







1.如何防止消息丢失
- 生产者:1)使用同步发送 2) 把ack设置成1或者all,并且同步的分区数 >= 2
- 消费方:把自动提交改为手动提交。
( 1 )acks=0: 表示producer不需要等待任何broker确认收到消息的回复,就可以继续发送下一条消息。性能最高,但是最容易丢消息。
( 2 )acks=1: 至少要等待leader已经成功将数据写入本地log,但是不需要等待所有follower是否成功写入。就可以继续发送下一条消息。这种情况下,如果follower没有成功备份数据,而此时leader又挂掉,则消息会丢失。
( 3 )acks=-1或all: 需要等待 min.insync.replicas(默认为 1 ,推荐配置大于等于2) 这个参数配置的副本个数都成功写入日志,这种策略会保证只要有一个备份存活就不会丢失数据。这是最强的数据保证。一般除非是金融级别,或跟钱打交道的场景才会使用这种配置。
2.如何防止消息的重复消费
一条消息被消费者消费多次。如果为了消息的不重复消费,而把生产端的重试机制关闭、消费端的手动提交改成自动提交,这样反而会出现消息丢失,那么可以直接在防治消息丢失的手段上再加上消费消息时的幂等性保证,就能解决消息的重复消费问题。
幂等性如何保证:
mysql 插入业务id作为主键,主键是唯一的,所以一次只能插入一条
使用redis或zk的分布式锁(主流的方案)
说说你的项目中怎么防止消息的重复消费
对于每个消息都有一个全局唯一的ID对应。
消费者消费时回去redis查询,第一次消费因为redis没有此id,可以消费,消费完将全局id存入redis中,
第二次消费相同的消息时,发现redis已经有此ID ,不消费丢弃该消息。
3.如何做到顺序消费
一个topic对于一个partition
发送消息时指定partition
发送方:保证消息顺序消费,且消息不能丢失,使用同步发送,ack不能设置为0
kafka:一个topic对于一个partition,发送消息时指定partition
接收方:消费者组只能有一个消费者
我的项目不用考虑顺序消费
kafka的顺序消费会牺牲掉性能。
4.解决消息积压问题
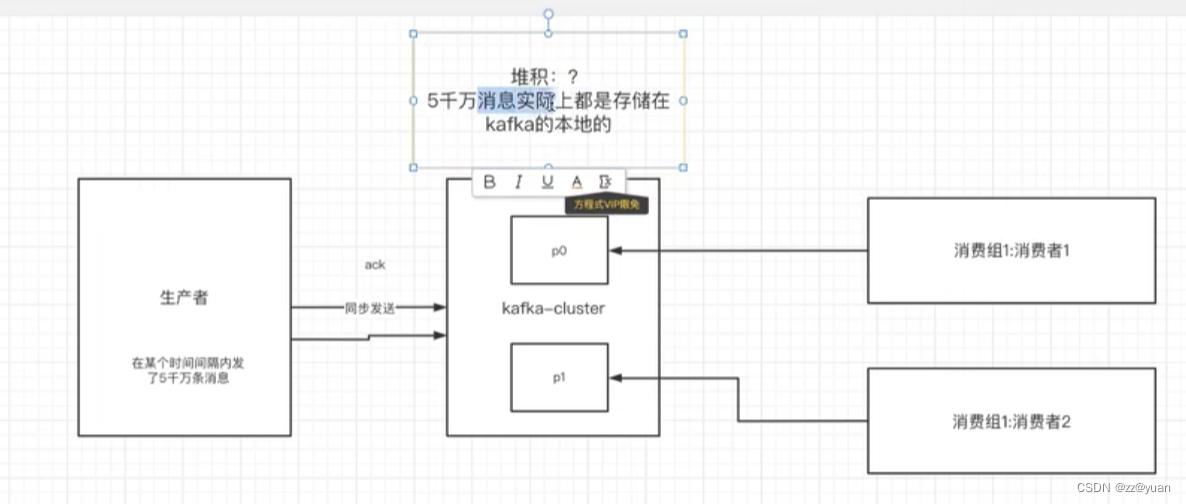

方案一:在一个消费者中启动多个线程,让多个线程同时消费。——提升一个消费者的消费能力(增加分区增加消费者)。
方案二:如果方案一还不够的话,这个时候可以启动多个消费者,多个消费者部署在不同的服务器上。其实多个消费者部署在同一服务器上也可以提高消费能力——充分利用服务器的cpu资源。
方案三:让一个消费者去把收到的消息往另外一个topic上发,另一个topic设置多个分区和多个消费者 ,进行具体的业务消费。
如果是因为本身消费能力较弱,我们可
以优化下消费逻辑,比如之前是一条一条消息消费处理的,
这次我们批量处理,比如数据库的插入,一条一条插和批量插效率是不一样的。

5.延迟队列
延迟队列的应用场景:在订单创建成功后如果超过 30 分钟没有付款,则需要取消订单,此时可用延时队列来实现
创建多个topic,每个topic表示延时的间隔
topic_5s: 延时5s执行的队列
topic_1m: 延时 1 分钟执行的队列
topic_30m: 延时 30 分钟执行的队列
消息发送者发送消息到相应的topic,并带上消息的发送时间
消费者订阅相应的topic,消费时轮询消费整个topic中的消息
如果消息的发送时间,和消费的当前时间超过预设的值,比如 30 分钟
如果消息的发送时间,和消费的当前时间没有超过预设的值,则不消费当前的offset及之后的offset的所有消息都消费
下次继续消费该offset处的消息,判断时间是否已满足预设值

















 626
626











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









