










先给个模板练习题(毒瘤bushi):P3379 【模板】最近公共祖先(LCA) - 洛谷 | 计算机科学教育新生态 (luogu.com.cn)![]() https://www.luogu.com.cn/problem/P3379
https://www.luogu.com.cn/problem/P3379
对于有根树T的两个结点u、v,最近公共祖先LCA(T,u,v)表示一个结点x,满足x是u和v的祖先且x的深度尽可能大。在这里,一个节点也可以是它自己的祖先。 通俗来讲,就是两个点的公共祖先中,离他们最近的那一个。
求解公共祖先分两步:
第一步求出每一个结点的父结点:
public static void dfs(int now,int fath){
fa[now] = fath; //记录父节点
depth[now] = depth[fath] + 1; //记录当前结点的深度:父节点+1
for(int i=he[now];i>0;i=to[i]) { //链式前向星遍历
if(vv[i] == fath) continue; //如果下一个结点是父亲,continue,不然死循环
dfs(vv[i],now); //进入下一个结点
}
}第二步求两个点的最近公共祖先:
//这段代码很好理解
public static int lca(int x,int y){
while(x != y) {
if(depth[x] >= depth[y])
x = fa[x];
else
y = fa[y];
}
return x;
}用上面这个朴素方法的完整代码:
import java.io.*;
import java.util.*;
public class Main {
static int maxn=500001; // also maxm
static int n,m,s,cnt;
static int[] vv=new int[maxn<<1],to=new int[maxn<<1],he=new int[maxn];
static int[] depth=new int[maxn],fa = new int[maxn];
public static void main(String[] args) throws IOException {
n=nextInt();m=nextInt();s=nextInt();
for(int i=1;i<n;i++){
int x=nextInt(),y=nextInt();
addEdge(x,y);
addEdge(y,x);
}
dfs(s,0);
for(int i=1;i<=m;i++){
int ans = lca(nextInt(), nextInt());
out.println(ans);
}
out.flush();
}
public static void dfs(int now,int fath){
fa[now] = fath;
depth[now] = depth[fath] + 1;
for(int i=he[now];i>0;i=to[i]) {
if(vv[i] == fath) continue;
dfs(vv[i],now);
}
}
public static int lca(int x,int y){
while(x != y) {
if(depth[x] >= depth[y])
x = fa[x];
else
y = fa[y];
}
return x;
}
public static void addEdge(int u,int v){
vv[++cnt]=v;
to[cnt]=he[u];
he[u]=cnt;
}
static StreamTokenizer in = new StreamTokenizer(new BufferedReader(new InputStreamReader(System.in)));
static PrintWriter out = new PrintWriter(new BufferedWriter(new OutputStreamWriter(System.out)));
static int nextInt() throws IOException {
in.nextToken();
return (int)in.nval;
}
}
提交后发现AC了,但没完全AC。
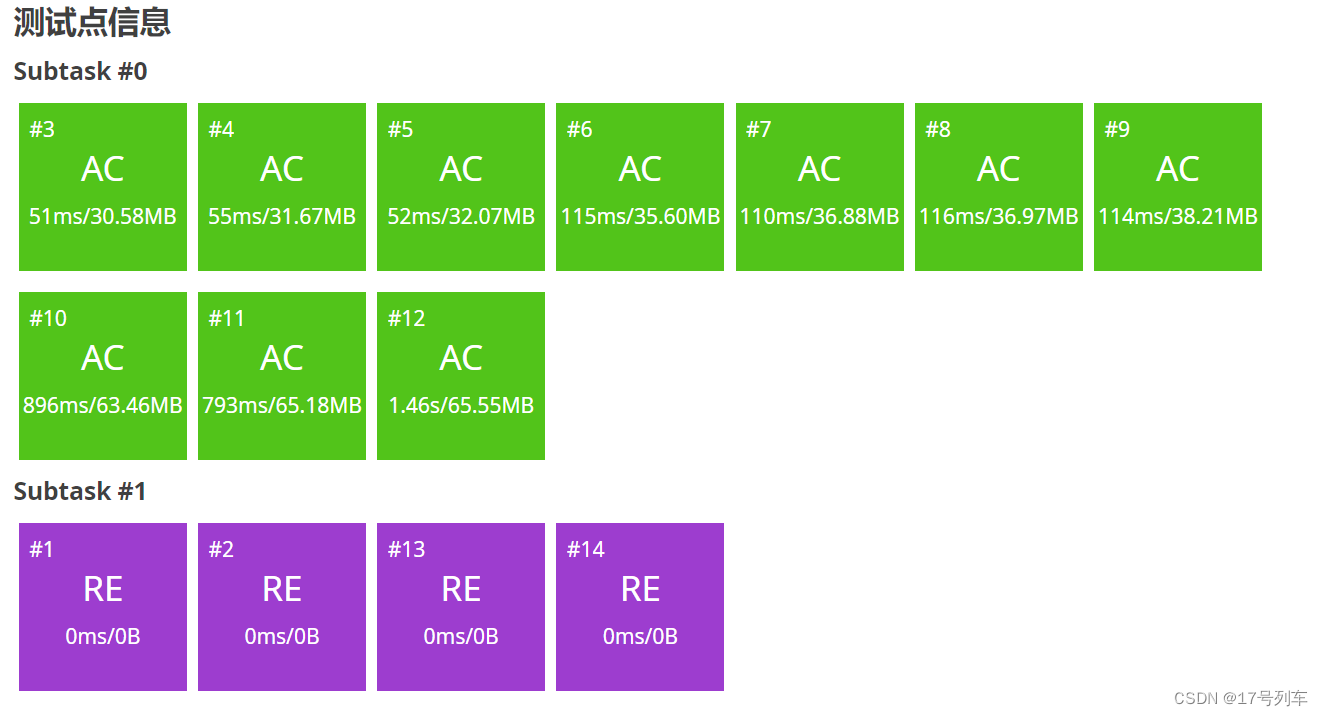
这是因为有毒瘤数据
499991 499993 416512 (n=499991, m=499993, s=416512)
314198 370928
125536 16538
277186 393869
171949 454871
160874 411546 ......
好家伙,这么大的数据,这一组数据就是故意来卡暴力求解的,看来我们得在基础模板上加一些优化,这时候倍增优化就来了。
