






论文题目:The Elephant in the Room: Rethinking the Usage of Pre-trained Language Model in Sequential Recommendation
代码链接:https://github.com/777pomingzi/Rethinking-PLM-in-RS
摘要:
我们发现预训练语言模型在序列推荐的行为序列建模中存在参数冗余和低效的问题。因此我们通过提出一种轻量化的预训练语言模型使用方法,将经过行为微调的预训练语言模型应用于传统基于物品 ID 的序列推荐模型的物品嵌入初始化中,实验结果表明该方法在无需增加推理成本的条件下即可显著提升模型性能。
一、背景和动机
近年来,由于预训练语言模型在自然语言处理领域取得的巨大进展,研究者开始考虑将其有效地应用于序列推荐中,一些研究希望利用其包含的丰富先验知识编码物品文本以增强物品表征,另一些研究则希望利用大语言模型的序列建模能力提升推荐效果。然而,由于文本和行为建模之间存在着巨大的差异,这些基于预训练语言模型的方法仅在冷启动场景下表现较好,在用户行为信息充足时效果欠佳。同时,尽管有部分研究已经探究了预训练语言模型在物品表征学习中的作用,其在行为序列建模中的影响却仍未得到充分的研究。 因此,我们希望回答以下的两个问题:
(1) 预训练语言模型在序列推荐的行为序列建模中是否能够被充分且高效地利用;
