









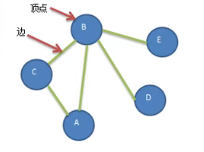
图的基本概念
图可用G=(V,E)表示,V为顶点集合,E为边集合。
边数较少的称稀疏图,边数较多的称密集图
如果边限定从一个顶点指向另一个顶点,则称此图为有向图,如果没有方向性叫无向图
每个点都有标号称标号图
路径上各顶点均不同,称该路径为简单路径
路径包含的边数成为路径的长度
构成回路的路径如果是简单路径,特别当首位两顶点不相同时,称此回路为简单回路
一个无向图任意一个顶点到其他顶点都至少存在一条路径,则称其为连通的
无向图的最大连通子图称为连通分量
不带回路的图称无环图、无环有向图
一棵自由树就是一个不带简单回路的无向图且连通
邻接表

图的实现
(1)存储顶点String 使用ArrayList
(2)保存矩阵int[][]edges 表示边
图的创建与遍历
package dsanda.graph;
import java.util.ArrayList;
import java.util.Arrays;
public class Graph {
private ArrayList<String> vertexList;
private int[][] edges;
private int numOfEdges;
public static void main(String[] args) {
int n=5;
String Vertexs[]={"A", "B", "C","D","E"};
Graph graph=new Graph(n);
//添加顶点
for (String vertex:Vertexs){
graph.insertVertex(vertex);
}
//添加边 A-B A-C B-C B-D B-E
graph.insertEdge(0,1,1);
graph.insertEdge(0,2,1);
graph.insertEdge(1,2,1);
graph.insertEdge(1,3,1);
graph.insertEdge(1,4,1);
//显示邻接矩阵
graph.showGraph();
}
//构造器
public Graph(int n){
edges = new int[n][n];
vertexList=new ArrayList<>(n);
numOfEdges=0;
}
//图中常用的方法
//返回边的个数
public int getNumOfEdges(){
return numOfEdges;
}
//返回结点的个数
public int getNumOfVertex(){
return vertexList.size();
}
//返回某结点下标i对应的数据
public String getValueByIndex(int i){
return vertexList.get(i);
}
//返回v1 v2 的 权值
public int getWeight(int v1, int v2){
return edges[v1][v2];
}
//显示对应的矩阵
public void showGraph(){
for (int[]link:edges){
System.err.println(Arrays.toString(link));
}
}
//插入一个结点
public void insertVertex(String vertex){
vertexList.add(vertex);
}
/**
* insert an edge
* @param v1 第一各顶点下标
* @param v2 第二个顶点下标
* @param weight 表示关联
*/
public void insertEdge(int v1,int v2, int weight){
edges[v1][v2]=weight;
edges[v2][v1]=weight;
numOfEdges++;
}
}
图的深度优先搜索DFS
图的遍历即对结点的访问
DFS:从初始访问结点出发,访问第一个节点在一这个节点作为初始节点访问它的第一个邻接结点,每次都在访问完当前节点后访问当前结点的第一个邻接结点。
步骤:1)访问初始结点v,并标记其已访问。
2)查找结点v的第一个邻接结点w
3)若w存在,则执行4,不存在则返回1,从v的下一个结点继续
4)若w未被访问,对w递归深度优先(将w当作下一个v)
5)查找结点v的w邻接结点的下一个邻接结点 转到步骤3
DFS算法对有向图的每条边都恰好处理一次,在无向图中,DFS对每条边分别沿两个方向进行处理,且每个顶点必须被访问,所以总的时间代价为Θ(|V|+|E|)

