






一 、Java基础
1 三大特性
封装、继承、多态
2 访问修饰符
private 类内部使用
default >同包类使用
protected >子类中使用
public >所以类中使用
继承时:子类的权限修饰符大于父类或接口
3 final、finally、finallize
final 修饰类不能被继承、修饰方法不能被重写、修饰常量不能被修改;
finally try...catch...finally... 异常捕获机制必执行的一个方法;
finallize object方法,用于判断是否可以被垃圾回收器进行回收
4 this、super
this 本类对象
super 父类对象
5 static
静态资源的标签,程序启动时加载到jvm虚拟机的方法区,所有对象共享;
比如 静态类、静态方法、常量、静态块
注意:静态只能访问静态,非静态都可以访问;
静态方法类名直接调用,实例方法对象调用;
6 break、continue、return
break 结束当前循环体
continue 结束当前循环
return 直接结束当前方法
7 面向对象五大原则
7.1 单一职责: 功能要单一;
7.2 开放封闭: 类要开放,属性要隐私;
7.3 里式替换: 子类可以代替父类的功能;
7.4 依赖倒置: 低层次的模块依赖于高层次;
7.5 接口分离:不同功能应分离成不同接口,不能一个接口包含;
8 抽象类、接口
抽象类 是对类的抽象,是一种模板设计;
接口 是对行为的抽象,是一种行为规范;
注意:多继承单实现
9 Java包
Java.lang: 系统基础类;
Java.io: 输入输出类;
Java.util: 系统辅助类,比如集合等;
Java.net: 网络类;
Java.sql: 数据库操作类
10 Java4种引用类型
1 强引用类型:
User user = new User(); 把一个对象赋给一个引用变量。
1.1 特点: 始终处于可达状态,不能被垃圾回收机制回收的,即使对象以后永远不再使用,也不能回收。
注:写在方法内的强引用,当栈销毁时,对象会被删除。
2 软引用类型:
softReference,当系统内存不足时才会被回收,常用于缓存。
3 弱引用类型
当垃圾回收器执行一次,不管对应有没有被引用,对象都会被回收
4 虚引用类型
与引用队列联合使用,主要作用是跟踪对象被回收的状态。
二、数据结构
1 八种基本与包装类型
基本类型:
boolean、byte、char
short、int、long
float、double
包装类型:
Boolean、Byte、Character
Short、Integer、Long
Float、Double
2 数组
2.1 数组的申明
1)String[] aa = new String[长度]; --只有长度没有内容的空数组
2)String[] bb = {"aa","bb","cc"}; --有元素有长度的数组
3)String[] cc = new String[]{"aa","bb","cc"} --有元素有长度的数组
2.2 Array方法
数组大小: size
数组、、、
2.3 Arrays工具类
数组转为集合:Arrays.asList(数组); --集合转为数组:Collection。toArray();
数组转字符串:toString(数组);
3.4 Arrayutils工具类
数组合并:addAll(数组1,数组2);
数组反转:reverse(数组);
3 集合
集合:单列集合(collection)、双列集合(map);
3.1 单列集合collection
arrayList:底层由数组实现,有序可重复,查询快,增删慢;
-- 扩容:初始值为0,初次扩容10,再次扩容1.5倍;初始值指定x,扩容为1.5倍;
linkedList:底层由链表实现,增删快,查询慢;
vector:线程安全;
HashSet:底层结构为哈希表(64)+链表(8)(实质上是hashMap),不重复; --哈希表>64,链表>8,则链表转为红黑树
TreeSet:底层数据结构是 二叉树;--可以传入比较器,常用于排序;
LinkedHashSet:hashSet的子类,底层是LinkedHashMap =数组+双向链表;
集合的遍历方式:fori循环、增强for、迭代器Iterator(hasNext、next 与while搭配)
collection接口常用方法:add、remove、contains、size、isEmpty、clear、addAll、containAll、removeAll
3.2 双列集合map
HashMap:底层为 数组+链表/红黑树 --key可以有null,线程不安全
HashTable:底层为 数组+链表/红黑树 --key不能有null,synchronized线程安全
TreeMap:构造器可以传入比较器,常用于存放需要排序的键值对数据
concurrentHashMap:使用synchronized+CAS;synchronized对数组节点加锁,CAS对数组节点进行自旋;
LinkedHashMap:
Properties:继承hashTable,可以读取xxx.properties 文件,存放键值对数据。
