









一.基础常识
在操作系统中,有硬盘,内存,磁道,扇区
数据和索引会存储在磁盘中
B+树等数据结构会放到内存中
1.1数据库读取数据
首先数据库获取数据时,
需要先找到数据索引,读入内存中
在根据内存中的索引,将数据读入内存
1.1.1数据表很大时,性能是否会下降?
有索引存在时
增删数据受到影响,会变慢
单条查询时,(有索引)查询一样会很快
并发查询时,搜到磁盘的影响(带宽)查询速度会变慢
二.Redis的简介和安装
2.1redis的简介
Redis是一个开源(BSD许可),内存存储的数据结构服务器,可用作数据库,高速缓存和消息队列代理。它支持字符串、哈希表、列表、集合、有序集合,位图,hyperloglogs等数据类型。内置复制、Lua脚本、LRU收回、事务以及不同级别磁盘持久化功能,同时通过Redis Sentinel提供高可用,通过Redis Cluster提供自动分区。
网址
https://www.redis.net.cn/
https://redis.io/commands/
2.1.1 由来
两个基础设施
以太网 tcp/ip的网络
冯洛伊曼体系的硬件
磁盘级别的数据库读取速度慢,内存级别的数据读取快但是会很贵
2.2为什么要用redis
memchace中key对应的value没有类型的概念
mencache返回vlue网卡io,client要有实现解码的代码(客户端逻辑实现)
当客户端(client)想要取出value中某个元素时,redis可以通过类型快速定位该元素
计算向数据移动
二进制安全
reids取数据是字节流的
底层存取数据也是按照字节去存的
类型不重要,重要的是每个类型都有对应的取值方法
2.3redis的安装
2.3.1linux版本 --通过网络安装
sudo yum install wget
$ wget http://download.redis.io/releases/redis-5.0.4.tar.gz
$ tar xzf redis-5.0.4.tar.gz
$ cd redis-5.0.4
$ yum install gcc 原因是redis依赖cc环境
$ make distclean 清理一下编译环境
$ make
网络安装启动数据测试
启动 $ src/redis-server
测试
$ src/redis-cli
redis> set foo bar
OK
redis> get foo
“bar”
2.3.2 通过下载好的redis安装
make install PREFIX=/…/…
vi/vim /etc/profile --添加环境变量
source /etc/profile
…/util/install_serve.sh
2.3.3 redis 的常用命令
service redis_6379 start
service redis_6379 stop
service redis_6379 status
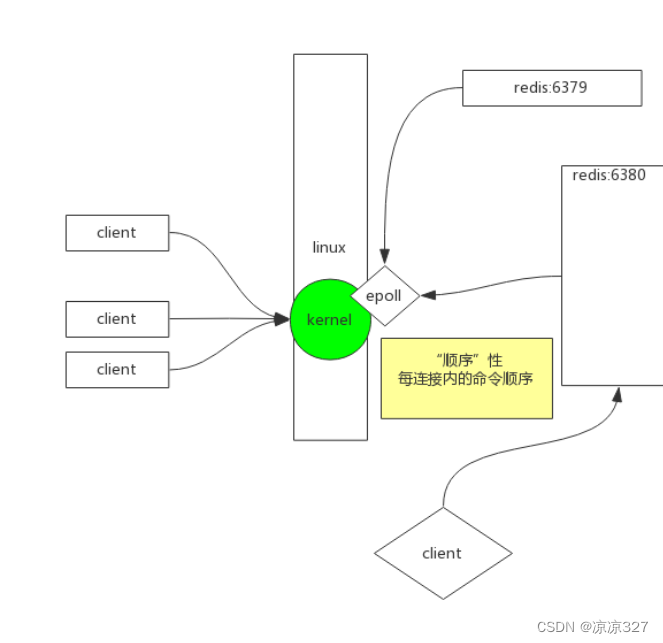
三.Epoll (eventpoll)
EPoll(event poll)是Linux系统内核为处理大量并发套接字而作出的改进。它是在2.6.x内核中引入的,用于替代之前的select和poll,解决了大并发、大并发连接导致的性能下降问题。EPoll 可以高效地处理数以万计的并发连接。
EPoll的原理是在内核中维护一个事件表,应用程序向内核注册一组文件描述符以及对应的事件(比如数据可读事件,连接关闭事件等),然后应用程序可以向内核获取哪些文件描述符发生了哪类事件。由于这些接口本质上是系统调用,因此它们可以节约大量的用户空间和内核空间两者之间的上下文切换开销。另外,与select和poll需要遍历整个监听集合不同,EPoll企通过回调机制来实现高效地获取已就绪的连接。
EPoll主要有以下三个函数:
epoll_create(): 创建一个epoll的句柄。epoll_ctl(): 控制某个epoll文件的描述符,可以注册、修改或者删除。epoll_wait(): 等待事件的产生,相当于事件监听函数,调用此函数程序会被阻塞。EPoll为很多高性能的服务器软件提供了强力的支持,例如Nginx、Redis、Memcached等。
3.1 AIO | BIO | NIO
这些术语通常用来描述 Java 中的不同类型的 IO(输入/输出)操作。
BIO (Blocking I/O): 在传统的 IO 模型中,当一个线程发起一个 IO 操作后,该线程只能等待操作完成后才能进行其他操作。在等待的过程中,该线程无法做任何其他事,这就是所谓的阻塞。BIO 适用于连接数目较少且固定的架构,这种方式对服务器资源要求比较高。
NIO (Non-blocking I/O): 在 Java 1.4 中引入了 NIO,其中最大的特点就是引入了非阻塞模式。在 NIO 中,线程可以请求操作后立即返回,它会继续执行其他代码,然后在操作完成后再来检查操作的结果。这是通过所谓的 “selector” 实现的,selector 会不断的轮询注册在其上的 channel,如果有一个 channel 发生读或者写操作,这个 channel 就处于就绪状态,会被 selector 检测出来,然后通过 SelectionKey 可以知道可读可写事件的集合。
AIO (Asynchronous I/O): AIO 是 NIO 2.0 的主要组成部分,在 Java 1.7 中引入。在 AIO 模型中,一旦开始了一项读或写操作,那么无需等待它的完成。可以直接返回并做其他事情,当操作完成后会收到通知。这是真正的异步 IO,即不需要额外的线程来处理 IO 事件,而是直接将 IO 事件和处理逻辑绑定起来,提交给系统,当 IO 事件触发时,系统会自动调用处理逻辑。
各种 IO 模型的选择首先还需要看具体应用的业务类型,比如请求处理时间长短,QPS 等因素来综合考虑其性能表现。
3.2redis的epoll实现
Redis 使用了epoll(在Linux上)作为其底层的 IO 多路复用技术。epoll 是Linux下多路复用IO接口select/poll的增强版,它能显著提高程序在大量并发连接中只有少量活跃的情况下的系统CPU利用率。
在 Redis 中,epoll 被用来让单个线程能并发地处理多个网络连接。所有的网络事件都通过该 epoll 事件循环来处理,包括新连接的接收,接收命令数据,向客户端发送命令回应等。
epoll 能甚至可以处理 thousands of connections 通过一个单线程,由于Redis的主要设计目标是效率,所以选择使用 epoll 作为其网络事件处理机制。
这是 epoll 在 Redis 中的一个基本使用流程:
- 初始化:系统调用 epoll_create 创建一个 epoll 对象,返回一个描述符。
- 注册:系统调用 epoll_ctl 来注册需要监听的 socket 描述符。
- 循环:系统调用 epoll_wait 来等待注册的 socket 描述符上有事件发生。
- 处理:一旦 epoll_wait 返回,redis 便处理所有已经就绪的 socket。
需要注意的是,虽然 Redis 的主干使用单线程模型,但它也会使用额外的线程来执行诸如清除过期键等后台任务。这些操作不通过epoll事件循环进行管理。不过,这些线程通常的工作量较小,主要的负载仍然在主线程上,且通过 epoll 事件循环进行处理。
这就是为什么我们经常听说 Redis 是单线程模型的原因,其主要操作是在一个epoll事件循环的单线程当中进行的。
四.redis启动和库进入及帮助
redis默认 16个库 可以在配置文件中修改 redis-cli -p port -n num
可以 切库 select num
redis-cli --raw 可以get的时候取中文 ,否则为二进制编码
4.1help 命令
redis-cli -p port 先进入客户端
help @generic | help @string | help @list | help @set | help @sorted_set |
help @hash | help @pubsub | help @transactions | help @connection |
type k 查看类型 | help @…
例子
五.redis类型的介绍
5.1 String 类型
https://redis.io/commands/?group=string
object help --查看help命令
OBJECT encoding k 查看详细类型
5.1.1 字符串
append k v 追加
strlen k 获取长度
setrange k offset v 替换/覆盖
mset k1v1 k2 v2 --多k设置
set
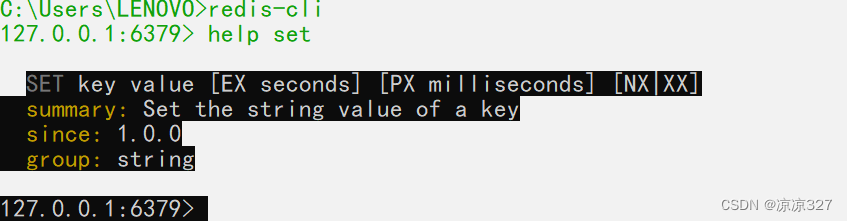
nx 不存在才去设置key 应用场景分布式锁
xx 存在的时候才能去 操作key
