例子:
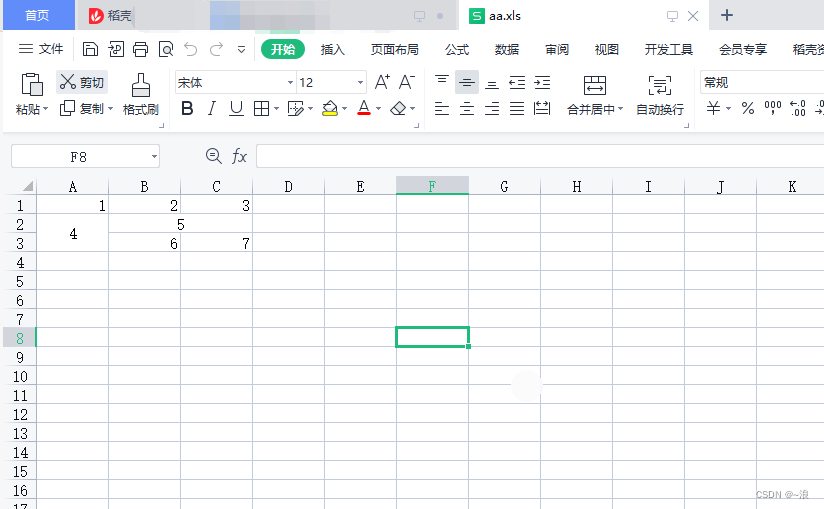
结果:

开始:-----------------------------------
导入的poi
<!-- https://mvnrepository.com/artifact/org.apache.poi/poi -->
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi</artifactId>
<version>3.14</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.poi/poi-ooxml -->
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-ooxml</artifactId>
<version>3.14</version>
</dependency>
判断文件格式初始化
/**
* 读取excel需求格式
* @param filePath 路径
* @return 返回
*/
public static Workbook readExcel(String filePath){
Workbook wb = null;
if(filePath==null){
return null;
}
String extString = filePath.substring(filePath.lastIndexOf("."));
InputStream is = null;
try {
is = new FileInputStream(filePath);
if(".xls".equals(extString)){
return wb = new HSSFWorkbook(is);
}else if(".xlsx".equals(extString)){
return wb = new XSSFWorkbook(is);
}else{
return wb = null;
}
} catch (Exception e) {
error("readExcel--" + e.getMessage());
}
return wb;
}
ExcelUtil完整代码(根据自己的需求进行修改,下面为我已经修改后的代码,代码我自己能够运行,如不能运行,请读一读改一改)
public class ExcelUtil {
public static void main(String[] args){
ExcelUtil excelUtil = new ExcelUtil();
String[] columnNames = {"1","2","3","4","5","6","7","8","9","10","11","12","13","14","15","16","17","18","19","20","21"};
//读取excel数据
ArrayList<Map<String,String>> result = excelUtil.readExcelToObj("sheet1",columnNames,"C:\\Users\\86182\\Desktop\\aa.xls");
for(Map<String,String> map:result){
System.out.println("输出:"+map);
}
}
/**
* 读取excel需求格式
* @param filePath 路径
* @return 返回
*/
public static Workbook readExcel(String filePath){
Workbook wb = null;
if(filePath==null){
return null;
}
String extString = filePath.substring(filePath.lastIndexOf("."));
InputStream is = null;
try {
is = new FileInputStream(filePath);
if(".xls".equals(extString)){
return wb = new HSSFWorkbook(is);
}else if(".xlsx".equals(extString)){
return wb = new XSSFWorkbook(is);
}else{
return wb = null;
}
} catch (Exception e) {
// error("readExcel--" + e.getMessage());
}
return wb;
}
/**---------------根据需要自己修改--------------------------------------------------------------------------------------------------------------
* 读取excel数据
* @param readExcel 传入
*/
public ArrayList<Map<String,String>> readExcelToObj(String name,Object[] columnNames, Workbook readExcel) {
// Workbook wb = null;
ArrayList<Map<String,String>> result = null;
try {
// wb = WorkbookFactory.create(new File(path));
result = readExcel(readExcel, name, 0, 0,columnNames);
} catch (Exception e) {
e.printStackTrace();
}
return result;
}
public ArrayList<Map<String,String>> readExcelToObj(String name,Object[] columnNames, String path) {
Workbook wb = null;
ArrayList<Map<String,String>> result = null;
try {
wb = WorkbookFactory.create(new File(path));
result = readExcel(wb, name, 0, 0,columnNames);
} catch (Exception e) {
e.printStackTrace();
}
return result;
}
//-----------------------------------------------------------------------------------------------------------------------------
/**
* 读取excel文件
* @param wb
* @param sheetIndex sheet页下标:从0开始
* @param startReadLine 开始读取的行:从0开始
* @param tailLine 去除最后读取的行
*/
private ArrayList<Map<String,String>> readExcel(Workbook wb,String sheetIndex, int startReadLine, int tailLine,Object[] columnNames) {
// Sheet sheet = wb.getSheetAt(sheetIndex);
Sheet sheet = wb.getSheet(sheetIndex);
Row row = null;
ArrayList<Map<String,String>> result = new ArrayList<Map<String,String>>();