map的遍历方式:containsKey、keySet、entitySet、values
map接口常用方法:put、remove、get、size、isEmpty、clear、containsKey
map的扩容:
新建的map容量为0,加载因子为0.75;当第一次添加元素时,扩容为16;当添加的元素达到16*0.75 = 12 时,再次扩容为原来容量的2倍即32,一直循环。
链表红黑树转换:
当哈希表容量达到64,并且链表容量达到8时,链表就会转为红黑树。
3.3 collections工具类
针对 集合(collection与map)操作的工具类;
常用静态方法:
三 、常用API
1 数学运算
Math类:
bigDecimal类; 线程安全的,对超过16位有效位数字的精确运算的api
因为 Double.valueOf(String) 和Float.valueOf(String) 会丢失精度,所以 new BigDecimal(double值); 或 new BigDecimal(Double.valueOf(xxx)); 不推荐使用,一般使用 new BigDecimal(string值);也就是 new BigDecimal(Double.toString(xxx))或 BigDecimal.valueOf(xxx);
2 系统操作
System类:
exit () 终止当前允许的虚拟机,入参为0表示人为终止
currentTimeMillis() 获取当前系统时间的毫秒值
3 runtime 运行环境
获取runtime对象 Runtime.getRuntime();
availableProcessors(); 获取虚拟机所使用的处理器数量
totalMemory(); 获取Java虚拟机中的内存总量
freeMemory(); 获取Java虚拟机中可用内存量
exec("某个程序.exe地址路径"); 启动某个程序,并返回该程序的对象。
destroy(); 关闭程序
4 时间日期
4.1 jdk1.8 之前日期时间api
4.1.1 new Date(); 获取当前日期时间
getTime(); 获取当前时间毫秒值
new Date(毫秒值); 或 setTime(毫秒值); 获得毫秒值对应的日期时间
4.1.2 new simpleDateFormat(); 格式化时间, yyyy-MM-dd HH:mm:ss EEE a/p
format(); 日期时间格式转为 字符串格式
parse(); 字符串格式时间转为 日期格式
4.1.3 new Calendar(); 日历对象,获取、修改年月日时分秒等
获取 calendar对象 Calendar.getInstance();
get(单位); 获取年月日时分秒周
getTime(); 获取当前日历
set(单位,数字); 修改日历属性值
add(单位,数字); 日历属性增减操作
注:
1 很多方法过期被淘汰
2 获取到年份是从1900开始的,不是实际年份值
3 线程不安全
4 都是可变对象,修改后丢失原始时间信息
5 不能精确到纳秒(精确度为毫秒)
4.2 jdk1.8新日期时间api
4.2.1 代替date:
Instant类: 时间戳/时间线
4.2.2 代替Calendar:
xxx.now(); 获得对应的对象
LocalDate: 年月日
LocalTime:时分秒
LocalDateTime:年月日时分秒
ZoneId:时区
ZonedDateTime: 带时区的时间
4.2.3 代替SimpleDateFormat:
DateTimeFormatter: 用于时间的格式化和解析
两种格式化方法:
DateTimeFormatter formatter = new DateTimeFormatter(“yyyy-MM-dd HH:mm:ss”);
1)String date = Formatter.format(LocalDateTime.now());
2) String date = LocalDateTime.now().format(formatter);
4.2.4 其他:
Period:时间间隔 (年月日)
LocalDate start = LocalDate.of(2023,02,03);
LocalDate end = LocalDate.of(2025,01.02);
Period period = Period.between(start,end);
获取间隔多少年 period.getYears();
获取间隔多少月 period.getMonths();
获取间隔多少日 period.getDays();
Duration:时间间隔(时分秒纳秒)
LocalDateTime start = LocalDateTime.of(2023,02,03,01,01,01);
LocalDateTime end = LocalDateTime.of(2025,01.02,02,02,02);
Duration duration = Duration.between(start,end);
获取间隔多少天 duration.toDays();
获取间隔多少毫秒 duration.toMillis();
获取间隔多少纳秒 duration.toNanos();
...
