









我们经常使用的springboot自带的 Hikari,今天我们看下Druid有什么不同
自己做一个练练手,一起来看看Druid强大之处
目录
1.新建一个springboot项目,建好之后别忘记yml中配置启动端口
3.引入对应的依赖包,版本的话看个人需求 我用的是2.2.4,数据库我用的是postgresql
1.新建一个springboot项目,建好之后别忘记yml中配置启动端口
#启动端口 server: port: 8088
配置好之后,验证看下是否正常,写个测试类
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
@RequestMapping("/test")
public class TestController {
@RequestMapping("/helloWord")
public String HelloWord(){
System.out.println("hello java");
return "hello java";
}
}2.启动项目
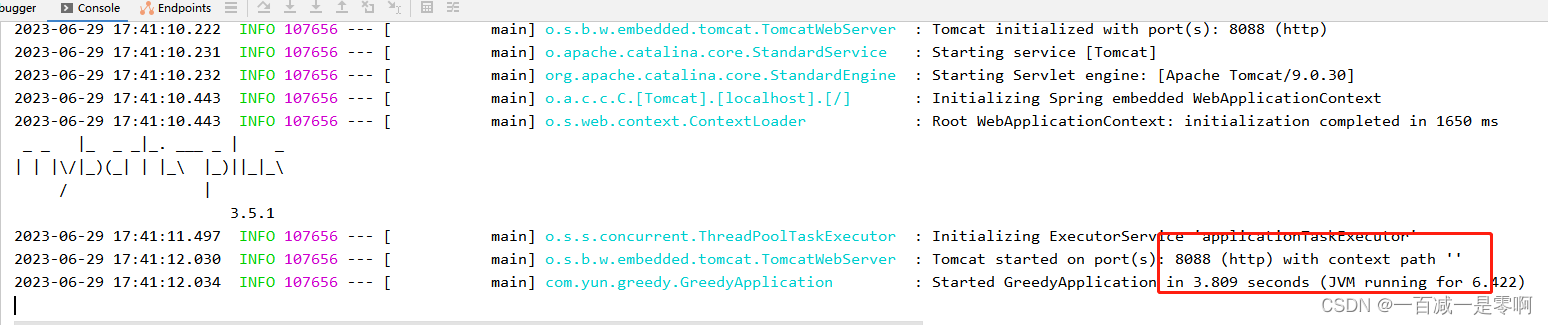
显示刚刚自己设置的端口号,启动成功,然后访问下看看是否正常
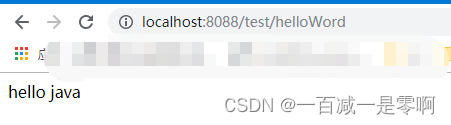
OK,启动和访问都没有问题。
3.引入对应的依赖包,版本的话看个人需求 我用的是2.2.4,数据库我用的是postgresql
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.2.4.RELEASE</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<dependency>
<groupId>org.postgresql</groupId>
<artifactId>postgresql</artifactId>
<scope>runtime</scope>
</dependency>
<!--引入druid starter-->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.2.16</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.2.16</version>
</dependency>
4.配置application.yml
#启动端口
server:
port: 8088
#druid细节配置可以写在yml中,也可以代码实现。我这版是代码实现的
spring:
datasource:
url: 连接地址
username: 账号
password: 密码
driver-class-name: org.postgresql.Driver
type: com.alibaba.druid.pool.DruidDataSource #切换为druid5.配置DruidConfiguration
import com.alibaba.druid.filter.Filter;
import com.alibaba.druid.pool.DruidDataSource;
import com.alibaba.druid.support.http.StatViewServlet;
import com.alibaba.druid.support.http.WebStatFilter;
import com.alibaba.druid.wall.WallConfig;
import com.alibaba.druid.wall.WallFilter;
import lombok.extern.slf4j.Slf4j;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.boot.web.servlet.FilterRegistrationBean;
import org.springframework.boot.web.servlet.ServletRegistrationBean;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import javax.sql.DataSource;
import java.sql.SQLException;
import java.util.*;
/**
* SpringBoot配置Druid
*/
@Slf4j
@Configuration
public class DruidConfiguration {
@ConfigurationProperties("spring.datasource")
@Bean
public DataSource druidDataSource() {
DruidDataSource dataSource = new DruidDataSource();
try {
// 启动程序时,在连接池中初始化多少个连接(10-50已足够)
dataSource.setInitialSize(50);
// 回收空闲连接时,将保证至少有 minIdle 个连接(与 initialSize 相同)
dataSource.setMinIdle(50);
// 连接池中最多支持多少个活动会话
dataSource.setMaxActive(10000);
// 程序向连接池中请求连接时,超过 maxWait 的值后,认为本次请求失败,即连接池,没有可用连接,单位毫秒,设置 -1 时表示无限等待(建议值为100)
dataSource.setMaxWait(100);
/*
缓存通过以下两个方法发起的 SQL:
public PreparedStatement prepareStatement(String sql)
public PreparedStatement prepareStatement(String sql, int resultSetType, int resultSetConcurrency)
(建议值为 true)
*/
dataSource.setPoolPreparedStatements(true);
// 每个连接最多缓存多少个 SQL(建议值为 20)
dataSource.setMaxPoolPreparedStatementPerConnectionSize(20);
// 检查空闲连接的频率,单位毫秒,非正整数时表示不进行检查(建议值:2000)
dataSource.setTimeBetweenEvictionRunsMillis(2000);
// 连接池中某个连接的空闲时长达到 N 毫秒后, 连接池在下次检查空闲连接时,将回收该连接,要小于防火墙超时设置 net.netfilter.nf_conntrack_tcp_timeout_established 的设置
dataSource.setMinEvictableIdleTimeMillis(600000);
// 配置一个连接在池中最大生存的时间,单位是毫秒
dataSource.setMaxEvictableIdleTimeMillis(900000);
