






正如某位大师说的那样,字符串的算法一般都不简单,确实,任何关于字符串的算法在理解上都并不是很简单。
Manacher算法是著名的最长回文子串的算法。首先来了解一下什么是最长回文子串
最长回文子串
什么是回文?正读和反读都相同的字符序列为“回文”。
对于一个字符串来说,可以有多个回文的子串,最长的那个便是最长回文子串 关于最长回文子串有很多算法,但是其中最为厉害的便是Manacher算法,它的时间复杂度是,是最快的最长回文子串的算法。
关于Manacher(马拉车)算法,我之前就在一次偶然的情况下听说过,但是当初并没有认真的学过,只是粗略的了解了其思想以及代码实现,今天我特意认真的学了一下这个马拉车算法,为了巩固,特意发布此文。
(一)中心扩散法
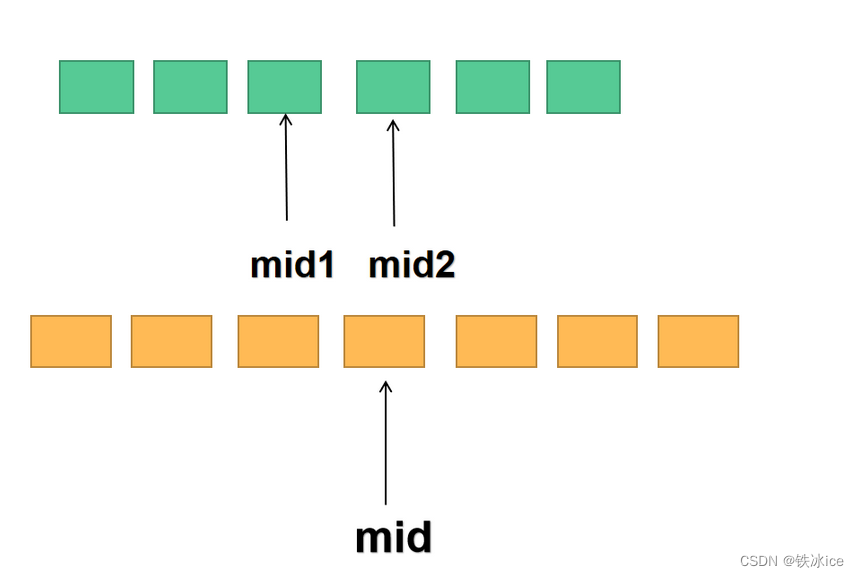
本质还是一个双指针。中心扩散法每次从最中间的字符开始依次往左右两边扩散。因此可以遍历每个字符,求以它们为中心的最长回文子串,然后得出最终结果。
但是这样就有一个问题,对于每个字符来说,以它们为中心的回文字符串长度可能是奇数,也可能是偶数,这个时候就需要对字符以奇数和偶数的情况进行判断。具体措施是奇数串的中心是一个字符,因此left=right=i。而偶数串是两个字符,left=i,right=i+1,两种情况都需要考虑,最终比较哪个情况的最长回文子串较大,就是哪个情况
此外,我们还需要考虑假设我们找到了最长回文子串的长度,该怎么求?
我们设这个长度为len
则如果len是奇数,那么我们可以很简单得到它的开始和结束
那么如果是偶数呢
实际上可以变为一个公式
因为对于奇数来说:
所以可以归纳得出一个串的开始和结束
另外还需要知道的是,如果某一次扩散后left和right指向的字符不相等,则可以说明最长的回文子串是[left+1,right-1]
则它的长度是:
知道这些我们可以很轻松的写出代码
def find(left,right):
while left>=0 and right<length and s[left]==s[right]:
right+=1
left-=1
return right-left-1
S=input()
length=len(S)
Max_len=0
for i in range(length):
len1=find(i,i)
len2=find(i,i+1)
lens=max(len1,len2)
if lens>Max_len:
start=i-(ans-1)//2
end=i+ans//2
Max_len=lens
print(S[start:end+1])
很显然时间复杂度是
同时每一次还需要两次的find操作。
Manacher算法使用了中心扩散的方法但是速度非常的快
(二)修改字符串
马拉车算法的第一步就是插入特殊字符。通过这个操作可以保证不需要考虑该回文子串的奇偶性。
Manacher算法在一个串S的每个字符之间以及串S前后都插入一个特殊字符“#”,即可保证回文子串一定是奇数
证明假设S有n个字符,那么“#”的个数一定是n+1。则新的S的个数为
,一定是奇数
代码实现:
new_s="#".join([x for x in s])
new_s="#"+new_s+"#"
(二)计算半径数组
这个是Manacher算法最核心的地方,半径数组,一般用p表示。
p[i]表示以i号位上的字符为中心的最长回文子串的半径长度,注意不包括i字符。
如何计算p数组?这就是Manacher算法的核心
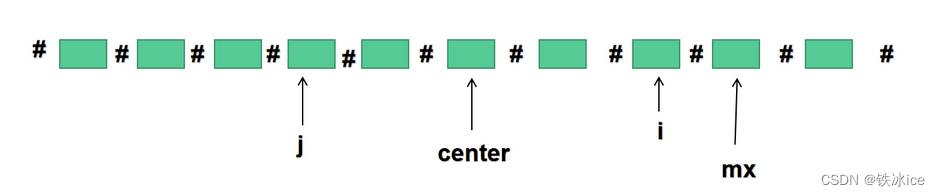
假设center为当前最靠右边的回文子串的中心,mx为该回文子串的最大的右边界。
当我们的要求的i号位字符位于该回文子串所能管辖的范围的时候,我们做出i关于center的对称点j,根据两点间的中点坐标公式我们可以知道j=2*center-i
此时我们可以通过p[j]来直接得到p[i]
但是我们能直接用p[i]==p[j]吗?不行
考虑以下两种情况
