







项目要求: 获取‘’站长素材‘’ 域名:https://sc.chinaz.com/jianli/free.html ,当中的免费简历素材。
项目分析:
我们通过域名访问到:以下页面

在菜单栏中找到:简历模板(鼠标点击进去)就可以看见免费模板
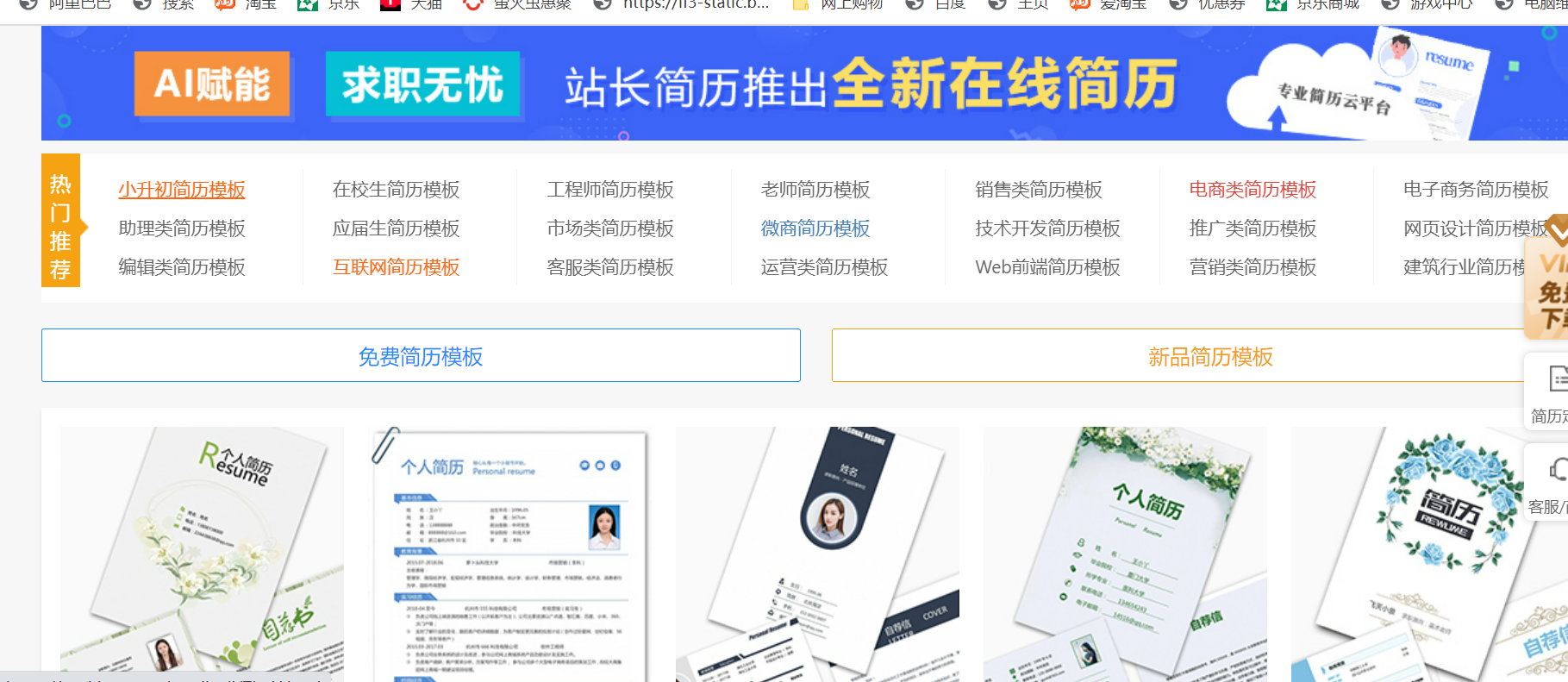
点击免费模板
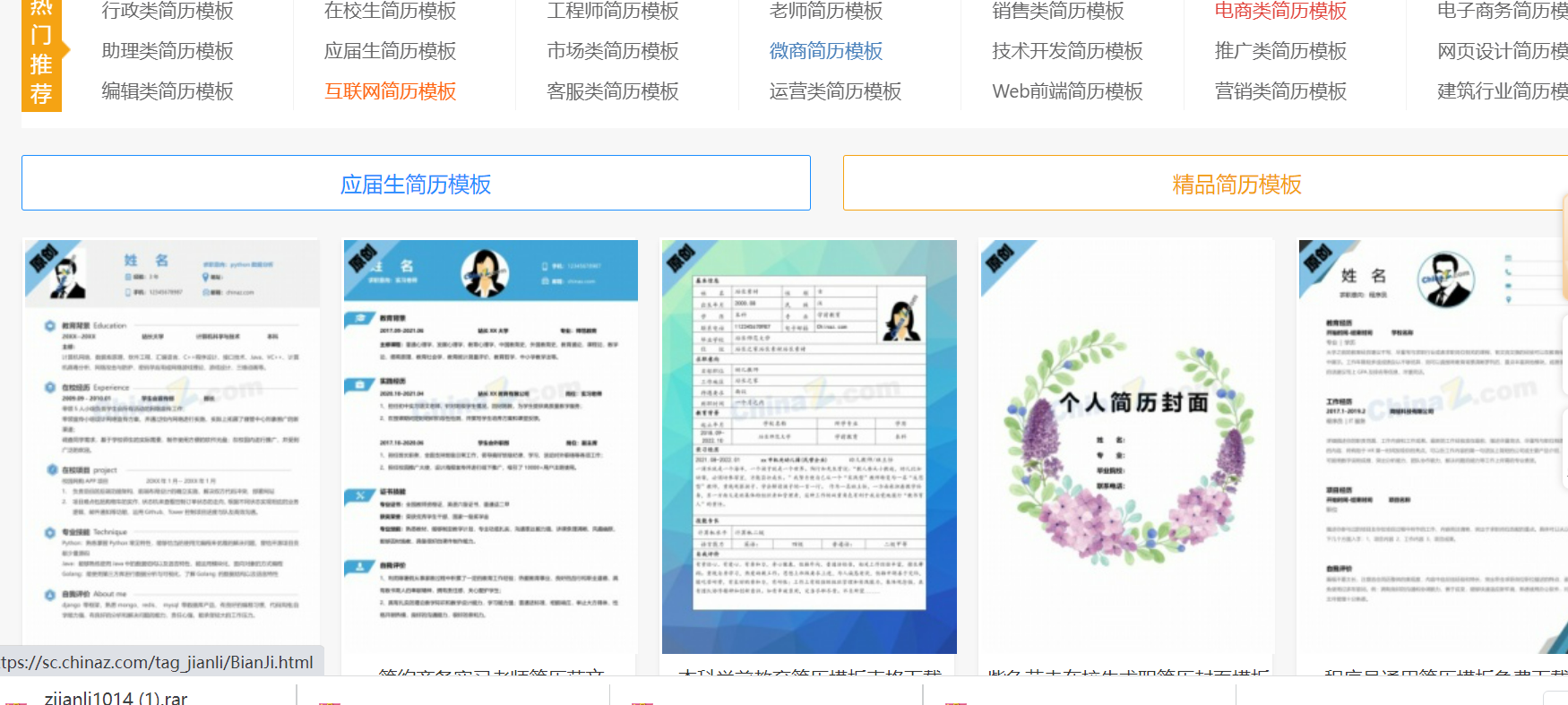
我们看到许多类型的模板可供我们下载,我们随便点击一个模板进去(以第一简历模板为例【python数据分析技术员】)
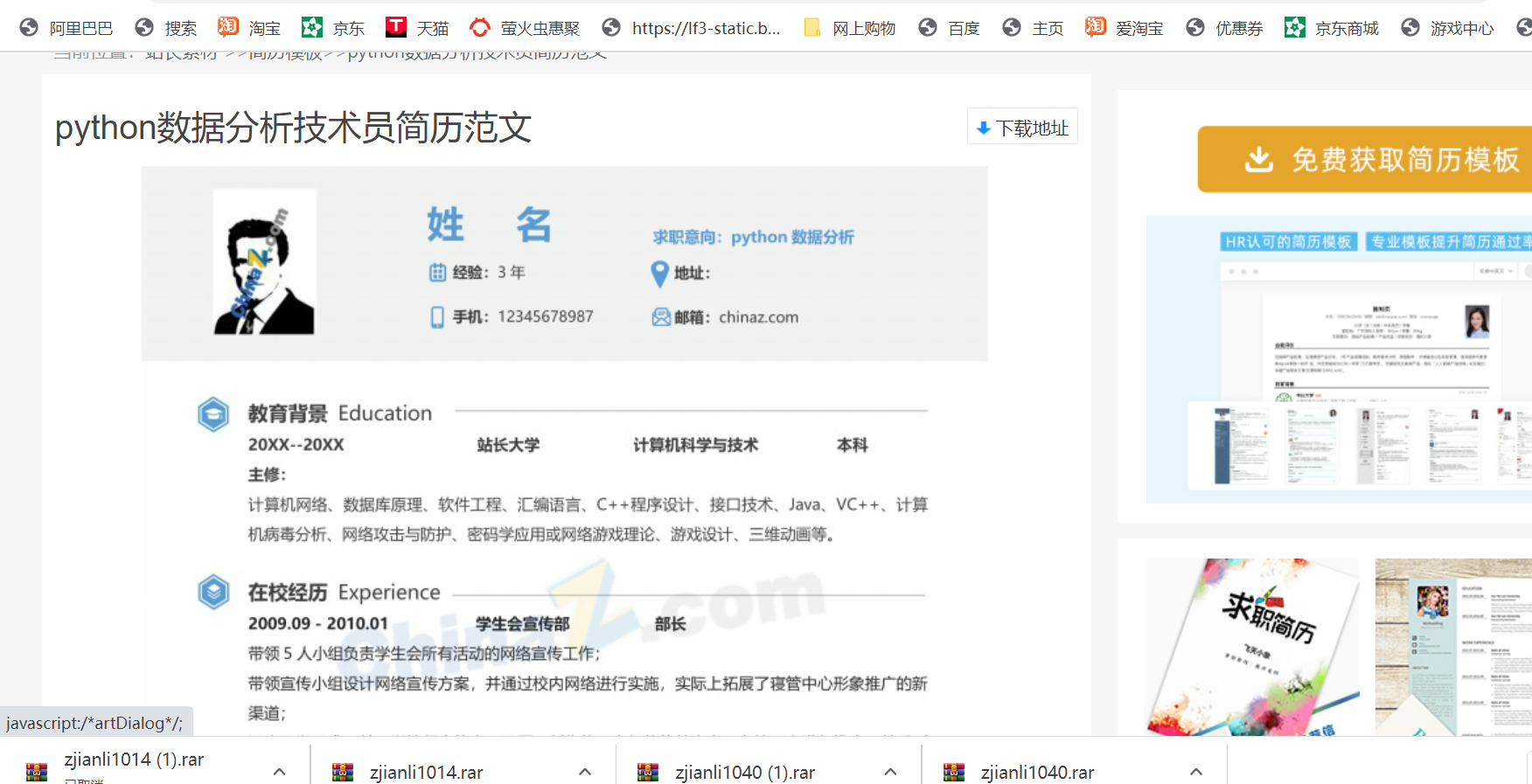