四、线程
五、jdk新特性
六、SQL及数据库
1 SQL语法
1)库操作语句:
create database xxx
show databases
alter database xxx ...
drop database xxx
2)表操作语句:
creat table xxx(
字段 类型(长度) not null default 默认值 comment 注释
) engine=数据库驱动 auto_increment = 主键自增 default character=默认编码 collate=使用编码 comment = 描述
3) 删除表
drop table xxx
4) 修改表
新增列 alter table xxx add 列 类型
删除列 alter table xxx drop 列
修改表名 alter table xxx rename to 新名字
5)增删改查
增: insert into xxx (列。。。) values(值。。。),全字段增可以不写列
删:delete from xxx where 。。。
改:update xxx set 列=值 where 。。。
查:select 列 as 别名 from xxx where 。。。
6)条件
区域范围:between。。。and。。。、in (。。。)
模糊匹配:like %。。。%
空值条件: is null、is not null
排序:order by asc/dsc
7) 聚合函数
count、max、min、sum、avg、distinct
8) 分组查询
where 。。。group by 字段 having 字段=value
1where对原始数据进行过滤,having对分组后的数据过滤
9)分页
limit (当前页-1)*每页条数,每页条数;
10)联表查询
表1 inner join 表2 on 。。。
表1 left join 表2 on 。。。
表1 right join 表2 on 。。。
表1 full join 表2 on 。。。
11)管理用户
2 MySQL数据库 与oracle数据库比较
2.1 数据类型
MySQL:
int、float、double 等数值型,
varchar、char 字符型,
date、datetime、time、year、timestamp 等日期型。
oracle:
number(数值型),varchar2、varchar、char(字符型),date(日期型
2.2 主键
mysql:使用 auto increment自增, oracle:
2.3 单双引号
mysql: 可以使用双引号, oracle:只使用单引号
2.4 分页操作
MySQL: 使用limit分页, oracle:使用嵌套查询实现
2.5 事务提交
MySQL:默认自动提交,可以修改为手动提交, oracle:手动提交,commit指令或按钮
2.6 对事务的支持
MySQL:innoDB存储引擎在宕机的情况下才支持事务, oracle:完全支持事务
2.7 事务隔离级别
MySQL:可重复读, oracle:读已提交
