






目录
1 使用 ReplicationController 和 pod 部署应用
12.2 k8s中覆盖docker的ENTRYPOINT和CMD
一 K8s 三个核心对象
1. Pod -- 包含多个docker容器
- K8s 对Docker 容器的封装对象 (容器)
- 对Docker容器进行自动管理,控制
- Pod对底层容器化技术进行解耦--该技术包括docker和containerd
2. 控制器
自动部署容器的工具--只需要指定部署容器的数量,它就会帮助创建部署
3.Service
对容器提供一个固定不变的访问地址
用户访问service地址,service会把请求进行转发到容器
二 初步尝试 kubernetes
kubectl run 命令是最简单的部署引用的方式,它自动创建必要组件,这样,我们就先不必深入了解每个组件的结构
1 使用 ReplicationController 和 pod 部署应用
2 控制器
ReplicationController
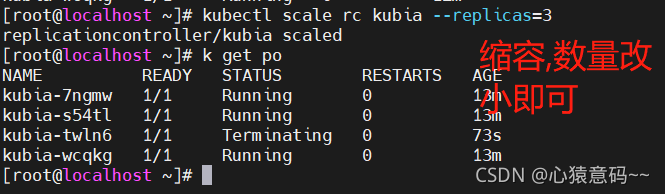
RC可以自动化维护多个pod,只需指定pod副本的数量,就可以轻松实现自动扩容缩容
当一个pod宕机,RC可以自动关闭pod,并启动一个新的pod替代它
- 下面是一个RC的部署文件,设置启动三个kubia容器:
cd ~/
cat <<EOF > kubia-rc.yml
apiVersion: v1
kind: ReplicationController # 资源类型
metadata:
name: kubia # 为RC命名
spec:
replicas: 3 # pod副本的数量
selector: # 选择器,用来选择RC管理的pod
app: kubia # 选择标签'app=kubia'的pod,由当前RC进行管理
template: # pod模板,用来创建新的pod
metadata:
labels:
app: kubia # 指定pod的标签
spec:
containers: # 容器配置
- name: kubia # 容器名
image: luksa/kubia # 镜像
imagePullPolicy: Never
ports:
- containerPort: 8080 # 容器暴露的端口
EOF
- 创建RC
- RC创建后,会根据指定的pod数量3,自动创建3个pod
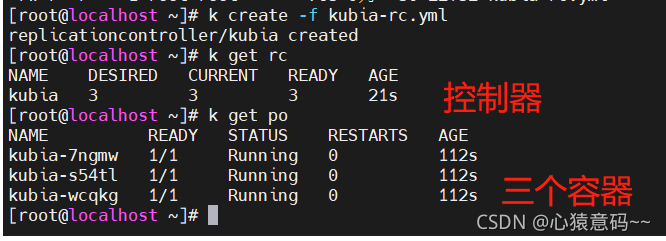
k create -f kubia-rc.yml
k get rc
----------------------------------------
NAME DESIRED CURRENT READY AGE
kubia 3 3 2 2m11s
k get po -o wide
------------------------------------------------------------------------------------------------------------------------------
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
kubia-fmtkw 1/1 Running 0 9m2s 172.20.1.7 192.168.64.192 <none> <none>
kubia-lc5qv 1/1 Running 0 9m3s 172.20.1.8 192.168.64.192 <none> <none>
kubia-pjs9n 1/1 Running 0 9m2s 172.20.2.11 192.168.64.193 <none> <none>
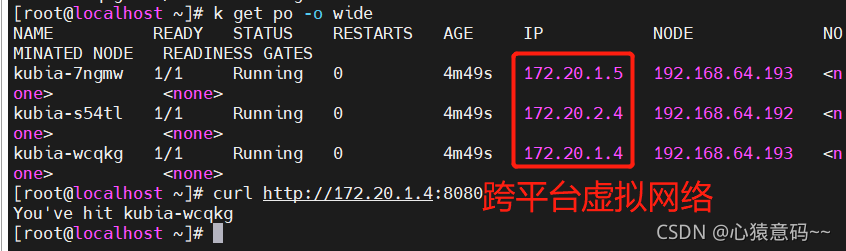
- 自动伸缩--自动扩容缩容器
通过改变数量来扩容或缩容启动容器
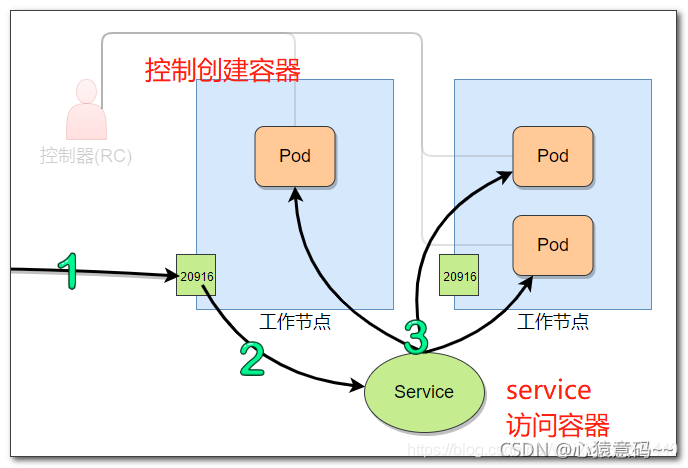
3 使用 service 对外暴露 pod
k expose \
rc kubia \
--type=NodePort \
--name kubia-http
k get svc
------------------------------------------------------------------------------
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubia-http NodePort 10.68.194.195 <none> 8080:20916/TCP 4s
这里创建了一个 service 组件,用来对外暴露pod访问,在所有节点服务器上,暴露了20916端口,通过此端口,可以访问指定pod的8080端口
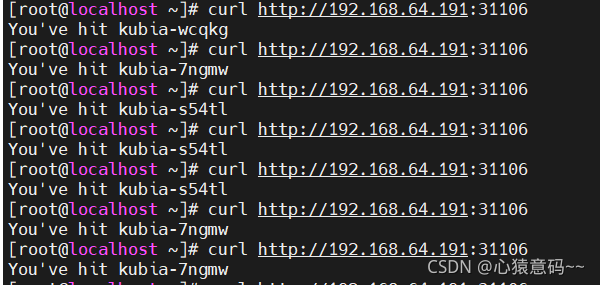
访问以下节点服务器的20916端口,都可以访问该应用
注意: 要把端口修改成你生成的随机端口
- http://192.168.64.191:20916/
- http://192.168.64.192:20916/
- http://192.168.64.193:20916/

谷歌浏览器:

微软浏览器:

注意: 换个浏览器,轮询才会有效,如果一直使用一个浏览器,访问的容器固定一个,这属于长连接
4 pod
4.1 使用部署文件手动部署pod
- 创建
kubia-manual.yml部署文件
cat <<EOF > kubia-manual.yml
apiVersion: v1 # k8s api版本
kind: Pod # 该部署文件用来创建pod资源
metadata:
name: kubia-manual # pod名称前缀,后面会追加随机字符串
spec:
containers: # 对pod中容器的配置
- image: luksa/kubia # 镜像名
imagePullPolicy: Never
name: kubia # 容器名
ports:
- containerPort: 8080 # 容器暴露的端口
protocol: TCP
EOF
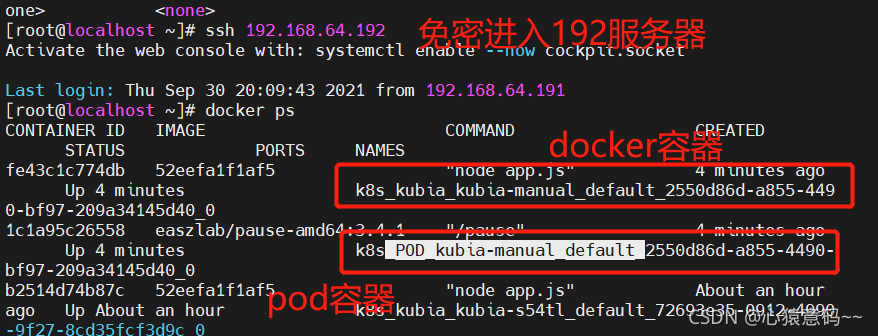
- 使用部署文件创建pod
k create -f kubia-manual.yml
k get po
-----------------------------------------------
NAME READY STATUS RESTARTS AGE
kubia-manual 1/1 Running 0 19s

4.2 查看pod的部署文件
4.4 pod 标签
- 创建pod时指定标签,只有指定标签的pod和service才能进入或访问对应标签的容器
通过kubia-manual-with-labels.yml部署文件部署pod
在部署文件中为pod设置了两个自定义标签:creation_method和env
cat <<EOF > kubia-manual-with-labels.yml
apiVersion: v1 # api版本
kind: Pod # 部署的资源类型
metadata:
name: kubia-manual-v2 # pod名
labels: # 标签设置,键值对形式
creation_method: manual
env: prod
spec:
containers: # 容器设置
- image: luksa/kubia # 镜像
name: kubia # 容器命名
imagePullPolicy: Never
ports: # 容器暴露的端口
- containerPort: 8080
protocol: TCP
EOF
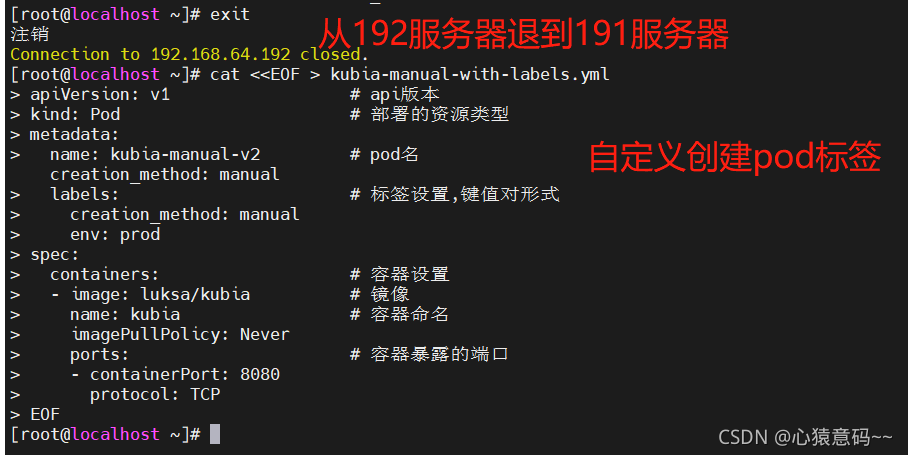
- 使用部署文件创建资源
k create -f kubia-manual-with-labels.yml
- 列出所有的pod,并显示pod的标签
k get po --show-labels
4.5 修改pod的标签
pod kubia-manual-v2 的env标签值是prod, 我们把这个标签的值修改为 debug
修改一个标签的值时,必须指定 --overwrite 参数,目的是防止误修改
k label po kubia-manual-v2 env=debug --overwrite

- 为pod
kubia-manual设置标签
k label po kubia-manual creation_method=manual env=debug
- 为pod
kubia-7ngmw设置标签
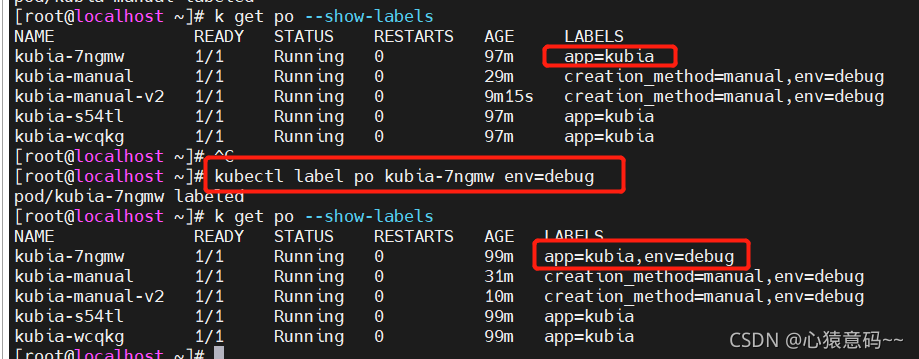
4.6 使用标签来查询 pod
- 查询
creation_method=manual的pod
# -l 查询
k get po \
-l creation_method=manual \
-L creation_method,env
---------------------------------------------------------------------------
NAME READY STATUS RESTARTS AGE CREATION_METHOD ENV
kubia-manual 1/1 Running 0 28m manual debug
kubia-manual-v2 1/1 Running 0 27m manual debug
- 查询有 env 标签的 pod
# -l 查询
k get po \
-l env \
-L creation_method,env
---------------------------------------------------------------------------
NAME READY STATUS RESTARTS AGE CREATION_METHOD ENV
kubia-5rz9h 1/1 Running 0 31m debug
kubia-manual 1/1 Running 0 30m manual debug
kubia-manual-v2 1/1 Running 0 29m manual debug
- 查询
creation_method=manual并且env=debug的 pod
# -l 查询
k get po \
-l creation_method=manual,env=debug \
-L creation_method,env
---------------------------------------------------------------------------
NAME READY STATUS RESTARTS AGE CREATION_METHOD ENV
kubia-manual 1/1 Running 0 33m manual debug
kubia-manual-v2 1/1 Running 0 32m manual debug
- 查询不存在 creation_method 标签的 pod
# -l 查询
k get po \
-l '!creation_method' \
-L creation_method,env
-----------------------------------------------------------------------
NAME READY STATUS RESTARTS AGE CREATION_METHOD ENV
kubia-5rz9h 1/1 Running 0 36m debug
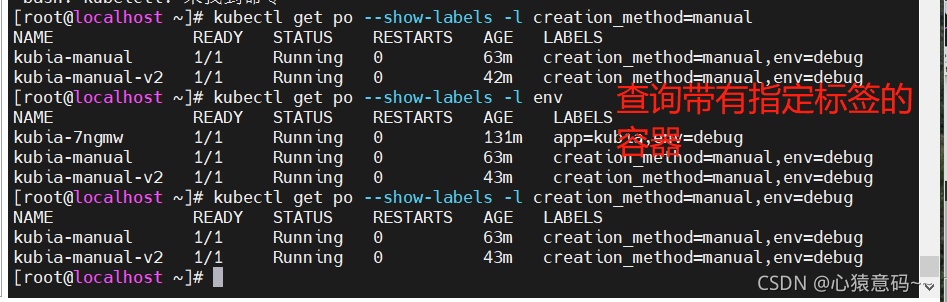
- 查询不存在creation_method 标签的 pod