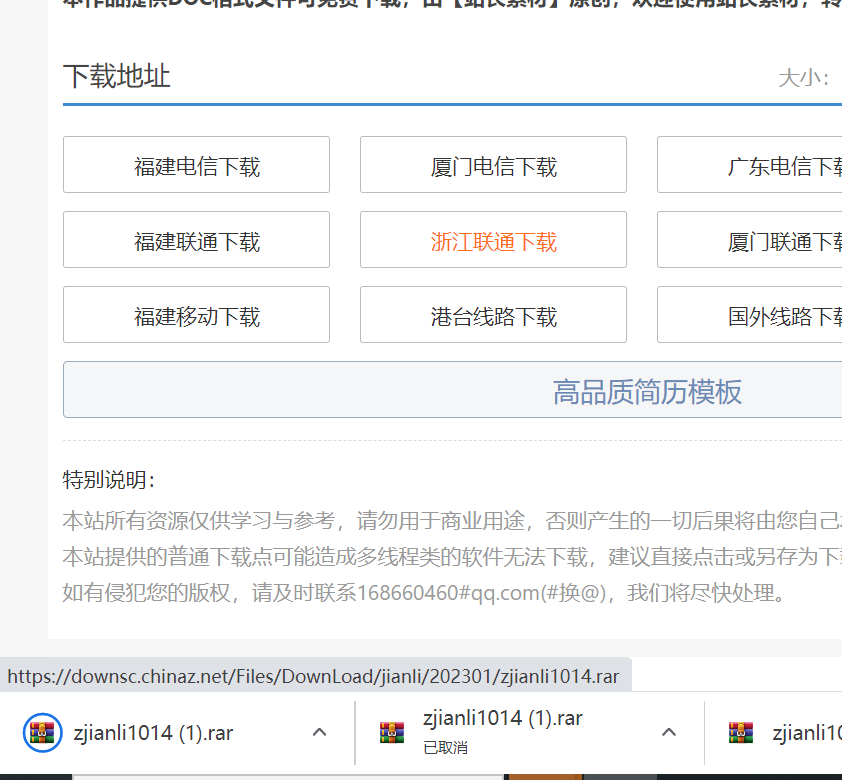
往下滑动,在中下方位置可以见到一些下载地址。
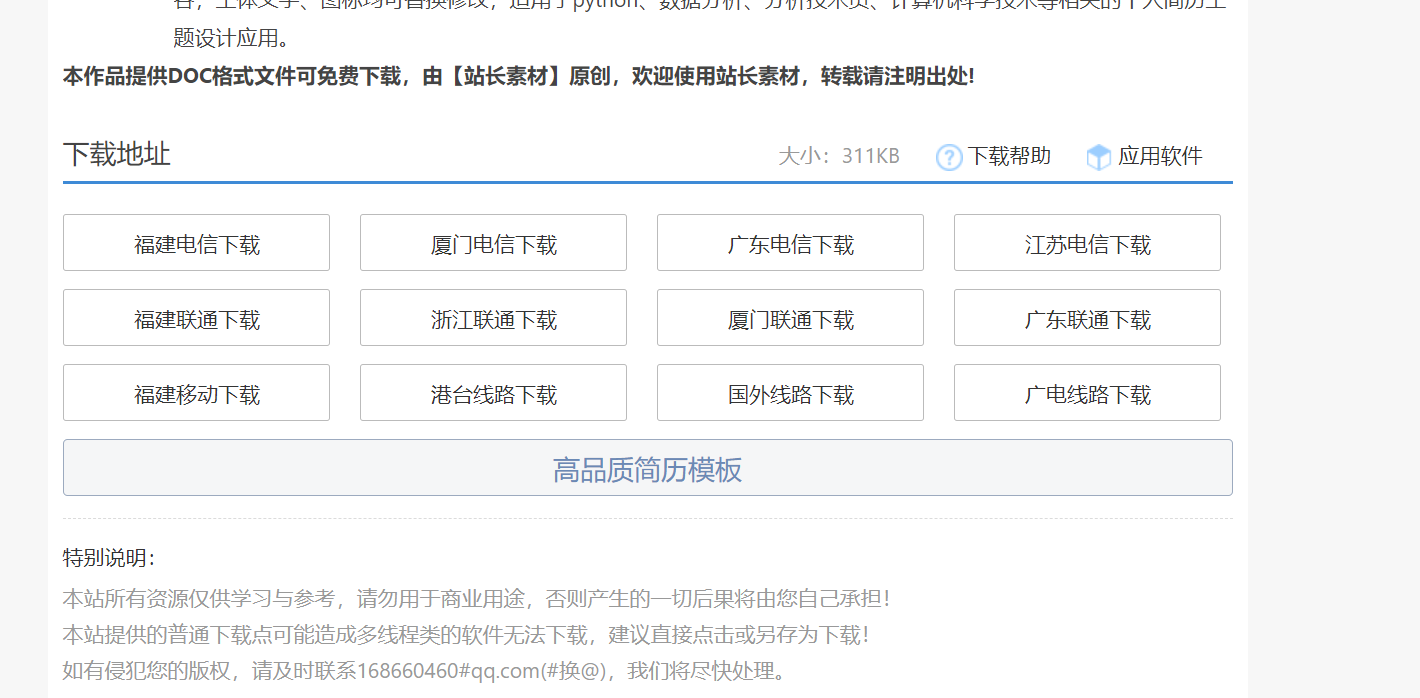
我们可以随便点击一种下载方式都可以下载成功。
二:第二大部分主要讲解以程序的思维下载资源
逆向思维:
我们可以通过抓包工具先检查一下,这个(第一大步的小 6 )下载按钮在页面的那一块,是通过那种方式下载。
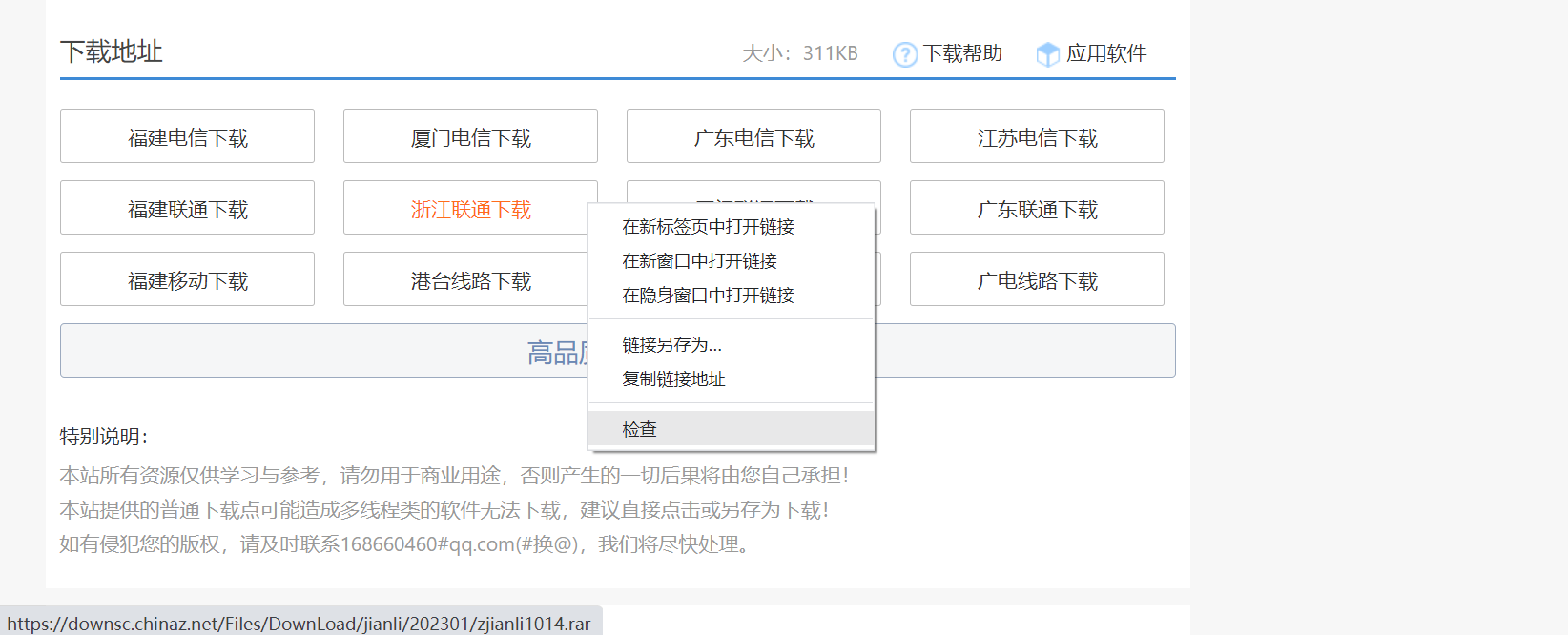
点击鼠标右键会出现上图样式,找到“检查”点击进去
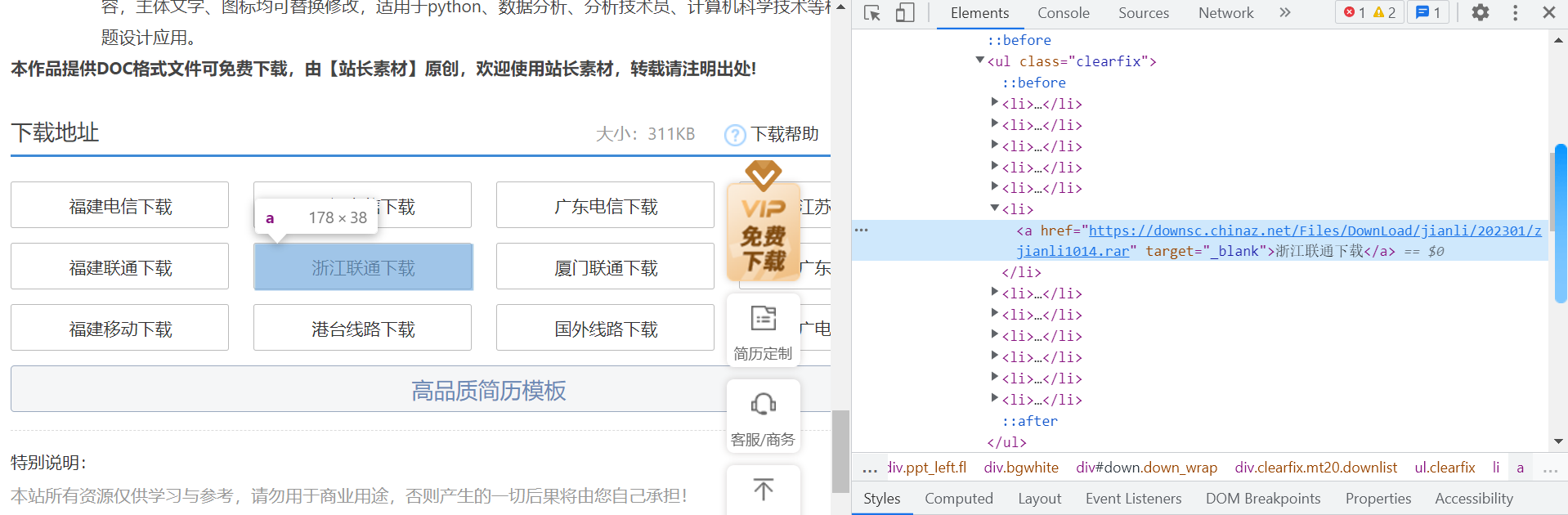
