









1.排序的术语及记号
排序关键码:可以是任何一种可比的数据类型(字符、字符串、整数实数等)。
对于任何一种记录都可以找到一个取得它关键码的函数。
稳定性:不改变具有相同关键码的记录的原始输入顺序。
2.三种代价为Θ(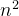 )的排序方法(插入、冒泡、选择)
)的排序方法(插入、冒泡、选择)
Ⅰ插入排序:逐个处理待排序的记录,每个新记录与前面已排序的子序列进行比较,将它插入到子序列的正确位置。输入为一个记录数组,其中存放着n个记录。
代码:
// 插入排序法
static int[] insertionsort(int[] array){
if (array.length>0){
for(int i=0;i<array.length;i++){
int current=array[i+1];
int index =i;
while (index>=0&& current<array[index]){
array[index+1]=array[index];
index--;
}
array[index+1]=current;
}
}
return array;
}外层循环进行n-1次,内层最差需要n-1次,故Θ()为最差,最佳为Θ(n),平均为Θ(
)
。
逆置:某数字前比他大的数。每一个这样的数称为一个逆置。
Ⅱ冒泡排序:双重for循环,内循环从数组的底部比较的顶部,比较相邻的关键码。如果下面的关键码比其上邻居的关键码小,则将二者交换顺序。
代码:
static int[] bubblesort(int[] array){
if(array.length>0){
for (int i=0;i<array.length-1;i++){
for(int j=0;j<array.length-1-i;j++){
if (array[j]>array[j+1]){
int temp=array[j];
array[j]=array[j+1];
array[j+1]=temp;
}
}
}
}
return array;
}
}双重循环,最差与平均均为Θ(),最好为Θ(n)。
Ⅲ选择排序:遍历数组,将最小的元素与第一个元素交换,再遍历数组,将最小的元素与第二个元素交换,每次遍历时不发生交换只有遍历结束后才发生交换。
代码:
public int[] selctingsort(int[] array) {
for (int i=0;i<array.length;i++){
int minnum=i;
for (int j=i;j<array.length;j++){
if(array[j]<array[minnum]){
minnum=j;
}
}
if(minnum!=i){
int temp=array[i];
array[i]=array[minnum];
array[minnum]=temp;
}
}
return array;
}无论如何都要进行双重循环,即使不进行交换,故平均最好最坏均为Θ(n方)。
交换(交换相邻记录叫做一次交换)排序算法的时间代价:
上面三种排序算法运行较慢的关键原因是只比较相邻的元素,因此比较和移动只能一步一步的进行。任何一种将比较限制在相邻两个元素之间进行的交换算法的平均时间代价都是Θ(n方)。
3.Shell排序(缩小增量排序法)
插入排序中如果插入的是较小的数时,需要后移的次数明显增多,影响效率。故需要寻找新的算法。
描述:将序列分成子序列,然后分别对子序列进行排序最后对子序列组合起来。(试图将待排序列变成近似序列状态再用插入排序完成最后的排序工作)
1每一次循环时靶序列分为互不相连的子序列且各个子序列中的元素在整个数组中的间距相同(即按照相同的间隔取子序列且其长度相同)。
代码:
1--交换式(内部为冒泡)
public int[] shellsort(int[] array){
int temp=0;
for(int gap=array.length;gap>0;gap=gap/2){
for (int i=gap;i<array.length;i++){
for (int j=i-gap;j>=0;j=j-gap){
if(array[j]>array[j+gap]){
temp=array[j];
array[j]=array[j+gap];
array[j+gap]=temp;
}
}
}
}
return array;
}
2--移位式(内部为插入) 真正的希尔排序
public static int[] shellsort2(int[] arrary){
for (int gap=arrary.length/2;gap>0;gap/=2){
for (int i=gap;i<arrary.length;i++) {
int j = i;
int temp = arrary[j];
if (arrary[j] < arrary[j - gap]) {
while (j - gap >= 0 && temp < arrary[j - gap]) {
arrary[j] = arrary[j - gap];
j = j - gap;
}
arrary[j]=temp;
}
}
}
return arrary;
}最佳平均最差均为Θ(nlog2n)。
4.快速排序
快速排序是对冒泡排序的一种改进。选定一个基准数(轴数v)将待排记录分成大于基准数与小于基准数的两部分,并对左右两部分分别递归排序。
代码:
实现一
public static int[] QuickSortv1(int[] array, int low, int hight) {
//if (array.length < 1 || low < 0 || hight >= array.length || low > hight) return null;
if (low < hight) {
int privotpos = partition(array, low, hight);
QuickSortv1(array, low, privotpos - 1);
QuickSortv1(array, privotpos + 1, hight);
}
return array;
}
//the method below is used in quicksort
public static int partition(int[] array, int low, int hight) {
int privot = array[low];
while (low < hight) {
while (low < hight && array[hight] >= privot) --hight;
array[low] = array[hight];
while (low < hight && array[low] <= privot) ++low;
array[hight] = array[low];
}
array[low] = privot;
return low;
}实现二:
public static int[] QuickSortv2(int[]array,int left,int right) {
int l = left;
int r = right;
int v = array[(left + right) / 2];
int temp = 0;
// the while block below aims to makes the smaller numbers put int the left and
//the larger put in the right (smaller or larger than the v value)
while (l < r) {
// search for the larger num from the left
while (array[l] < v) {
l += 1;
}
// search for the smaller num for the right
while (array[r] > v) {
r -= 1;
}
//if l>=r, meaning that nums on the left are all smaller or equal to v value
// and the nums on the right are all lager or equal to v value
if (l >= r) {
break;
}
//things are not always that good for us, so we need to do the swap to move the smaller to the left
// and the lager to the right.