(2) 是否存在更加有效且经济的方式将预训练语言模型应用于序列推荐。通过针对 SOTA 模型 RECFORMER 的相关实验,我们发现:预训练语言模型在行为序列建模中存在明显的功能分层和参数冗余现象,仅微调其中 1/4 的模型参数层即可达到或超过原模型性能。基于该发现,我们提出了一种轻量化使用预训练语言模型的框架,使用简单的基于物品 ID 的序列推荐模型进行行为建模,并采用经过用户行为微调的预训练语言模型进行物品嵌入初始化,在保持推理效率的情况下显著提升模型推荐效果。
二、基于预训练语言模型的序列推荐模型的序列建模分析-以 RECFORMER 为例
1.RECFORMER介绍
RECFORMER是一个基于PLM的SR模型。模型基于双向Transformer结构Longformer进行对item和用户历史行为序列文本进行编码,通过在其对应文本表示前加入特殊 T𝑜𝑘𝑒𝑛[𝐶𝐿𝑆] ,将该文本经过模型后得到的 ℎ[𝐶𝐿𝑆] 作为item/user历史行为的表示。
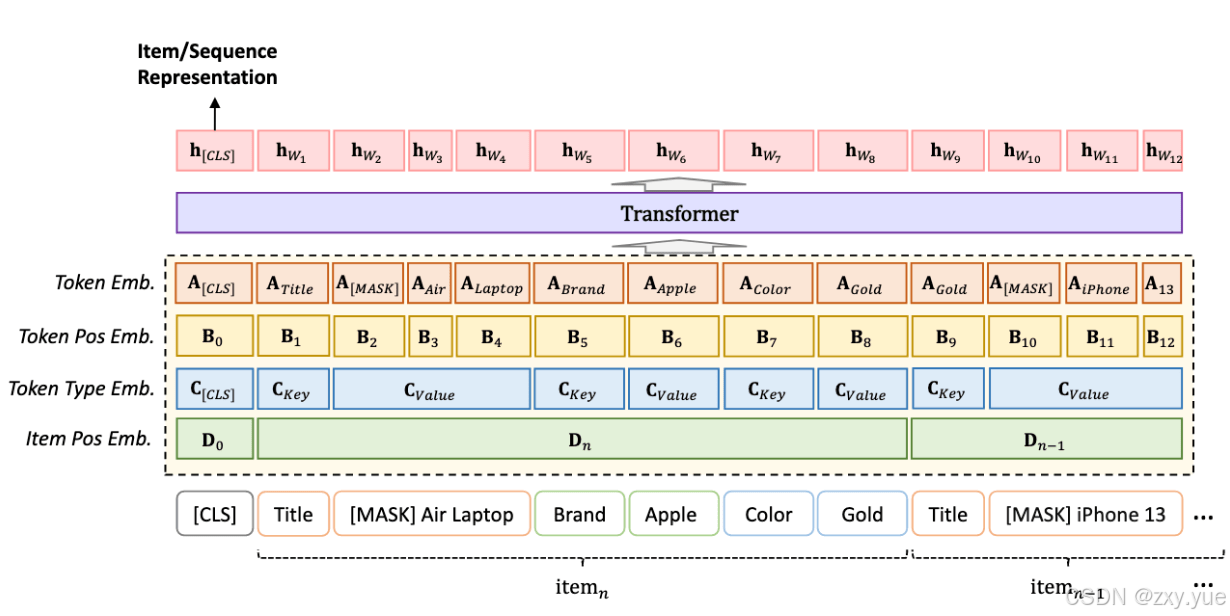
Recformer训练过程包括预训练和两步微调:
预训练
掩蔽语言建模(MLM)
该任务随机遮盖某个word,要求模型预测出被遮盖的word。该任务能够防止语言模型在与其他特定任务联合训练的时候忘记单词语义。借助MLM任务,能够消除通用语言语料库和item文本之间的差距。
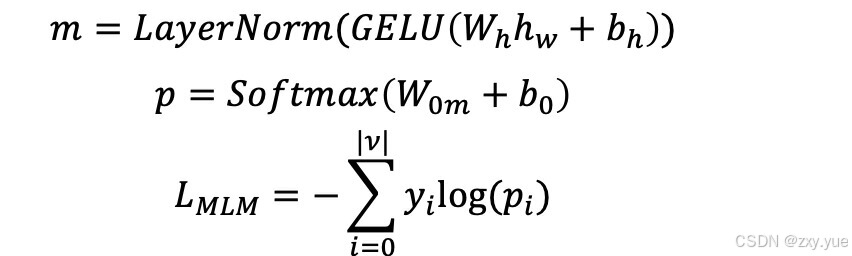
item-item对比(IIC)任务
该任务的目标是对于正样本item,要让模型提高user的打分,对于负样本,则尽可能让模型降低user的打分。正样本就是训练数据中的ground-truth,负样本把同一个batch内的其他item作为负例。
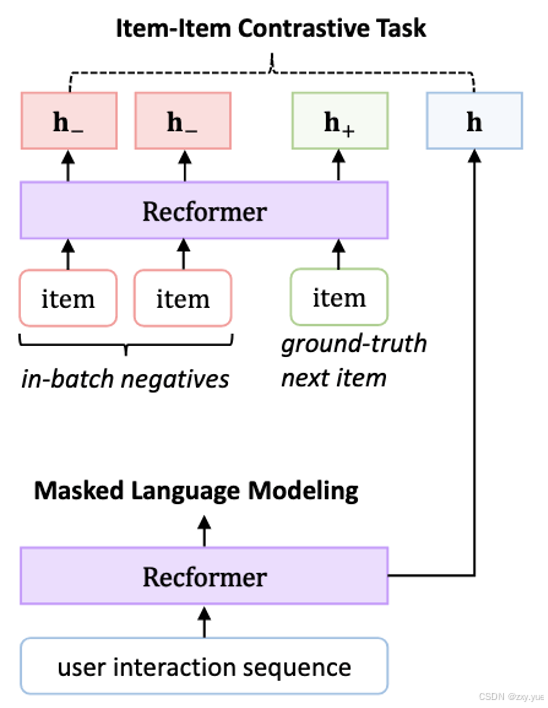
微调