(以浙江联通为例)我们会发现,这个按钮,在本张html页面的a标签中,我们可以尝试点击一下a标签中 @href属性的链接地址。
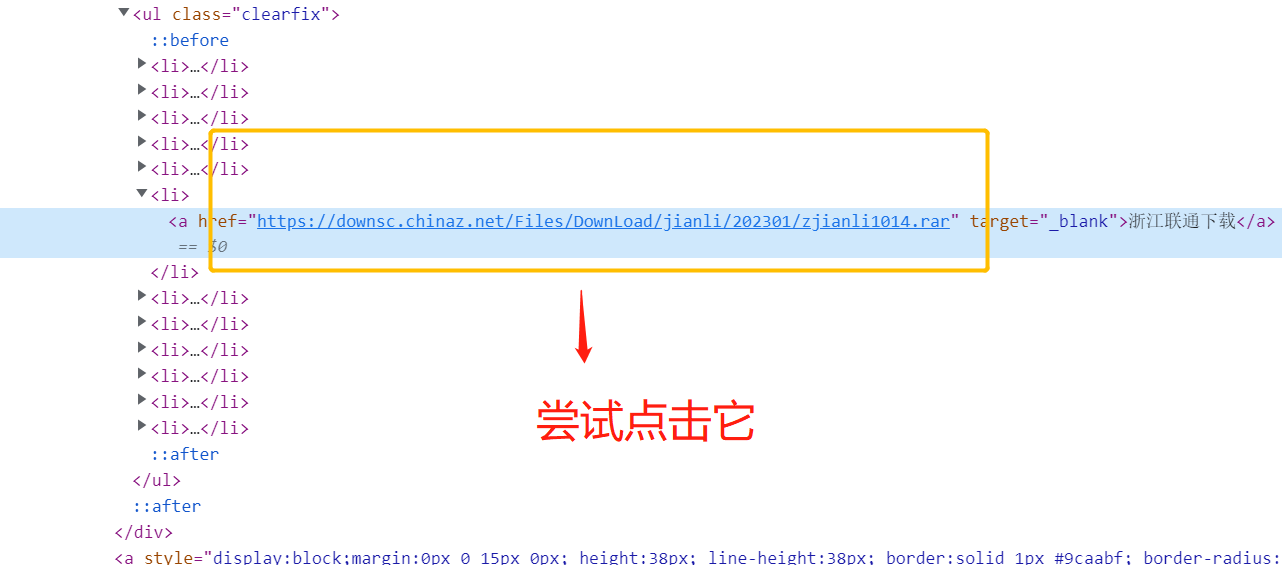
我们会发现当点击它的时候,它会发起一个下载请求,它会把文档下载我们本地。
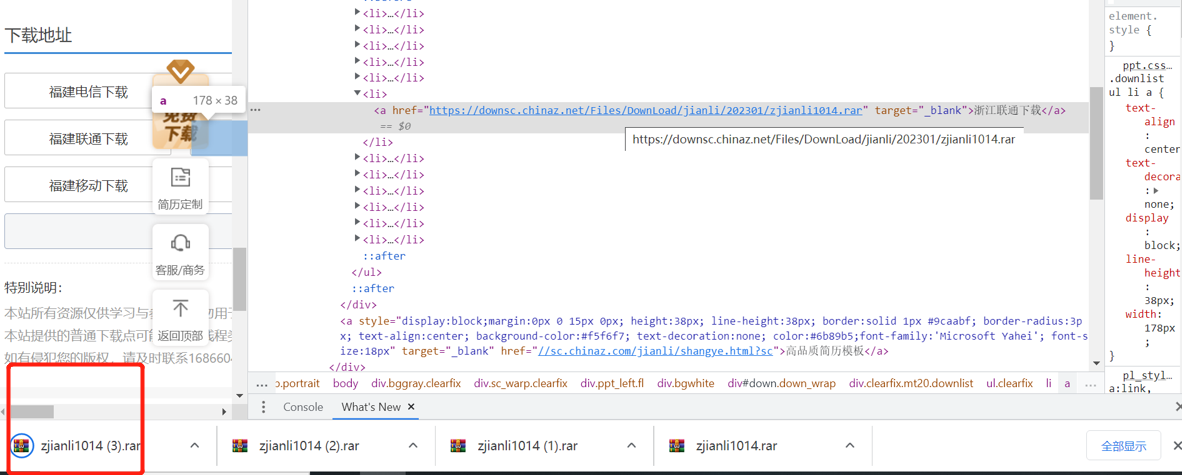
说明了我们只要拿到所有的简历的a标签下的@href属性(连接地址:"https://downsc.chinaz.net/Files/DownLoad/jianli/202301/zjianli1014.rar),并且对它发起一个get请求,就会将所有我们通过爬虫获取的简历下载到本地。
