
( x.split("\t")(9),Integer.parseInt(x.split("\t")(18))) //(team,kills)
}).reduceByKey(_+_).sortBy(_._2,false).take(5)
sc.makeRDD(array).map(x=>{
var str=""
str=x._1+","+x._2
str
}).repartition(1).saveAsTextFile("hdfs://192.168.91.100:9000/spark/out/out6")
}
}测试:
[root@hadoop3 ~]# hadoop fs -cat /spark/out/out6/part-00000
Invictus Gaming,1317
Team WE,1271
Suning,1261
LGD Gaming,1221
Rogue Warriors,1219
3.13.5 总结
RDD:分布式弹性数据集,如何去掌握学好RDD
熟悉常用的RDD
多做练习,针对不同需求有不同解决方法
测试:
1、统计整个赛年中,lpl赛区,助攻榜排名前五
案例:
package org.tjcj
import org.apache.spark.{SparkConf, SparkContext}
/**
* lol助攻榜
*/
object AssistsTop5 {
def main(args: Array[String]): Unit = {
//1、获取SparkContext对象
val conf:SparkConf = new SparkConf().setAppName("ban5").setMaster("local[*]")
val sc:SparkContext = new SparkContext(conf)
val array = sc.textFile("hdfs://192.168.91.100:9000/javaMkdir/lol.txt").filter(!_.contains("agt")).
filter(_.contains("LPL")).map(x=>{
( x.split("\t")(9),Integer.parseInt(x.split("\t")(19))) //(team,Assists)
}).reduceByKey(_+_).sortBy(_._2,false).take(5)
sc.makeRDD(array).map(x=>{
var str=""
str=x._1+","+x._2
str
}).repartition(1).saveAsTextFile("hdfs://192.168.91.100:9000/spark/out/out7")
}
}运行结果:
package org.tjcj
import org.apache.spark.{SparkConf, SparkContext}
/**
* lol助攻榜
*/
object AssistsTop5 {
def main(args: Array[String]): Unit = {
//1、获取SparkContext对象
val conf:SparkConf = new SparkConf().setAppName("ban5").setMaster("local[*]")
val sc:SparkContext = new SparkContext(conf)
val array = sc.textFile("hdfs://192.168.91.100:9000/javaMkdir/lol.txt").filter(!_.contains("agt")).
filter(_.contains("LPL")).map(x=>{
( x.split("\t")(9),Integer.parseInt(x.split("\t")(19))) //(team,Assists)
}).reduceByKey(_+_).sortBy(_._2,false).take(5)
sc.makeRDD(array).map(x=>{
var str=""
str=x._1+","+x._2
str
}).repartition(1).saveAsTextFile("hdfs://192.168.91.100:9000/spark/out/out7")
}
}2、统计整个赛年中,拿1血胜率
案例:
package org.tjcj
import org.apache.spark.{SparkConf, SparkContext}
/**
* 拿一血的胜率
*/
object WinFirstBlood {
def main(args: Array[String]): Unit = {
//创建SparkContext对象
val conf = new SparkConf().setAppName("winFirstBlood").setMaster("local[*]")
val sc = new SparkContext(conf)
sc.textFile("hdfs://192.168.91.100:9000/javaMkdir/lol.txt").filter(!_.contains("agt"))
.map(x=>{
var splits=x.split("\t")
(Integer.parseInt(splits(16)),Integer.parseInt(splits(24)))
}).filter(x=>{
x._2==1
}).reduceByKey(_+_).map(x=>{
var d:Double=x._2
("win",d)
}).reduceByKey(_/_).map(x=>{
(x._1,x._2.formatted("%.2f"))
}).repartition(1).saveAsTextFile("hdfs://192.168.91.100:9000/spark/out/out9")
}
}运行结果:
[root@hadoop1 ~]# hadoop fs -cat /spark/out/out8/part-00000
(win,0.58)
3、统计整个赛年中,胜率超过60%队伍,以及胜率
package org.tjcj
import org.apache.spark.{SparkConf, SparkContext}
/**
* 整个赛年中胜率超过60%
*/
object WinSpark {
def main(args: Array[String]): Unit = {
//创建SparkContext对象
val conf = new SparkConf().setAppName("winFirstBlood").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd= sc.textFile("hdfs://192.168.91.100:9000/javaMkdir/lol.txt").filter(!_.contains("agt"))
val rdd1= rdd.map(x=>{
var splits =x.split("\t")
(splits(9),Integer.parseInt(splits(16)))
}).reduceByKey(_+_)
val rdd2 = rdd.map(x=>{
var splits =x.split("\t")
(splits(9),1)
}).reduceByKey(_+_)
rdd1.union(rdd2).reduceByKey((x1,x2)=>{
var win:Int=0;
if(x1<x2){