第一阶段,更新I,也更新模型的参数M。这里,为了高效训练,不会每个batch重新encode item的内容,从而获得item的表示。而是每个epoch,encode所有的item,然后保存在I中,方便接下来训练的使用。
第二阶段,冻结I,更新模型参数M。这一阶段和第一阶段的不同主要体现在不会再更新item的表示table I了,而是只更新模型的参数,以通过稳定的训练达到最优的结果。【阶段一获得商品最优表征,阶段二更新模型参数,获得最佳序列建模】本文进行改进,可以使得整体优化到最优。

2.注意力差异分析
为了探究基于预训练语言模型的序列推荐模型在进行用户行为序列建模时的具体机制,我们选择了 RECFORMER 作为进行观察的模型。RECFORMER 基于双向 Transformer 架构的 Longformer 对物品和用户历史行为序列文本进行编码,得到其对应的物品表征以进行推荐。RECFORMER 的训练过程包含两阶段,第一阶段模型的序列建模部分和物品嵌入部分同时被优化(在每一个 epoch 开始时使用模型重新编码全部物品更新物品嵌入),第二阶段仅更新序列建模部分,保持物品嵌入冻结。其整体训练流程可以看作在第一阶段获得物品最优表征嵌入,第二阶段获得最佳序列建模模型。因此,我们选择观察完成第二阶段微调后的RECFORMER 中的注意力表示,以探究预训练语言模型在序列推荐任务中的具体运行机制。
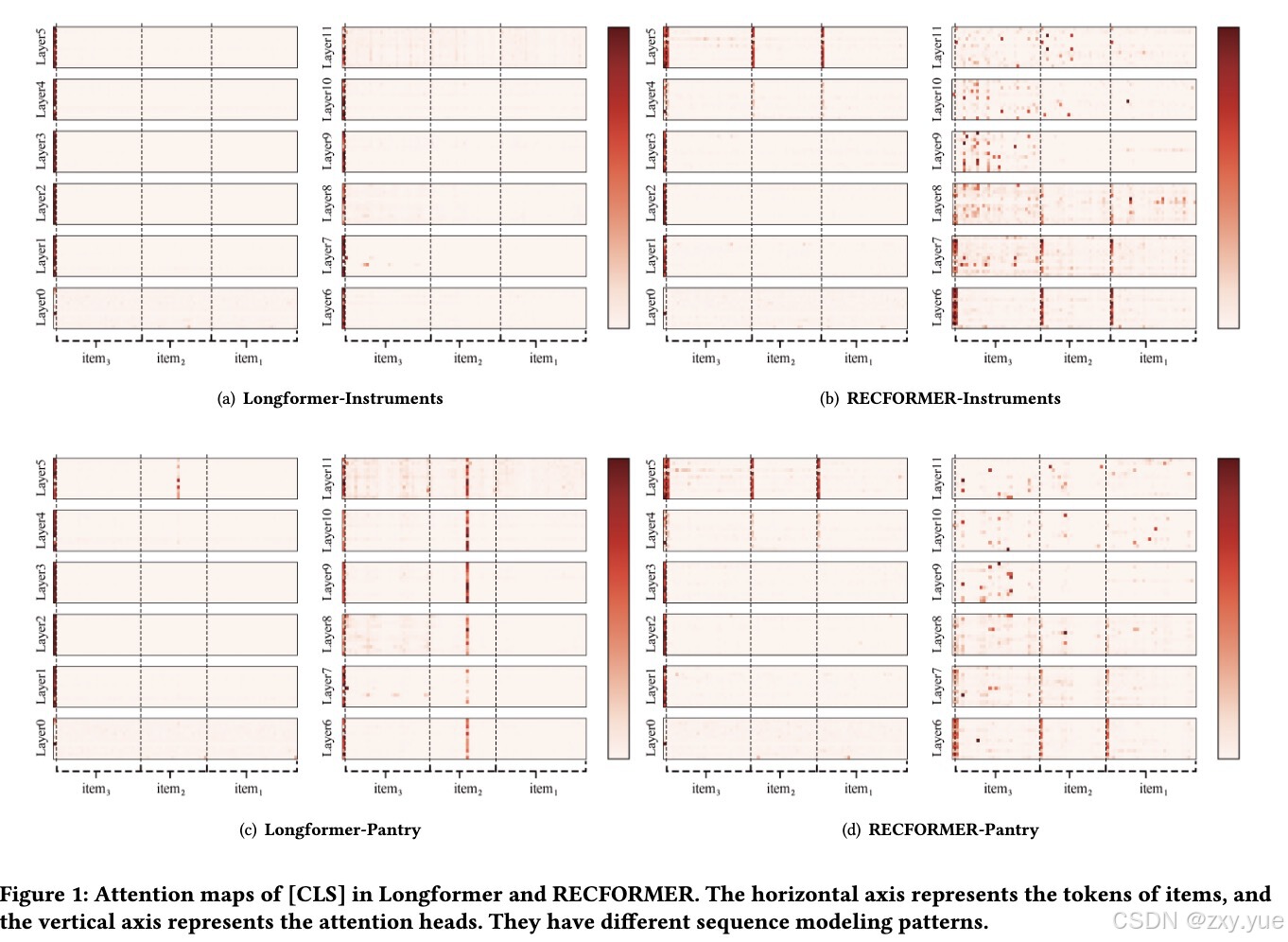
我们给出了Longformer 和完成两阶段微调的RECFORMER在Instruments和Pantry
数据集上的注意力图,从图中我们可以得到以下的四点观察:
(1)RECFORMER的注意力分布表现出明显的分层现象,注意力分布在特定层级范围内(如 0-3 层、4-7 层、8-11 层)表现出相似性。
(2)RECFORMER 的 4-7 层注意力主要集中在每个物品的首个 token,该现象表明这些层正在执行建模物品边界的功能。 物品的首个 token 在浅层主要关注物品内部 token,这与基于物品 ID 的序列推荐模型中的物品嵌入生成过程相似。
(3)在 8-11 层,RECFORMER 中的注意力开始关注每个物品中的关键 token,同时表现出类似于基于物品 ID 的序列推荐模型的模式,更多地聚焦于最近交互的物品。
(4)在某些 RECFORMER 的层和注意力头中,注意力分布几乎相同,该现象表明基于预训练语言模型的序列推荐模型可能存在显著的参数冗余。同时,这些现象在 Longformer 中并没有被观察到, 说明原始的语言模型并不具有良好地处理用户行为信息的能力,需要通过在行为数据上的微调使其具备该能力。
为了进一步验证参数冗余现象的存在,我们对 RECFORMER 中的大部分参数进行冻结,仅训练其中的特定层。实验结果表明,仅微调 RECFORMER 中特定的几层(如 3、7、11 层)即可达到甚至超过全量微调的效果,该现象再次验证了参数冗余的存在。
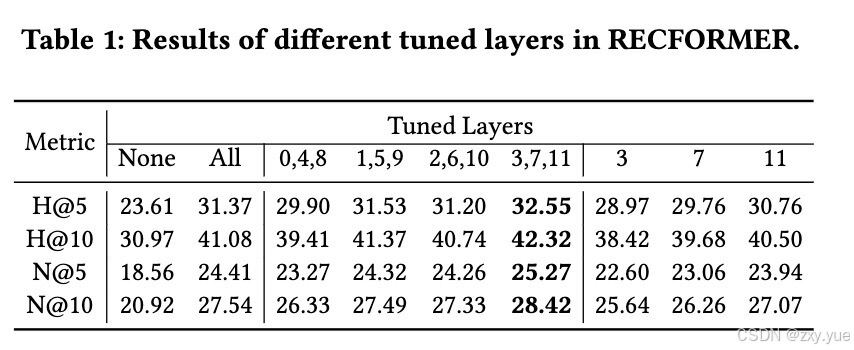
三、序列建模模型简化
基于上述观察,我们认为预训练语言模型可能不适合用于进行用户行为序列建模(由于存在大量的参数冗余),因此,我们考虑采用相对简单且轻量的模型对其进行替代,即保留 RECFORMER 编码得到的物品嵌入层,将其序列建模模型替换为较为简单的 SASRec 和 BERT4Rec 模型。我们采用了三种设定:
(1)使用冻结的物品嵌入,仅训练序列建模模型部分,该设定与 RECFORMER 第二阶段微调一致,仅对其序列建模部分进行了简化,通过观察该设定下的结果,我们可以判断在进行行为建模时预训练语言模型是否充分发挥了其序列建模的能力,是否可以被更为简单的序列建模模型所替换。
(2)使用编码得到的物品嵌入,并同时训练物品嵌入和序列建模模型,该设定可以进一步验证通过预训练语言模型得到的物品嵌入是否提取到了足够的行为信息。
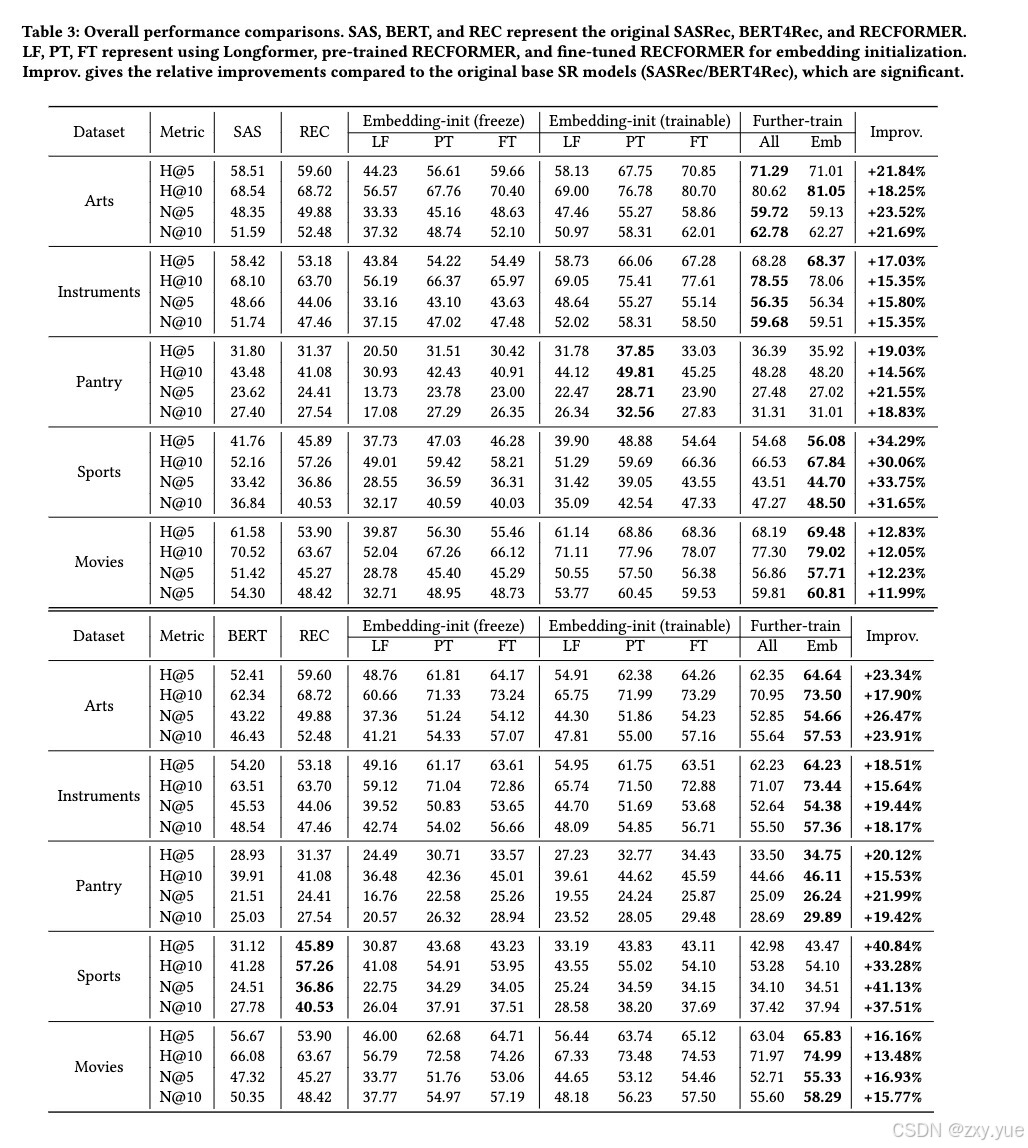
(3)在完成(1)的训练后,冻结序列建模模型部分,训练物品嵌入,该设定为利用行为数据训练物品嵌入时提供了一个更优的序列建模模型初值,以得到更优的结果。同时,我们采用了三种版本的 RECFORMER 进行物品嵌入的编码,分别为 LF(未在行为数据上训练的 RECFORMER),PT(在预训练数据集上训练得到的 RECFORMER)和 FT(在目标领域数据集上微调得到的 RECFORMER)。 通过观察实验结果,我们可以得到以下的结论:
(1)序列建模模型存在参数冗余:预训练语言模型的强大序列建模能力在进行序列推荐中的行为序列建模时未能充分发挥其能力。相比之下,结构更加简单的基于物品 ID 的序列建模模型仅使用冻结后的初始化物品嵌入便能在多个数据集上获得与更复杂模型相当甚至更好的效果,该现象表明简单模型已经足够胜任序列推荐中的行为序列建模任务。