那我们如何才能拿到a标签的@href 属性值呢,显然可以用今天爬虫方法,xpath 语法:
我们应该先拿到a标签,然后同xpath获取属性值的语法,拿到a标签当中的@href属性值。
如何拿到a标签? 我们可以看一下整个html界面的标签层次。
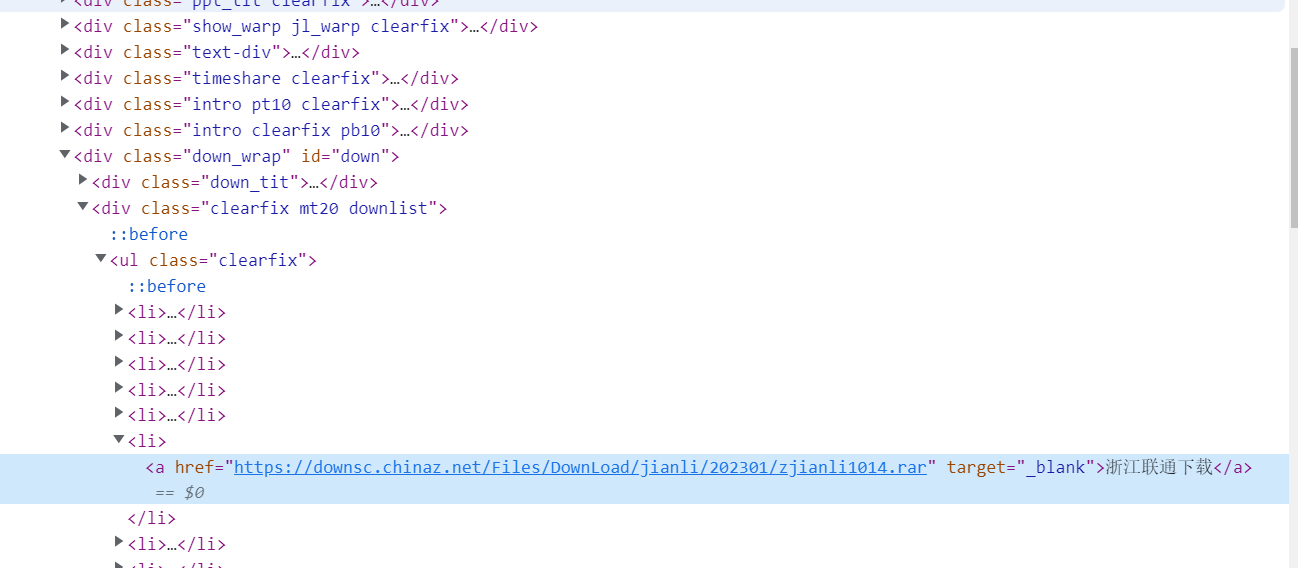
a 标签在li标签中,li标签在ul标签中,ul标签在<div class = "clearfix mt20 downlist"> 标签中
显然我们获取到a标签的层次顺序是 <div class = "clearfix mt20 downlist"> - <ul> - <li> - <a> @href
我们来写xpath 语法:
'//div[@class="down_wrap"]/div[2]/ul[@class="clearfix"]/li[6]/a/@href')[0]
] 表示当前从 div[@class="down_wrap"]标签开始,下一层是第二个div标签 /div[2,下一层是ul标签且class属性为"clearfix"
/ul[@class="clearfix"],下一层是li 标签第六个/ li [6],下一层是 a标签/a,a标签中href属性 /@href .
回到大的界面上看,我们既然通过html界面分析获取 下载地址,那如何才能找到当前(获取下载地址的页面 页面6)这个页面呢?