4.7 把pod部署到指定的节点服务器
我们不能直接指定服务器的地址来约束pod部署的节点
通过为node设置标签,在部署pod时,使用节点选择器,来选择把pod部署到匹配的节点服务器
- 部署文件,其中节点选择器
nodeSelector设置了通过标签gpu=true来选择节点
cat <<EOF > kubia-gpu.yml
apiVersion: v1
kind: Pod
metadata:
name: kubia-gpu # pod名
spec:
nodeSelector: # 节点选择器,把pod部署到匹配的节点
gpu: "true" # 通过标签 gpu=true 来选择匹配的节点
containers: # 容器配置
- image: luksa/kubia # 镜像
name: kubia # 容器名
imagePullPolicy: Never
EOF
- 创建pod
kubia-gpu,并查看pod的部署节点
k create -f kubia-gpu.yml
k get po -o wide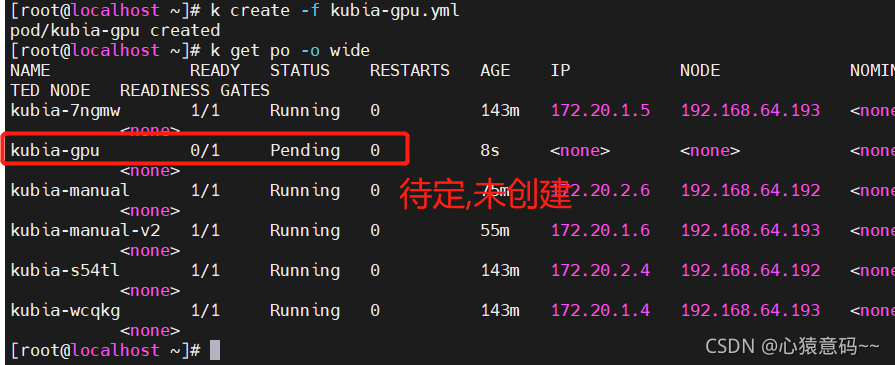
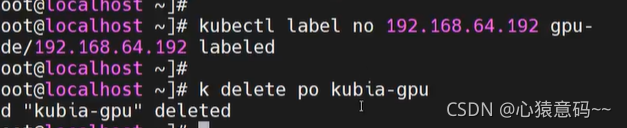
- 下面为名称为
192.168.64.192的节点服务器,添加标签gpu=true
kubectl label no 192.168.64.192 gpu=true

5 namespace 命名空间
可以使用命名空间对资源进行组织管理
不同命名空间的资源并不完全隔离,它们之间可以通过网络互相访问
5.1 查看命名空间
# namespace
k get ns
k get po --namespace kube-system
k get po -n kube-system

5.2 创建命名空间
- 新建部署文件
custom-namespace.yml,创建命名空间,命名为custom-namespace
cat <<EOF > custom-namespace.yml
apiVersion: v1
kind: Namespace
metadata:
name: custom-namespace
EOF
# 创建命名空间
k create -f custom-namespace.yml
k get ns
5.3 将pod部署到指定的命名空间中
- 创建pod,并将其部署到命名空间
custom-namespace
# 创建 Pod 时指定命名空间
k create \
-f kubia-manual.yml \
-n custom-namespace
# 默认访问default命名空间,默认命名空间中不存在pod kubia-manual
k get po kubia-manual
# 访问custom-namespace命名空间中的pod
k get po kubia-manual -n custom-namespace
----------------------------------------------------------
NAME READY STATUS RESTARTS AGE
kubia-manual 0/1 ContainerCreating 0 59s


6 删除资源
# 按名称删除, 可以指定多个名称
# 例如: k delete po po1 po2 po3
k delete po kubia-gpu
# 按标签删除
k delete po -l creation_method=manual
# 删除命名空间和其中所有的pod
k delete ns custom-namespace
# 删除当前命名空间中所有pod
k delete po --all
# 由于有ReplicationController,所以会自动创建新的pod
[root@master1 ~]# k get po
NAME READY STATUS RESTARTS AGE
kubia-m6k4d 1/1 Running 0 2m20s
kubia-rkm58 1/1 Running 0 2m15s
kubia-v4cmh 1/1 Running 0 2m15s
# 删除工作空间中所有类型中的所有资源
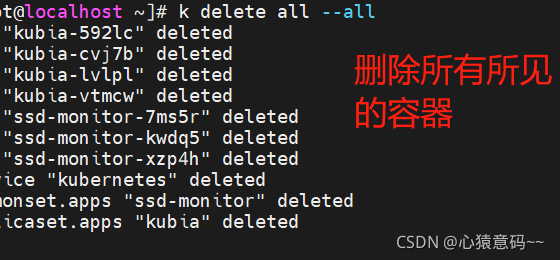
# 这个操作会删除一个系统Service kubernetes,它被删除后会立即被自动重建
k delete all --all
注意:只删除pod容器,RC控制器会自动把这些pod容器再创建回来,所以要删除RC控制器和service
- 标签的删除
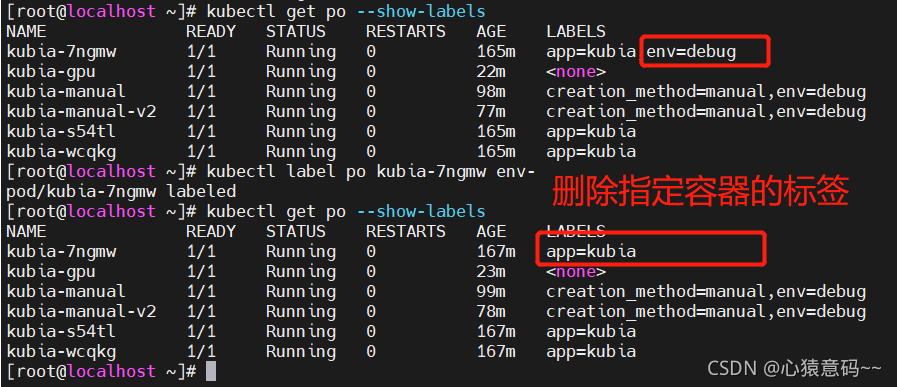
- 节点服务器的删除
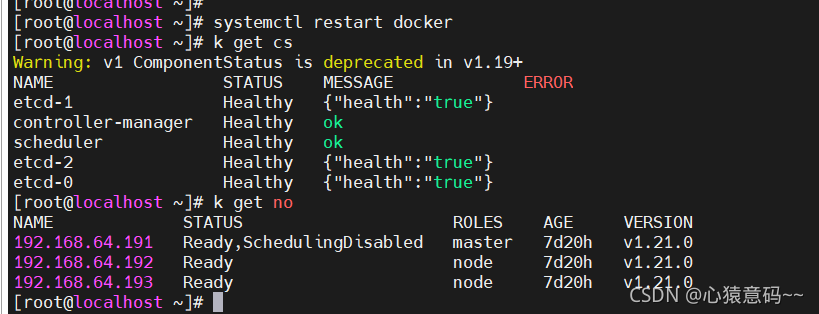
- 下次重启,执行命令

7 存活探针
探测容器的运行状态,默认10秒每次
有三种存活探针:
-
HTTP GET
返回 2xx 或 3xx 响应码则认为探测成功 -
TCP
与指定端口建立 TCP 连接,连接成功则为成功 -
Exec
在容器内执行任意的指定命令,并检查命令的退出码,退出码为0则为探测成功
HTTP GET 存活探针
luksa/kubia-unhealthy 镜像
在kubia-unhealthy镜像中,应用程序作了这样的设定: 从第6次请求开始会返回500错
在部署文件中,我们添加探针,来探测容器的健康状态.
探针默认每10秒探测一次,连续三次探测失败后重启容器
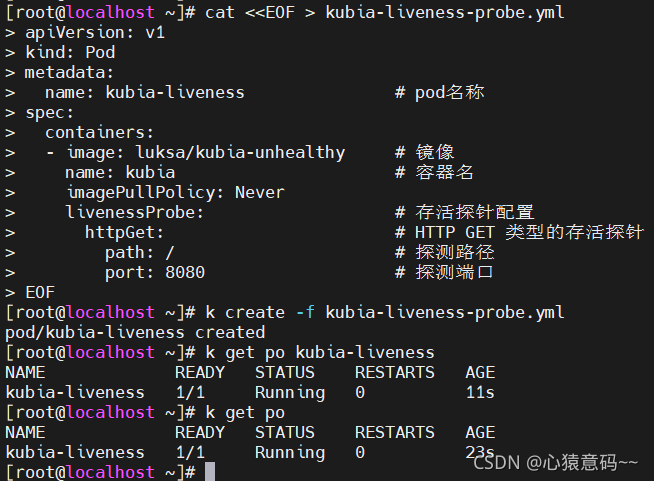
cat <<EOF > kubia-liveness-probe.yml
apiVersion: v1
kind: Pod
metadata:
name: kubia-liveness # pod名称
spec:
containers:
- image: luksa/kubia-unhealthy # 镜像
name: kubia # 容器名
imagePullPolicy: Never
livenessProbe: # 存活探针配置
httpGet: # HTTP GET 类型的存活探针
path: / # 探测路径 /代表根路径,也可以指定哪个路径/xx/xx/xx
port: 8080 # 探测端口
EOF
- 创建 pod
k create -f kubia-liveness-probe.yml
# pod的RESTARTS属性,每过1分半种就会加1
k get po kubia-liveness
--------------------------------------------------
NAME READY STATUS RESTARTS AGE
kubia-liveness 1/1 Running 0 5m25s
- 查看上一个(previous)pod的日志,前5次探测是正确状态,后面3次探测是失败的,则该pod会被删除;如果不加previous表示查看当前pod日志
k logs kubia-liveness --previous
-----------------------------------------
Kubia server starting...
Received request from ::ffff:172.20.3.1
Received request from ::ffff:172.20.3.1
Received request from ::ffff:172.20.3.1
Received request from ::ffff:172.20.3.1
Received request from ::ffff:172.20.3.1
Received request from ::ffff:172.20.3.1
Received request from ::ffff:172.20.3.1
Received request from ::ffff:172.20.3.1
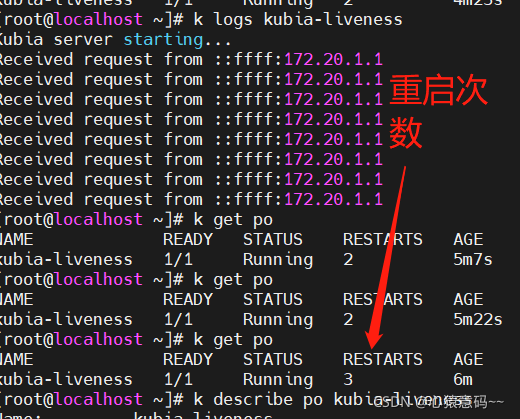
- 查看pod描述kubia-liveness存活探针的默认参数
k describe po kubia-liveness
---------------------------------
......
Restart Count: 6
Liveness: http-get http://:8080/ delay=0s timeout=1s period=10s #success=1 #failure=3
......
delay0表示容器启动后立即开始探测timeout1表示必须在1秒内响应,否则视为探测失败period10s表示每10秒探测一次failure3表示连续3次失败后重启容器
通过设置 delay 延迟时间,可以避免在容器内应用没有完全启动的情况下就开始探测
cat <<EOF > kubia-liveness-probe-initial-delay.yml
apiVersion: v1
kind: Pod
metadata:
name: kubia-liveness
spec:
containers:
- image: luksa/kubia-unhealthy
name: kubia
imagePullPolicy: Never
livenessProbe:
httpGet:
path: /
port: 8080
initialDelaySeconds: 15 # 第一次探测的延迟时间
EOF