win = x1*100/x2
}
win
}).filter(_._2>60).map(x=>(x._1,x._2+"%"))
.repartition(1).saveAsTextFile("hdfs://192.168.91.100:9000/spark/out/out11")
}
}运行:
[root@hadoop1 ~]# hadoop fs -cat /spark/out/out11/part-00000
(Invictus Gaming,61%)
(DRX,64%)
(JD Gaming,70%)
(DAMWON Gaming,67%)
(T1,67%)
(Gen.G,69%)
(Top Esports,67%)
3.14 Spark中Spark-sql应用
3.14.1 Spark-sql的基础用法
搭建Spark-sql开发环境
<!--引入spark-sql依赖-->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.1.1</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.11</artifactId>
<version>2.1.1</version>
</dependency>案例:
package org.tjcj.sql
import org.apache.spark.sql.SparkSession
/**
*
*/
object MyFirstSparkSql {
def main(args: Array[String]): Unit = {
//创建SparkSession对象
val spark = SparkSession.builder().appName("myFirstSparkSession").master("local[*]").getOrCreate()
val df = spark.read.json("D:\\spark-sql\\person.json")
df.show()
}
}
可以读取JSON格式的文件,进行展示
Spark-sql的基础用法:
package org.tjcj.sql
import org.apache.spark.sql.SparkSession
/**
*
*/
object MyFirstSparkSql {
def main(args: Array[String]): Unit = {
//创建SparkSession对象
val spark = SparkSession.builder().appName("myFirstSparkSession").master("local[*]").getOrCreate()
val df = spark.read.json("D:\\spark-sql\\people.json")
df.show()
//打印二维表的格式
df.printSchema()
//类似于sql语句格式进行查询数据
df.select("name","age").show()
//引入scala,隐式转换
import spark.implicits._
//让字段进行运算
df.select($"name",$"age"+1).show()
//加上条件
df.select("name").where("age>20").show()
//进行分组统计
df.groupBy("age").count().show()
//创建一个临时表
df.createOrReplaceTempView("people")
spark.sql("select age,count(*) as count1 from people group by age").show()
//关闭spark
spark.stop()
}
}3.14.2 Spark-sql中read
package org.tjcj.sql
import org.apache.spark.sql.SparkSession
/**
* 读取不同类型的文件
*/
object SparkRead {
def main(args: Array[String]): Unit = {
//构建SparkSession对象
val spark = SparkSession.builder().appName("sparkRead").master("local[*]").getOrCreate()
//读取json文件
val df = spark.read.json("D:\\spark-sql\\employees.json")
df.show()
df.printSchema()
//读取csv文件
val df1= spark.read.csv("D:\\spark-sql\\lol.csv")
df1.show()
df1.printSchema()
//读取普通文本文件
val df2=spark.read.text("D:\\spark-sql\\student.txt")
df2.show()
df2.printSchema()
//读取orc
//读取
val df4 =spark.read.parquet("D:\\spark-sql\\users.parquet")
df4.show()
df4.printSchema()
}
}
3.14.3 Spark-sql中的写
package org.tjcj.sql
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{Dataset, Row, SparkSession}
import org.apache.spark.sql.types.{DataTypes, StructField, StructType}
object SparkWrite {
def main(args: Array[String]): Unit = {
val spark=SparkSession.builder().appName("write").appName("write").master("local[*]").getOrCreate()
spark.sql("set spark.sql.adaptive.enabled=true")
val rdd:RDD[Row]= spark.sparkContext.parallelize(List(
Row(1,"张三","大四",18),
Row(1,"李四","大四",19),
Row(1,"王五","大四",20),
Row(1,"赵六","大四",21),
Row(1,"刘七","大四",22)
))
val schema=StructType(List(
StructField("id",DataTypes.IntegerType,false),
StructField("name",DataTypes.StringType,false),
StructField("grade",DataTypes.StringType,false),
StructField("age",DataTypes.IntegerType,false)
))
val df = spark.createDataFrame(rdd,schema)
df.show()
df.printSchema()
df.repartition(1).write.json("D:\\spark-sql\\out\\out3")
import spark.implicits._
val ds:Dataset[Student]= spark.createDataset(List(