(2)基于行为微调的预训练语言模型初始化物品嵌入能显著提升模型性能:与随机初始化相比,基于行为微调的预训练语言模型初始化能够显著提高模型性能,而直接使用未在行为序列数据集上微调的预训练语言模型进行物品嵌入初始化可能引入额外的噪声,从而导致模型性能下降。该实验结果表明行为微调的预训练语言模型能有效管理和利用其中的文本先验知识,以提升序列推荐效果。
(3)进一步微调物品嵌入能够提升推荐效果:对行为微调的预训练语言模型编码得到的物品嵌入进行持续训练能够进一步提升模型性能。该现象说明通过行为微调的预训练语言模型编码得到的物品嵌入仍然缺少行为信息,文本信息和行为信息之间存在较大的差异,因此需要在行为序列数据集上对物品嵌入进行持续的训练以更好地补足行为信息和弥合其与文本信息之间的差异。
(4)基于行为微调的预训练语言模型的初始化方法具有迁移性:使用在行为数据集上预训练后的语言模型进行物品嵌入初始化均能够为下游新领域中的序列推荐模型带来显著提升。
(5)具有与预训练语言模型类似架构和训练目标的序列推荐模型能够获得更大的提升:与行为微调预训练语言模型拥有相似架构和训练目标的序列推荐模型(如 BERT4Rec)从预训练语言模型初始化中受益更大。相比预训练语言模型复杂的序列建模模型,较为简单的序列模型在行为序列建模中表现优异,该现象也说明预训练语言模型在序列推荐任务中过度复杂,无法充分发挥其强大的序列建模能力。
四、行为微调的预训练语言模型初始化嵌入方法的泛化性
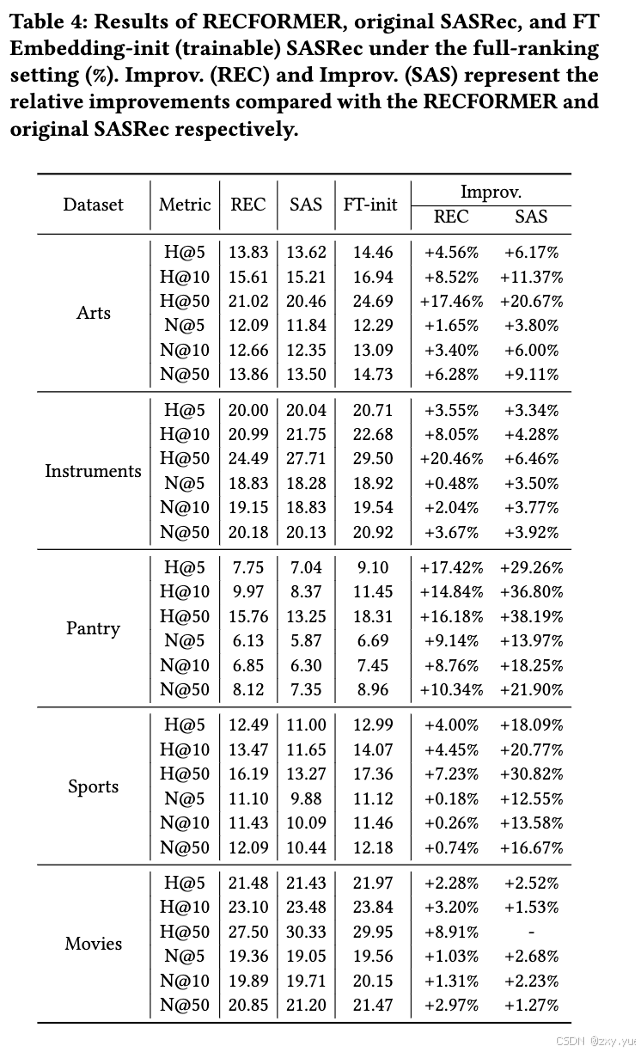
为验证行为微调的预训练语言模型初始化物品嵌入方法的泛化性,我们在全量排名的设定下进行了相关实验,结果表明使用经过行为微调的预训练语言模型初始化的物品嵌入在全量排名设定下仍能显著提升 SASRec 模型的性能,特别是在粗粒度准确度(如 HR@k)指标上,这表明该方法在提升模型的泛化能力方面具有优势。