mget k1 k2 --多k获取
get k --获取值
getrange k start end 截取
getset k v return oldvalue
msetnx k v k v
mgetnx k k …
上述命令都可以 通过 help 指令名去查看如何使用
5.1.2 数值
incrby k num 对值进行+num操作
# key 存在且是数字值 redis> SET rank 50 OK redis> INCRBY rank 20 (integer) 70 redis> GET rank "70" # key 不存在时 redis> EXISTS counter (integer) 0 redis> INCRBY counter 30 (integer) 30 redis> GET counter "30" # key 不是数字值时 redis> SET book "long long ago..." OK redis> INCRBY book 200 (error) ERR value is not an integer or out of rangedecrby k num 对值进行-num操作
incrbyfloat k num 对值加+num 浮点数
incr k 对值进行+1操作
decr k 对值进行-1操作
5.1.2.1 数值案例
抢购 ----------------
详情页
点赞,评论数
秒杀
规避并发下,对数据库的事务操作,完全由redis内存操作代替
上述都是高并发 ,直接数据到数据库的情况下,数据库会崩掉。
所以采用redis作为中间件,进行数据的缓冲
5.1.3 bitmap位图
setbit k offset v – 这里的offset对应的是 二进制的字节的位数
一个字节八位 00000000 00000000redis> SETBIT bit 10086(10086位) 1 (integer) 0 redis> GETBIT bit 10086 (integer) 1 redis> GETBIT bit 100 # bit 默认被初始化为 0 (integer) 0bitcount k 开始的字节 结束的字节 统计key出现的次数
其实就是统计1出现的次数
bitpos k bit 开始的字节 结束的字节 查二进制位
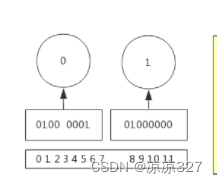
例如 --采用上面的图作为k
bitpos k 1 0 0 返回 1
bitpos k 1 0 1 返回 1
bitpos k 1 1 1 返回 9
意思是 查偏移量 当前k的这个值(1)从字节(0) 到字节(1)的偏移量是多少
bittop operation(and | or | null) destkey k [k] and 全1为1…or 有1为1 null 取反
触发两个k 的二进制位的 逻辑运算
redis> SET key1 "foobar" "OK" redis> SET key2 "abcdef" "OK" redis> BITOP AND dest key1 key2 (integer) 6 redis> GET dest "`bc`ab" BITOP AND destkey(自定义的) srckey1 srckey2 srckey3 ... srckeyN BITOP OR destkey(自定义的) srckey1 srckey2 srckey3 ... srckeyN BITOP XOR destkey(自定义的) srckey1 srckey2 srckey3 ... srckeyN BITOP NOT destkey(自定义的) srckey
5.1.3.1 位图案例
统计用户登录天数,且窗口随机
setbit userkey 30(第30天) 1
bitcount userket 0 1 (统计0-16天用户登录天数)
送礼物,大库备货(备库多少礼物去送出去)(面试)
setbit 20231001 1(标识用户) 1 (这里举个例子 23年10月1号 只有我登录了 )
setbit 20231005 10 1 (23年10月1号 其他人登录了 )
bittop or destkey 20231001 20231005 (这里就是合并这个区间内 活跃用户数)
bitcount destket 0 -1 (最后得出结论,在某个区间有多少活跃用户)然后就准备礼物送出去
5.2 list类型
https://redis.io/commands/?group=list
help @list 查看list所有操作
lindex k index 取key 中 对应索引的值
redis> LPUSH mylist "World" (integer) 1 redis> LPUSH mylist "Hello" (integer) 2 redis> LINDEX mylist 0 "Hello" redis> LINDEX mylist -1 "World" redis> LINDEX mylist 3 (nil)lrang k start end 从什么地方开始查看元素
redis> RPUSH mylist "one" (integer) 1 redis> RPUSH mylist "two" (integer) 2 redis> RPUSH mylist "three" (integer) 3 redis> LRANGE mylist 0 0 1) "one" redis> LRANGE mylist -3 2 1) "one" 2) "two" 3) "three" redis> LRANGE mylist -100 100 1) "one" 2) "two" 3) "three" redis> LRANGE mylist 5 10 (empty array) redis>lrem k count v 移除多少个元素
redis> RPUSH mylist "hello" (integer) 1 redis> RPUSH mylist "hello" (integer) 2 redis> RPUSH mylist "foo" (integer) 3 redis> RPUSH mylist "hello" (integer) 4 redis> LREM mylist -2 "hello" (integer) 2 redis> LRANGE mylist 0 -1 1) "hello" 2) "foo" redis>linsert k before|after privot(这个是v) v 插入
redis> RPUSH mylist "Hello" (integer) 1 redis> RPUSH mylist "World" (integer) 2 redis> LINSERT mylist BEFORE "World" "There" (integer) 3 redis> LRANGE mylist 0 -1 1) "Hello" 2) "There" 3) "World" redis>ltrim k start end 两边删除元素
redis> RPUSH mylist "one" (integer) 1 redis> RPUSH mylist "two" (integer) 2 redis> RPUSH mylist "three" (integer) 3 redis> LTRIM mylist 1 -1 "OK" redis> LRANGE mylist 0 -1 1) "two" 2) "three" redis>blpop 阻塞 单播队列

移除并获取列表或块中的第一个元素,直到可用为止
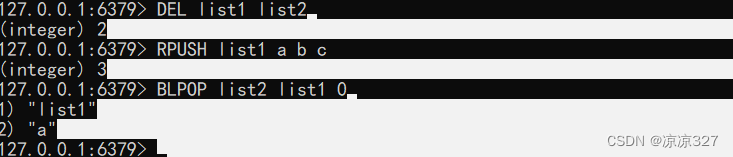
也可理解为栈 lpush+lpop rpush+rpop
redis> DEL list1 list2 (integer) 0 redis> RPUSH list1 a b c (integer) 3 redis> BLPOP list1 list2(这里list2是不存在的) 0 1) "list1" 2) "a"数组 lset k index v
redis> RPUSH mylist "one" (integer) 1 redis> RPUSH mylist "two" (integer) 2 redis> RPUSH mylist "three" (integer) 3 redis> LSET mylist 0 "four" "OK" redis> LSET mylist -2 "five" "OK" redis> LRANGE mylist 0 -1 1) "four" 2) "five"队列 lpush+rpop
左进 ,右出
底层为链表
5.3 hash类型
https://redis.io/commands/?group=hash
help @hash
hget k option
hset k option v