Student(1,"张三","大四",18),
Student(1,"李四","大四",19),
Student(1,"王五","大四",20),
Student(1,"赵六","大四",21),
Student(1,"刘七","大四",22)
))
ds.show()
ds.printSchema()
ds.repartition(1).write.csv("D:\\spark-sql\\out\\out4")
}
}
case class Student(id:Int,name:String,grade:String,age:Int)3.15 图表可视化
基于大数据处理的数据,基本上都是文件的格式-----需要使用图表化的工具进行展示
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>电影</title>
<style>
#main{
width: 1500px;
/*自适应的高度*/
height: 100vh;
margin: 0px auto;
padding: 0px;
}
#one{
width: 700px;
height: 50vh;
float: left;
}
#two{
width: 700px;
height: 50vh;
float: right;
}
#three{
width: 700px;
height: 50vh;
float: left;
}
#four{
width: 700px;
height: 50vh;
float: right;
}
</style>
</head>
<body>
<div id="main">
<div id="one"></div>
<div id="two"></div>
<div id="three"></div>
<div id="four"></div>
</div>
</body>
<!--引入外部的js文件-->
<script src="../js/jquery.min.js"></script>
<script src="../js/echarts-all.js"></script>
<!--编写javascript代码引用json文件-->
<script>
$(function(){
$.ajax({ //统计各个国家排电影的总数
url:"../data/part-00000-6aee901d-e3d1-4e45-8ced-26e24edadb88.json",
type:"get",
dataType:"json",
success:function(res){
let x=[]
let y=[]
for (let i=0;i<res.length;i++){
x.push(res[i].address)
y.push(res[i].count)
}
//1、初始化echats
let myEcharts = echarts.init(document.getElementById("one"))
// 2、设置option选项值
let option = {
title : {
text: '统计各个国家拍电影总数排行榜',
subtext: '豆瓣'
},
tooltip : {
trigger: 'axis'
},
legend: {
data:['电影数据']
},
calculable : true,
xAxis : [
{
type : 'category',
boundaryGap : false,
data : x
}
],
yAxis : [
{
type : 'value',
axisLabel : {
formatter: '{value} 部'
},
splitArea : {show : true}
}
],
series : [
{
name:'电影数据',
type:'line',
itemStyle: {
normal: {
lineStyle: {
shadowColor : 'rgba(0,0,0,0.4)'
}
}
},
data:y
}
]
};
// 3、加载Option选项
myEcharts.setOption(option)
}
})
$.ajax({ //导演的拍电影的总数
url:"../data/part-00000-256eb3a7-952f-49ee-befe-9cc3952d7d17.json",
type:"get",
dataType:"json",
success:function(res){
let x=[]
let y=[]
for (let i=0;i<res.length;i++){
x.push(res[i].direct)
y.push(res[i].count)
}
//1、初始化echats
let myEcharts = echarts.init(document.getElementById("two"))
// 2、设置option选项值
let option = {
title : {
text: '导演的拍电影排行榜',
subtext: '豆瓣'
},
tooltip : {
trigger: 'axis'
},
legend: {
data:['电影数据']
},
toolbox: {
show : true,
feature : {
mark : true,
dataView : {readOnly: false},
magicType:['line', 'bar'],
restore : true,
saveAsImage : true
}
},
calculable : true,
xAxis : [
{
type : 'category',
data : x
}
],
yAxis : [
{
type : 'value',
splitArea : {show : true}
}
],
series : [
{
name:'电影数据',
type:'bar',
data:y
}
]
};
// 3、加载Option选项
myEcharts.setOption(option)
}
})
$.ajax({ //统计各个国家排电影的总数
url:"../data/part-00000-419034d2-3312-487c-a467-d426debeb2ef.json",
type:"get",
dataType:"json",
success:function(res){
let x=[]
let y=[]
for (let i=0;i<res.length;i++){
x.push(res[i].movieName)
y.push(res[i].grade)
}
//1、初始化echats
let myEcharts = echarts.init(document.getElementById("three"))
// 2、设置option选项值
let option = {
title : {
text: '评分排行榜',
subtext: '豆瓣'
},
tooltip : {
trigger: 'axis'
},
legend: {
data:['电影数据']
},
calculable : true,
xAxis : [
{
type : 'category',
boundaryGap : false,
data : x
}
],
yAxis : [
{
type : 'value',
axisLabel : {
formatter: '{value} 分'
},
splitArea : {show : true}
}
],
series : [
{
name:'电影数据',
type:'line',
itemStyle: {