2.8 并发性
MySQL:表锁为主,锁粒度大,并发性能低, oracle:行锁为主,粒度小,并发性能高
2.9 日期转换
MySQL:使用dateFormat函数, oracle:使用date函数或to_char函数
3 数据库事务
3.1 概念:数据库系统中一组完整的操作,要么全部执行,要么全部回滚。
3.2 特性:原子性、一致性、隔离性、持久性。
3.3 事务的隔离级别:读未提交、读已提交、可重复读、序列化
读未提交:一个事务在执行的过程中,能够读到其他事务未提交的数据; --可能出现脏读
读已提交:一个事务在执行的过程中,能够读到其他事务已提交的数据; --可能出现 不可重复读(指原始数据可能被修改并提交,导致不能重复读取原来数据了)
可重复读:一个事务在执行的过程中,能够读取到其他事务新增的数据,但是不能读取到已修改提交的数据 --可能出现幻读
序列化:所有事务排队执行
4 SQL优化
4.1 建索引
优先考虑 where和order by中所使用的列加索引;
索引个数不能过多;
建索引字段不能大量重复;
4.2 可能使索引失效的操作
is null、<> != 、or、(not)in、like、等号左侧使用算术运算、对字段使用函数等操作
4.3 更高效的操作代理低效操作
(not)exists 代替 (not)in;
varchar代替 char, ---节约空间;
具体字段代替 *;
避免频繁建临时表,当向临时表插入大量数据时,使用select into 代替 create table,并且及时删除临时表; --避免产生大量log,
>= 代替 >;
union all 代替 union;
where子句 代替 having; --on、where、having这三个都是删选条件的子句,on最先执行,where次之,hiving最后;
4.4 SQL书写顺序
当使用join联表查询时,小表在前,大表在后;
4.5 提倡使用
多表联查时,尽量使用别名; 因为别名可以减少SQL的解析时间;
4 redis
七、spring
八、servlet
servlet(server applet) 就是一个接口,定义了Java类被浏览器访问到(Tomact识别)的规则。
1 执行原理:
web.xml版本:浏览器访问路径--->web.xml文件,标签记录servlet实现类路径---->Tomcat创建对应servlet实现类对象---->调用servlet实现类server方法(Java项目方法)
注解版本: @WebServ(“/url”)
相当于springMVC的@RequestMapping 注解
2 生命周期
servlet 中的三个方法
init()服务启动是执行,创建servlet
server() 浏览器调用一次执行一次,,,
destroy()服务器停止时,销毁servlet
3 静态资源与动态资源
3.1 静态资源:直接返回到浏览器进行解析使用,所有客户访问结果都一样,例如:HTML,css,JavaScript
3.2 动态资源: 需要先转换为静态资源,再返回到浏览器进行解析使用,所有客户访问结果不一样,例如:servlet、jsp、php、、、