redis> HSET myhash field1 "Hello" (integer) 1 redis> HGET myhash field1 "Hello" redis> HSET myhash field2 "Hi" field3 "World" (integer) 2 redis> HGET myhash field2 "Hi" redis> HGET myhash field3 "World" redis> HGETALL myhash 1) "field1" 2) "Hello" 3) "field2" 4) "Hi" 5) "field3" 6) "World" redis>hincrby | hincrbyfloat
redis> HSET myhash field 5 (integer) 1 redis> HINCRBY myhash field 1 (integer) 6 redis> HINCRBY myhash field -1 (integer) 5 redis> HINCRBY myhash field -10 (integer) -5 redis> hincrbyfloat 同理hmset | hmget | hkeys | hvals | hgetall
redis> HMSET myhash field1 "Hello" field2 "World" "OK" redis> HGET myhash field1 "Hello" redis> HGET myhash field2 "World" redis> HMGET myhash field1 field2 nofield 1) "Hello" 2) "World" 3) (nil) 剩余的同理可得
5.4 set类型
https://redis.io/commands/?group=set
help @set
sadd k1 v1 v2… 添加
redis> SADD myset "Hello" (integer) 1 redis> SADD myset "World" (integer) 1 redis> SADD myset "World" (integer) 0 redis> SMEMBERS myset 1) "Hello" 2) "World" redis> sadd myset "test" (integer) 1 redis> SMEMBERS myset 1) "Hello" 2) "World" 3) "test" redis> SADD myset "a" "b" "c" (integer) 3 redis> SMEMBERS myset 1) "Hello" 2) "World" 3) "test" 4) "a" 5) "b" 6) "c"srem k v1 v2 … 移除元素
同上
smembers k 查看所有v
sunion k1 k2 并集
redis> SADD key1 "a" (integer) 1 redis> SADD key1 "b" (integer) 1 redis> SADD key1 "c" (integer) 1 redis> SADD key2 "c" (integer) 1 redis> SADD key2 "d" (integer) 1 redis> SADD key2 "e" (integer) 1 redis> SUNION key1 key2 1) "a" 2) "b" 3) "c" 4) "d" 5) "e"sdiff k1 k2 差集
spop k 取出一个
任意取出一个后,原set中就不存在了
应用场景 抽奖
redis> SADD myset "one" (integer) 1 redis> SADD myset "two" (integer) 1 redis> SADD myset "three" (integer) 1 redis> SPOP myset "one" redis> SMEMBERS myset 1) "two" 2) "three" redis> SADD myset "four" (integer) 1 redis> SADD myset "five" (integer) 1 redis> SPOP myset 3 1) "two" 2) "three" 3) "four" redis> SMEMBERS myset 1) "five" redis>sinter k1 k2 取交集
sinter 取交集不会生成新key,而下述方法会生成新key
sinterstore dest k1 k2
redis> SADD key1 "a" (integer) 1 redis> SADD key1 "b" (integer) 1 redis> SADD key1 "c" (integer) 1 redis> SADD key2 "c" (integer) 1 redis> SADD key2 "d" (integer) 1 redis> SADD key2 "e" (integer) 1 redis> SINTERSTORE key key1 key2 (integer) 1 redis> SMEMBERS key 1) "c" redis>srandmember k count 随机取count情况的value
redis> SADD myset one two three (integer) 3 redis> SRANDMEMBER myset "one" redis> SRANDMEMBER myset 2 1) "one" 2) "two" redis> SRANDMEMBER myset -5 1) "two" 2) "two" 3) "three" 4) "two" 5) "three" count
为整数:取出一个去重的结果集(不能超过已有集)
为负数:取出一个带重复的结果集,一定满足要的数量
为0:不返回 应用场景 抖音福袋抽手机
SRANDMEMBER myset 1 1台
SRANDMEMBER myset 2 2台
5.5 sortedSet类型
https://redis.io/commands/?group=sortedSet
https://www.runoob.com/redis/redis-sorted-sets.html
help @sorted_set
集合操作 – 并集 |交集 --权重| 聚合指令
zadd k score member s2 m2 …分值 成员
此处的 score 其实就是权重
排序实现增删改查速度
https://www.bilibili.com/video/BV1xv41137Yj/?spm_id_from=333.337.search-card.all.click&vd_source=0b4eb32d238e9a8aec6f01570cc479e1
跳跃表
跳跃表(Skip list)是一种数据结构,它在计算机科学中用于快速查找有序的元素。它是一种可以用并发执行的算法替代平衡树的数据结构。它由 William Pugh 在 1989 年提出。
跳跃表的基本思想是这样的:在一个有序的链表上,增加更多的前向指针,使得我们能更快地跳到我们想要的元素。一个节点的这种前向指针的数量是根据预定的概率决定的,这样,查找一个元素在平均和最坏的情况下时间复杂度都是 O(log n)。
跳跃表由很多层结构组成,最底层是原始的有序链表。每一层都是下一层的一个“快速通道”,每个节点在这一层的概率是 p,通常 p 取 0.5。只有在下层出现的节点才可能出现在上层,在第i层的节点比第i-1层的节点少。
对于一个查询操作,我们从最高层的链表开始搜索,如果当前节点的前向节点包含的键大于查找的键,那么在该层链表的搜索停止,并在下一层链表继续搜索,否则继续在当前层链表进行查找,直到找到相应的元素位置或者不可能存在的情况。
以下是跳跃表的一些主要操作:
搜索(Search):从最高层开始,如果当前节点的下一个节点的值比目标小,就向前移动;否则,向下移动,直到找到目标值。
插入(Insert):创建一个新节点,通过随机过程决定新节点的层数,然后插入相应的链位置。
删除(Delete):从链表中找到并删除节点,然后调整上层链表的指针。
跳跃表在Redis中广泛使用,因为它能提供高效的搜索、插入和删除操作,同时,跳跃表的内存消耗较小,而且更易于实现。
六.redis的进阶使用
6.1 管道
yum install nc --这个可以用来和redis建立 socket通信 命令发送 可以 nc localhost prot / echo -e “命令/n…/n” | nc localhost port
官网例子
$(echo -en “PING\r\n SET w3ckey redis\r\nGET w3ckey\r\nINCR visitor\r\nINCR visitor\r\nINCR visitor\r\n”; sleep 10) | nc localhost 6379)
+PONG
+OK
redis
:1