normal: {
lineStyle: {
shadowColor : 'rgba(0,0,0,0.4)'
}
}
},
data:y
}
]
};
// 3、加载Option选项
myEcharts.setOption(option)
}
})
$.ajax({ //统计各个国家排电影的总数
url:"../data/part-00000-d06a0328-f4be-408c-b050-231c1f17a2b9.json",
type:"get",
dataType:"json",
success:function(res){
let x=[]
let y=[]
for (let i=0;i<res.length;i++){
x.push(res[i].movieName)
y.push({"value":res[i].count,"name":res[i].movieName})
}
//1、初始化echats
let myEcharts = echarts.init(document.getElementById("four"))
// 2、设置option选项值
let option = {
title : {
text: '上映率',
subtext: '豆瓣',
x:'center'
},
tooltip : {
trigger: 'item',
formatter: "{a} <br/>{b} : {c} ({d}%)"
},
legend: {
orient : 'vertical',
x : 'left',
data:x
},
toolbox: {
show : true,
feature : {
mark : true,
dataView : {readOnly: false},
restore : true,
saveAsImage : true
}
},
calculable : true,
series : [
{
name:'观影次数',
type:'pie',
radius : '55%',
center: ['50%', 225],
data:y
}
]
};
// 3、加载Option选项
myEcharts.setOption(option)
}
})
})
</script>
</html> 四、项目实战
4.1 项目文件分析
需求:
读取两个csv文件,并且输出内容以及,schema(二维表结构)
package org.tjcj.sql
import org.apache.spark.sql.SparkSession
/**
* 统计电影的文件情况
*/
object MoviesSpark {
def main(args: Array[String]): Unit = {
//获取SparkSession对象
val spark =SparkSession.builder().appName("movie").master("local[*]").getOrCreate()
val df1=spark.read.option("header",true).csv("D:\\data\\input\\movie.csv")
df1.show(10)
df1.printSchema()
val df2=spark.read.option("header",true).csv("D:\\data\\input\\user.csv")
df2.show(10)
df2.printSchema()
}
}4.2 统计一下观影次数排名前十的电影名称和观影次数
通过分析:
得出结论,只通过user一个表就可以统计出电影名称以及其观影次数
package org.tjcj.sql
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.functions.desc
/**
* 统计观影次数最多的5部电影
*/
object MoviesTop5 {
def main(args: Array[String]): Unit = {
//获取SparkSession对象
val spark =SparkSession.builder().appName("movie").master("local[*]").getOrCreate()
val df=spark.read.option("header",true).csv("D:\\data\\input\\user.csv")
//方式一:采用spark-sql提供df方法操作
import spark.implicits._
df.select($"movieName").groupBy($"movieName").count().orderBy(desc("count")).show(5)
df.select($"movieName").groupBy($"movieName").count().orderBy($"count".desc).show(5)
//方式二:利用hive的sql方式
df.createOrReplaceTempView("user")
spark.sql("select movieName,count(*) as count from user group by movieName order by count desc").show(5)
}
}写出到文件中:
package org.tjcj.sql
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.functions.{array, desc}
/**
* 统计观影次数最多的10部电影
*/
object MoviesTop5 {
def main(args: Array[String]): Unit = {
//获取SparkSession对象
val spark =SparkSession.builder().appName("movie").master("local[*]").getOrCreate()
val df=spark.read.option("header",true).csv("D:\\data\\input\\user.csv")
//方式一:采用spark-sql提供df方法操作
import spark.implicits._
df.select($"movieName").groupBy($"movieName").count().orderBy(desc("count")).show(5)
df.select($"movieName").groupBy($"movieName").count().orderBy($"count".desc).limit(10).repartition(1)
.write.csv("D:\\spark-sql\\out\\out5")
//方式二:利用hive的sql方式
df.createOrReplaceTempView("user")
spark.sql("select movieName,count(*) as count from user group by movieName order by count desc").limit(10).repartition(1)
.write.json("D:\\spark-sql\\out\\out6")
}
}4.3 统计一下评分排名前10的电影名称和评分
分析:只需要movie.csv文件
package org.tjcj.sql
import org.apache.spark.sql.SparkSession
/**
* 统计电影的文件情况
*/
object GradeTop10 {