4 网络通信的三要素
IP 、端口、传输协议
4.1 传输协议:
tcp:三次握手,速度慢,比较安全
udp:速度快,不安全
http:基于TCP、IP的高级协议;默认端口80
5 http协议:
5.1 特点:一次请求对应一次响应;无状态:每次请求之前独立,不交互数据
5.2 请求格式:
请求行:
Request URL: http://127.0.0.1:9000/api/v1/admin/info?token=xxx
Request Method: GET 请求方式
Status Code: 200 请求状态
Remote Address: 127.0.0.1:9000 请求地址
Referrer Policy: strict-origin-when-cross-origin
请求头:
请求体:
JSON格式的数据
5.3 请求方式:
get:
post:
patch:
delete:
6 restful风格
6.1 四要素:
面向资源,使用名词
URL中体现版本
根据http不同方法,进行不同的资源操作
使用JSON 格式传输数据
6.2 http 格式 查询数据:
GET ip:port/v1/user/1
响应{code:0,msg:成功,data:{name:小虎,age:18}}
新增数据:
POST ip:port/v1/user 请求体 {name:小虎,age:18}
响应{code:0,msg:成功,data:{name:小虎,age:18}}
更新数据:
PUT ip:port/v1/user/1 请求体{name:小虎}
响应{code:0,msg:成功}
删除数据:
DELETE ip:port/v1/user/1
响应{code:0,msg:成功}
7 servlet容器中request
6.1 继承结构: Tomcat中requestFacade --继承 --> httpServletRequest --继承--> servletRequest
6.2 request功能:
获取请求行数据:
getMethod() 获取请求方式
getContextPath() 获取虚拟路径
getServletPath() 获取servlet路径
getQueryString() 获取请求参数
getRequestURL() 获取请求URI
getRequstURL() 获取请求URL
getRemoteAddr() 获取客户主机IP地址
获取请求头数据:
getHeader(String key) 根据名称获取请求头的值
获取请求体数据:(post专属)
setCharacterEncoding(“utf-8”) 设置流的编码
getReader() 获取字符输入流
getInputStream() 获取字节输入流
8 servlet容器中response
设置响应行:
setStatus(int status) 设置响应行状态
sendError(int sc) 设置响应行错误信息
设置响应头:
addHeader(String name,String value) 增加响应头
setHeader (String name,String value) 设置响应头
设置消息体:
getOutputStream() 获取字节输出流
getWriter() 获取字符输出流
9 IO流
IO:input与output
流: 是抽象的一串连续动态的数据集合
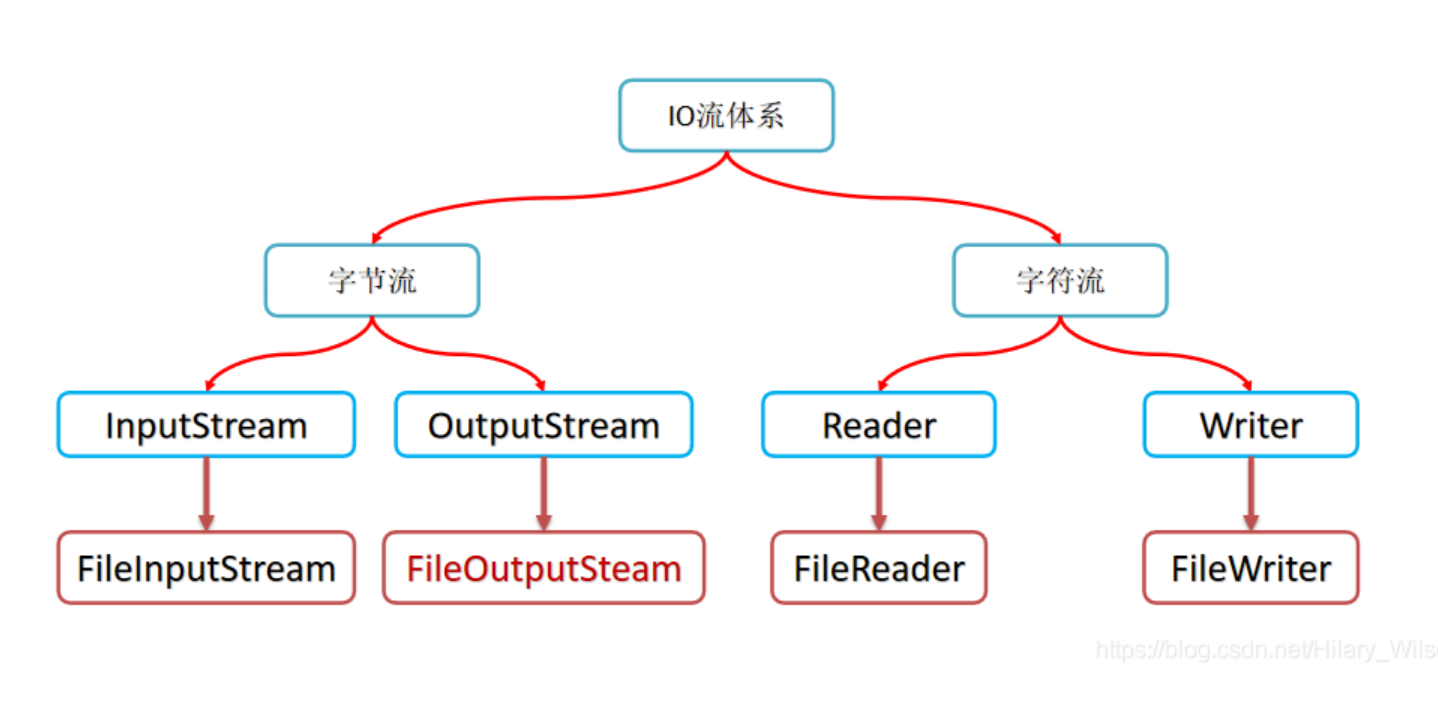
字节输入流返回的是byte,字符输入流返回的是int,二者若没有读取到数据,返回的是 -1;
读写操作:read读流、 writ写流
关闭:close
处理流:bufferedInputStream、bufferedOutPutStream,用于包装处理 节点流(上图中的流)来提高效率。
10 过滤器
10.1 概念:
基于servlet实现,并在servlet之外 对request和response 进行修改,主要用于客户请求的预处理或者响应后置处理;
流程: web请求---<httpServletRequest>--->过滤器-----<httpServletRequest>----> servlet的server方法
10.2 实现
实现filter接口,重写 init() 初始化、doFilter()做过滤逻辑、destroy() 销毁过滤 等方法
类上注解 :
@WebFilter("/xxx")指定过滤URL中含有 xxx
@Order(级别参数) 参数越小优先级越高
init() :
项目启动时只初始化一次
doFilter():
参数:servletRequest、servletResponse、filtChain
destroy() :
项目停止时,执行一次
11 监听器
11.1 概念:
基于servlet实现,用于监听web 变化情况而做出相应的变动。主要用于 在线人数等
11.2 三类8种监听器:
1 监听生命周期
ServletRequestListener、HttpSessionListener、ServletContextListener
2 监听值的变化
ServletRequestAttributelistener、HttpSessionAttributeListener、ServletContextAttributeListener
3 针对 session中的对象
监听session 中的Java 对象(是JavaBean直接实现监听器的接口)
11.3 实现
类上注解:@WebListener
按需实现以上 接口,或者自定义
12 拦截器
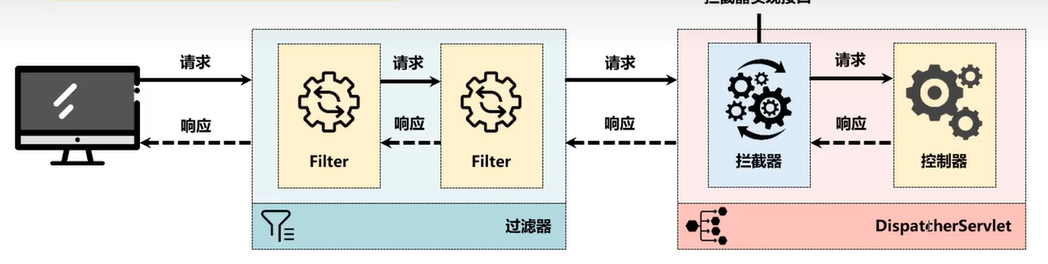
12.1 概念
基于springMVC实现,与dispatchServlet捆绑一起实现功能;是属于servlet下一层的内容,是为了更好的对控制层的类进行过滤处理,主要用于拦截处理敏感词等操作
12.2 实现
实现HandlerInterceptor接口
重写 preHandler、postHandler、afterHandler方法