:2
:3
以上实例中我们通过使用 PING 命令查看redis服务是否可用, 之后我们们设置了 w3ckey 的值为 redis,然后我们获取 w3ckey 的值并使得 visitor 自增 3 次。
在返回的结果中我们可以看到这些命令一次性向 redis 服务提交,并最终一次性读取所有服务端的响应
6.2 发布与订阅
publish 通道名 message 推送消息
subscribe 管道名 接收信息可参考
https://www.redis.net.cn/tutorial/3514.html

6.3 事务处理
https://www.redis.net.cn/tutorial/3515.html
help @transactions


6.4 布置布隆过滤器实例
https://blog.csdn.net/listeningsea/article/details/132055401
https://blog.csdn.net/qq_52720916/article/details/129278482
mudle下载完成后 redis-service --loadmudle /…/…/xxx.so /…/…/xxx.conf 作用是在redis中多加了一些功能,比如 bloom
https://github.com/RedisBloom/RedisBloom/
wget https://github.com/RedisBloom/RedisBloom/archive/refs/tags/v2.2.0.zip
yum install unzip
unzip v2.2.2.zip
cd RedisBloom-2.2.0/
make
cp redisbloom.so /usr/local/src/redis/redis5(这里就要看你的具体路径)
redis-server /etc/redis/6379.conf --loadmodule /usr/local/src/redis/redis5/redisbloom.so
后期使用
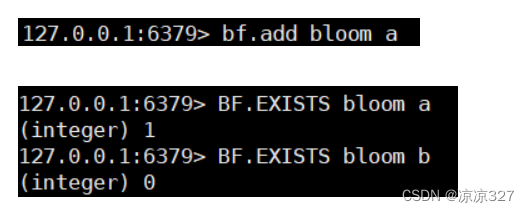
6.5 缓存击穿
缓存击穿是指热点key在某个时间点过期的时候,而恰好在这个时间点对这个Key有大量的并发请求过来,从而大量的请求打到db,属于常见的“热点”问题
拓展一丢丢
一个冷门的新闻或者一个冷门的人,突然爆火 “佛山电翰” “恐龙抗狼” “我是云南的…”
解决方案
1.预先设置热门数据,提前存入缓存
2.实时监控热门数据,调整key过期时长
3.二级缓存:对于热点数据进行二级缓存,并对于不同级别的缓存设定不同的失效时间。
4.设置分布式锁
6.6 缓存穿透
缓存穿透是指客户端请求的数据在缓存中和数据库中都不存在,这样缓存永远不会生效,这些请求都会被打倒数据库上。
即这个数据根本不存在,如果黑客攻击时,启用很多个线程,一直对这个不存在的数据发送请求 ,那么请求就会一直被打到数据库上,很容易将数据库打崩。
解决方案
1.缓存空对象
优点:实现简单,维护方便
缺点:额外的内存消耗,因为缓存了一些瞎编的id对应的空对象,但是可以通过给对象设置TTL解决,但是会造成短期的数据不一致
2.布隆过滤器(counting bloom)
优点:内存占用少
缺点:实现复杂,存在误判cukcoo
布谷鸟过滤器
3.其他
使用bitmaps类型定义访问白名单,或进行实时监控,和运维人员配合排查访问对象 和访问数据设置黑名单限制服务
6.7 缓存雪崩
缓存雪崩(Cache Avalanche)是指在同一时间大量缓存数据失效,从而导致大量请求直接击穿到数据库,可能会引发数据库宕机等严重问题。这种情况也称为 “缓存崩溃冲击” 或 “缓存崩溃震荡”。
缓存雪崩常见于以下两类情景:
- 当单个或多个高速缓存宕机或重启时,将导致大量请求直接转移到数据库。
- 在高速缓存的大量数据被设置为在同一时间点过期时。例如,如果使用一种策略将缓存在同一时间实施刷新,这可能会导致在所有缓存数据过期和重新填充缓存这两个时刻之间产生大量的数据库请求。
为预防缓存雪崩,以下的解决策略可供参考:
初始设置随机的 TTL(Time to Live):为缓存数据设定不同的过期时间,可避免各数据同时过期,从而防止大量请求同时冲击到数据库。
二级缓存:设定一级缓存和二级缓存,二级缓存的过期时间比一级缓存晚一些,即使一级缓存过期,二级缓存还能承接一部分请求,降低数据库的压力。
预防性地重新加载:在缓存数据过期之前,启动后端任务
击穿 数据库有,缓存没有
穿透 两者都没有
雪崩 缓存没有
6.8 数据库和缓存的区别
数据库和缓存是在计算系统中用于存储数据的两种不同的方式,它们的主要区别体现在数据的持久化、访问速度、数据的一致性和使用的硬件资源等方面,下面详细地介绍一下:
数据的持久化:数据库是用于长期存储数据的,即使在系统断电或重启之后,存储在数据库中的数据仍然存在,并且可以随时被读取和修改。而缓存通常是临时的,也就是说,当系统断电或重启时,缓存中的数据通常会丢失。一些高级的缓存系统,如 Redis,提供了持久化选项,但这并不改变其主要是为了临时存储和快速访问数据的性质。
访问速度:缓存的数据读取速度比数据库快得多。这是因为缓存一般存放在随机访问内存(RAM)中,而数据库通常存放在磁盘上,RAM的访问速度远远快于磁盘。
数据的一致性:由于数据的更新可能同时发生在数据库和缓存中,因此需要策略来处理数据一致性问题。如果一个数据项在数据库中进行了更新,而缓存中的该数据项还未同步更新,就可能造成数据的不一致。数据库中的数据是最权威,最准确的。
硬件资源:缓存一般使用内存,而数据库通常使用硬盘。内存是昂贵的,但访问速度快;而硬盘的存储成本相对较低,但访问速度较慢。因此需要根据读取速度和数据持久化需求来选择使用数据库还是缓存。
总的来说,数据库和缓存都是为计算系统服务的存储机制,它们各有利弊,但可以互补。缓存通常用于存储经常访问的数据,以减少对数据库的访问,在提高响应速度的同时,也能够减轻数据库的负担。
6.9 过期
Redis keys过期有两种方式:被动和主动方式。
当一些客户端尝试访问它时,key会被发现并主动的过期。
当然,这样是不够的,因为有些过期的keys,永远不会访问他们。 无论如何,这些keys应该过期,所以定时随机测试设置keys的过期时间。所有这些过期的keys将会从密钥空间删除。
具体就是Redis每秒10次做的事情:
1.测试随机的20个keys进行相关过期检测。
2.删除所有已经过期的keys。
3.如果有多于25%的keys过期,重复步奏1.
这是一个平凡的概率算法,基本上的假设是,我们的样本是这个密钥控件,并且我们不断重复过期检测,直到过期的keys的百分百低于25%,这意味着,在任何给定的时刻,最多会清除1/4的过期keys
更详细的解释
Redis是一个开源的内存中的数据结构存储系统,常被用作数据库、缓存和消息传递代理。Redis在处理数据的过期上有自己的特性和机制。
Redis允许为键设置生存时间(TTL, Time to Live)。一旦键达到设定的生存时间,它将会自动被系统删除。这在许多情况下很有用,例如在缓存层面,你可能希望一个键值对仅在一段时间内有效,之后自动过期。
设置过期时间可以使用以下两种命令:
EXPIRE key seconds:为给定的键设置过期时间(以秒为单位)。PEXPIRE key milliseconds:为给定的键设置过期时间(以毫秒为单位)。你也可以用
TTL key命令查询键剩余的过期时间。至于Redis的过期策略,虽然Redis会尝试以此确保键到达其TTL时能被及时删除,但由于其主要关注点在性能上,Redis的过期删除策略是惰性的,并非所有键都能准时删除。实际上,Redis有以下两种策略来处理键的过期:
惰性过期(Lazy Expiration):当你尝试访问一个键时,Redis首先会检测它是否过期,如果过期,则会删除这个键。这就是所谓的"惰性过期"。这种方式的优点是简单且节省CPU资源,但是如果有很多过期的键没有被访问,它们就会一直存在内存中,形成所谓的"过期键"。
定期过期(Periodic Expiration):为了缓解过期键引发的内存问题,Redis会定期随机选取一部分键,并删除其中已经过期的键。这种过期策略是一种折中的策略,Redis每秒会执行几次清理过程,以控制过期键占用内存的比例。然而,由于这种过期策略的随机性,有时候它可能删除了一些最近刚过期的键,而忽略了一些已经过期很久的键。
这两种策略并行处理键的过期问题,以实现在不影响Redis主要的读写性能的情况下,删除过期的键。这就是Redis处理过期键的整体策略。
七.redis持久化
7.1 持久化策略前的铺垫
7.1.1非阻塞+数据落地
在排快照的同时,redis继续对外提供服务就会造成时点混乱,维护成本很高
意思就是 数据 一边写一边改,最终生成的日志文件很可能不是正确的
7.1.2管道
衔接,前一个命令的输出作为后一个命令的输入
会触发创建子进程
7.1.1父子进程问题
父进程的数据,子进程能否看到?