情况一:p[j]比较大,使得如果给了p[i],则p[i]+i>mx,这样的时候,不能直接让p[i]=p[j],因为p[i]=p[j]只有在当前回文字符串的管辖范围内才能成立,因此超过的部分我们无法得知。所以如果p[j]较大,我们只能让p[i]取最大,最大是多少,显然mx-i是不包括i的最大的半径长度。故公式p[i]=min(p[j],mx-i)公式是这么来的。在此之后,就是暴力的查找。即让mx后面的字符与其关于i的对称点进行比较即可。
情况二:如果j指向的刚好是原字符串的左边界,此时我们可以很轻松的得到p[j]=1,但是p[i]指向的并不是右边界,因此它还有可能会扩充长度,因此也需要后面的暴力查找。
if i<mx:
j=2*center-i
p[i]=min(mx-i,p[j])暴力查找部分
while new_s[i-p[i]-1]==new_s[i+p[i]+1]:
p[i]+=1上面的暴力查找并没有判断边界,实际上这是有原因的,原因是Manacher实际上对于字符串的改变并不是只插入特殊字符那么简单,它还在字符串的左右插入不同的字符,这样到达边界一定while循环条件一定不成立,直接退出
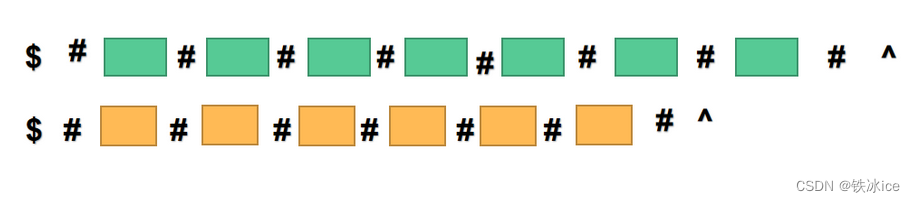
new_s="#".join([x for x in s])
new_s="$#"+new_s+"#^"前面的要求都是i在当前回文子串的管辖范围内,那么如果这个i不在该回文字符串的管辖范围内,那就只能通过暴力查找了。
后面如果我们发现如果该回文字符串还能更加靠右,即i+p[i]>mx的时候,我们需要更新一下center和mx。原因是我们希望i尽量被当前的最靠右的回文子串所包围。
if i+p[i]>mx:
mx=i+p[i]
center=i最后就是每一次算出来的p[i]都需要与当前最长的回文子串相比较,如果比它大就更新。
if 2*p[i]+1>len(max_str):
max_str=new_s[i-p[i]:i+p[i]+1]
max_len=p[i]这里主要p[i]是不包括中心的半径长度,因此整个回文长度应该是它的两倍加上中心字符个数。
实际上这里也说明了原字符串的最长回文子串的长度为p[i],因为当前的最长回文子串一定是”#“开始,”#“结尾。那么可知当前的最长回文子串的非”#“个数为n,那么“#”的个数为n+1,而我们知道原来的回文子串的长度应该是2n+1。正好与p[i]相等
for循环从1开始一直到到倒数第二个字符,执行完for循环后就可以得出最大的回文子串了。
然后输出。输出Python非常方便只需要用replace方法把里面的”#“去掉即可
print(max_str.replace("#",''))
s=input()
if len(s)==1: #特判,如果字符串只有一个字符则最长的回文子串即为它自己
ans=s
new_s="#".join([x for x in s])
new_s="$#"+new_s+"#^"
#print(new_s)
n=len(new_s)
p=[0]*(n)
center=0
mx=0
max_str=''
#初始化中心点,右边界均初始化为0
max_len=0
for i in range(1,n-1):
#i=0时即第一个字符是”$"无需判断,i=n-1时即最后一个字符”%“无需判断
#对于任意一个i要先判断这个i在不在右边界管辖范围内
if i<mx:
j=2*center-i
p[i]=min(mx-i,p[j])
while new_s[i-p[i]-1]==new_s[i+p[i]+1]:
p[i]+=1
if i+p[i]>mx:
mx=i+p[i]
center=i
if 2*p[i]+1>len(max_str):
max_str=new_s[i-p[i]:i+p[i]+1]
max_len=p[i]
print(max_len)
print(max_str.replace("#",''))














 746
746











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