我们先预处理求解,模拟下面这段代码可以得到
,也就是说,lg[ i ] - 1 =
,这个lg[ i ]在倍增中可以用来确定高度和索引之间的关系。我们定义int[][] fa = new int[maxn][maxn] , 不同于基础模板的int[] fa = new int[maxn],倍增优化使用二维数组,多出来的一维存放
,以便lca的时候可以利用倍增快速找祖宗。
for(int i=1;i<=n;i++)
lg[i]=lg[i-1]+(1<<lg[i-1]==i?1:0);还有个地方理解起来比较难:
for(int i=1;i<=lg[depth[now]];i++)
fa[now][i]=fa[fa[now][i-1]][i-1]; fa[now][i]=fa[fa[now][i-1]][i-1]可以理解为:now结点的第 的父亲 相当于 第
个父亲的第
的父亲,即
上模板:
import java.io.*;
import java.util.*;
public class Main {
static int maxn=500001; // n和m的可能最大值
static int n,m,s,cnt;
static int[] vv=new int[maxn<<1],to=new int[maxn<<1],he=new int[maxn<<1];
static int[] lg=new int[maxn],depth=new int[maxn];
static int[][] fa = new int[maxn][22];
public static void main(String[] args) throws IOException {
n=nextInt();m=nextInt();s=nextInt();
for(int i=1;i<=n;i++)
lg[i]=lg[i-1]+(1<<lg[i-1]==i?1:0);
for(int i=1;i<n;i++){
int x=nextInt(),y=nextInt();
addEdge(x,y);
addEdge(y,x);
}
dfs(s,0);
for(int i=1;i<=m;i++){
int x=nextInt(),y=nextInt();
int ans=lca(x,y);
out.println(ans);
}
out.flush();
}
public static void dfs(int now,int fath){
fa[now][0]=fath;depth[now]=depth[fath]+1; //这一行和基础模板大差不差
for(int i=1;i<=lg[depth[now]];i++) //解释过了
fa[now][i]=fa[fa[now][i-1]][i-1];
for(int i=he[now];i>0;i=to[i])
if(vv[i]!=fath) dfs(vv[i],now);
}
public static int lca(int x,int y){
if(depth[x]<depth[y]) {int tmp=x;x=y;y=tmp;} //保证x的深度大于或等于y的深度
while(depth[x]>depth[y])
x=fa[x][lg[depth[x]-depth[y]]-1]; //让x和y的深度一样
if(x==y) return x;
for(int k=lg[depth[x]]-1;k>=0;k--) //这里x和y已经在同一个深度,那么一起网上倍增跳
if(fa[x][k]!=fa[y][k]){ //也可以说指数爆炸式地跳
x=fa[x][k];y=fa[y][k];
}
return fa[x][0];
}
//使用链式前向星
public static void addEdge(int u,int v){
vv[++cnt]=v;
to[cnt]=he[u];
he[u]=cnt;
}
//魔法快读
static StreamTokenizer in = new StreamTokenizer(new BufferedReader(new InputStreamReader(System.in)));
static PrintWriter out = new PrintWriter(new BufferedWriter(new OutputStreamWriter(System.out)));
static int nextInt() throws IOException {
in.nextToken();
return (int)in.nval;
}
}
















 162
162











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