显然是我们来到这个页面的前一个界面(第一大步,步骤小3)界面
我们通过抓包工具打开这个界面
第一个免费简历在当前html页面的位置
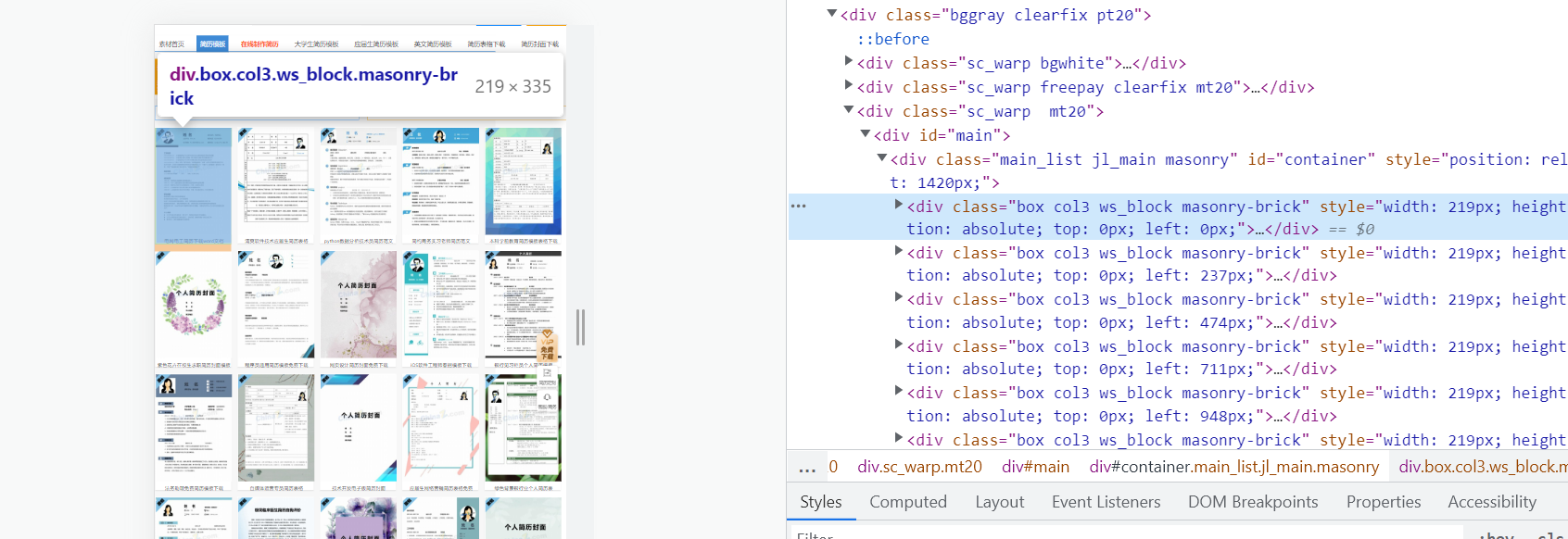
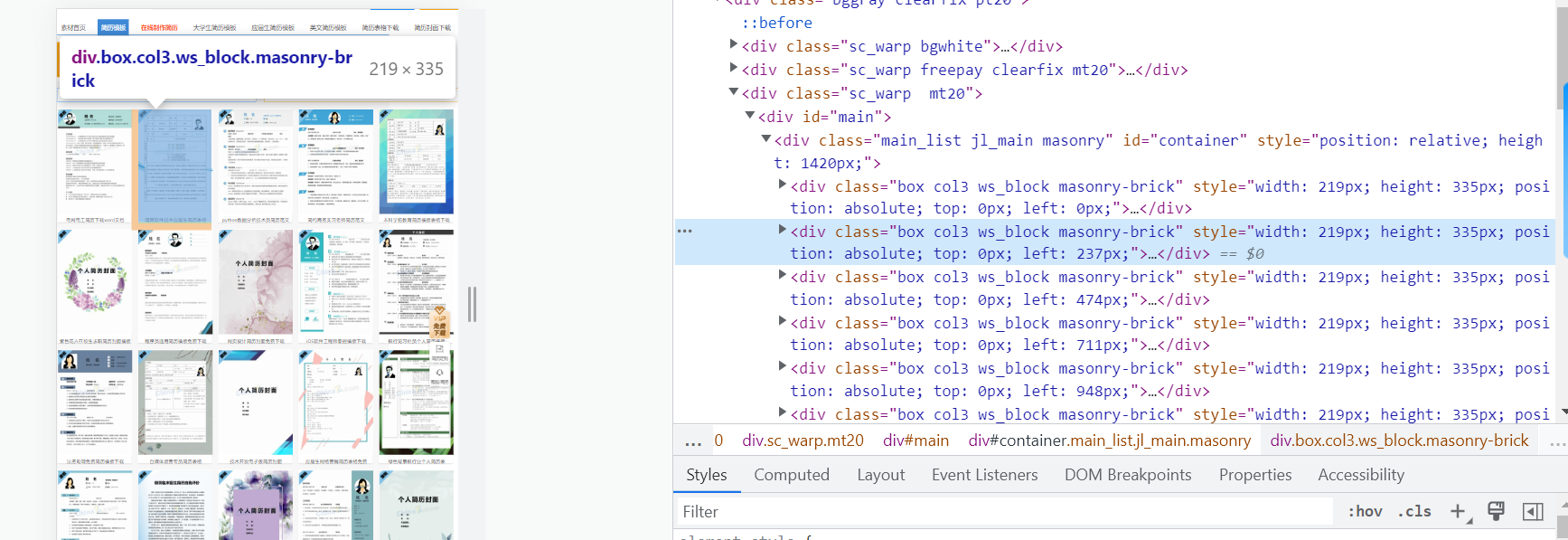
从我给大家发的上面两个图片中,我们可以看到,每一个简历都在一个div标签,这页有多少张简历,就有多少张div标签。
我么以第一个 div标签为例打开它。可以看到有一个a标签,a标签里有一个请求地址,a标签下的img标签中有一个不完整的请求地址。
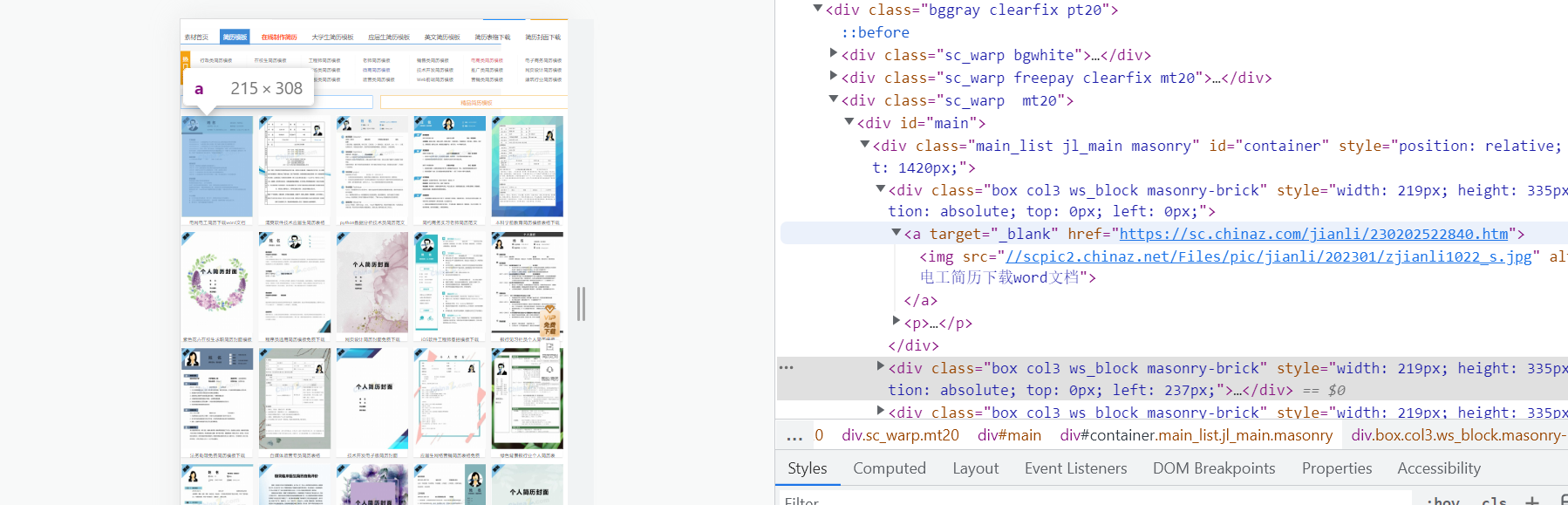
我们通过分析得到img中的连接地址为第一个div标签(也就是第一张简历)的图片请求地址,那么a标签中的链接地址是什么呢?