在一般的操作系统设计中,子进程是父进程的一个副本,它继承了父进程的数据段、堆和栈等内容。所以在此意义上,对于在子进程创建之前存在的数据,子进程是能够看到的。然而,父进程和子进程之间是不共享这些数据的,他们有各自独立的地址空间,即使他们的地址空间开始时是相同的。
这意味着,子进程可以读取父进程中的变量值,但是它不能改变父进程中的那个变量。任何在子进程中对这些数据进行的修改,都是在它自己的地址空间中进行,不会影响到父进程。这就是所谓的“写时复制”(copy-on-write)策略。
"写时复制"是一种由许多操作系统用于效率地执行fork()系统调用的优化策略。 当进程调用fork()时,子进程不会立即创建所有的数据的副本,而是使用与其父进程相同的物理页面。只有当其中一个进程-父进程或子进程-试图修改这些页面时,操作系统才会创建页面的副本(复制),从而保持父进程和子进程的地址空间互不影响。
在某些特殊情况下,如需要父进程与子进程共享数据时,可以使用特定的进程间通信(Interprocess Communication, IPC)机制,例如管道(Pipe)、消息队列、共享内存等。
7.2 RDB策略
Redis通过创建.rdb文件来进行RDB持久化。这个文件是一个二进制文件,并在一系列的配置规则触发时,对数据库的当前状态进行快照。
快照创建过程:
- Redis使用fork操作创建一个子进程。
- 子进程开始对内存中的数据结构进行遍历,并按需要适当的编码写入新的.rdb文件。这个过程完全在内存中操作,所以不会阻止父进程继续处理命令。
- 当子进程完成新的rdb文件,替换旧的.rdb文件。
- 子进程退出。
创建RDB文件的触发条件可以是时间和写入操作数量的组合,你可以有多个这样的条件。因例,下面这组条件:
save 900 1
save 300 10
save 60 10000
这意味着在下列任一条件满足时,Redis会开始创建一个新的RDB文件:
- 如果至少有1个键在过去的900秒内被修改
- 如果至少有10个键在过去的300秒内被修改
- 如果至少有10000个键在过去的60秒内被修改
使用RDB做持久化的优点在于:
-
高效率的数据读取: 由于RDB文件是紧凑的二进制文件,Redis加载RDB文件的速度通常比读取和解析AOF文件要快得多。
-
好的数据完整性保护: 因为RDB是在子进程中创建的,这保护了主Redis进程不会在写入磁盘期间存在任何磁盘I/O。同时,它也使得数据的完整性得到了保护,因为新的RDB文件总是先写入临时文件,然后再替换旧文件。
然而,RDB的缺点是:
-
数据不一致: 根据你的
save配置,你可能会丢失最后一次快照和Redis停止之间的所有操作。如果你需要更高的数据一致性保证,AOF可能是一个更好的选择。 -
Fork操作可能导致性能开销: Fork操作需要复制父进程的地址空间,在数据集很大且内存资源有限的情况下,这可能导致显著的性能开销。这可能对大型的Redis实例有影响,尤其是创建快照时。
7.3 AOF 策略
7.3.1. AOF持久化的工作方式
当一个更改数据集的命令(如SET)被执行时,它会被追加写入到AOF文件中。这样,当Redis服务器重启时,它可以通过读取和重新执行这些命令来重建数据集。这就是为什么它被称为"Append Only File":所有新的更改都被追加添加到文件的末尾。
它的工作过程很简单:
- 当一个写命令到达,Append Only File除了在内存中执行这个命令外,还会将这个命令写入硬盘的AOF缓冲区。
- 根据fsync策略,Redis再决定是立即将数据从AOF缓冲区保存到硬盘上,还是延迟执行这个操作。
7.3.2. AOF与RDB的比较
AOF和RDB是Redis提供的两种数据持久化方法。使用RDB进行持久化,Redis会在指定的时间内,将内存中的数据生成快照并保存到硬盘。相较于这种定期持久化,AOF的方式则能提供更好的持久性保证。
具体的差异如下:
-
数据恢复性:AOF持久化将所有修改操作都写入日志,因此在Redis重启后,可以通过回放这些操作来恢复数据,恢复性更好。但是RDB则只能恢复到最后一次创建快照的时刻。
-
数据一致性:AOF具有比RDB更好的数据一致性。当Redis不期望停止时(比如说电源突然断电),AOF能保证所有写入操作都不会丢失(这也取决于AOF的fsync策略),而RDB则可能会丢失最后一次快照之后的所有数据。
-
性能开销:由于AOF持久化记录了每个写命令,因此 IO 吞吐量会比RDB方式要大,CPU与硬盘的负担也更繁重,对Redis的性能影响也更明显。
7.3.3. AOF的fsync策略
fsync是一个用于控制如何将数据从操作系统的缓冲区写入到物理磁盘的选项。这个选项的设置关系着数据安全和性能之间的平衡:
always模式可以最大化数据安全性,因为只要有一个写命令,就会立即将其写入硬盘。然而,每次磁盘操作都需要时间,特别是在传统机械硬盘上,这将对性能产生非常大的影响。everysec是默认的选项,每秒钟会将缓冲区的数据写入硬盘。这样,在最坏的情况下,你可能丢失最近一秒的数据。这是一种折中的选择,它在数据可靠性和性能之间取得了平衡。no指不主动进行fsync操作,完全依赖操作系统决定何时将数据写入硬盘。这种方式可以提供最好的性能,但在出现问题时,可能会丢失最近几秒钟的数据。
7.3.4. AOF与RDB的联合使用
在某些情况下,你可能希望同时使用AOF和RDB。这在数据恢复方面提供了最大的灵活性:如果AOF文件出现问题,你还可以从RDB快照中恢复数据。而且,RDB快照提供了一个非常方便的备份文件,你可以将其存放在远程位置以供灾难恢复使用。
7.3.5. AOF重写
随着Redis运行时间的增长,AOF文件可能会变得越来越大。为了避免这个问题,Redis 提供了一个叫做 bgrewriteaof的命令,它可以生成一个新的AOF文件,这个新的AOF文件的内容与旧的完全一样,但体积要小得多,因为它移除了所有冗余的写命令。
4.0 以前
删除抵消的命令
合并重复的命令
最终也是一个纯指令的日志文件4.0 以后
将老的数据RDB到AOF文件中,将增量的数据以指令的方式append到AOF中
AOF是一个混合体
利用了RDB的快
利用了日志的全量
7.3.6. 选择AOF还是RDB
这取决于你的具体需求。如果你需要最大的数据持久性,并且在Redis重启后,需要保证所有操作都被正确地恢复回来,那么应该使用AOF。如果你可以接受在Redis重启后,数据只恢复到最后一次快照的状态,并且希望获得更好的性能,那么你应该使用RDB。
7.4 磁盘存储
如果执行flushall/flushdb 在执行bgsave 以前的数据将会丢失
原因bgsava会生成一个rdb日志文件,是个二进制文件,读不懂+
flushall和flushdb是Redis提供的两个命令,用于清空数据库中的所有数据。其中flushdb只删除当前数据库中的数据,而flushall则会删除所有数据库中的数据。