def main(args: Array[String]): Unit = {
//获取SparkSession对象
val spark =SparkSession.builder().appName("movie").master("local[*]").getOrCreate()
val df=spark.read.option("header",true).csv("D:\\data\\input\\movie.csv").distinct()
//采用sql方式实现
//创建临时表
df.createOrReplaceTempView("movie")
spark.sql("select distinct(movieName),grade from movie where grade >8 order by grade desc").limit(10)
.write.json("D:\\spark-sql\\out\\out8")
//关闭spark session对象
spark.stop()
}
}4.4 验证单表效果
统计剧情类型电影中评分最高10部电影
package org.tjcj.sql
import org.apache.spark.sql.SparkSession
/**
* 统计剧情类型的电影排行榜
*/
object JqTop10 {
def main(args: Array[String]): Unit = {
//获取SparkSession对象
val spark =SparkSession.builder().appName("movie").master("local[*]").getOrCreate()
val df=spark.read.option("header",true).csv("D:\\data\\input\\movie.csv").distinct()
//采用sql方式实现
//创建临时表
df.createOrReplaceTempView("movie")
spark.sql("select distinct(movieName),grade from movie where grade >8 and type='剧情' order by grade desc").limit(10)
.write.json("D:\\spark-sql\\out\\out9")
//关闭spark session对象
spark.stop()
}
}
统计各个国家电影数量排名前十电影
package org.tjcj.sql
import org.apache.spark.sql.SparkSession
/**
* 各个国家数据量
*/
object CountTop10 {
def main(args: Array[String]): Unit = {
//获取SparkSession对象
val spark =SparkSession.builder().appName("movie").master("local[*]").getOrCreate()
val df=spark.read.option("header",true).csv("D:\\data\\input\\movie.csv")
df.createOrReplaceTempView("movie")
spark.sql("select address,count(*) as count from movie group by address order by count desc").limit(10)
.write.json("D:\\spark-sql\\out\\out10")
spark.stop()
}
}4.5 统计近年来那些导演拍的电影多(TOPN榜)
package org.tjcj.sql
import org.apache.spark.sql.SparkSession
/**
* 近年来那些导演拍的电影较多
*/
object DirectTop10 {
def main(args: Array[String]): Unit = {
//1、获取SparkSession对象
val spark = SparkSession.builder().appName("directTop10").master("local[*]").getOrCreate()
//2、获取要处理的文件
val df = spark.read.option("header",true).csv("D:\\data\\input\\movie.csv").distinct()
//方式一:采用spark-sql中方言方式
import spark.implicits._
df.repartition(1).select("direct").groupBy("direct").count().orderBy($"count".desc).limit(10)
.write.json("D:\\spark-sql\\out\\out11")
//方式二:采用hive-sql的方式
df.createOrReplaceTempView("movie")
spark.sql("select direct,count(*) as count from movie group by direct order by count desc").limit(10).repartition(1)
.write.json("D:\\spark-sql\\out\\out12")
}
}4.6 统计评分高于9.0,受欢迎的电影以及观影次数,排行榜
package org.tjcj.sql
import org.apache.spark.sql.SparkSession
/**
* 统计电影的文件情况
*/
object MoviesGrade {
def main(args: Array[String]): Unit = {
//获取SparkSession对象
val spark =SparkSession.builder().appName("movie").master("local[*]").getOrCreate()
val df1=spark.read.option("header",true).csv("D:\\spark-sql\\movie.csv")
val df2=spark.read.option("header",true).csv("D:\\spark-sql\\user.csv")
//创建临时表
df1.createOrReplaceTempView("movie")
df2.createOrReplaceTempView("user")
spark.sql("select m.movieName,count(*) as count from movie m left join user u on m.movieName = u.movieName " +
"where m.grade >9.0 group by m.movieName order by count desc").limit(10).repartition(1)
.write.json("D:\\spark-sql\\out\\out13")
}
}运行结果:
{"movieName":"疯狂动物城","count":208}
{"movieName":"阿甘正传","count":190}
{"movieName":"美丽人生","count":126}
{"movieName":"三傻大闹宝莱坞","count":126}
{"movieName":"窃听风暴","count":120}