- 删除全部容器
k delete all --all
8 Dashboard 仪表盘
- 查看 Dashboard 部署信息
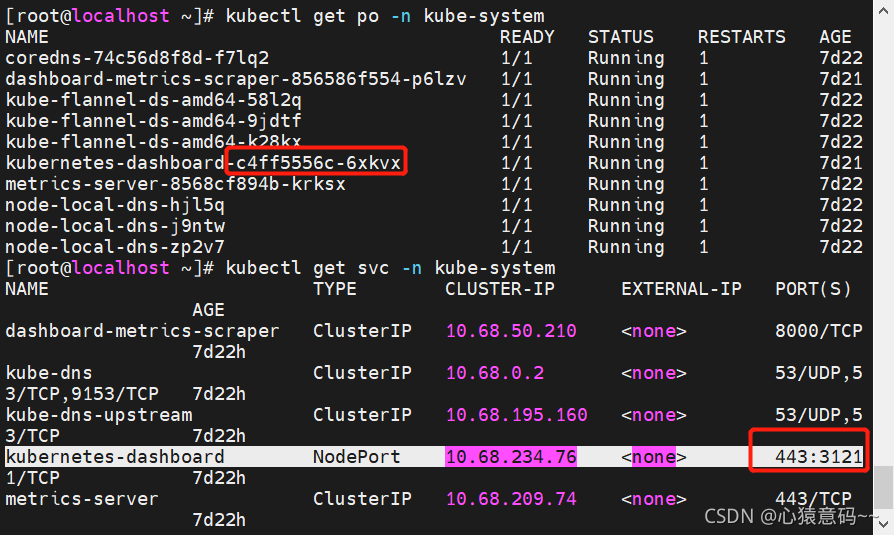
访问测试:https://192.168.64.191:31211
每个控制台的端口号都不一样
现在访问 dashboard 由于安全设置的原因无法访问
令牌
# 获取 Bearer Token,复制输出中 ‘token:’ 开头那一行
k -n kube-system describe secret $(kubectl -n kube-system get secret | grep admin-user | awk '{print $1}')

注意复制时的空格,需要删除

- 输入令牌处,复制粘贴下方的令牌,登录即可
eyJhbGciOiJSUzI1NiIsImtpZCI6InMtS1lqMnJSWlpTUmpUaGhfQmx0SldrRUh2VHl4aTJaZDVHTDZHbHZObk0ifQ.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJrdWJlLXN5c3RlbSIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VjcmV0Lm5hbWUiOiJhZG1pbi11c2VyLXRva2VuLTg2aGJnIiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9zZXJ2aWNlLWFjY291bnQubmFtZSI6ImFkbWluLXVzZXIiLCJrdWJlcm5ldGVzLmlvL3NlcnZpY2VhY2NvdW50L3NlcnZpY2UtYWNjb3VudC51aWQiOiI0ZDFhYTY0Yy0zZDI2LTQ4NWMtODQ4OS1kOWUzM2ZkY2FkMTYiLCJzdWIiOiJzeXN0ZW06c2VydmljZWFjY291bnQ6a3ViZS1zeXN0ZW06YWRtaW4tdXNlciJ9.S1icWl24RUI1tAgF8xsXA4Z4WI10J9pqEO5EPaAQDc4LDvITCIfsZoHHkY9RkBNXSUd3nffcX41oNTOa-QJjMTAYDxav7GPKQRHl8v9gMOfzJF7plOh8506jozbuoJi1niNlfzhRd_ej9mLlmVLE-itNkckiVhSYvyABqeE1q765CHnB27rgFI3u7MYed7KxUTYXAeEKK5BF6gPyFW__gaSpgnVuE58bh_WvH01st1PqdNBN1drLAAn3haP2rCBzy0oMfExclz0P-Fuu5v6Nxcj-Kix3_ZWTIOrxu0Deai6FGLhx5mX3i3OQhf7eANjyCg1WLelW7ZfS-q8nH1u2oA 
9 控制器
命令行创建控制器和Dashboard控制台创建都可以
9.1 ReplicationController
RC可以自动化维护多个pod,只需指定pod副本的数量,就可以轻松实现自动扩容缩容
当一个pod宕机,RC可以自动关闭pod,并启动一个新的pod替代它
下面是一个RC的部署文件,设置启动三个kubia容器:
cat <<EOF > kubia-rc.yml
apiVersion: v1
kind: ReplicationController # 资源类型
metadata:
name: kubia # 为RC命名
spec:
replicas: 3 # pod副本的数量
selector: # 选择器,用来选择RC管理的pod
app: kubia # 选择标签'app=kubia'的pod,由当前RC进行管理
template: # pod模板,用来创建新的pod
metadata:
labels:
app: kubia # 指定pod的标签
spec:
containers: # 容器配置
- name: kubia # 容器名
image: luksa/kubia # 镜像
imagePullPolicy: Never
ports:
- containerPort: 8080 # 容器暴露的端口
EOF
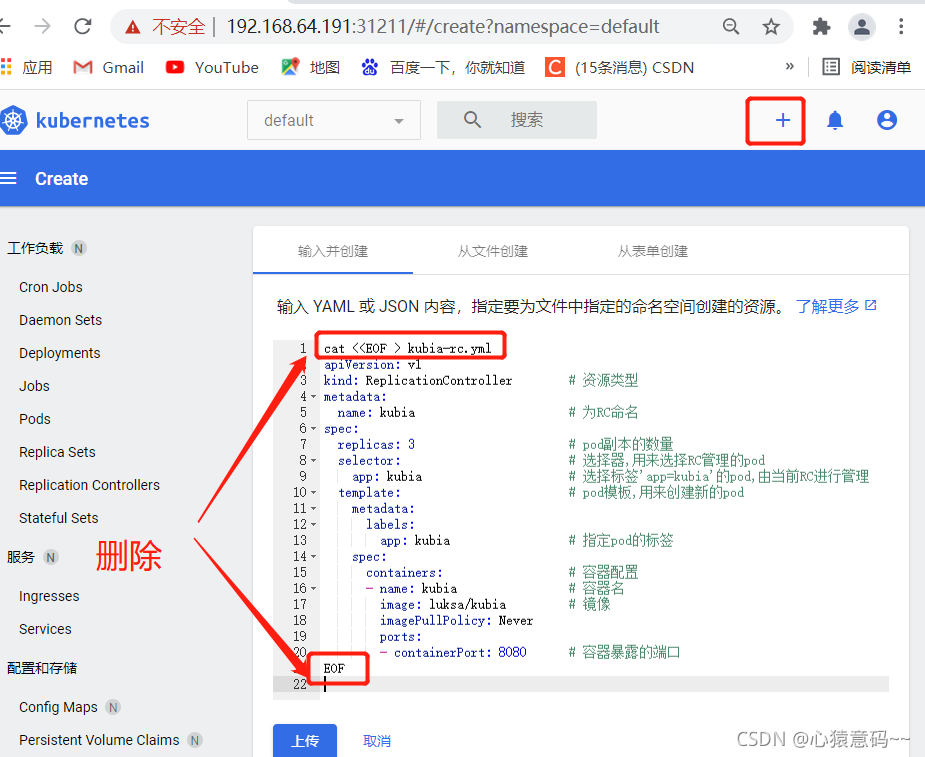
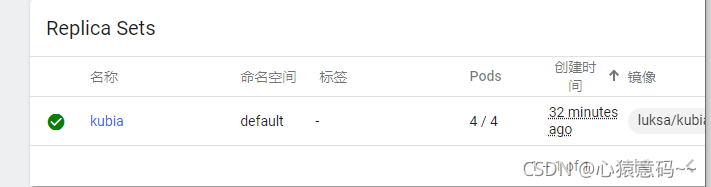
- 查看pod和控制器,控制器会创建指定数量的pod,此处为三个pod,如图所示

9.2 创建RC
RC创建后,会根据指定的pod数量3,自动创建3个pod
k create -f kubia-rc.yml
k get rc
----------------------------------------
NAME DESIRED CURRENT READY AGE
kubia 3 3 2 2m11s
k get po -o wide
------------------------------------------------------------------------------------------------------------------------------
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
kubia-fmtkw 1/1 Running 0 9m2s 172.20.1.7 192.168.64.192 <none> <none>
kubia-lc5qv 1/1 Running 0 9m3s 172.20.1.8 192.168.64.192 <none> <none>
kubia-pjs9n 1/1 Running 0 9m2s 172.20.2.11 192.168.64.193 <none> <none>
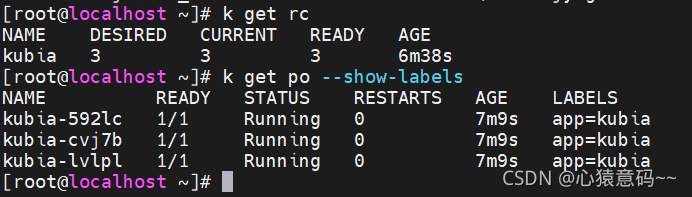
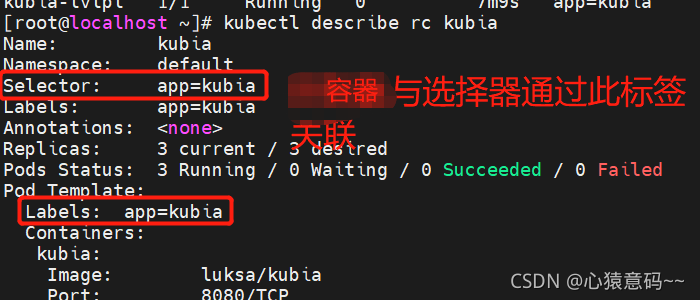
- RC是通过指定的标签
app=kubia对匹配的pod进行管理的 - 允许在pod上添加任何其他标签,而不会影响pod与RC的关联关系
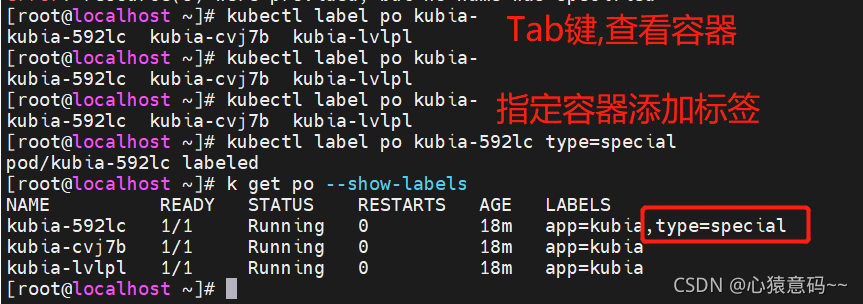
k label pod kubia-fmtkw type=special
k get po --show-labels
----------------------------------------------------------------------
NAME READY STATUS RESTARTS AGE LABELS
kubia-fmtkw 1/1 Running 0 6h31m app=kubia,type=special
kubia-lc5qv 1/1 Running 0 6h31m app=kubia
kubia-pjs9n 1/1 Running 0 6h31m app=kubia
- 指定容器添加标签
- 修改指定容器的标签,会使该容器脱离控制器的管理,同时创建一个新的容器

但是,如果改变pod的app标签的值,就会使这个pod脱离RC的管理,这样RC会认为这里少了一个pod,那么它会立即创建一个新的pod,来满足我们设置的3个pod的要求
k label pod kubia-fmtkw app=foo --overwrite
k get pods -L app
-------------------------------------------------------------------
NAME READY STATUS RESTARTS AGE APP
kubia-fmtkw 1/1 Running 0 6h36m foo
kubia-lc5qv 1/1 Running 0 6h36m kubia
kubia-lhj4q 0/1 Pending 0 6s kubia
kubia-pjs9n 1/1 Running 0 6h36m kubia
9.3 修改 pod 模板
pod模板修改后,只影响后续新建的pod,已创建的pod不会被修改
可以删除旧的pod,用新的pod来替代
# 编辑 ReplicationController,添加一个新的标签: foo=bar
k edit rc kubia
------------------------------------------------
......
spec:
replicas: 3
selector:
app: kubia
template:
metadata:
creationTimestamp: null
labels:
app: kubia
foo: bar # 任意添加一标签
spec:
......
# 之前pod的标签没有改变
k get pods --show-labels
----------------------------------------------------------------------
NAME READY STATUS RESTARTS AGE LABELS
kubia-lc5qv 1/1 Running 0 3d5h app=kubia
kubia-lhj4q 1/1 Running 0 2d22h app=kubia
kubia-pjs9n 1/1 Running 0 3d5h app=kubia
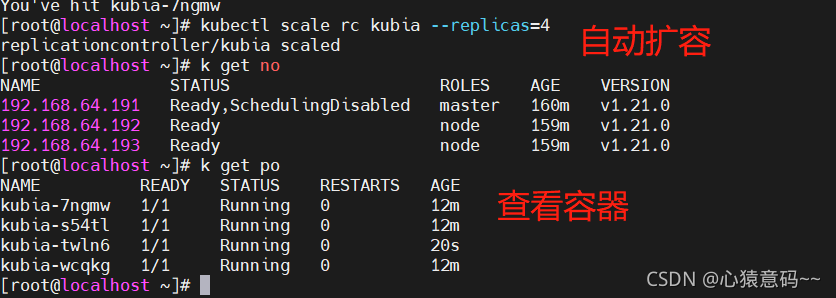
# 通过RC,把pod扩容到6个
# 可以使用前面用过的scale命令来扩容
# k scale rc kubia --replicas=6
# 或者,可以编辑修改RC的replicas属性,修改成6
k edit rc kubia
---------------------
spec:
replicas: 6 # 从3修改成6,扩容到6个pod
selector:
app: kubia
# 新增加的pod有新的标签,而旧的pod没有新标签
k get pods --show-labels
----------------------------------------------------------------------
NAME READY STATUS RESTARTS AGE LABELS
kubia-8d9jj 0/1 Pending 0 2m23s app=kubia,foo=bar
kubia-lc5qv 1/1 Running 0 3d5h app=kubia
kubia-lhj4q 1/1 Running 0 2d22h app=kubia
kubia-pjs9n 1/1 Running 0 3d5h app=kubia
kubia-wb8sv 0/1 Pending 0 2m17s app=kubia,foo=bar
kubia-xp4jv 0/1 Pending 0 2m17s app=kubia,foo=bar
# 删除 rc, 但不级联删除 pod, 使 pod 处于脱管状态
k delete rc kubia --cascade=false
9.4 ReplicaSet
ReplicaSet控制器被设计用来替代 ReplicationController,它提供了更丰富的pod选择功能
以后我们总应该使用 RS, 而不适用 RC, 但在旧系统中仍会使用 RC
首先:
- 删除rc控制器,但是保留创建的容器
kubectl delete rc kubia --cascade=orphan
#查看rc控制器是否删除
k get rc
#查看五个容器是否还在
k get po