temp = array[l];
array[l] = array[r];
array[r] = temp;
//if arr[l]==v after swapping, do r-- to move back;
if (array[l] == v) {
r -= 1;
}
//iff arr[r]==v after swapping, do l++ to move forward
if (array[r] == v) {
l += 1;
}
}
// if l==r, must do l++ and r--, or the stock will overflow
if(l==r){
l+=1;
r-=1;
}
// do the same sort on the left and right sub-array
if(left<r){
QuickSortv2(array,left,right);
}
if(right>1){
QuickSortv2(array,1,right);
}
return array;
}分析:最好情况与平均情况为Θ(nlogn),最差情况为Θ(n方)
5.归并排序
归并排序基于分治法,将待排序的元素序列分成两个长度相等的子序列,为每一个子序列排序后再将他们合并成一个子序列。归并排序是稳定的排序算法,最好最坏平均情况均为Θ(nlog2n)
先写一个处理两个子序列排序的方法:将左右两边的数据按照规则填充到temp数组内,直到左右两边的有序序列有一边处理完毕为止。将左右两侧数组从左边开始第一个数字与右边数组的第一个数字比较,如果左边的数字小,则将其加入到temp数组内,反之则将右边的数字加到数组内,完成加入的左边或右边的下标与temp的下标都要进行后移以处理下一位。如果某一次有剩余的数据,则需将剩余部分全部依次填充到temp内(判断条件为左侧下标是否到mid以及右侧是否到right
public static void merge(int[]arr,int left,int mid,int right){
int i=left;
int []temp=new int[arr.length];//辅助数组
int j=mid+1;
int t=0;//指向temp数组的当前索引
//先把左右两边的数据按规则拷贝到temp中,直到左右两边的有序序列有一边处理完毕
while (i<=mid&&j<=right){
if (arr[i]<=arr[j]){
temp[t]=arr[i];
t+=1;
i+=1;
}else {
temp[t]=arr[j];
t+=1;
j+=1;
}
}
//处理左右边未填充进去的数
while (i<=mid){
temp[t]=arr[i];
t=t+1;
i=i+1;
}
while (j<=right){
temp[t]=arr[i];
t+=1;
j+=1;
}
//完成填充后将temp数组内的元素全部拷贝到arr
for (int x = left; x <=right; x++){
arr[x]=temp[x];}
}
//拆+合
public static void mergeSort(int[]a ,int start,int end){
if(start<end){
int mid=(start+end)/2;
mergeSort(a,start,mid);
mergeSort(a,mid+1,end);
merge(a,start,mid,end);
}
}由于每次调用merge都需要new temp,这样造成了大量的时间损耗,经过改良,将int[] temp作为参数传入函数在数据量足够大时,将大大减少时间消耗。下面有改进版本。
public static void merge(int[]arr,int left,int mid,int right,int[] temp){
int i=left;
int j=mid+1;
int t=0;//指向temp数组的当前索引
//先把左右两边的数据按规则拷贝到temp中,直到左右两边的有序序列有一边处理完毕
while (i<=mid&&j<=right){
if (arr[i]<=arr[j]){
temp[t]=arr[i];
t+=1;
i+=1;
}else {
temp[t]=arr[j];
t+=1;
j+=1;
}
}
//处理左右边未填充进去的数
while (i<=mid){
temp[t]=arr[i];
t=t+1;
i=i+1;
}
while (j<=right){
temp[t]=arr[i];
t+=1;
j+=1;
}
//完成填充后将temp数组内的元素全部拷贝到arr
t=0;
int tempLeft =left;
while (tempLeft<=right){
arr[tempLeft]=temp[t];
t+=1;
tempLeft+=1;
}
}
//拆+合
public static void mergeSort(int[]a ,int start,int end,int[] temp){
if(start<end){
int mid=(start+end)/2;
mergeSort(a,start,mid,temp);
mergeSort(a,mid+1,end,temp);
merge(a,start,mid,end,temp);
}
}6.基数排序
基数排序是桶排序的扩展,是一种稳定的排序方式,基本思想为逐位排序,将各位的数字分在桶中,其个数由所有数据的最长数据决定,典型的用空间换时间,无法处理海量数据。利用到了栈的相关知识。
处理整数数据的基数排序:
public static void radixSort(int[] arr){
//获取最大的位数
int max=arr[0];
for (int i=1;i<arr.length;i++){
if (arr[i]>max){
max=arr[i];
}
}
int maxlength=(max+"").length();
//定义二维数组表示十个桶,每个桶为一个一维数组,为防止溢出,将桶的大小定义大一些
int[][] bucket=new int[10][arr.length];
//记录每个桶内实际存放了多少个数据,定义一个数组记录各个桶每次放入数据的个数
int[] bucketElementCounts =new int[10];
//使用循环处理代码
for (int i=0,n=1;i<maxlength;i++,n*=10){
for (int j=0;j<arr.length;j++){
//取出第i+1位
int digitOfElement=arr[j]/n%10;
//放入对应桶