{"movieName":"指环王3:王者无敌","count":120}
{"movieName":"教父","count":120}
{"movieName":"乱世佳人","count":120}
{"movieName":"辛德勒的名单","count":117}
{"movieName":"这个杀手不太冷","count":112}
4.7 统计评分高于9.0,且时间在1月份,电影名称和电影评分,排行榜
package org.tjcj.sql
import org.apache.spark.sql.SparkSession
/**
* 统计电影的文件情况
*/
object GradeMovie {
def main(args: Array[String]): Unit = {
//获取SparkSession对象
val spark =SparkSession.builder().appName("movie").master("local[*]").getOrCreate()
val df1=spark.read.option("header",true).csv("D:\\spark-sql\\movie.csv").distinct()
val df2=spark.read.option("header",true).csv("D:\\spark-sql\\user.csv").distinct()
//创建临时表
df1.createOrReplaceTempView("movie")
df2.createOrReplaceTempView("user")
spark.sql("select m.movieName,m.grade,count(*) as count from movie m left join user u on m.movieName = u.movieName " +
"where m.grade >9.0 and substr(u.time,0,7) = '2018-01' group by m.movieName,m.grade order by count desc").limit(10)
.repartition(1)
.write.json("D:\\spark-sql\\out\\out14")
}
}
4.8 总结和回顾
在Spark中,spark-sql和spark-core之间可以进行相互转换的
RDD和DateFrame,RDD和DataSet是可以进行相互转换的
package org.tjcj.sql
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{Dataset, Row, SparkSession}
import org.apache.spark.sql.types.{DataTypes, StructField, StructType}
object SparkWrite {
def main(args: Array[String]): Unit = {
val spark=SparkSession.builder().appName("write").appName("write").master("local[*]").getOrCreate()
spark.sql("set spark.sql.adaptive.enabled=true")
val rdd:RDD[Row]= spark.sparkContext.parallelize(List(
Row(1,"张三","大四",18),
Row(1,"李四","大四",19),
Row(1,"王五","大四",20),
Row(1,"赵六","大四",21),
Row(1,"刘七","大四",22)
))
val schema=StructType(List(
StructField("id",DataTypes.IntegerType,false),
StructField("name",DataTypes.StringType,false),
StructField("grade",DataTypes.StringType,false),
StructField("age",DataTypes.IntegerType,false)
))
val df = spark.createDataFrame(rdd,schema)
df.show()
df.printSchema()
df.repartition(1).write.json("D:\\spark-sql\\out\\out3")
import spark.implicits._
val ds:Dataset[Student]= spark.createDataset(List(
Student(1,"张三","大四",18),
Student(1,"李四","大四",19),
Student(1,"王五","大四",20),
Student(1,"赵六","大四",21),
Student(1,"刘七","大四",22)
))
ds.show()
ds.printSchema()
ds.repartition(1).write.csv("D:\\spark-sql\\out\\out4")
}
}case class Student(id:Int,name:String,grade:String,age:Int)
样例类----自动生成set、get方法以及构造方法
DataFrame和DataSet区别不大,DataSet是有格式的
执行Sql两种方式:
利用Spark-sql,独有方言进行计算
package org.tjcj.sql
import org.apache.spark.sql.SparkSession
/**
* 近年来那些导演拍的电影较多
*/
object DirectTop10 {
def main(args: Array[String]): Unit = {
//1、获取SparkSession对象
val spark = SparkSession.builder().appName("directTop10").master("local[*]").getOrCreate()
//2、获取要处理的文件
val df = spark.read.option("header",true).csv("D:\\data\\input\\movie.csv").distinct()
//方式一:采用spark-sql中方言方式
import spark.implicits._
df.repartition(1).select("direct").groupBy("direct").count().orderBy($"count".desc).limit(10)
.write.json("D:\\spark-sql\\out\\out11")
//方式二:采用hive-sql的方式
df.createOrReplaceTempView("movie")
spark.sql("select direct,count(*) as count from movie group by direct order by count desc").limit(10).repartition(1)
.write.json("D:\\spark-sql\\out\\out12")
}
}方式二:通常比较常用的一种,编写sql语句直接使用,总体来说,Spark-sql更加便于开发。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