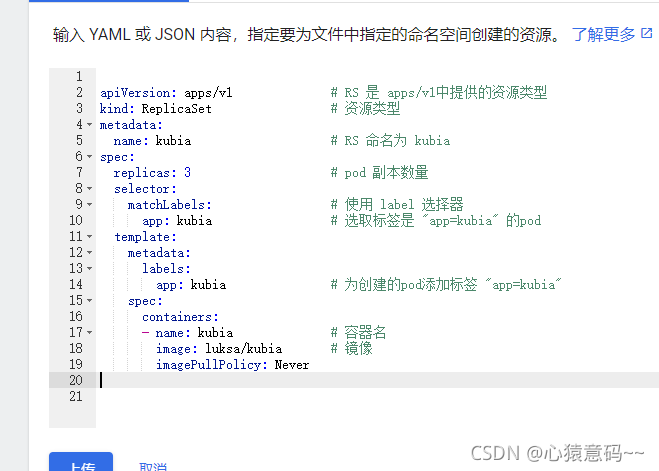
- 然后:创建rs控制器
cat <<EOF > kubia-replicaset.yml
apiVersion: apps/v1 # RS 是 apps/v1中提供的资源类型
kind: ReplicaSet # 资源类型
metadata:
name: kubia # RS 命名为 kubia
spec:
replicas: 3 # pod 副本数量
selector:
matchLabels: # 使用 label 选择器
app: kubia # 选取标签是 "app=kubia" 的pod
template:
metadata:
labels:
app: kubia # 为创建的pod添加标签 "app=kubia"
spec:
containers:
- name: kubia # 容器名
image: luksa/kubia # 镜像
imagePullPolicy: Never
EOF
- 也可以在控制台创建
注意:之前是五个容器,创建后会杀掉一个容器
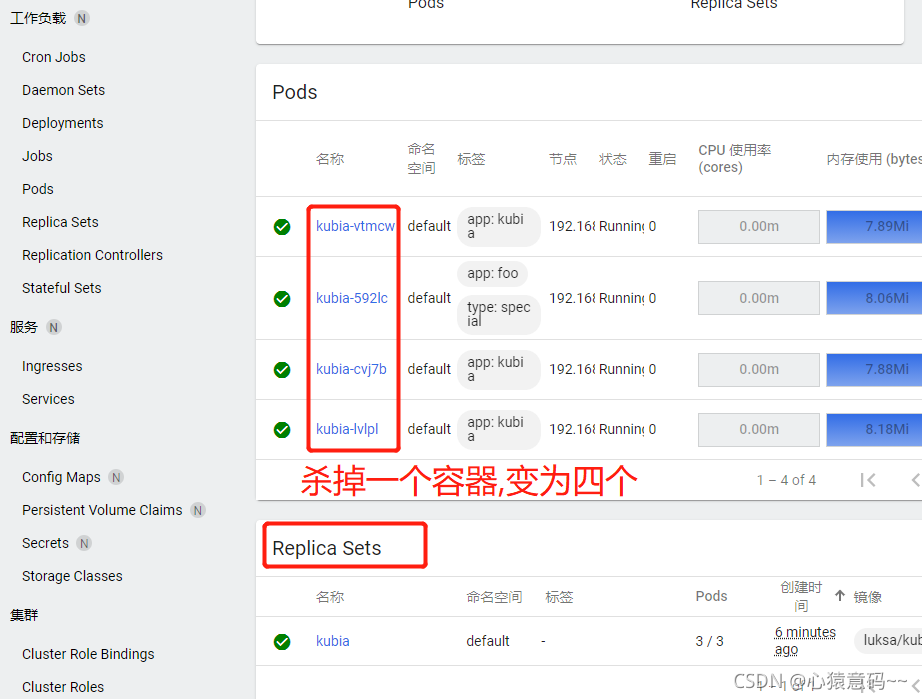
- 创建 ReplicaSet
k create -f kubia-replicaset.yml
# 之前脱离管理的pod被RS管理
# 设置的pod数量是3,多出的pod会被关闭
k get rs
----------------------------------------
NAME DESIRED CURRENT READY AGE
kubia 3 3 3 4s
# 多出的3个pod会被关闭
k get pods --show-labels
----------------------------------------------------------------------
NAME READY STATUS RESTARTS AGE LABELS
kubia-8d9jj 1/1 Pending 0 2m23s app=kubia,foo=bar
kubia-lc5qv 1/1 Terminating 0 3d5h app=kubia
kubia-lhj4q 1/1 Terminating 0 2d22h app=kubia
kubia-pjs9n 1/1 Running 0 3d5h app=kubia
kubia-wb8sv 1/1 Pending 0 2m17s app=kubia,foo=bar
kubia-xp4jv 1/1 Terminating 0 2m17s app=kubia,foo=bar
# 查看RS描述, 与RC几乎相同
k describe rs kubia
- 使用更强大的标签选择器
cat <<EOF > kubia-replicaset.yml
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: kubia
spec:
replicas: 4
selector:
matchExpressions: # 表达式匹配选择器
- key: app # label 名是 app
operator: In # in 运算符
values: # label 值列表
- kubia
- foo
template:
metadata:
labels:
app: kubia
spec:
containers:
- name: kubia
image: luksa/kubia
imagePullPolicy: Never
EOF


可使用的运算符:
In: label与其中一个值匹配NotIn: label与任何一个值都不匹配Exists: 包含指定label名称(值任意)DoesNotExists: 不包含指定的label
清理控制器和容器:
k delete rs kubia
k get rs
k get po
9.5 DaemonSet
使用场景:对部属服务器的监控
在每个节点上运行一个 pod,例如资源监控,kube-proxy等
DaemonSet不指定pod数量,它会在每个节点上部署一个pod
cat <<EOF > ssd-monitor-daemonset.yml
apiVersion: apps/v1
kind: DaemonSet # 资源类型
metadata:
name: ssd-monitor # DS资源命名
spec:
selector:
matchLabels: # 标签匹配器
app: ssd-monitor # 匹配的标签
template:
metadata:
labels:
app: ssd-monitor # 创建pod时,添加标签
spec:
containers: # 容器配置
- name: main # 容器命名
image: luksa/ssd-monitor # 镜像
imagePullPolicy: Never
EOF
# 先清理
k delete ds ssd-monitor
# 再重新创建
k create -f ssd-monitor-daemonset.yml
- 查看 DS 和 pod, 看到并没有创建pod,这是因为不存在具有
disk=ssd标签的节点
k get ds
k get po

9.6 Job
Job 用来运行单个任务,任务结束后pod不再重启
cat <<EOF > exporter.yml
apiVersion: batch/v1 # Job资源在batch/v1版本中提供
kind: Job # 资源类型
metadata:
name: batch-job # 资源命名
spec:
template:
metadata:
labels:
app: batch-job # pod容器标签
spec:
restartPolicy: OnFailure # 任务失败时重启
containers:
- name: main # 容器名
image: luksa/batch-job # 镜像
imagePullPolicy: Never
EOF
- 创建 job
镜像 batch-job 中的进程,运行120秒后会自动退出
k create -f exporter.yml
k get job
-----------------------------------------
NAME COMPLETIONS DURATION AGE
batch-job 0/1 7s
k get po
-------------------------------------------------------------
NAME READY STATUS RESTARTS AGE
batch-job-q97zf 0/1 ContainerCreating 0 7s
- 等待两分钟后,pod中执行的任务退出,再查看job和pod
k get job
-----------------------------------------
NAME COMPLETIONS DURATION AGE
batch-job 1/1 2m5s 2m16s
k get po
-----------------------------------------------------
NAME READY STATUS RESTARTS AGE
batch-job-q97zf 0/1 Completed 0 2m20s
- 使用Job让pod连续运行5次
先创建第一个pod,等第一个完成后后,再创建第二个pod,以此类推,共顺序完成5个pod
cat <<EOF > multi-completion-batch-job.yml
apiVersion: batch/v1
kind: Job
metadata:
name: multi-completion-batch-job
spec:
completions: 5 # 指定完整的数量
template:
metadata:
labels:
app: batch-job
spec:
restartPolicy: OnFailure
containers:
- name: main
image: luksa/batch-job
imagePullPolicy: Never
EOF
k create -f multi-completion-batch-job.yml
- 共完成5个pod,并每次可以同时启动两个pod
cat <<EOF > multi-completion-parallel-batch-job.yml
apiVersion: batch/v1
kind: Job
metadata:
name: multi-completion-parallel-batch-job
spec:
completions: 5 # 共完成5个
parallelism: 2 # 可以有两个pod同时执行
template:
metadata:
labels:
app: batch-job
spec:
restartPolicy: OnFailure
containers:
- name: main
image: luksa/batch-job
imagePullPolicy: Never
EOF
k create -f multi-completion-parallel-batch-job.yml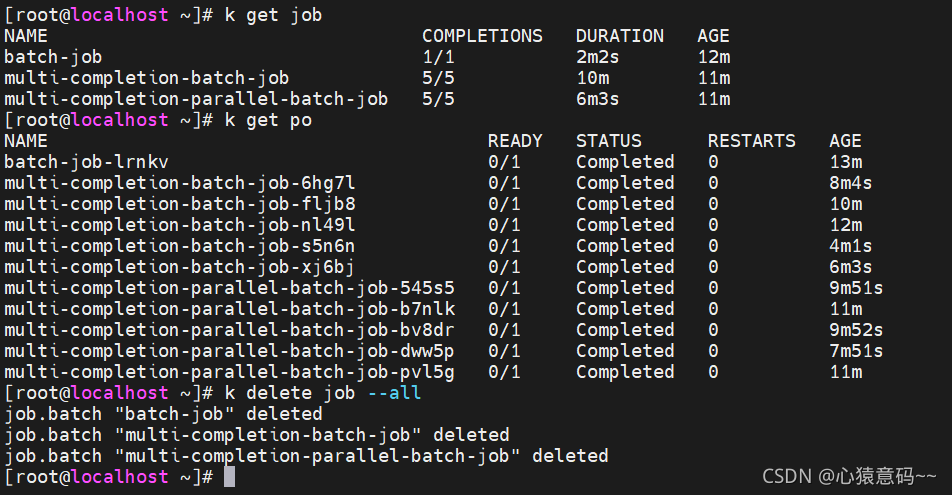

9.7 CronJob
定时和重复执行的任务
cron时间表格式:"分钟 小时 每月的第几天 月 星期几"
cat <<EOF > cronjob.yml
apiVersion: batch/v1beta1 # api版本
kind: CronJob # 资源类型
metadata:
name: batch-job-every-fifteen-minutes
spec:
# 0,15,30,45 - 分钟
# 第一个* - 每个小时
# 第二个* - 每月的每一天
# 第三个* - 每月
# 第四个* - 每一周中的每一天
schedule: "0,15,30,45 * * * *"
jobTemplate:
spec:
template:
metadata:
labels:
app: periodic-batch-job
spec:
restartPolicy: OnFailure
containers:
- name: main
image: luksa/batch-job
imagePullPolicy: Never
EOF
- 创建cronjob
k create -f cronjob.yml
# 立即查看 cronjob,此时还没有创建pod
k get cj
----------------------------------------------------------------------------------------------
NAME SCHEDULE SUSPEND ACTIVE LAST SCHEDULE AGE
batch-job-every-fifteen-minutes 0,15,30,45 * * * * False 1 27s 2m17s
# 到0,15,30,45分钟时,会创建一个pod,每15分钟会启动一个容器
k get po
--------------------------------------------------------------------------------------
NAME READY STATUS RESTARTS AGE
batch-job-every-fifteen-minutes-1567649700-vlmdw 1/1 Running 0 36s
10 Service
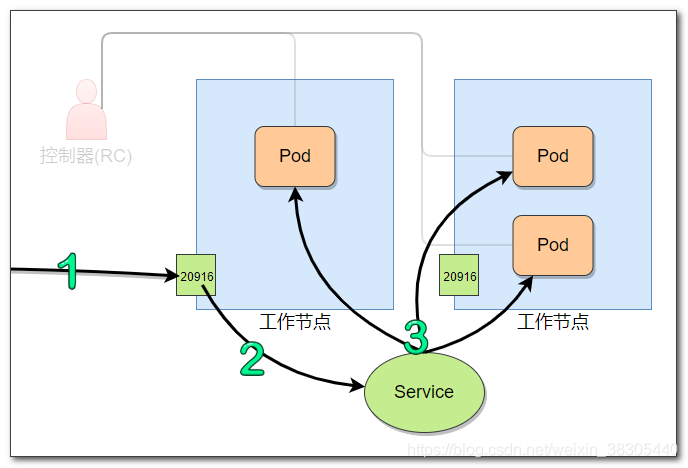
通过Service资源,为多个pod提供一个单一不变的接入地址,service用于访问请求的转发调用
cat <<EOF > kubia-svc.yml
apiVersion: v1
kind: Service # 资源类型
metadata:
name: kubia # 资源命名
spec:
ports:
- port: 80 # Service向外暴露的端口
targetPort: 8080 # 容器的端口
selector:
app: kubia # 通过标签,选择名为kubia的所有pod
EOF
- 创建service资源
k create -f kubia-svc.yml
k get svc
--------------------------------------------------------------------
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.68.0.1 <none> 443/TCP 2d11h
kubia ClusterIP 10.68.163.98 <none> 80/TCP 5s
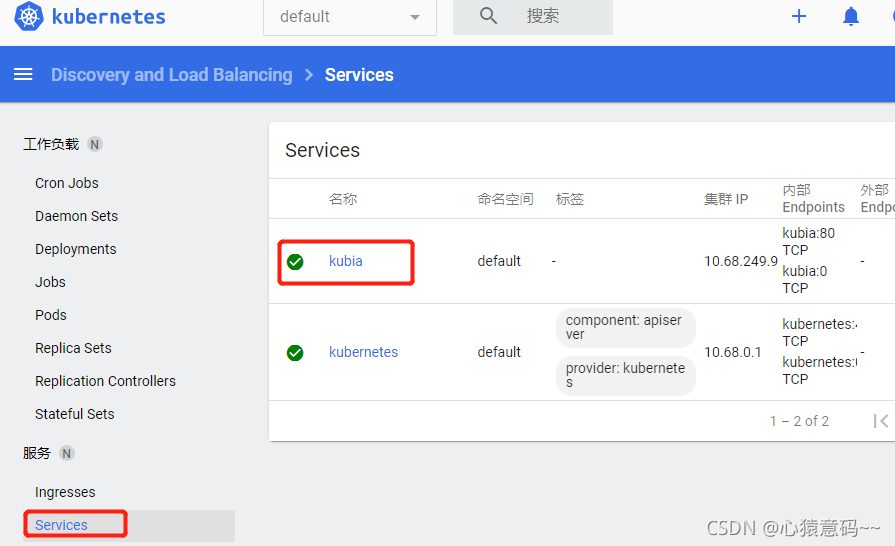