bucket[digitOfElement][bucketElementCounts[digitOfElement]]=arr[j];
bucketElementCounts[digitOfElement]++;
}
//按照桶的顺序取出数据放入原来数组
int index=0;
for(int k=0;k<bucketElementCounts.length;k++){
//如果桶中有数据才放入原数组中
if (bucketElementCounts[k]!=0){
//循环该桶放入数据
for (int l=0;l<bucketElementCounts[k];l++){
arr[index]=bucket[k][l];
index++;
}
}
//第i+1轮处理后需要将每个 bucketElementCounts[K]归零,以存放下一位
bucketElementCounts[k]=0;
}
System.out.println("第"+(i+1)+"轮,对数组的排序结果为"+Arrays.toString(arr));
}处理字符串的基数排序:实现一
public static String[] stringradixSort(String[] strArr) {
if(strArr == null) {
return null;
}
int maxLength = 0; // 只记录最大的位数
// 先获取数组的最大位数
for (String len : strArr) {
// 只记录最大的位数
if (len.length() >= maxLength) {
maxLength = len.length();
}
}
System.out.println("字符串基数排序中字符串最大长度为: " + maxLength);
ArrayList<ArrayList<String>> buckets = null;
// 从最后一个字母开始排序
for (int i=maxLength-1; i>=0; i--) {
// 因为英文字母只有26个,所以声明26个桶
buckets = new ArrayList<ArrayList<String>>();
for (int b = 0; b < 27; b++) {
buckets.add(new ArrayList<String>());
}
// 排序,主要需要考虑到桶的容量,比如数组为10个桶,字母26个桶
for (String str : strArr) {
buckets.get(getStrIndex(str, i)).add(str);
}
// 重新赋值
int index = 0;
for (ArrayList<String> bucket : buckets) {
for (String str : bucket) {
strArr[index++] = str;
}
}
}
return strArr;
}
public static int getStrIndex(String str, int charIndex) {
if (charIndex >= str.length()) {
return 0; // 第 0 个桶存非字母情况
}
int index = 26; // 总共26个字母
int n = (int) str.charAt(charIndex); // 把字母强制转换成数字
if (64 < n && n < 91) { // 大写字母区间范围
index = n - 64;
} else if (96 < n && n < 123) { // 小写字母区间范围
index = n - 96;
} else {
// 把其余非字母的排最后
index = 26;
}
return index;
}实现二:
public static String[] sorting(String[] strings)
{
//找到字符串中最大的长度来作为循环次数
int max = 0;//最大值
for (String string : strings) {
if (string.length()>max)
{
max = string.length();
}
}
int a = 1;//用来计算要获取哪一位的小标
//创建数据大桶
List<List<String>>listList = null;//先赋值为null,因为需要每循环一次就要清空桶内的数据
//开始排序
for (int i = 0; i <=max-1; i++) { //循环多少次
listList = new ArrayList<>();//每次循环都重新刷新了一次list集合
//创建27个数据桶
for (int k = 0; k<27; k++) {
listList.add(new ArrayList<>());
}
//把排序好的数据存放到数据桶中
for (String string : strings) {
listList.get(getint(string,string.length()-a)).add(string);//string.length()-a 这样就可以获取到每一位数的统一下标位置
}
a++;
//提出数据
int index = 0;
for (List<String> stringList : listList) {
for (String s : stringList) {
strings[index++] = s;
}
}
}
return strings ;
}
//得到每个字母的数据通位置
public static int getint(String s,int i){
if(i<0)
//下标越界了就直接返回0 因为是更具最长的字符串来决定循环次数和下标数。
// 那样就会导致用长的小标去获取短的导致获取不到就会报错下标越界
{
return 0;
}
int a =s.charAt(i);//根据字符获取ASCll表中的位置
if (a>64&&a<91)
{
return a-64;
}
else if (a>96&&a<123)
{
return a-96;//-96就可以得到数据桶的位置假如是a那么他在ASCll表中的位置是97,
//那么就的到1就放入下标为1的数据桶中
}
return 0;
}
以上两种排序均可以处理长度不同的字符串,比较依据位字典序ascii码排序。
比较:

其中堆排序待作者完成树相关的学习后再做更新















 3669
3669

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