for(int i=startReadLine; i<sheet.getLastRowNum()-tailLine+1; i++) {
row = sheet.getRow(i);
Map<String,String> map = new HashMap<String,String>();
for(Cell c : row) {
//全部按照字符串类型来读取
c.setCellType(Cell.CELL_TYPE_STRING);
String returnStr = "";
boolean isMerge = isMergedRegion(sheet, i, c.getColumnIndex());
//判断是否具有合并单元格
if(isMerge) {
String rs = getMergedRegionValue(sheet, row.getRowNum(), c.getColumnIndex());
// System.out.print(rs + "------ ");
returnStr = rs;
}else {
// System.out.print(c.getRichStringCellValue()+"++++ ");
// c.setCellType(Cell.CELL_TYPE_STRING);
// returnStr = c.getRichStringCellValue().getString();
returnStr = c.getStringCellValue();
}
//赋值
for (int i1 = 0; i1 < columnNames.length; i1++) {
if (c.getColumnIndex() == i1){
map.put(String.valueOf(columnNames[i1]),returnStr);
}
}
/* if(c.getColumnIndex()==0){
map.put(columnNames[0],returnStr);
}else if(c.getColumnIndex()==1){
map.put("base",returnStr);
}else if(c.getColumnIndex()==2){
map.put("siteName",returnStr);
}else if(c.getColumnIndex()==3){
map.put("articleName",returnStr);
}else if(c.getColumnIndex()==4){
map.put("mediaName",returnStr);
}else if(c.getColumnIndex()==5){
map.put("mediaUrl",returnStr);
}else if(c.getColumnIndex()==6){
map.put("newsSource",returnStr);
}else if(c.getColumnIndex()==7){
map.put("isRecord",returnStr);
}else if(c.getColumnIndex()==8){
map.put("recordTime",returnStr);
}else if(c.getColumnIndex()==9){
map.put("remark1",returnStr);
}else if(c.getColumnIndex()==10){
map.put("remark2",returnStr);
}else if(c.getColumnIndex()==11){
map.put("remark3",returnStr);
}else if(c.getColumnIndex()==12){
map.put("remark4",returnStr);
}else if(c.getColumnIndex()==13){
map.put("remark5",returnStr);
}else if(c.getColumnIndex()==14){
map.put("remark6",returnStr);
}else if(c.getColumnIndex()==15){
map.put("remark7",returnStr);
}else if(c.getColumnIndex()==16){
map.put("mediaUrl9",returnStr);
}else if(c.getColumnIndex()==14){
map.put("newsSource9",returnStr);
}else if(c.getColumnIndex()==18){
map.put("isRecord9",returnStr);
}else if(c.getColumnIndex()==19){
map.put("recordTime9",returnStr);
}else if(c.getColumnIndex()==20){
map.put("remark19",returnStr);
}else if(c.getColumnIndex()==21){
map.put("remark29",returnStr);
}else if(c.getColumnIndex()==22){
map.put("remark39",returnStr);
}else if(c.getColumnIndex()==23){
map.put("remark49",returnStr);
}else if(c.getColumnIndex()==24){
map.put("remark59",returnStr);
}else if(c.getColumnIndex()==25){
map.put("remark69",returnStr);
}else if(c.getColumnIndex()==26){
map.put("remark79",returnStr);
}*/
}
result.add(map);
}
return result;
}
/**
* 获取合并单元格的值
* @param sheet
* @param row
* @param column
* @return
*/
public String getMergedRegionValue(Sheet sheet ,int row , int column){
int sheetMergeCount = sheet.getNumMergedRegions();
for(int i = 0 ; i < sheetMergeCount ; i++){
CellRangeAddress ca = sheet.getMergedRegion(i);
int firstColumn = ca.getFirstColumn();
int lastColumn = ca.getLastColumn();
int firstRow = ca.getFirstRow();
int lastRow = ca.getLastRow();
if(row >= firstRow && row <= lastRow){
if(column >= firstColumn && column <= lastColumn){
Row fRow = sheet.getRow(firstRow);
Cell fCell = fRow.getCell(firstColumn);
return getCellValue(fCell) ;
}
}
}
return null ;
}
/**
* 判断合并了行
* @param sheet
* @param row
* @param column
* @return
*/
private boolean isMergedRow(Sheet sheet,int row ,int column) {