bgsave命令是Redis的一个快照命令,它创建了一个包含当前所有数据的快照,并将其存储在磁盘中。如果你在执行flushall或flushdb之后执行bgsave,那么你将会得到一个空的快照,因为此时数据库中已经没有数据了。换句话说,执行bgsave不会恢复flushall或flushdb执行之前的数据。因此在执行flushall或flushdb之后需要特别小心,这种操作通常在完全清除数据库或进行某些特殊测试时才会执行。
如果你不希望丢失所有数据,那么你应该在执行flushall或flushdb之前执行bgsave或者开启AOF,这样Redis就会在磁盘中保留一份当前的数据快照。然后即使你执行了flushall或flushdb,也可以通过载入磁盘上的RDB文件或执行AOF中的命令来恢复数据。
7.5 淘汰策略
- 无淘汰(No-eviction):
当内存使用达到了上限,Redis 不会淘汰任何数据,而只是返回一个错误。这是默认的淘汰策略。 - 随机淘汰(Allkeys-random):
当内存使用达到了上限,Redis 会随机淘汰一些键。 - 最少使用淘汰(Allkeys-lru, Allkeys-lfu):
LRU (Least Recently Used) 基于键最后一次被访问的时间淘汰数据,越久没有被访问的键优先被淘汰。LFU (Least Frequently Used) 则是基于键被访问的频率进行淘汰,访问频率最低的键优先被淘汰。 - 基于过期时间的淘汰(Volatile-random,Volatile-lru,Volatile-lfu,Volatile-ttl):
这些策略只会淘汰已经设置了过期时间的键。Volatile-random 随机淘汰一些将要过期的键,Volatile-lru 和 Volatile-lfu 分别基于最后一次访问时间和访问频率进行淘汰,Volatile-ttl 则是优先淘汰那些过期时间最近的键。
八.redis集群
8.1 AKF
AKF模型是一个用于理解和设计服务型体系结构中的可扩展性、可用性和故障隔离的模型,由 Martin Abbott 和 Michael Fisher 提出。以下是 AKF 的三个核心原则:
-
Availability(可用性): 设计系统及其服务时,首要考虑的应是其中的可用性。采取如冗余设计、避免单点故障、管理和处理异常等措施,都能提高系统的整体可用性。
-
Keep things simple(保持简单): 这个原则强调服务应保持单一化,避免过度复杂。在设计服务时,遵守互斥且全面覆盖(MECE)的原则可以确保每个服务只做一件事,且不会重叠。最理想的微服务应该是简洁、易于理解,其角色和责任清晰易分。
-
Focus on fault isolation(专注于故障隔离): 为降低服务之间的相互依赖,从而防止一个服务的故障导致其他服务的故障,设计系统时应重点关注故障隔离。这通常意味着对服务进行深度的分解和隔离。一个好的故障隔离设计也可以加快错误识别和定位的速度。
来看一个具体的例子,令人非常熟悉的Redis。Redis 是一个开源的,内存中的数据结构存储,用作数据库、缓存和消息中间件。它有多种使用模式,我们选择其中三个来进行AKF模型的应用解释:
数据复制与可用性: Redis 允许在主服务器和一个或多个副本服务器之间进行数据复制,提供高可用性和数据持久性。当主服务器出现问题时,系统可以迅速切换到副本服务器,避免服务中断。这就是Availability(可用性)原则的体现。
Redis 简单易用: Redis 保持了极其简单的数据模型,以键值对的形式存储数据,使得学习、使用和维护都变得更加简单。同时,Redis 提供丰富的数据结构以满足各种需求,包括列表、集合、哈希等,但每种数据结构的功能都尽可能保持简单和一致。这符合Keep things simple(保持简单)原则。
隔离的 Redis 实例: 为了隔离不同服务的缓存,你可能会创建不同的Redis实例,每一个实例独立运行,使用独立的内存空间。这样,即使某个实例发生了问题,也不会影响其他实例的运行。这就体现了Focus on fault isolation(专注于故障隔离)原则。
8.1.1补充:
我们可以分为三个维度看待AKF
X 维度 :全量、镜像(主从复制)
Y维度 : 业务、 功能
Z维度 :优先级、逻辑
在系统的设计和扩展方面,Martin Abbott 和 Michael Fisher 提出了一个被称为 “XY&Z” 的可扩展性模型。在这个模型中,X, Y 和 Z 形象地代表着数据或者服务在不同维度上的分割或者划分,满足了AKF的原则。具体的:
X 维度:关注的是如何复制或镜像数据和服务以达到冗余和提高可用性。如果一个服务或数据有问题,那么系统可以立即切换到镜像来保持可用性。此外,实现全量镜像可以为负载平衡提供额外的能力。
Y 维度:关注的是服务和功能的分解。将复杂的系统拆分为职责更加明确、独立且较简单的组件,以提升可读性,便于维护和迭代,这就是业务和功能的分离来提高服务的单一职责和清晰度。
Z 维度:在高负载情况或数据量巨大的情况下,对数据或服务进行逻辑或优先级划分,以扩展服务的处理能力和存储容量。这种划分使得错误和故障可以局部化,并避免问题扩散到整个系统,也即提高了故障隔离的能力。
8.1.2 解决的问题
redis从单机变成了集群,解决了单点故障,容量有限,单台redis并发压力问题
8.1.3 引发的新问题
redis从单台变成集群
数据一致性问题就需要解决了
1.强一致性 :会导致AKF中的A遭受破坏
2.容忍数据丢失一部分
3.中间加同步阻塞kafka
8.2 主从复制高可用
Redis 主从复制简介:
主从复制是指将一台 Redis 服务器的数据,复制到其它的 Redis 服务器。在主从复制模式下,被复制的服务器称为主服务器,而接受复制的服务器被称为从服务器。主从复制的目的主要是为了数据冗余和数据备份,还可以用于在多个从服务器间进行读取操作的负载均衡。
Redis 主从复制的工作原理:
在 Redis 主从复制的过程中,从服务器会向主服务器发送一个 SYNC 命令。收到 SYNC 命令后,主服务器会开始执行 BGSAVE 命令生成 RDB 文件,并将此期间接收到的所有写命令缓存起来。然后将此 RDB 文件和所有缓存的写命令发送给从服务器。从服务器接收并载入这个 RDB 文件,然后执行所有接收到的写命令。这样,从服务器的数据集就和主服务器一模一样了。
Redis 主从复制的高可用:
Redis 主从复制对于构建高可用环境非常关键,不过通常主从复制应与 Sentinel 系统一起使用。Redis Sentinel 是 Redis 官方推出的高可用解决方案,本质是一个监控系统,用于监控多个 Redis 服务器(主服务器及其从服务器)的运行状态,并在主服务器出现故障时,能够自动将一台从服务器提升为新的主服务器,然后其他从服务器会自动连接新的主服务器进行数据复制。