此外,该方法在所有数据集上一致优于 RECFORMER,虽然在全量排名设置下的表现提升不如随机采样设置明显,但该方法仍然在提升模型推理效率的同时带来了推荐效果的提升。
同时,我们也针对两种使用行为微调的预训练语言模型初始化物品嵌入的变体进行了相关实验,具体设定为(1)与可训练的物品 ID 嵌入协作:将行为微调的预训练语言模型初始化物品嵌入视为 SASRec 中的额外文本嵌入,并在训练期间固定这些初始化嵌入并将其与物品 ID 嵌入相加,以提供额外的训练信号。(2)与RECFORMER 的序列建模模型协作:将 RECFORMER 在其第二阶段微调中的物品嵌入设定为可训练,保持其他设置不变。
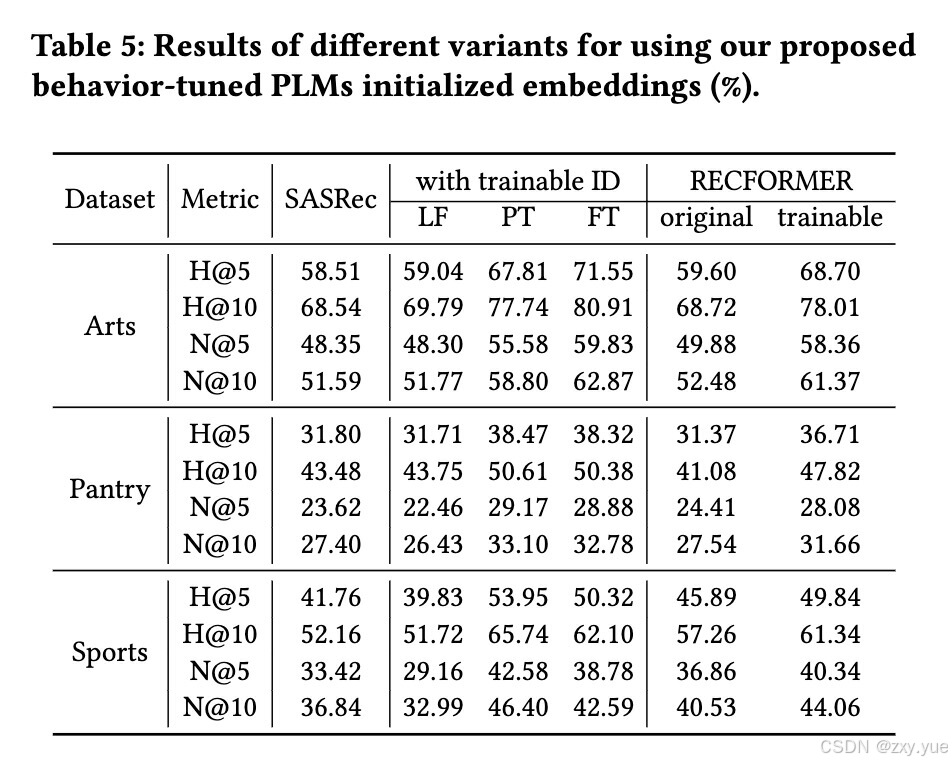
结果表明:
(1)在与可训练物品 ID 嵌入协作的实验中,使用行为微调的预训练语言模型初始化的嵌入(PT 和 FT)显著提升了模型性能,而原始预训练语言模型编码得到的嵌入(LF)则未能带来相应的提升。该现象表明,提升序列推荐模型性能的是基于行为感知的语义信息,而非原始语义信息。
(2)在与 RECFORMER 序列建模模型协作的实验中,行为微调的预训练语言模型初始化嵌入在所有数据集上显著提升了 RECFORMER 的性能,尽管其表现仍略逊于使用 SASRec 的行为序列建模模型。这验证了基于行为微调预训练语言模型的物品嵌入初始化方法的有效性,并进一步突显了预训练语言模型在行为序列建模中的冗余性。