int sheetMergeCount = sheet.getNumMergedRegions();
for (int i = 0; i < sheetMergeCount; i++) {
CellRangeAddress range = sheet.getMergedRegion(i);
int firstColumn = range.getFirstColumn();
int lastColumn = range.getLastColumn();
int firstRow = range.getFirstRow();
int lastRow = range.getLastRow();
if(row == firstRow && row == lastRow){
if(column >= firstColumn && column <= lastColumn){
return true;
}
}
}
return false;
}
/**
* 判断指定的单元格是否是合并单元格
* @param sheet
* @param row 行下标
* @param column 列下标
* @return
*/
private boolean isMergedRegion(Sheet sheet,int row ,int column) {
int sheetMergeCount = sheet.getNumMergedRegions();
for (int i = 0; i < sheetMergeCount; i++) {
CellRangeAddress range = sheet.getMergedRegion(i);
int firstColumn = range.getFirstColumn();
int lastColumn = range.getLastColumn();
int firstRow = range.getFirstRow();
int lastRow = range.getLastRow();
if(row >= firstRow && row <= lastRow){
if(column >= firstColumn && column <= lastColumn){
return true;
}
}
}
return false;
}
/**
* 判断sheet页中是否含有合并单元格
* @param sheet
* @return
*/
private boolean hasMerged(Sheet sheet) {
return sheet.getNumMergedRegions() > 0 ? true : false;
}
/**
* 合并单元格
* @param sheet
* @param firstRow 开始行
* @param lastRow 结束行
* @param firstCol 开始列
* @param lastCol 结束列
*/
private void mergeRegion(Sheet sheet, int firstRow, int lastRow, int firstCol, int lastCol) {
sheet.addMergedRegion(new CellRangeAddress(firstRow, lastRow, firstCol, lastCol));
}
/**
* 获取单元格的值
* @param cell
* @return
*/
public String getCellValue(Cell cell){
if(cell == null) return "";
if(cell.getCellType() == Cell.CELL_TYPE_STRING){
return cell.getStringCellValue();
}else if(cell.getCellType() == Cell.CELL_TYPE_BOOLEAN){
return String.valueOf(cell.getBooleanCellValue());
}else if(cell.getCellType() == Cell.CELL_TYPE_FORMULA){
return cell.getCellFormula() ;
}else if(cell.getCellType() == Cell.CELL_TYPE_NUMERIC){
return String.valueOf(cell.getNumericCellValue());
}
return "";
}
/**
* 从excel读取内容
*/
public static void readContent(String fileName) {
boolean isE2007 = false; //判断是否是excel2007格式
if(fileName.endsWith("xlsx"))
isE2007 = true;
try {
InputStream input = new FileInputStream(fileName); //建立输入流
Workbook wb = null;
//根据文件格式(2003或者2007)来初始化
if(isE2007)
wb = new XSSFWorkbook(input);
else
wb = new HSSFWorkbook(input);
Sheet sheet = wb.getSheetAt(0); //获得第一个表单
Iterator<Row> rows = sheet.rowIterator(); //获得第一个表单的迭代器
while (rows.hasNext()) {
Row row = rows.next(); //获得行数据
// System.out.println("Row #" + row.getRowNum()); //获得行号从0开始
Iterator<Cell> cells = row.cellIterator(); //获得第一行的迭代器
while (cells.hasNext()) {
Cell cell = cells.next();
System.out.println(cell.getStringCellValue());
// System.out.println("Cell #" + cell.getColumnIndex());
// switch (cell.getCellType()) { //根据cell中的类型来输出数据
// case HSSFCell.CELL_TYPE_NUMERIC:
// System.out.println(cell.getNumericCellValue());
// break;
// case HSSFCell.CELL_TYPE_STRING:
// System.out.println(cell.getStringCellValue());
// break;
// case HSSFCell.CELL_TYPE_BOOLEAN:
// System.out.println(cell.getBooleanCellValue());
// break;
// case HSSFCell.CELL_TYPE_FORMULA:
// System.out.println(cell.getCellFormula());
// break;
// default:
// System.out.println("unsuported sell type======="+cell.getCellType());
// break;
// }
}
}
} catch (IOException ex) {
ex.printStackTrace();
}
}
}






















 5256
5256











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