//深度优先遍历算法DFS
private void dfs(boolean[] isVisited,int i){
System.out.print(getValueByIndex(i)+"->");
//首先我们访问该结点,输出
isVisited[i]=true;
//查找结点i 的第一个 邻接结点w
int w =getFirstNeighbor(i);
while (w!=-1) {
if (!isVisited[w]){
dfs(isVisited, w);}
//如果w结点已经被访问过
w = getNextNeighbor(i, w);
}
}
//对dfs重载,遍历所有的结点并进行dfs
public void dfs(){
for (int i = 0; i<getNumOfVertex(); i++){
if (isVisited[i]){
dfs(isVisited,i);
}
}
}图的广度优先搜索BFS
分层搜索的过程,需要使用一个队列以保持访问过的结点的顺序,以便按这个顺序来访问这些结点的邻接结点。
广度优先搜索BFS算法步骤:
1)访问初始结点v并标记结点v为已访问
2)结点v入队列
3)当队列非空时,继续执行,否则算法结束
4)出队列,取得队头结点u
5)查找结点u的第一个邻接结点w
6)若结点u的邻接结点w不存在,则转到步骤3;否则循环执行以下三个步骤:
6.1 若结点w尚未被访问,则访问结点w并标记为已访问
6.2结点w入队列
6.3查找结点u的继w邻接结点后的下一个邻接结点w,转到步骤6
private void bfs(boolean[]isVisited , int i){
int u;//表示队列的头结点对应的下标
int w;//邻接结点w
LinkedList queue =new LinkedList();
//访问结点 输出结点信息
System.out.println(getValueByIndex(i)+"=>");
isVisited[i]=true;//标为已访问
queue.addLast(i);
while (!queue.isEmpty()){
u=(Integer)queue.removeFirst();
w=getFirstNeighbor(u);
while (w!=-1){
//表示找到
if (!isVisited[w]){//没有访问的话继续
System.out.println(getValueByIndex(w)+"=>");
isVisited[w]=true;
queue.addLast(w);
}
//访问过后 则以u为前驱 找到w后面的下一个邻接结点
w=getNextNeighbor(u,w);
}
}
}
//遍历所有的结点都进行bfs
public void bfs(){
for (int i=0;i<getNumOfVertex();i++){
if (!isVisited[i]){
bfs(isVisited,i);
}
}
}
拓扑排序
图的遍历(周游)可以解决先决条件问题,而我们需要安排一系列任务比如轮班、分工等,在某个人物的先决条件具备时才着手执行这个任务。可以使用一个有向无环图DAG来模拟这个问题。因为人物之间存在先决条件,即顶点之间有方向性,因此图是邮箱的,图又需要无回路(隐含了相互冲突的条件)。
将一个有向无环图中所有顶点在不违反先决条件规定的基础上排成线性序列的过程成为拓扑排序。

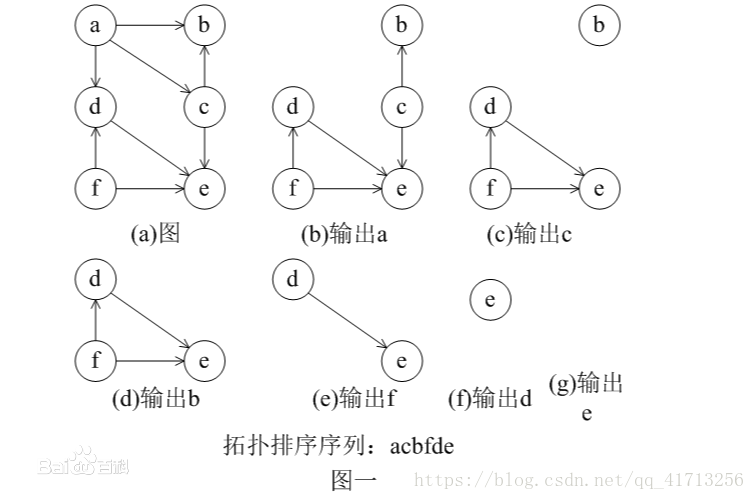
拓扑排序及其Java实现_Maxwell_7-CSDN博客_拓扑排序java
习题:


此题选B O(v+E)


有向图顶点入度等于出度,无向图中每一个边关联于两个顶点,因而所有顶点的度数之和等于所有边数的两倍。


邻接表与相邻矩阵都可以完成有向图和无向图的存储
一定是连通图 不一定是完全图















 1065
1065











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