(3)由行为微调的预训练语言模型得到的物品表征仍然缺少充足的行为信息,由于文本和行为表征之间的巨大冲突,更优的物品表征提取策略应该为:不应强行使用文本表示物品,而是使用行为微调的预训练语言模型进行其物品嵌入初始化,物品表征应该更强调其行为信息,同时采用相关的语义信息作为其重要补充。
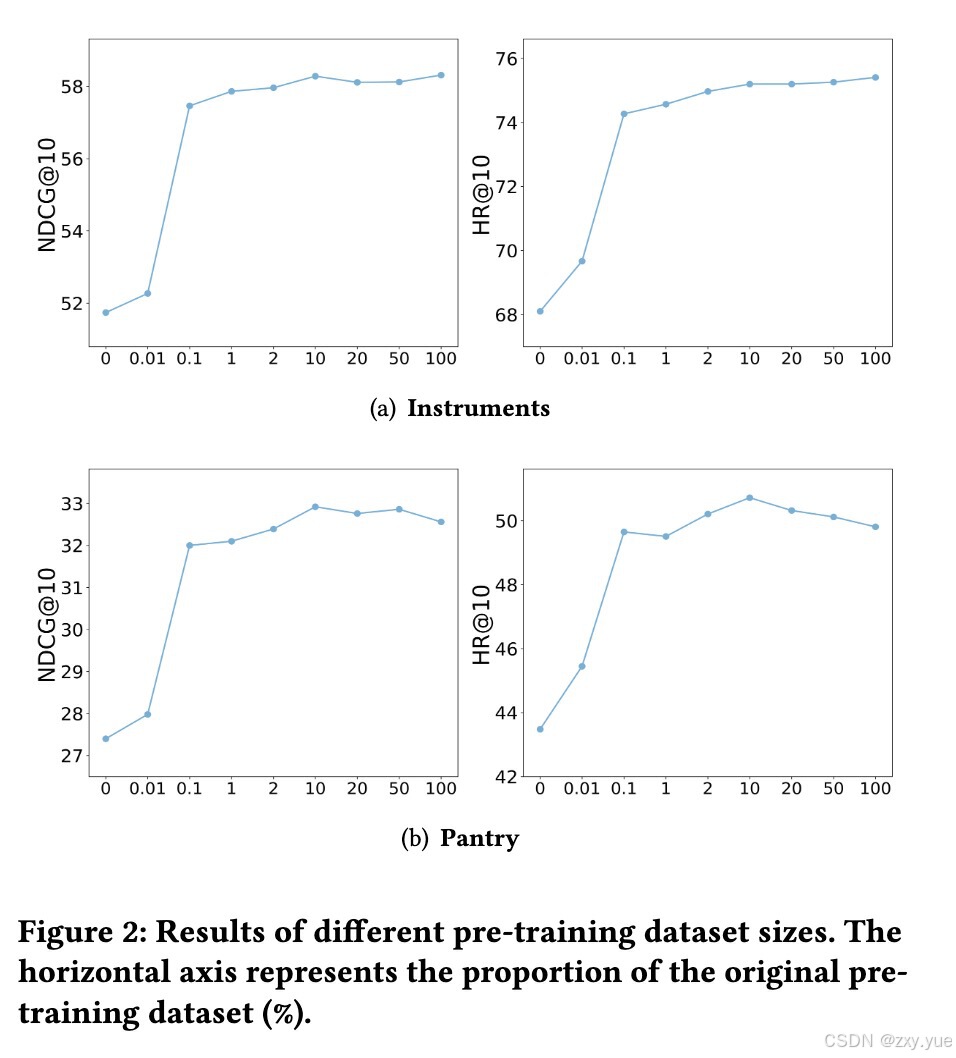
五、预训练数据集规模的影响
由于使用在行为数据集上预训练后的 RECFORMER(PT)进行物品嵌入初始化也能够为序列推荐模型带来较大的效果提升,因此我们针对预训练数据集的规模对基于行为微调预训练语言模型的物品嵌入初始化方法的影响进行了探究。实验使用了在不同规模随机选择的预训练数据集子集上训练的模型,这些子集规模从原始数据集的 0.01%到 50%不等。结果表明,使用在行为数据集上预训练后的语言模型进行物品嵌入初始化能够显著提升序列推荐模型性能,即使是最小规模的行为预训练(涉及几千名用户)也能带来相较于原始 Longformer 的显著提升。这进一步验证了我们提出方法的有效性源于行为感知的预训练语言模型,表示少量行为数据可能足以将语言模型有效迁移至序列推荐任务,突显了方法的实用性和高效性。
六、总结
在本研究中,我们深入探讨了预训练语言模型在序列推荐中的运行机制,通过分析注意力分布和简化预训练语言模型的序列建模模型,发现了在使用预训练语言模型进行序列建模时存在的显著低效和冗余。实验结果表明,采用传统基于物品ID 的序列推荐模型简化序列建模,并结合行为微调的预训练语言模型初始化物品嵌入,能够在提升模型推理效率的同时显著提升性能。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