请注意,单纯的主从复制无法解决所有高可用性问题,例如在网络分区、主服务器故障等情况下可能会有数据丢失或不一致的问题。因此,Redis 还提供了 Redis Cluster,这是一个自动分区的、支持主从复制的 Redis 集群系统。在 Cluster 模式下,数据被分散存储在多个节点上,每个节点都有主从复制结构,当某个主节点故障时,其对应的从节点会被自动提升为主节点,以提供服务,这真正地实现了高可用。
8.2.1 引发问题
1.(监控)统计不准确、不够势力范围
导致问题:网络分区–脑裂 (用人话说,找不到老大)
2.大于3的单数节点解决脑裂问题 n/2+1 过半
脑裂"(Split-Brain)是一个在分布式系统中常见的问题,在 Redis 的情境下,它指的是在主从复制或集群模式下,由于网络问题或者其他原因,导致从节点不能与主节点正常通信。在一定的条件下,这可能导致多个从节点被提升为主节点,这就形成了"脑裂"现象,即在一个瞬间,存在多个"主"节点。
下面是造成 Redis 脑裂的几种可能情况和如何应对:
- 网络分区:最常见的脑裂情况就是网络分区,即主节点和从节点(或者多个从节点之间)之间的网络连接中断。这时,各节点无法获取其他节点的信息,所以可能导致多个"主"节点的出现。为了避免这种情况,Redis Sentinel(哨兵模式)在选主过程中有 “多数派” 的原则,也就是说,只有当 Sentinel 节点中的多数能够互相通信,并且同意将一个从节点提升为主节点时,才认定真正的主节点。这样可以极大的降低脑裂现象发生的可能性。
- 主节点宕机或重启时:如果主节点突然宕机或重启,从节点可能临时失去和主节点的连接,如果同时有 Sentinel 在监控这个主节点,它可能会发起选举,将某个从节点提升为新的主节点。但是,如果旧的主节点在这个过程中恢复,且其数据并未改变(或者没有被新的主节点覆盖),那么就可能会有两个主节点同时存在,导致脑裂。为了解决这个问题,Redis 有一个 “短暂失效” 的策略,即 Sentinel 在主节点失去连接的一开始,并不会立刻发起选举,而是会等待一定的时间(sdown-timeout),只有在过了这段时间,主节点依然没有恢复,Sentinel 才会发起选举。
3.集群一般使用奇数台。
如果有偶数个节点,可能会发生分区(Partition),即两个部分的节点数量相等,这样在进行投票决定主节点时,可能会因为票数相同而无法决定出一个唯一的主节点,导致脑裂(Split-Brain)现象,这样会对数据一致性造成威胁。
例如,如果你有两个节点,一部分 Sentinel 选择了节点 A 作为主节点,另一部分选择了节点 B,那么就无法达成一致的决定。
相反,如果有奇数个节点,比如3个,5个或7个,那么在节点进行投票决定新的主节点时,总是能够有一个节点得到大多数的票数,这样就可以保证一致性,避免脑裂现象。
8.3 CAP原则
CAP原则又称CAP定理,指的是在一个分布式系统中,一致性(Consistency)、可用性(Availability)、分区容错性(Partition tolerance)。CAP 原则指的是,这三个要素最多只能同时实现两点,不可能三者兼顾。
8.4 redis主从复制
-
新的Replica(替代了Slave)术语: 在Redis 5.0中,术语’Slave’被替换为’Replica’,这主要是出于避免负面含义。虽然这个变化对 Redis 功能没有直接影响,但它确实改变了我们讨论和记录Redis主从复制的方式。
-
新的
REPLICAOF命令: 取代了SLAVEOF命令。这个命令设计用于改变复制的主服务器,可以在一个运行的服务器上使用REPLICAOF命令去启动复制或者关闭复制,不需要重启服务器。REPLICAOF :https://blog.csdn.net/norang/article/details/119965408
-
增量复制: 在早期版本中,每次同步都要完全复制主节点的数据,这在处理大量数据时可能会导致问题。从Redis 5.0开始,新增了增量复制特性,部分同步成为可能。只有当一个副本与其主节点断开连接后又重新连上,而且主节点的复制积压缓冲区仍然包含了所有被副本错过的写命令,才会进行部分重同步。否则,仍会执行全量复制。
-
复制积压缓冲区: Redis 5.0版本引入了新的缓冲机制,名为复制积压缓冲区。它是主节点和副本(以前的从节点)在断开连接后用于数据同步的缓冲区。
-
混合持久性: 在Redis 5.0中,当
appendfsync设置为always或者everysec时,即使RDB后台保存失败,主节点也能够继续接收写命令。然后主节点会创建一个特殊的叫做rdb_last_save_replication_no的复制流,其中包含了执行bgsave命令时正在运行的所有写命令。
8.5 sentinel --哨兵
哨兵搭建 https://baijiahao.baidu.com/s?id=1754918449370959814&wfr=spider&for=pc
集群搭建https://blog.csdn.net/weixin_42675423/article/details/129971359
8.5.1 哨兵如何监视发现其他服务?
通过redis的发布订阅模式(向主机发送)
得到从机信息和其他哨兵信息
8.5.2哨兵和集群的区别
Redis的哨兵(Sentinel)和集群(Cluster)是两个服务Redis高可用性和分布式能力的两个重要方案,它们的关键差异在于他们解决的问题:
- Redis Sentinel是为了解决Redis服务单点故障的问题。通过使用主从复制和自动故障转移(failover)机制,当主节点宕机时,Sentinel可以自动选举一台从节点升级为新的主节点来提供服务,从而保证了服务的持续提供。在Sentinel系统中,所有的数据在一次内存中所有键值对的副本都是一样的(Replica)。Sentinel更关注于高可用性和故障切换。
- Redis Cluster则提供了一种方式将数据在多个节点上分片(Sharding),用以支持大数据集合并提供更高的交易处理吞吐量。在Cluster模式下,不同的key可能存储在不同的节点上。如果你需要处理的数据大于单个Redis节点的内存,那么可能需要使用Redis Cluster。Redis Cluster同时也提供复制和故障转移功能,主要目标是对高可用性和水平扩展性的支持。
如果你的关注点是数据的高可用性,你要尽量避免单点故障,那么Redis Sentinel可能是你的选择;如果你处理的数据量很大,并且需要在多个节点之间分布数据以提高性能和负载分摊,那么你可能需要使用Redis Cluster。实际上,这两种方案依据具体的需求和环境,往往会被结合使用。
8.6 算法(客户端实现即可) 解决数据没办法拆解问题
8.6.1 取模算法