- 如果没有pod具有app:kubia标签,可以创建前面的ReplicaSet资源,并让RS自动创建pod
k create -f kubia-replicaset.yml


- 从内部网络访问Service
- 执行
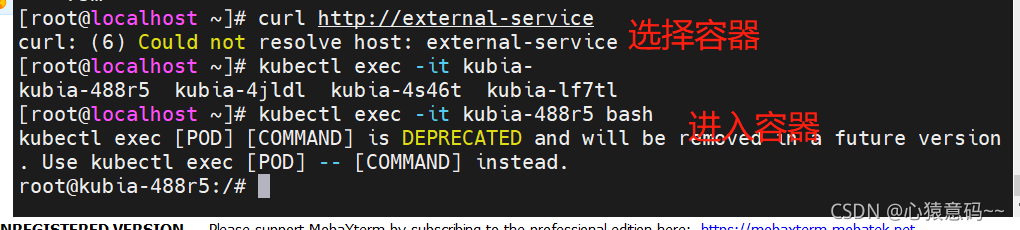
curl http://10.68.249.99来访问Service - 执行多次会看到,Service会在多个pod中轮训发送请求
[root@localhost ~]# k get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.68.0.1 <none> 443/TCP 32m
kubia ClusterIP 10.68.249.99 <none> 80/TCP 3m24s
[root@localhost ~]# curl http://10.68.249.99
curl: (7) Failed to connect to 10.68.249.99 port 80: 拒绝连接
[root@localhost ~]# curl http://10.68.249.99
You've hit kubia-4jldl
[root@localhost ~]# curl http://10.68.249.99
You've hit kubia-lf7tl
[root@localhost ~]# curl http://10.68.249.99
You've hit kubia-4s46t
[root@localhost ~]# curl http://10.68.249.99
You've hit kubia-4s46t
[root@localhost ~]#
- 回话亲和性
- 来自同一个客户端的请求,总是发给同一个pod
cat <<EOF > kubia-svc-clientip.yml
apiVersion: v1
kind: Service
metadata:
name: kubia-clientip
spec:
sessionAffinity: ClientIP # 回话亲和性使用ClientIP
ports:
- port: 80
targetPort: 8080
selector:
app: kubia
EOF
k create -f kubia-svc-clientip.yml
k get svc
------------------------------------------------------------------------
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.68.0.1 <none> 443/TCP 2d12h
kubia ClusterIP 10.68.163.98 <none> 80/TCP 38m
kubia-clientip ClusterIP 10.68.72.120 <none> 80/TCP 2m15s
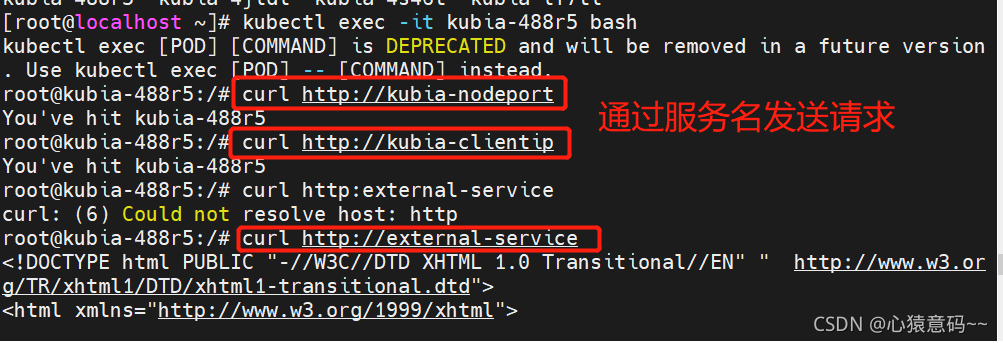
# 进入kubia-5zm2q容器,向Service发送请求
# 执行多次会看到,每次请求的都是同一个pod
curl http://10.68.72.120
- 在pod中,可以通过一个环境变量来获知Service的ip地址
- 该环境变量在旧的pod中是不存在的,我们需要先删除旧的pod,用新的pod来替代
k delete po --all
k get po
-----------------------------------------------
NAME READY STATUS RESTARTS AGE
kubia-k66lz 1/1 Running 0 64s
kubia-vfcqv 1/1 Running 0 63s
kubia-z257h 1/1 Running 0 63s

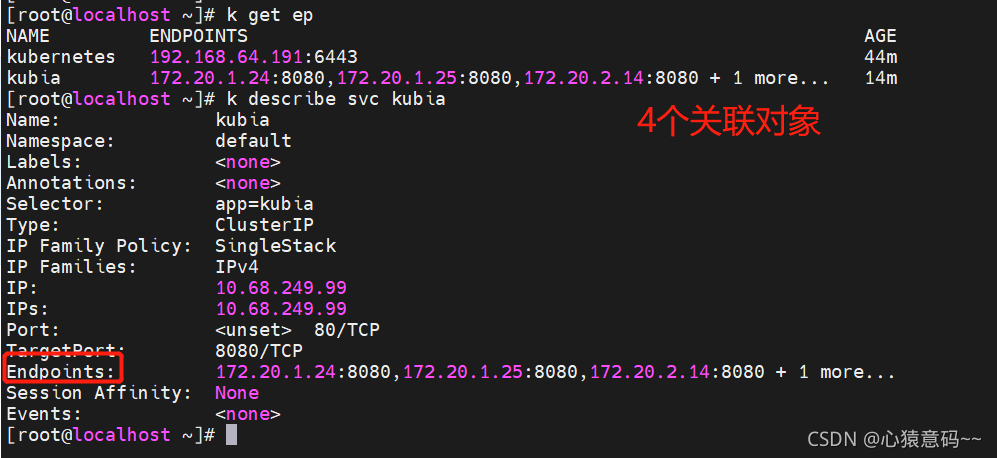
endpoint
endpoint是在Service和pod之间的一种资源
一个endpoint资源,包含一组pod的地址列表
# 查看kubia服务的endpoint
k describe svc kubia
------------------------------
......
Endpoints: 172.20.2.40:8080,172.20.3.57:8080,172.20.3.58:8080
......
# 查看所有endpoint
k get ep
--------------------------------------------------------------------------
NAME ENDPOINTS AGE
kubia 172.20.2.40:8080,172.20.3.57:8080,172.20.3.58:8080 95m
kubia-clientip 172.20.2.40:8080,172.20.3.57:8080,172.20.3.58:8080 59m
# 查看名为kubia的endpoint
k get ep kubia
当service转发请求时,就会创建endpoint


- 不含pod选择器的服务,不会创建 endpoint
cat <<EOF > external-service.yml
apiVersion: v1
kind: Service
metadata:
name: external-service # Service命名
spec:
ports:
- port: 80
EOF
# 创建没有选择器的 Service,不会创建Endpoint
k create -f external-service.yml
# 查看Service
k get svc
# 通过内部网络ip访问Service,没有Endpoint地址列表,会拒绝连接
curl http://10.68.228.157
#因为没有ip绑定endpoint
k describe svc external-service
- 创建endpoint关联到Service,它的名字必须与Service同名
cat <<EOF > external-service-endpoints.yml
apiVersion: v1
kind: Endpoints # 资源类型
metadata:
name: external-service # 名称要与Service名相匹配
subsets:
- addresses: # 包含的地址列表
- ip: 120.52.99.224 # 中国联通的ip地址
- ip: 117.136.190.162 # 中国移动的ip地址
ports:
- port: 80 # 目标服务的的端口
EOF
# 创建Endpoint
k create -f external-service-endpoints.yml
# 进入一个pod容器
k exec -it kubia-k66lz bash
# 访问 external-service
# 多次访问,会在endpoints地址列表中轮训请求移动或者联通
# curl http://external-service
curl http://10.68.228.157
服务暴露给客户端
前面创建的Service只能在集群内部网络中访问,那么怎么让客户端来访问Service呢?
三种方式
- NodePort
- 每个节点都开放一个端口
- LoadBalance
- NodePort的一种扩展,负载均衡器需要云基础设施来提供
- Ingress
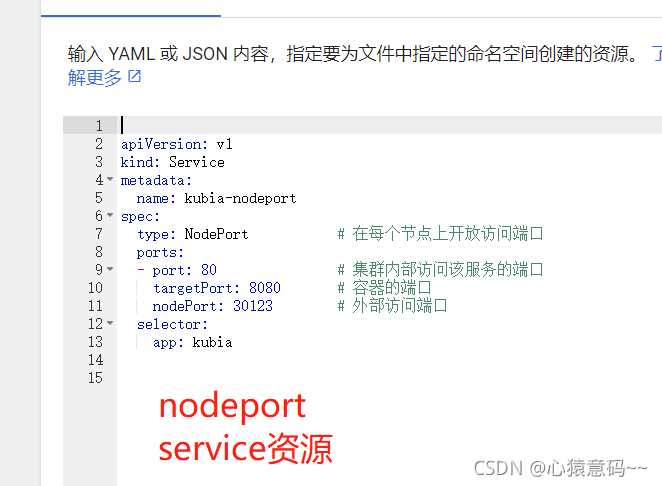
NodePort
- 在每个节点(包括master),都开放一个相同的端口,可以通过任意节点的端口来访问Service
cat <<EOF > kubia-svc-nodeport.yml
apiVersion: v1
kind: Service
metadata:
name: kubia-nodeport
spec:
type: NodePort # 在每个节点上开放访问端口
ports:
- port: 80 # 集群内部访问该服务的端口
targetPort: 8080 # 容器的端口
nodePort: 30123 # 外部访问端口
selector:
app: kubia
EOF
- 创建并查看 Service
k create -f kubia-svc-nodeport.yml
k get svc kubia-nodeport
-----------------------------------------------------------------------------
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubia-nodeport NodePort 10.68.140.119 <none> 80:30123/TCP 14m
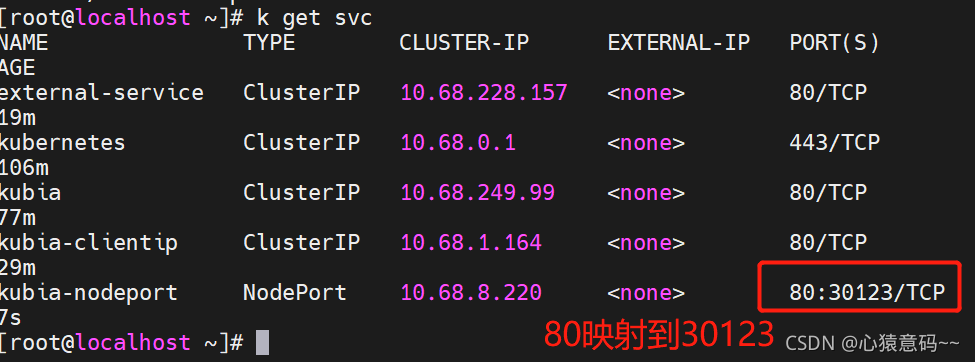
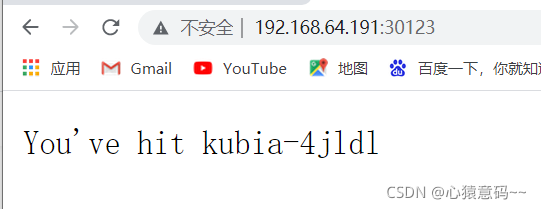
可以通过任意节点的30123端口来访问 Service
- http://192.168.64.191:30123
- http://192.168.64.192:30123
- http://192.168.64.193:30123