我们可以尝试点击一下,哎怎么是这张页面,我们上一个发起按钮下载请求地址的模块就在这张页面,所以由此可知,只要我们得到了上一个页面,在上一个界面找到a标签中的请求地址,并对它发起一个get请求就可以得到这张页面
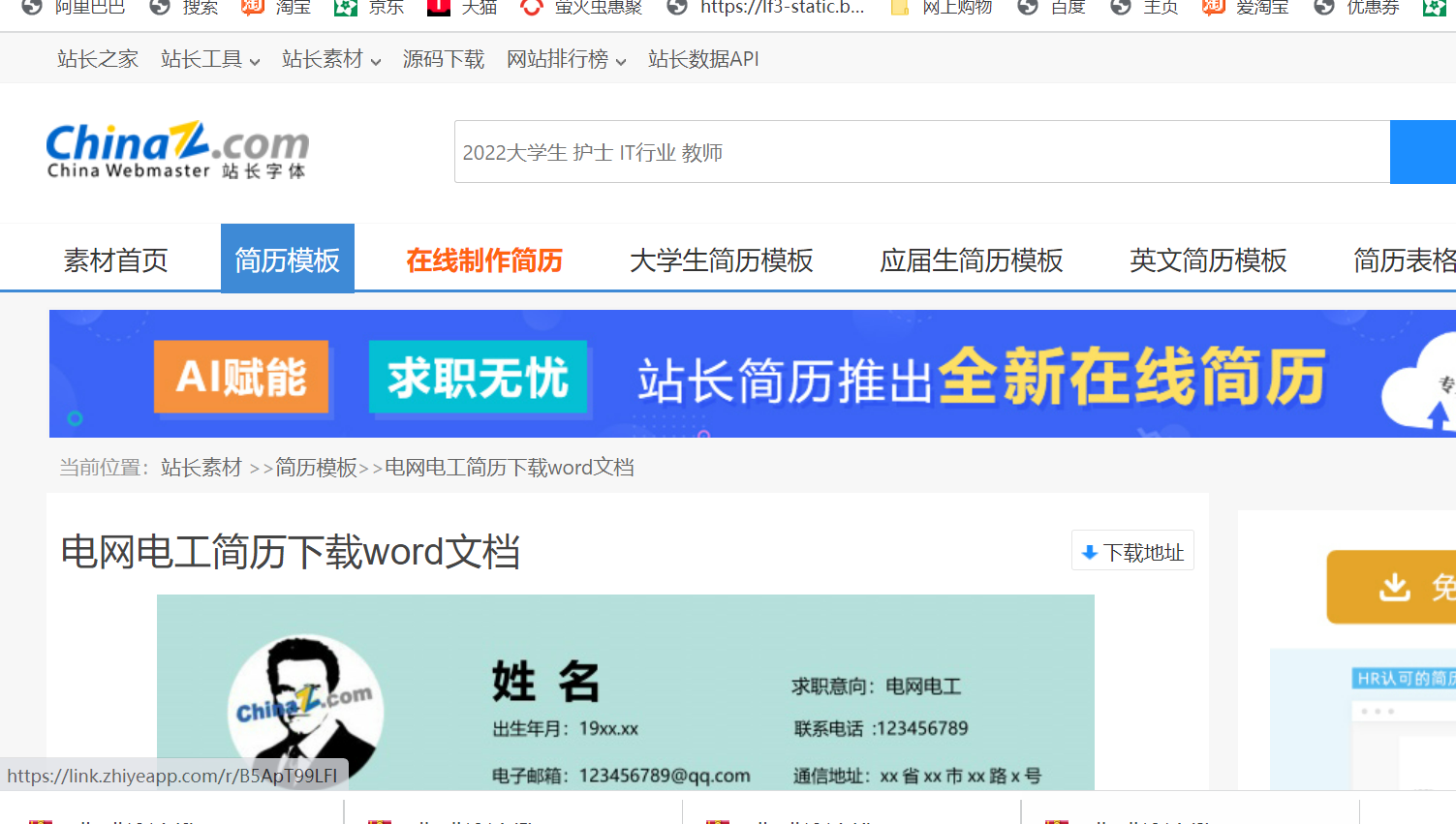
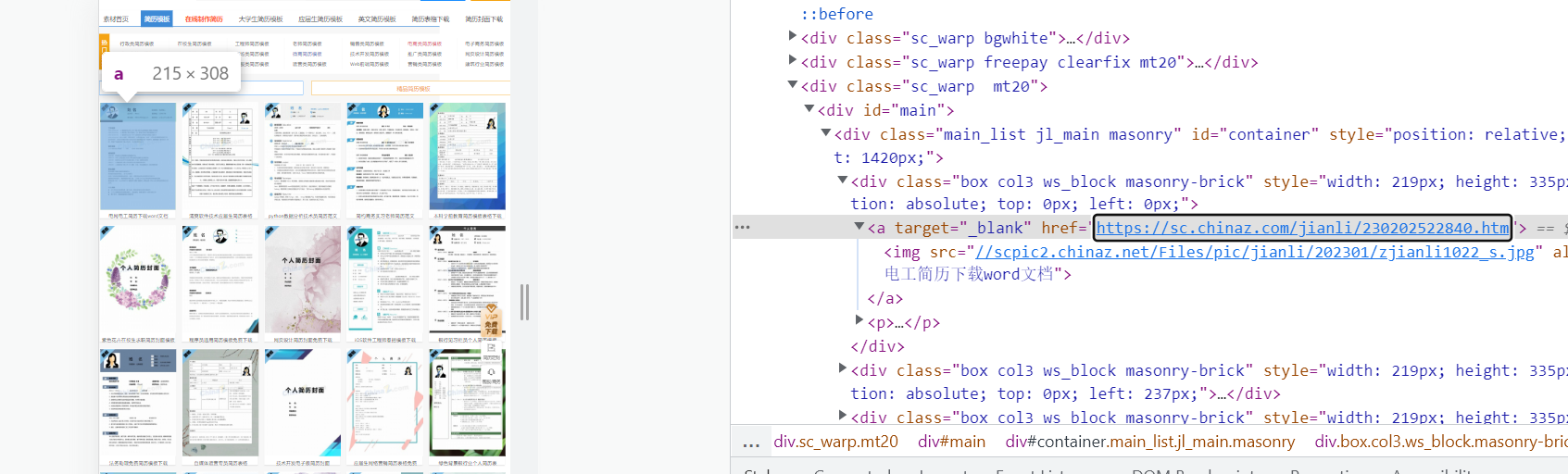
我们来写一下下面这张页面的xpath语法,分析就不说了,可以看我前面发的文章关于xpath文档介绍
('//*[@id="container"]/div/a/@href')
代码:
import requests
import re
import time
from lxml import etree
url = 'https://sc.chinaz.com/jianli/free.html'
headers = {
'User-Agent':'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Mobile Safari/537.36',
'Cookie':'cz_statistics_visitor=4a8a9b1f-0570-5d2e-affa-cf37cad60bed; __bid_n=186057514a234397264207; Hm_lvt_398913ed58c9e7dfe9695953fb7b6799=1675128805; FPTOKEN=pTGhI9nUtCISS9benFInL08EGASsO55DxwcH3LwT8WvabT19iAWTX1eW9gvicfMmaqfbA6JHHBwJi8F6mLtsAqB8o+dFv0dfaL/zCk7DILQLc8t61HBeFdEtSCCsZXTj1JyyDG3VNEVEucuU5Z8nIy8Pyw9bZjdmM5OXv7o9DuQRgOOmxkDCE9zfmCp9sBAZLI1/WL4fWvnOknz3Z44wB7xLtymPMrVzqXbetQwjYUPOU01cyW6zsP+gWikEEHjv2Yz5HO9E3NLG6epkQfSn6NJfpf6ovEHWiH6Ur0Mb9wiBMRh4i57gRnv8uHntHTFDFtoLUd4buW8G3h83EdLhM+2pHR4iuin0MDLStJJECQ3iwM1915WLS9CdveG8W/kf+3mSYb9ziG7rhKE+lN5PwQ==|E9F5DHUgE51103VdnV5fMvGiJYF3EA4y8Wq7W8Iq7Vk=|10|c2ff4b741bf7747bf410affa6f820071; ASP.NET_SessionId=ktkksyywl0rxaytyznol3gre; Hm_lpvt_398913ed58c9e7dfe9695953fb7b6799=1675159055'
}
# 问题高风险区 会报错:
'''
response = requests.get(url=url,headers=headers).text
response.encoding="utf-8"
报错:response.encoding="utf-8"
AttributeError: 'str' object has no attribute 'encoding'
“str”对象没有属性“content” 这种问题出现的原因绝大可能和代码的执行顺序相关。text解析的是文本格式,以字符串的格式接收,接下来用字符串来解析编码格式是不允许的。
打印response 返回的是 200 结果打印正常
通过打印:rr 说明解析页面成功返回的是一个完整html页面
'''
response = requests.get(url=url,headers=headers)
# print(response)
response.encoding="utf-8"
rr = response.text
# print(rr)
tree = etree.HTML(rr)
#
# # print(tree)
#//* 的含义是选取文档中的所有元素。 @选取属性
a_list = tree.xpath('//*[@id="container"]/div')
#通过打印 a_list 得到了进入第一个免费模板域名地址如何在标签中正确提取域名地址,假如域名地址在<a>标签中,这样写//.@*/a/@href
# print(a_list)
all_city = []
#通过for循环得到第一张页面的所有简历地址而不是只有第一张
fp = open("connect.txt","w",encoding="utf-8")
for a in a_list:
#通过下标索引获取到了列表中的绝对地址
title = (a.xpath('./a/@href'))[0]