Redis Cluster 用一种基于取模(modulus)的算法进行数据分片。这个算法被称为一致性哈希技术的一种简化版本。
在这个算法中,整个哈希表被分割为 16384 个不同的槽(slots)。当 keys 被存储到 Redis Cluster 时,keys 的 CRC16 值会被计算出来然后取模 16384,结果就是应该存储这个 key 的槽的编号。
具体的计算函数可以这样写 (Python 实现):
def key_slot(key):
"""Calculate the slot index of the given key"""
return crc16(key) % 16384
上面的 crc16 函数会返回 key 的 CRC16 校验和。
由于 Redis Cluster 规定,槽在 node 间是可以迁移的。换句话说,如果在运行中某一 node 压力过大,或者数据量过大,可以将这个 node 的某些槽迁移到其他 node 上,实现负载均衡。
在使用 Redis Cluster 的时候,一般推荐的 node 数目是 3 或以上。这是为了在部分 node 宕机的时候,还可以通过其他 node 来查询数据,提高 Redis Cluster 的可用性。
8.6.2 随机算法
-
在REDIS中的随机算法可能最常见用途就在于
RANDOMKEY和SRANDMEMBER命令。RANDOMKEY命令:这是一个简单的命令,它只返回数据库中的一个随机的 key。实现随机过程的方式是,来自Redis的内部哈希表数据结构(它存储所有的键值对)中选择一个随机的“bucket”并从bucket中的链表(如果存在)中select一个键。这个过程并不保证每个键有相同的机会被选中,因为这取决于哈希函数如何映射键到bucket上,但在实践中,这种方法非常有效和快速。
操作的大致步骤是:
- 先获取当前的hash表的大小,也就是桶(bucket)的数量。
- 然后在桶(bucket)的数量中产生一随机数,这个随机数就代表要挑选的桶(bucket)。
- 如果选中的桶(bucket)里没有任何数据,则重复上一步操作,直到找到一个非空桶(bucket)。
- 获得桶(bucket)内的所有键,然后从中随机获取一个键。
SRANDMEMBER命令:这个命令随机返回一个预先填写的集合的成员。具体的实现方式会根据集合的实现方式(它是一个小集合,使用整数数组实现,还是一个大集合,使用哈希表实现)有所不同。对于大集合,这与随机键的情况基本相同,对于小集合,实际上会创建一个所有元素的数组的复制版,并随机地返回一个。
操作的大致步骤为:
- 如果是小集合,先复制一份数组,然后在数组的长度中产生一个随机数,选取此随机数对应的元素作为返回结果。
- 如果是大集合,按照 RANDOMKEY 命令类似的方式,选中一哈希表的桶(bucket),在桶(bucket)内部随机选择一个元素作为返回结果。
8.6.3 哈希算法
参考链接 https://blog.csdn.net/loseyourself94/article/details/129561104
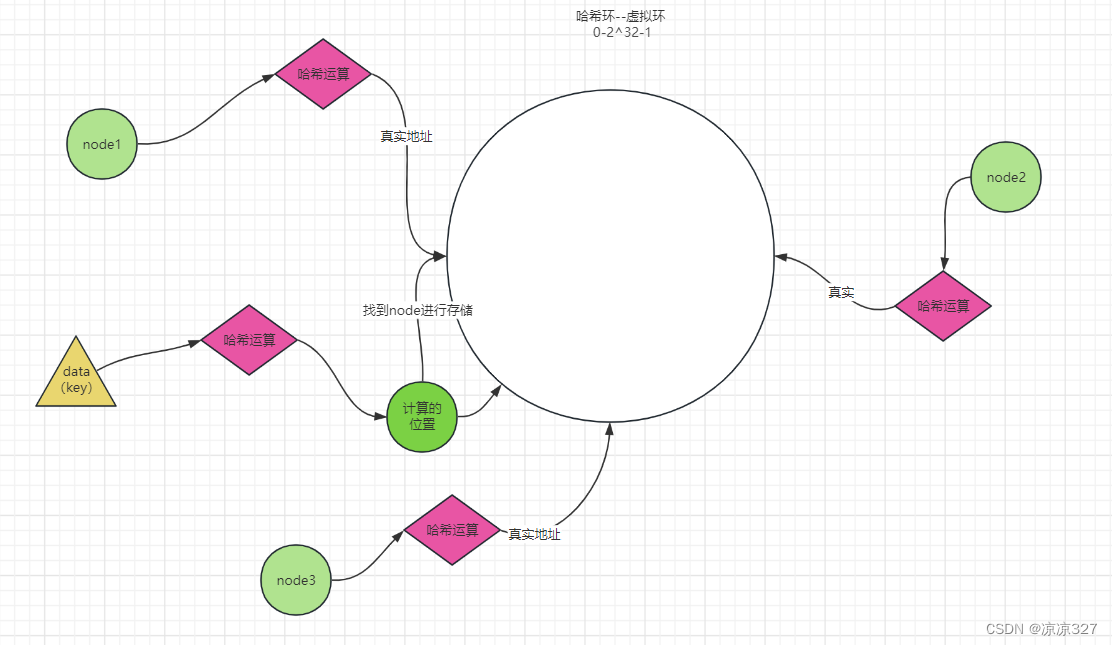
8.6.3.1 优缺点
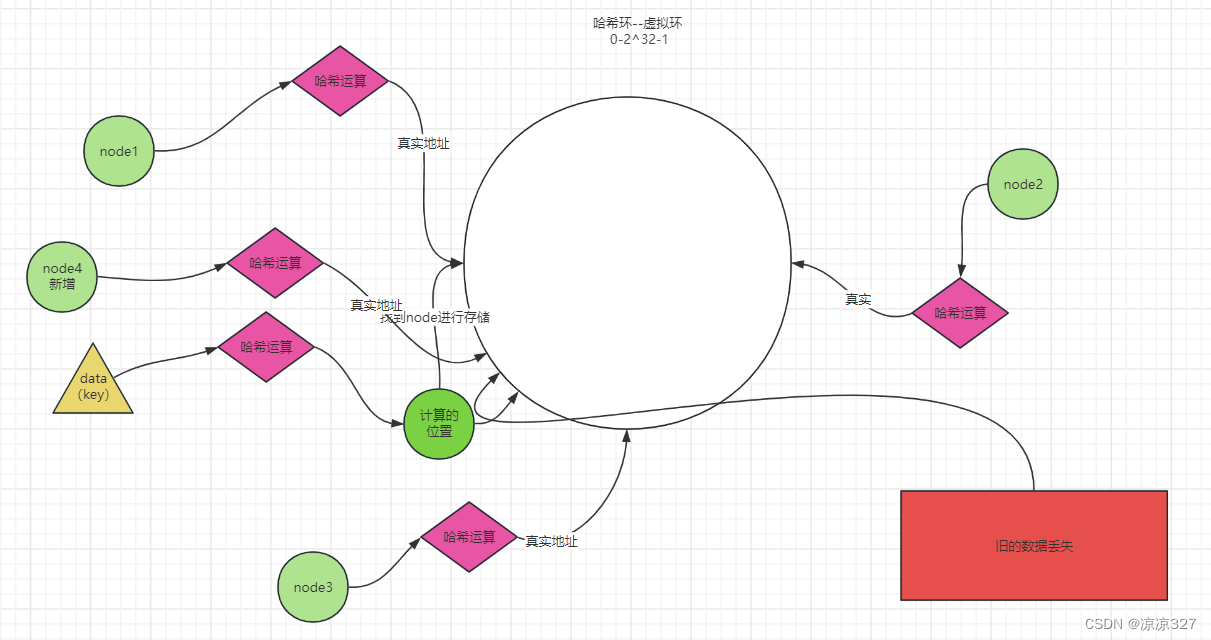
优点
加节点的确可以分担其他节点压力,不会造成全局洗牌
缺点
新增节点造成一小部分数据不能命中
1.问题,击穿,压到mysql
2.方案,每次去取相近的两个物理节点
所以更倾向作为缓存,而不是作为数据库使用
解决数据倾斜问题?
虚拟节点(node)不应太少
8.7 用代理解决redis连接成本高对server造成的问题
参考博客: https://blog.csdn.net/qq_37200262/article/details/122462030
8.9 集群种类
-
**Twemproxy(也被称为 nutcracker):**这是一个开放源代码的代理和集群管理器,由 Twitter 开发。Twemproxy 支持多种数据分片策略,并且可以无缝地代理多个 Redis 或 Memcached 集群。它提供了一个简化的接口,通过这个接口,应用程序可以像与单个 Redis 或 Memcached 实例交互一样,与多个后端实例进行交互。
-
**Predixy:**这是一个高性能的、全功能的 Redis 代理和 Sentinel。与 Twemproxy 相比,Predixy 提供了更全面的 Redis 特性支持,包括多数据库、事务和 Lua 脚本。它也支持读写分离和负载均衡,并且可以在 Redis Sentinel 配置中作为一个高效的代理使用。
-
**Redis Cluster:**这是 Redis 自己的集群解决方案,提供了数据分片和高可用性功能。Redis Cluster 支持在多个节点之间自动分割数据,每个节点负责维护其自己的数据部分。如果某个节点出现故障,系统可以自动选择另一台机器来接管它的数据。
-
**Codis:**这是一个代理基础的 Redis 集群解决方案,源自于中国的 Wandou Labs。Codis 提供了比 Redis Cluster 更灵活的数据分片和重新分片功能,并且支持在线添加、删除和迁移节点。在 Codis 中,所有的 Redis 实例都是平等的,不分主从。Codis 的优点是易于管理和扩展,缺点是因为所有请求都需要通过代理,可能会对性能产生影响。
8.10 分区
- 范围分区(Range partitioning): 在此分区方法中,对象会根据它们的键在不同的 Redis 实例之间被划分。例如,用户 ID 1-10000 可以在一台机器上,10001-20000 在第二台上,等等。
- 哈希分区(Hash partitioning): 在此分区方法中,对象根据哈希值进行分配。哈希函数对键进行哈希计算,然后将哈希值分配到不同的 Redis 实例中。常见的库如 Redis Cluster 和 Twemproxy (nutcracker) 都使用此种策略。
- 列表分区(List partitioning): 在此分区方法中,管理员会定义可以存储特定值的 Redis 实例。例如,对于给定的产品编码,管理员可以定义一个实例专用于存储某一类产品的全部信息。
- 组合分区(Composite partitioning): 一种混合了哈希分区和范围分区的方案。例如,可以先对键进行哈希,然后根据得到的哈希值范围来选择对应的 Redis 实例。
九.利用springboot 集成redis
参考 :https://www.baidu.com/s?wd=springboot%E9%9B%86%E6%88%90redis















 4998
4998











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