preHandler 在进行控制层执行之前调用,返回值为TRUE执行目标路径,FALSE则不执行目标路径
postHandler 在控制层方法执行完成之后调用
afterHandler 在控制层处理操作完成之后调用
九、springMVC
一个基于MVC设计的轻量级web框架,是servlet+JSP+JavaBean的实现。
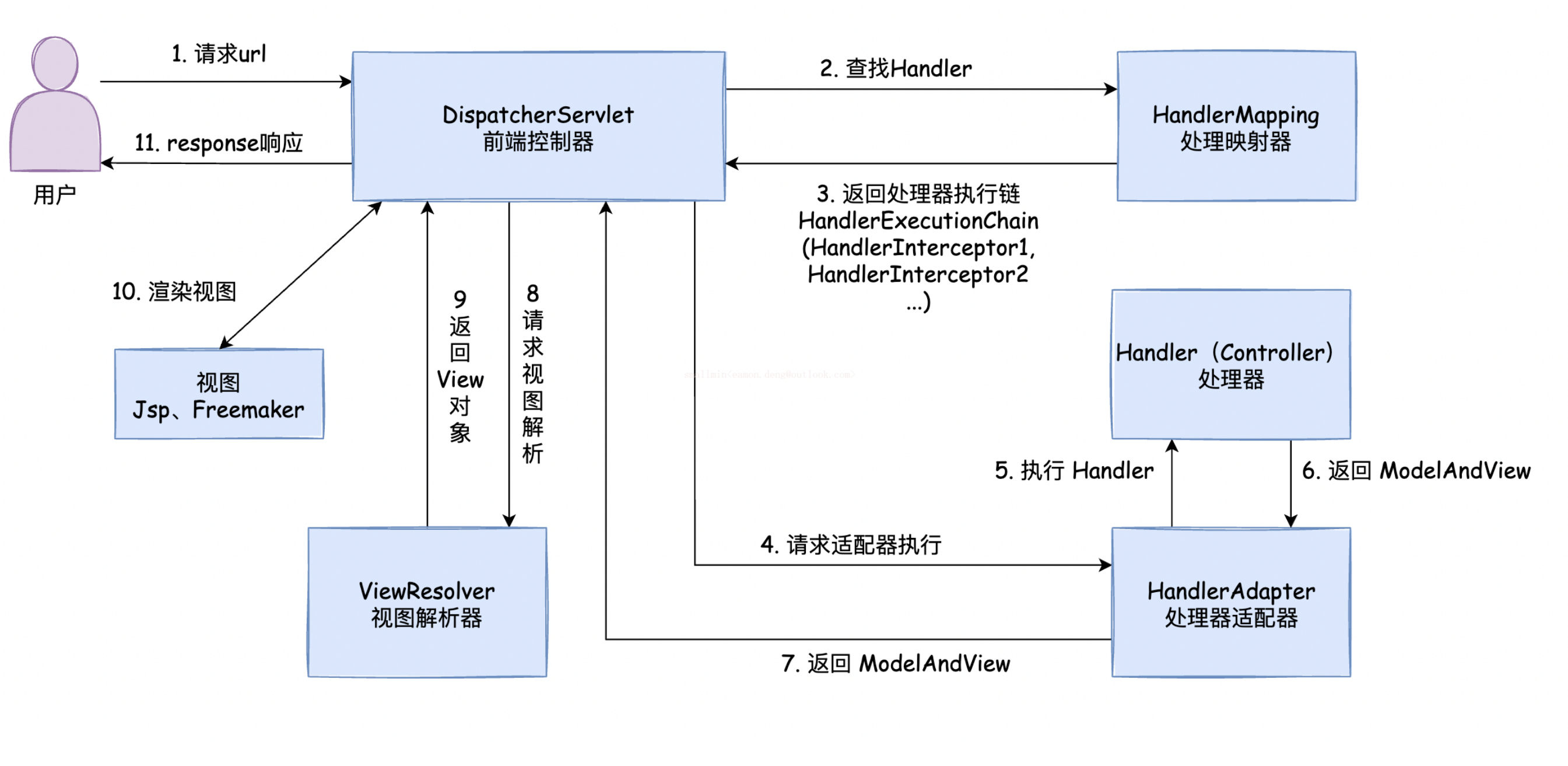
1 组成
dispatcherServlet 是 springMVC核心,主要负责获取请求,并将请求分配给相应的处理器。
handlerMapping 处理映射器,根据请求的URL,返回处理器执行链
handlerAdapter 处理器适配器,根据映射器找到handler处理器。
handler 处理器,也就是Controller
view resolver 视图解析器
2 常用注解
@Controller 注册bean对象
@RequestMapping 给控制器指定可以处理的URL
@RequestBody 将前端发送过来的 JSON或xml 数据封装到对应的形参Javabean对象上
@ResponseBody 将controller返回的对象,通过转换器转化为指定的格式,直接写入http response body中,也就是直接返回JSON或xml数据,不走视图解析器。
@GetMapping@PostMapping
@Requestparam 将请求参数传递给controller方法的形参上
@pathVariable 将URL中的占位符映射到controller方法的形参上
十 、springboot
十一 、mybatis
一款优秀的持久层框架,用于简化jdbc
1 基本原理
架构设计:
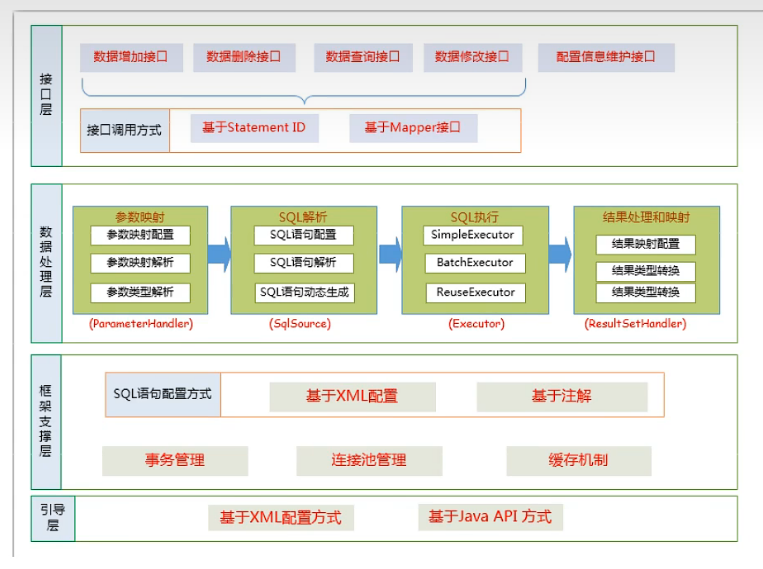
执行流程:
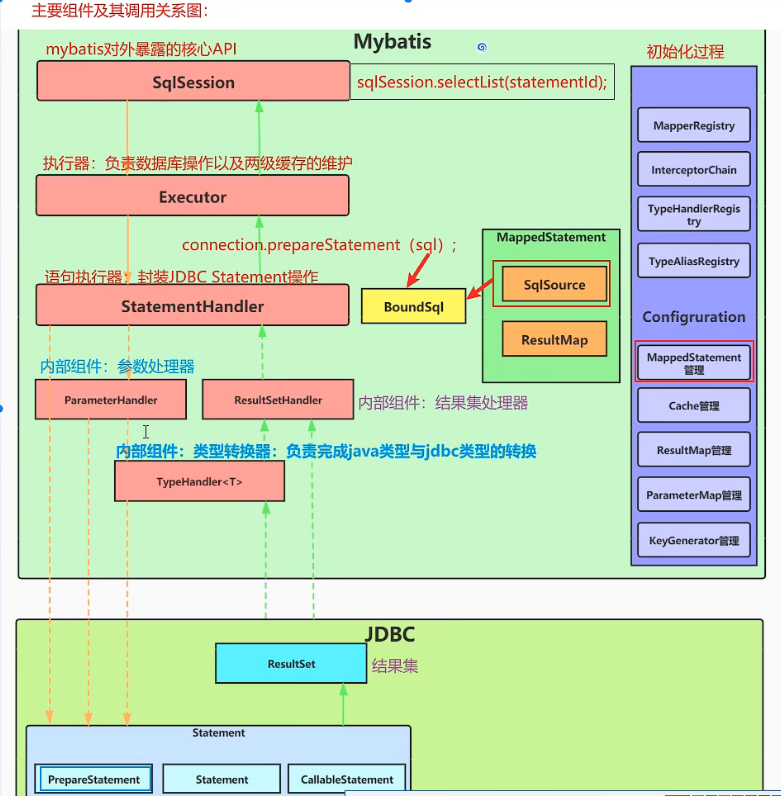
1 jdbc:
jdbc执行流程: 加载数据库驱动-->创建数据库连接-->设置入参执行SQL-->返回结果集
存在的弊端:硬编码、频繁创建连接、复杂结果处理
注:
持久层:负责将数据保存到数据库的那一层代码
框架:一个半成品软件,是一套可重用的、通用的、软件基础代码模型
2 基于xml文件书写SQL
2.1 参数传递原理:
2.1.1 入参为散装时
把mapper接口方法入参封装为map,然后SQL语句使用${} 或 #{} 获取参数值
1.1 默认情况下每个参数被封装为 两对map键值,按照参数顺序,key为arg0或param1,此时SQL语句#{arg0} 或 #{param1} 获取参数;
1.2 使用@Param(“map的key”)指定 map的key, sql 获取参数: #{map的key}
2.1.2 入参为数组或集合时,是argX和 @Param() 指定的值 作为key,数据或集合整体作为value进行 map封装。
2.1.3 入参为POJO对象时, 对象属性 与占位符对应绑定
2.1.4 入参为map时,key 与占位符对应绑定
2.2 #{}/${}/?