# print(title)
# print(all_city)
# for connect in all_city:
# print(connect)
# proxy = random.choice()
# 下面的这些都是废话,因为 url = tiltes 我把它写成 url = 'titles' 加上把地址加上单引号,我在这里搞了半天,还以为是一次发送的地址太多,因为我从自定义 all_city 列表中拿出的是一批数据。
for title in all_city:
#这里for循环很重要我们需要拿到所有@href: 'http://xxxx'所有页面,所以关于下面的html页面解析 一定要放在for循环里面。
# print(titles)
Dolls_title = requests.get(url=title, headers=headers)
# print(Dolls_title)
# Dolls_title = requests.get(url='tiltle', headers=headers)
Dolls_title.encoding = 'utf-8'
# print(Dolls_title)
html = Dolls_title.text
# print(html)
Page_parsing = etree.HTML(html)
jian_li = Page_parsing.xpath('//div[@class="down_wrap"]/div[2]/ul[@class="clearfix"]/li[6]/a/@href')[0]
time.sleep(2)
print(jian_li)
all_city.append(jian_li)
# print(all_city)
# print('第{page}页获取完成'.format(page=i+1))
# print(jian_li)
# fp.write(jian_li+ '\n')
# print("第一页爬取完毕")
#下面这些很重要如果是乱码
# Dolls_title = requests.get(url="titles", headers=headers)
# Dolls_title.encoding = 'utf-8'
# html = Dolls_title.text
# print(html)
'''
#页面解析:
Page_parsing= etree.HTML(Dolls_title)
zjian_li= Page_parsing.xpath("")
fp.write(title+'\n')
print("第一页爬取完毕")
'''
#简历当中的详情页面
# Dolls_title = requests.get(url='title',headers=headers).text
# #出现乱码通过: 获取到乱码的,把get到的对象r.encoding=r.apparent_encoding
# #乱码的这样: resopnse_text = resopnse.text.encode(resopnse.encoding).decode("utf-8")
# print(Dolls_title)
#打印报错: 试试看单个url,而不是url列表还有检查网络是不是通
""" raise InvalidSchema(f"No connection adapters were found for {url!r}")
requests.exceptions.InvalidSchema: No connection adapters were found for "['https://sc.chinaz.com/jianli/230131204110.htm']"
"""
# //*[@id="container"]/div[1]/a这个小项目的关键点在于思维分析,如何找到简历的下载地址,对它发一get请求就可以得到当前地址下的简历文档。
项目我没有写完,关于对下载地址发起一个get请求,就可以项目完整了,因为要对两个页面,两个url分别发起一次get请求,大家可以用面向对象的方法,把一个页面从获取地址到发起请求创建一个方法,这样看起来代码比价高级。
xpath文档地址:XPath 语法 (w3school.com.cn)
总结:
论语二则:
礼之用,和为贵。——《论语·学而》(礼的作用,在于使人的关系和谐为可贵。)
君子不器。——《论语·为政》(君子博学多才,可胜任各种工作。或:君子不会拘泥于形式教条。)
哪里不懂欢迎私信/留言















 815
815











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