11 磁盘挂载到容器--卷
卷的类型:
- emptyDir: 简单的空目录
- hostPath: 工作节点中的磁盘路径
- gitRepo: 从git克隆的本地仓库
- nfs: nfs共享文件系统
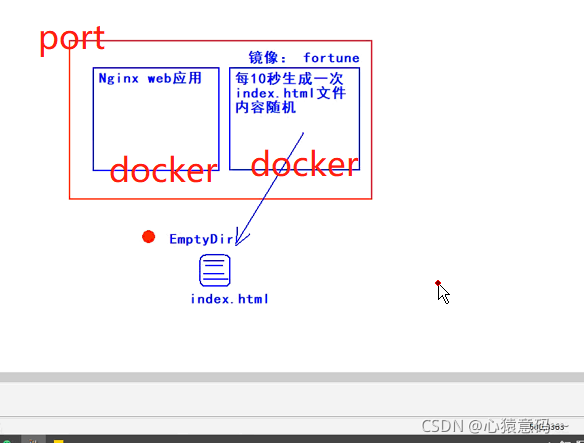
创建临时存储目录emptyDir,包含两个容器的pod, 它们共享同一个卷

cat <<EOF > fortune-pod.yml
apiVersion: v1
kind: Pod
metadata:
name: fortune
labels:
app: fortune
spec:
containers:
- image: luksa/fortune # 镜像名
name: html-genrator # 容器名
imagePullPolicy: Never
volumeMounts:
- name: html # 卷名为 html
mountPath: /var/htdocs # 容器中的挂载路径
- image: nginx:alpine # 第二个镜像名
name: web-server # 第二个容器名
imagePullPolicy: Never
volumeMounts:
- name: html # 相同的卷 html
mountPath: /usr/share/nginx/html # 在第二个容器中的挂载路径
readOnly: true # 设置为只读
ports:
- containerPort: 80
protocol: TCP
volumes: # 卷
- name: html # 为卷命名
emptyDir: {} # emptyDir类型的卷
EOF
k create -f fortune-pod.yml
k get po


#查看html容器的详细信息,找到挂载目录并进入,看看是否有index.html文件
docker inspect faff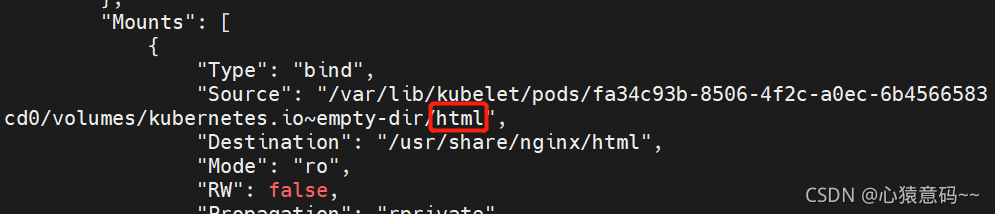

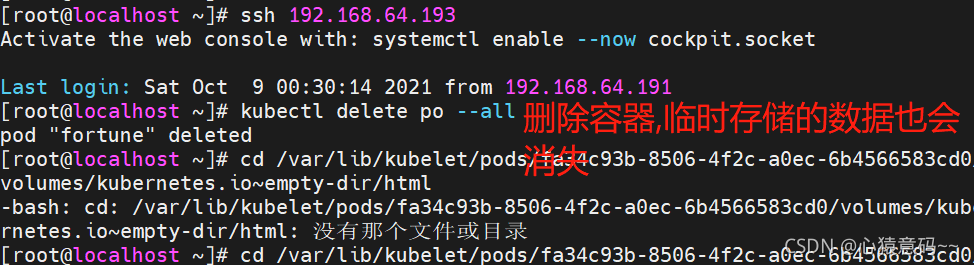
- 创建Service, 通过这个Service访问pod的80端口
cat <<EOF > fortune-svc.yml
apiVersion: v1
kind: Service
metadata:
name: fortune
spec:
type: NodePort
ports:
- port: 8088
targetPort: 80
nodePort: 38088
selector:
app: fortune
EOF
k create -f fortune-svc.yml
k get svc
# 用浏览器访问 http://192.168.64.191:38088/
NFS 文件系统
- 在191/192/193 三台服务器上安装 nfs:
dnf install nfs-utils
- 在 master 节点 192.168.64.191 上创建 nfs 目录
/etc/nfs_data, - 并允许 1921.68.64 网段的主机共享访问这个目录
# 创建文件夹
mkdir /etc/nfs_data
# 在exports文件夹中写入配置
# no_root_squash: 服务器端使用root权限
cat <<EOF > /etc/exports
/etc/nfs_data 192.168.64.0/24(rw,async,no_root_squash)
EOF
systemctl enable nfs-server
systemctl enable rpcbind
systemctl start nfs-server
systemctl start rpcbind

- 尝试在客户端主机上,例如192.168.64.192,挂载远程的nfs目录
# 新建挂载目录
mkdir /etc/web_dir/
# 在客户端, 挂载服务器的 nfs 目录
mount -t nfs 192.168.64.191:/etc/nfs_data /etc/web_dir/
持久化存储

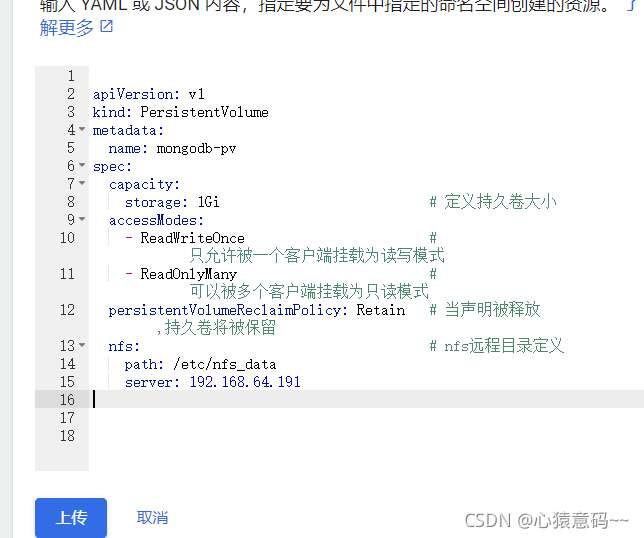
PersistentVolume(PV)用于为用户和管理员提供如何提供和消费存储的API,PV由管理员在集群中提供的存储。
- 可以使用命令行或者kubernetes Dashbord控制台 创建 PersistentVolume - 持久卷资源
cat <<EOF > mongodb-pv.yml
apiVersion: v1
kind: PersistentVolume
metadata:
name: mongodb-pv
spec:
capacity:
storage: 1Gi # 定义持久卷大小
accessModes:
- ReadWriteOnce # 只允许被一个客户端挂载为读写模式
- ReadOnlyMany # 可以被多个客户端挂载为只读模式
persistentVolumeReclaimPolicy: Retain # 当声明被释放,持久卷将被保留
nfs: # nfs远程目录定义
path: /etc/nfs_data
server: 192.168.64.191
EOF
# 创建持久卷
k create -f mongodb-pv.yml
# 查看持久卷,此时没有创建持久卷声明,claim栏是没有关联的pvc
k get pv
----------------------------------------------------------------------------------------------------------
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
mongodb-pv 1Gi RWO,ROX Retain Available 4s
或者:
持久卷声明
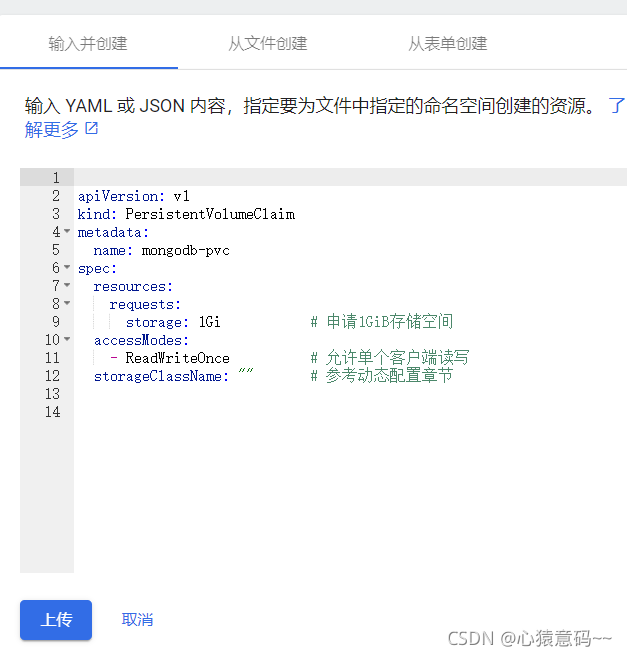
- 使用持久卷声明,使应用与底层存储技术解耦
PersistentVolumeClaim(简称PVC)是用户存储的请求,PVC消耗PV的资源,可以请求特定的大小和访问模式,需要指定归属于某个Namespace,在同一个Namespace的Pod才可以指定对应的PVC。
cat <<EOF > mongodb-pvc.yml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: mongodb-pvc
spec:
resources:
requests:
storage: 1Gi # 申请1GiB存储空间
accessModes:
- ReadWriteOnce # 允许单个客户端读写
storageClassName: "" # 参考动态配置章节
EOF
k create -f mongodb-pvc.yml
k get pvc
-----------------------------------------------------------------------------------
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
mongodb-pvc Bound mongodb-pv 1Gi RWO,ROX 3s

- 启动mongdb容器
cat <<EOF > mongodb-pod-pvc.yml
apiVersion: v1
kind: Pod
metadata:
name: mongodb
spec:
containers: # mongdb镜像
- image: mongo
name: mongodb
imagePullPolicy: Never
securityContext:
runAsUser: 0
volumeMounts: #数据卷存储路径
- name: mongodb-data
mountPath: /data/db
ports:
- containerPort: 27017
protocol: TCP
volumes:
- name: mongodb-data
persistentVolumeClaim:
claimName: mongodb-pvc # 引用之前创建的"持久卷声明"
EOF
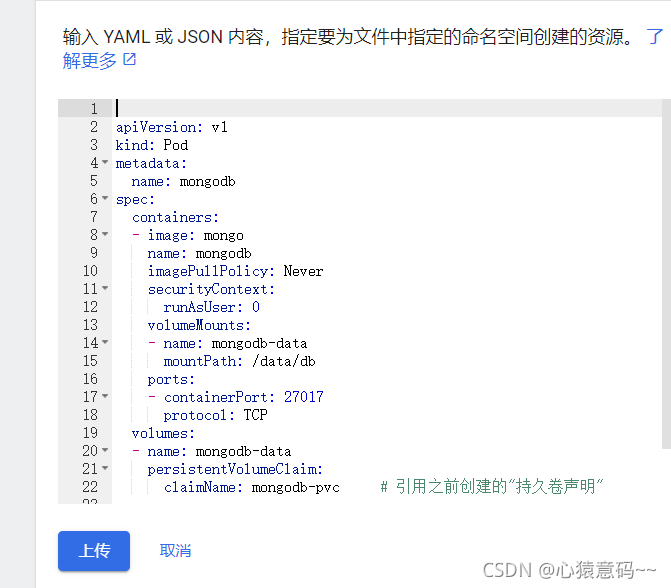
- 验证 pod 中加挂载了 nfs 远程目录作为持久卷
k create -f mongodb-pod-pvc.yml
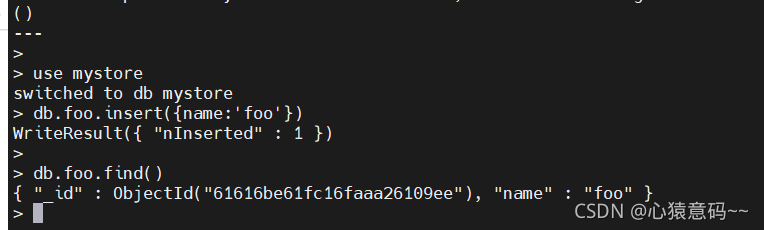
k exec -it mongodb mongo
use mystore #使用mystore数据库
db.foo.insert({name:'foo'}) #向foo表插入数据
db.foo.find()
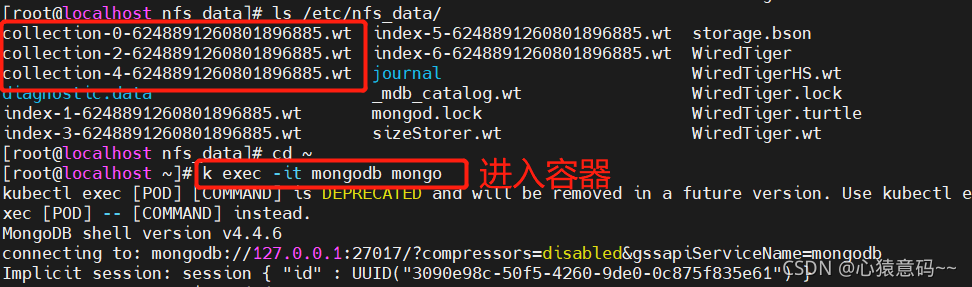
- 查看在 nfs 远程目录中的文件
cd /etc/nfs_data
ls
12 配置启动参数
12.1 docker 的命令行参数
Dockerfile中定义命令和参数的指令
ENTRYPOINT启动容器时,在容器内执行的命令CMD对启动命令传递的参数
CMD可以在docker run命令中进行覆盖
例如:
......
ENTRYPOINT ["java", "-jar", "/opt/sp05-eureka-0.0.1-SNAPSHOT.jar"]
CMD ["--spring.profiles.active=eureka1"]
- 启动容器时,可以执行:
docker run <image>
- 或者启动容器时覆盖CMD
docker run <image> --spring.profiles.active=eureka2
12.2 k8s中覆盖docker的ENTRYPOINT和CMD
command可以覆盖ENTRYPOINTargs可以覆盖CMD
在镜像luksa/fortune:args中,设置了自动生成内容的间隔时间参数为10秒
......
CMD ["10"]