#{} 占位符,将变量转换为 ?再把变量中的参数添加到 ?,防止SQL注入
${} 拼接符,直接把变量中的参数拼接到SQL中,存在SQL注入的风险,使用场景:表明或列名作为变量时可以使用。
2.3 特殊符号的处理
1 转义字符,适用特殊字符少的情况
< == <
2 CDATA区,适用特殊字符比较多的情况
<![CDATA[ 特殊符号 ]]>
2.4 动态SQL
if标签:<if test=“aaa != null and aaa== 'xxx'”> #{aaa} </if?
choose(when,otherwise) 标签: 多条件中只有一个条件生效,对应Java 中 switch(case default)
trim标签 <where>、<set>
foreach标签:
<foreach collection = "注解param中的值" item="item"> open="(" separator="," close=")">
#{item}
</foreach>
2.5 解决动态语句出现多余and或or
过渡语法: where 1=1 if ...
使用where标签: <where></where>,自动调节错误语法,比如去除多余and或or,或where
2.6 插入语句获取主键id
useGeneratedKeys 开启获取主键功能
keyProperty 指定获取的主键
<insert id="" useGeneratedKeys=true keyProperty="pkid">
2.7 更新语句动态实现
常规:update tableName set <if ...> name = #{},</if> <if ...> name = #{},</if> ... where id = #{}
使用<set>标签可以解决动态标签多余的 , 号问题:
update tableName <set> <if ...> name = #{},</if> <if ...> name = #{},</if> </set> ... where id = #{}
3 基于注解书写SQL
直接在mapper接口方法上使用 @Select、@insert、@Update、@Delete 书写SQL语句
注意:适用于简单SQL
十二 、spring cloud
1 spring cloud openFeign
1.1 概念:
一种声明式、模板化的http客户端。
注: 与eureka 配合使用
声明式:就像调用本地方法一样调用远程方法,无需感知操作远程的http请求。
1.2 引入依赖 spring-cloud-starter-openfeign
1.3 相关配置
# 连接超时时间(防止由于服务器处理时间长而阻塞调用),单位:ms
feign.client.config.myDefault.connect-timeout=5000
# 读取超时时间,单位:ms
feign.client.config.myDefault.read-timeout=5000
# gzip压缩配置
feign.compression.request.enabled=true
feign.compression.response.enabled=true
# 默认的Feign日志记录
feign.client.config.myDefault.logger-level = BASIC
##
feign.compression.request.enabled=true
##支持的格式
feign.compression.request.mime-types=text/xml,application/xml,application/json
##阈值
feign.compression.request.min-request-size=2048
1.4 @FeignClient
客户端调用类上使用FeignClient(“eureka中服务名称”)注解,请求方法上使用 springMVC注解即可实现调用
1.5 http协议中压缩传输:
客户端请求头携带 Accept-Encoding: gzip deflate ------>服务端则会将返回数据压缩成gzip 文件发送给服务端,并在其请求体中 携带 Content-Encoding:gzip
2 Eureka
2.1 概念
微服务架构中的“通讯录”,记录了服务和服务地址的映射关系。当服务之间相互调用时,先从注册中心查询信息,再调用目标服务。
主要作用:服务发现、路由、负载均衡、故障转移
2.2 常见的注册中心
NetFlix Eureka:
Alibaba Nacos:
Apache Zookeeper:
2.3 核心组件
Eureka Server: eureka服务,通过Register、Get、Renew 等接口提供服务的注册和发现
Application Server(Provider):被治理的服务,把自身的服务实例注册到eureka server中
Application Client(consumer):服务调用方,通过eureka server获取服务列表,消费服务















 986
986











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