- 启动fortune-pod-args的docker容器时可以通过k8s的
args来覆盖docker的CMD 设置的间隔时间 ,改为两秒,每两秒生成一个文件
cat <<EOF > fortune-pod-args.yml
apiVersion: v1
kind: Pod
metadata:
name: fortune
labels:
app: fortune
spec:
containers:
- image: luksa/fortune:args
args: ["2"] # docker镜像中配置的CMD是10,这里用args把这个值覆盖成2
name: html-genrator
imagePullPolicy: Never
volumeMounts:
- name: html
mountPath: /var/htdocs
- image: nginx:alpine
name: web-server
imagePullPolicy: Never
volumeMounts:
- name: html
mountPath: /usr/share/nginx/html
readOnly: true
ports:
- containerPort: 80
protocol: TCP
volumes:
- name: html
emptyDir: {}
EOF
k create -f fortune-pod-args.yml
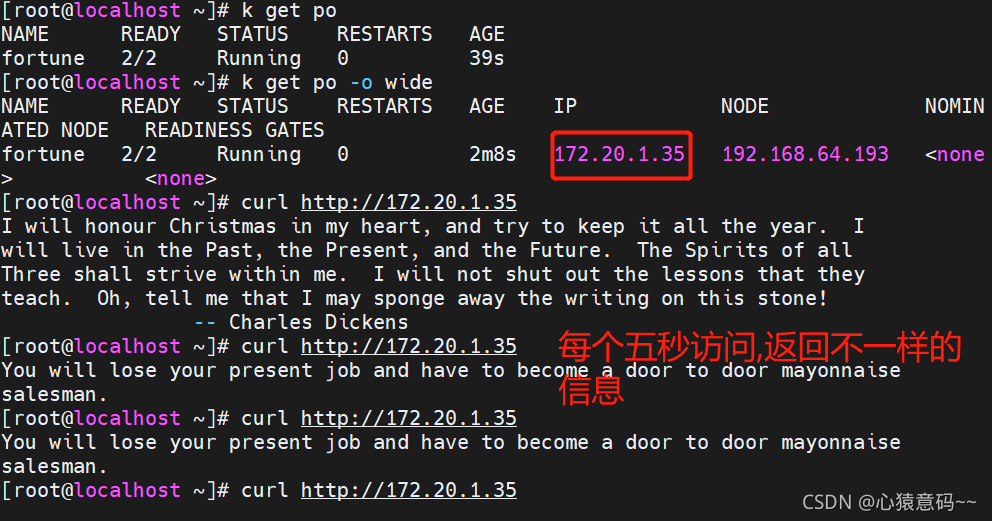
# 查看pod
k get po -o wide
--------------------------------------------------------------------------------------------------------------
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
fortune 2/2 Running 0 34s 172.20.2.55 192.168.64.192 <none> <none>
重复地执行curl命令,访问该pod,会看到数据每2秒刷新一次
注意要修改成你的pod的ip
curl http://172.20.2.55具体操作步骤:

kubernetes 控制台部署容器:

12.3 环境变量INTERVAL来指定内容生成的间隔时间
在镜像luksa/fortune:env中通过环境变量INTERVAL来指定内容生成的间隔时间
下面配置中,通过env配置,在容器中设置了环境变量INTERVAL的值
cat <<EOF > fortune-pod-env.yml
apiVersion: v1
kind: Pod
metadata:
name: fortune
labels:
app: fortune
spec:
containers:
- image: luksa/fortune:env
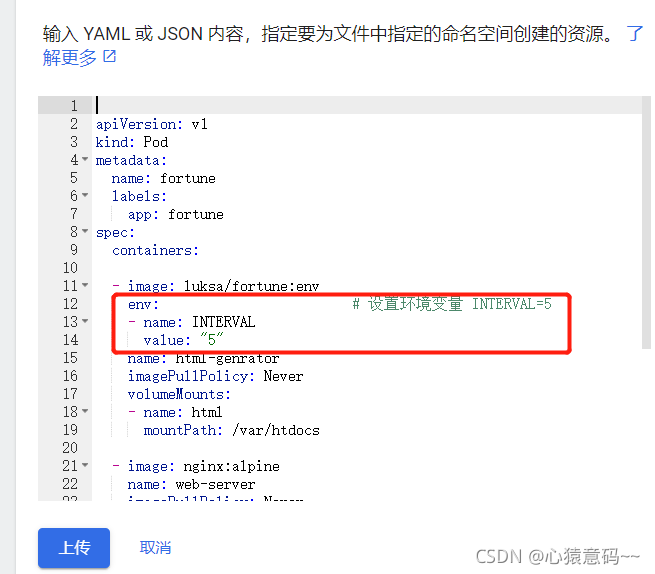
env: # 设置环境变量 INTERVAL=5
- name: INTERVAL
value: "5"
name: html-genrator
imagePullPolicy: Never
volumeMounts:
- name: html
mountPath: /var/htdocs
- image: nginx:alpine
name: web-server
imagePullPolicy: Never
volumeMounts:
- name: html
mountPath: /usr/share/nginx/html
readOnly: true
ports:
- containerPort: 80
protocol: TCP
volumes:
- name: html
emptyDir: {}
EOF
k delete po fortune
k create -f fortune-pod-env.yml
# 查看pod
k get po -o wide
--------------------------------------------------------------------------------------------------------------
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
fortune 2/2 Running 0 8s 172.20.2.56 192.168.64.192 <none> <none>
# 进入pod
k exec -it fortune bash
# 查看pod的环境变量
env
------------
INTERVAL=5
......
# 从pod推出,回到宿主机
exit
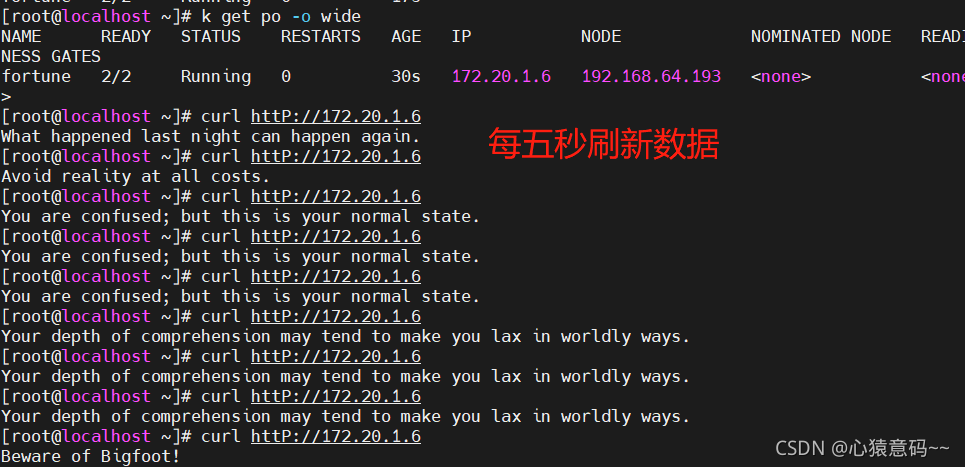
重复地执行curl命令,访问该pod,会看到数据每5秒刷新一次
注意要修改成你的pod的ip:
curl http://172.20.2.56具体步骤:
12.4 ConfigMap
通过ConfigMap资源,可以从pod中把环境变量配置分离出来,是环境变量配置与pod解耦
可以从命令行创建ConfigMap资源:
# 直接命令行创建
k create configmap fortune-config --from-literal=sleep-interval=20
或者从部署文件创建ConfigMap:
# 或从文件创建
cat <<EOF > fortune-config.yml
apiVersion: v1
kind: ConfigMap
metadata:
name: fortune-config
data:
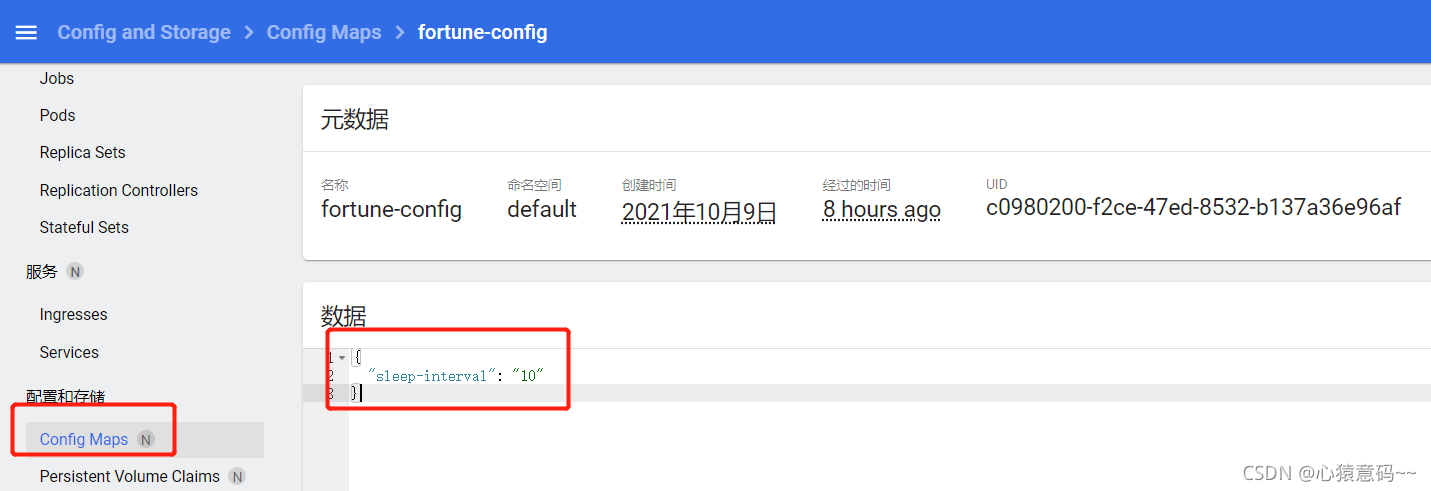
sleep-interval: "10"
EOF
# 创建ConfigMap
k create -f fortune-config.yml
# 查看ConfigMap的配置
k get cm fortune-config -o yaml
从ConfigMap获取配置数据,设置为pod的环境变量
cat <<EOF > fortune-pod-env-configmap.yml
apiVersion: v1
kind: Pod
metadata:
name: fortune
labels:
app: fortune
spec:
containers:
- image: luksa/fortune:env
imagePullPolicy: Never
env:
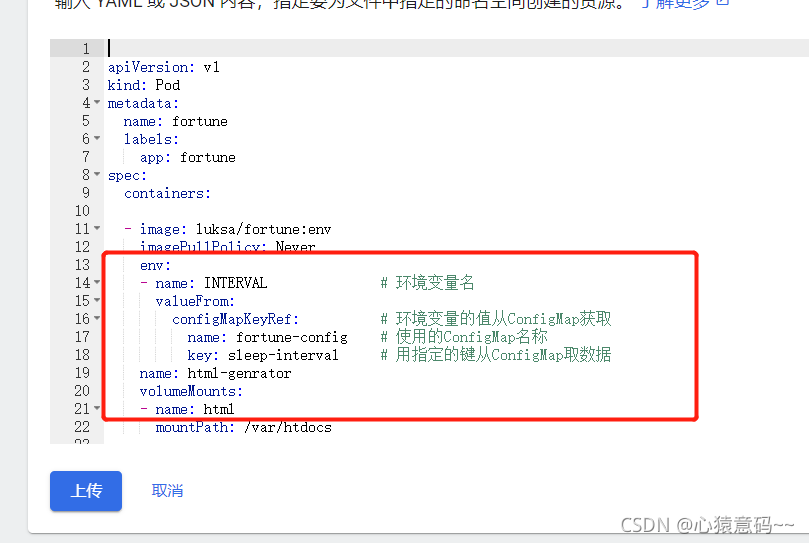
- name: INTERVAL # 环境变量名
valueFrom:
configMapKeyRef: # 环境变量的值从ConfigMap获取
name: fortune-config # 使用的ConfigMap名称
key: sleep-interval # 用指定的键从ConfigMap取数据
name: html-genrator
volumeMounts:
- name: html
mountPath: /var/htdocs
- image: nginx:alpine
imagePullPolicy: Never
name: web-server
volumeMounts:
- name: html
mountPath: /usr/share/nginx/html
readOnly: true
ports:
- containerPort: 80
protocol: TCP
volumes:
- name: html
emptyDir: {}
EOF
具体操作步骤:



12.5 config-map–>env–>arg
配置环境变量后,可以在启动参数中使用环境变量
cat <<EOF > fortune-pod-args.yml
apiVersion: v1
kind: Pod
metadata:
name: fortune
labels:
app: fortune
spec:
containers:
- image: luksa/fortune:args
imagePullPolicy: Never
env:
- name: INTERVAL
valueFrom:
configMapKeyRef:
name: fortune-config
key: sleep-interval
args: ["\$(INTERVAL)"] # 启动参数中使用环境变量
name: html-genrator
volumeMounts:
- name: html
mountPath: /var/htdocs
- image: nginx:alpine
imagePullPolicy: Never
name: web-server
volumeMounts:
- name: html
mountPath: /usr/share/nginx/html
readOnly: true
ports:
- containerPort: 80
protocol: TCP
volumes:
- name: html
emptyDir: {}
EOF
- 从磁盘文件创建 ConfigMap
- 先删除之前创建的ComfigMap
d delete cm fortune-config
- 创建一个文件夹,存放配置文件
cd ~/
mkdir configmap-files
cd configmap
- 创建nginx的配置文件,启用对文本文件和xml文件的压缩
cat <<EOF > my-nginx-config.conf
server {
listen 80;
server_name www.kubia-example.com;
gzip on;
gzip_types text/plain application/xml;
location / {
root /ur/share/nginx/html;
index index.html index.htm;
}
}
EOF
- 添加
sleep-interval文件,写入值25
cat <<EOF > sleep-interval
25
EOF
- 从configmap-files文件夹创建ConfigMap
cd ~/
k create configmap fortune-config \
--from-file=configmap-files
13 Deployment
Deployment 是一种更高级的资源,用于部署或升级应用.
创建Deployment时,ReplicaSet资源会自动随之创建,实际Pod是由ReplicaSet创建和管理,而不是由Deployment直接管理
Deployment可以在应用滚动升级过程中, 引入另一个RepliaSet, 并协调两个ReplicaSet.
cat <<EOF > kubia-deployment-v1.yml
apiVersion: apps/v1
kind: Deployment
metadata:
name: kubia
spec:
replicas: 3
selector:
matchLabels:
app: kubia
template:
metadata:
name: kubia
labels:
app: kubia
spec:
containers:
- image: luksa/kubia:v1 #v1版本镜像
imagePullPolicy: Never
name: nodejs
EOF
k create -f kubia-deployment-v1.yml --record
k get deploy
-----------------------------------------------
NAME READY UP-TO-DATE AVAILABLE AGE
kubia 3/3 3 3 2m35s
k get rs
----------------------------------------------------
NAME DESIRED CURRENT READY AGE
kubia-66b4657d7b 3 3 3 3m4s
k get po
------------------------------------------------------------
NAME READY STATUS RESTARTS AGE
kubia-66b4657d7b-f9bn7 1/1 Running 0 3m12s
kubia-66b4657d7b-kzqwt 1/1 Running 0 3m12s
kubia-66b4657d7b-zm4xd 1/1 Running 0 3m12s
k rollout status deploy kubia
------------------------------------------
deployment "kubia" successfully rolled out

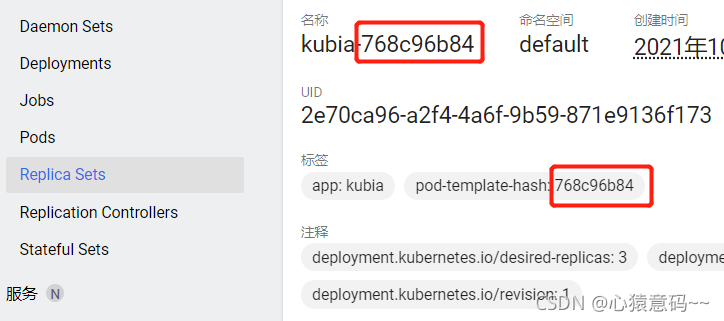
rs 和 pod 名称中的数字,是 pod 模板的哈希值:
具体操作:


13.1 升级 Deployment
只需要在 pod 模板中修改镜像的 Tag, Deployment 就可以自动完成升级过程
Deployment的升级策略
- 滚动升级 Rolling Update - 渐进的删除旧的pod, 同时创建新的pod, 这是默认的升级策略
- 重建 Recreate - 一次删除所有旧的pod, 再重新创建新的pod
minReadySeconds设置为10秒, 减慢滚动升级速度, 便于我们观察升级的过程.
k patch deploy kubia -p '{"spec": {"minReadySeconds": 10}}'触发滚动升级
修改 Deployment 中 pod 模板使用的镜像就可以触发滚动升级
为了便于观察, 在另一个终端中执行循环, 通过 service 来访问pod
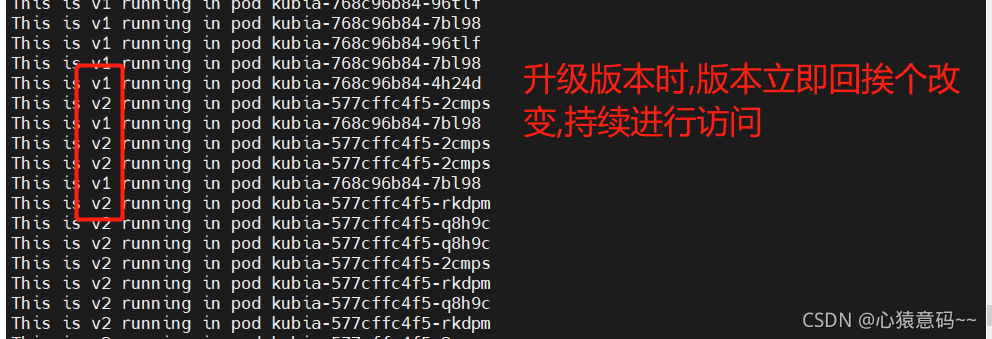
while true; do curl http://192.168.64.191:30123; sleep 0.5s; done
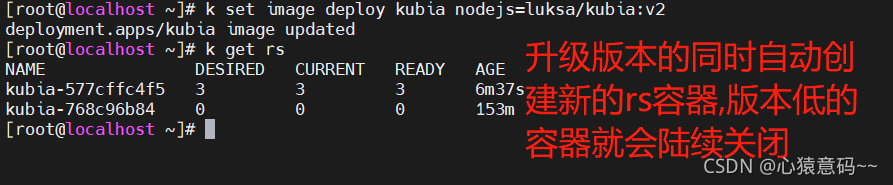
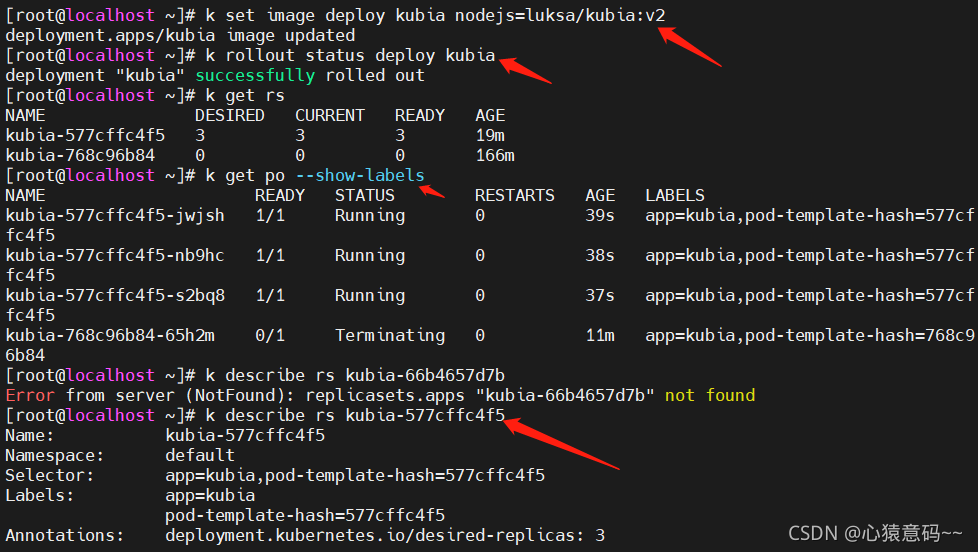
k set image deploy kubia nodejs=luksa/kubia:v2
通过不同的命令来了解升级的过程和原理
k rollout status deploy kubia
k get rs
k get po --show-labels
k describe rs kubia-66b4657d7b
具体操作:
第一步:先创建一个service,用于转发调用请求

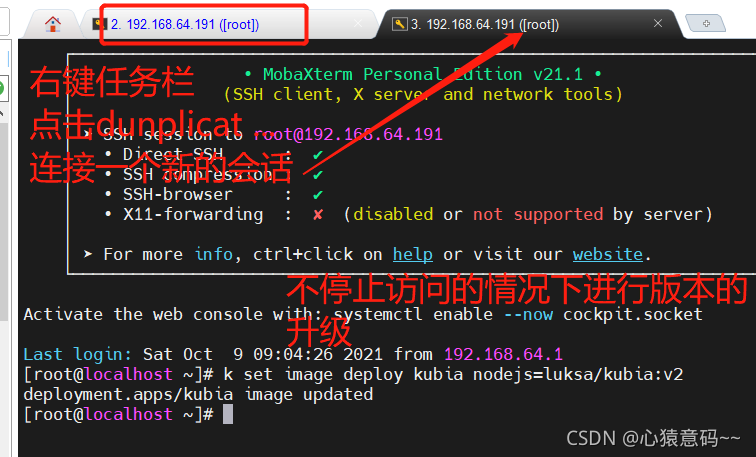
- 右键任务栏,点击Duplicate tab,连接新会话进行版本升级

13.2 回滚 Deployment
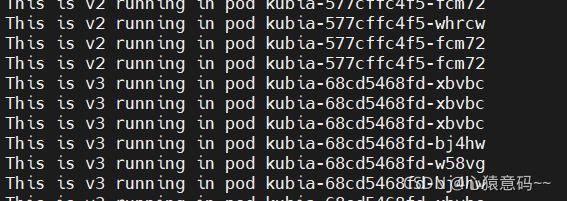
luksa/kubia:v3 镜像中的应用模拟一个 bug, 从第5次请求开始, 会出现 500 错误
k set image deploy kubia nodejs=luksa/kubia:v3
手动回滚到上一个版本
k rollout undo deploy kubia
另一个会话框:
13.3 控制滚动升级速率
滚动升级时
- 先创建新版本pod
- 再销毁旧版本pod
可以通过参数来控制, 每次新建的pod数量和销毁的pod数量:
maxSurge - 默认25%
- 允许超出的 pod 数量.
- 如果期望pod数量是4, 滚动升级期间, 最多只允许实际有5个 pod.
maxUnavailable - 默认 25%
- 允许有多少个 pod容器处于不可用状态.
- 如果期望pod数量是4, 滚动升级期间, 最多只允许 1 个 pod 不可用, 也就是说任何时间都要保持至少有 3 个可用的pod.
查看参数
k get deploy -o yaml
--------------------------------
......
strategy:
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
type: RollingUpdate
......13.4 暂停滚动升级
将 image 升级到 v4 版本触发更新, 并立即暂停更新.
这时会有一个新版本的 pod 启动, 可以暂停更新过程, 让少量用户可以访问到新版本, 并观察其运行是否正常.
根据新版本的运行情况, 可以继续完成更新, 或回滚到旧版本.
k set image deploy kubia nodejs=luksa/kubia:v4
# 暂停
k rollout pause deploy kubia
# 继续
k rollout resume deploy kubia
金丝雀升级策略:


- 如果没有问题,执行继续升级命令

- 如果允许状态出现错误,执行回退版本命令
k rollout undo deploy kubia13.5 自动阻止出错版本升级
minReadySeconds
- 新创建的pod成功运行多久后才,继续升级过程
- 在该时间段内, 如果容器的就绪探针返回失败, 升级过程将被阻止
修改Deployment配置,添加就绪探针
cat <<EOF > kubia-deployment-v3-with-readinesscheck.yml
apiVersion: apps/v1
kind: Deployment
metadata:
name: kubia
spec:
replicas: 3
selector:
matchLabels:
app: kubia
minReadySeconds: 10
strategy:
rollingUpdate:
maxSurge: 1
maxUnavailable: 0
type: RollingUpdate
template:
metadata:
name: kubia
labels:
app: kubia
spec:
containers:
- image: luksa/kubia:v3 #v3版本,有故障,第五次会出错
name: nodejs
imagePullPolicy: Never
readinessProbe:
periodSeconds: 1 #每一秒探测一次
httpGet:
path: /
port: 8080
EOF
k apply -f kubia-deployment-v3-with-readinesscheck.yml
就绪探针探测间隔设置成了 1 秒, 第5次请求开始每次请求都返回500错, 容器会处于未就绪状态. minReadySeconds被设置成了10秒, 只有pod就绪10秒后, 升级过程才会继续.所以这是滚动升级过程会被阻塞, 不会继续进行.
默认升级过程被阻塞10分钟后, 升级过程会被视为失败, Deployment描述中会显示超时(ProgressDeadlineExceeded).
k describe deploy kubia
-----------------------------
......
Conditions:
Type Status Reason
---- ------ ------
Available True MinimumReplicasAvailable
Progressing False ProgressDeadlineExceeded
......
- 这时只能通过手动执行 rollout undo 命令进行回滚
k rollout undo deploy kubia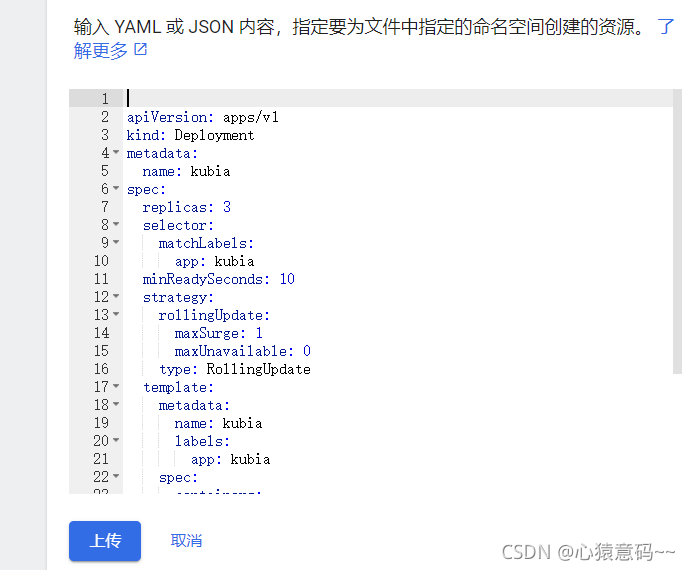















 190
190











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