// 程序没有 close 连接且空闲时长超过 minEvictableIdleTimeMillis,则会执行 validationQuery 指定的 SQL,以保证该程序连接不会池 kill 掉,其范围不超过 minIdle 指定的连接个数(建议值为 true)
dataSource.setKeepAlive(true);
// 检查池中的连接是否仍可用的 SQL 语句,druid 会连接到数据库执行该 SQL,如果正常返回,则表示连接可用,否则表示连接不可用
dataSource.setValidationQuery("SELECT 1");
// 当程序请求连接,池在分配连接时,是否先检查该连接是否有效(高效,并且保证安全性;建议值为 true)
dataSource.setTestWhileIdle(true);
// 程序申请连接时,进行连接有效性检查(低效,影响性能;建议值为 false)
dataSource.setTestOnBorrow(false);
// 程序返还连接时,进行连接有效性检查(低效,影响性能;建议值为 false)
dataSource.setTestOnReturn(false);
// 物理连接初始化的时候执行的 sql
// Collection<String> connectionInitSqls = new ArrayList<>(10);
// connectionInitSqls.add("SELECT 1 FROM DUAL");
// dataSource.setConnectionInitSqls(connectionInitSqls);
/*
这里配置的是插件,常用的插件有:
监控统计:stat
日志监控:log4j2
防御 SQL 注入:wall
*/
dataSource.setFilters("stat,log4j2");
// 是否合并多个 DruidDataSource 的监控数据
dataSource.setUseGlobalDataSourceStat(true);
// 监控统计
// 是否启用慢 SQL 记录
dataSource.addConnectionProperty("druid.stat.logSlowSql", "true");
// 执行时间超过 slowSqlMillis 的就是慢,单位毫秒(建议值 500)
dataSource.addConnectionProperty("druid.stat.slowSqlMillis", "500");
// 要求程序从池中 get 到连接后,N 秒后必须 close,否则 druid 会强制回收该连接,不管该连接中是活动还是空闲,以防止进程不会进行 close 而霸占连接(建议值为 false,当发现程序有未正常 close 连接时设置为 true)
// dataSource.setRemoveAbandoned(false);
// 设置 druid 强制回收连接的时限,当程序从池中 get 到连接开始算起,超过此值后,druid将强制回收该连接,单位秒(应大于业务运行最长时间)
// dataSource.setRemoveAbandonedTimeout();
// 当 druid 强制回收连接后,是否将 stack trace 记录到日志中(建议值为 true)
// dataSource.setLogAbandoned(true);
// 连接属性。比如设置一些连接池统计方面的配置 druid.stat.mergeSql=true;druid.stat.slowSqlMillis=5000
// dataSource.setConnectProperties();
// 防御 SQL 注入
WallFilter wallFilter = new WallFilter();
WallConfig config = new WallConfig();
// 是否允许执行 DELETE 语句(建议值为 false)
config.setDeleteAllow(false);
// 是否允许删除表(建议值为 false)
config.setDropTableAllow(false);
wallFilter.setConfig(config);
// 插件代理
List<Filter> proxyFilters = new ArrayList<>(10);
proxyFilters.add(wallFilter);
dataSource.setProxyFilters(proxyFilters);
} catch (SQLException e) {
log.error(e.toString());
}
return dataSource;
}
@Bean
public ServletRegistrationBean<StatViewServlet> statViewServlet() {
// 监控信息显示页面
StatViewServlet statViewServlet = new StatViewServlet();
// 访问监控信息显示页面的 url 路径(建议值为 /druid/* )
String urlPattern = "/druid/*";
ServletRegistrationBean<StatViewServlet> bean = new ServletRegistrationBean<>(statViewServlet, urlPattern);
Map<String, String> initParams = new HashMap<>();
// 是否允许清空统计数据
initParams.put("resetEnable", "false");
// 登录监控信息显示页面的用户名
initParams.put("loginUsername", "admin");
// 登录监控信息显示页面的密码
initParams.put("loginPassword", "admin");
// 允许访问控制(格式:ip地址、ip地址/子网掩码位数)逗号分隔多个地址
initParams.put("allow", "127.0.0.1");
// 拒绝访问控制(格式:ip地址、ip地址/子网掩码位数)逗号分隔多个地址
// initParams.put("deny", "");
bean.setInitParameters(initParams);
return bean;
}
@Bean
public FilterRegistrationBean<WebStatFilter> webStatFilter() {
FilterRegistrationBean<WebStatFilter> bean = new FilterRegistrationBean<>();
// 网络监控过滤器(用于采集 web-jdbc 关联监控的数据)
bean.setFilter(new WebStatFilter());
// 过滤所有的 url 路径
Collection<String> urlPatterns = new ArrayList<>();
urlPatterns.add("/*");
bean.setUrlPatterns(urlPatterns);
Map<String, String> initParams = new HashMap<>();
// 排除不必要采集的 url 路径,以逗号“,”分割
initParams.put("exclusions", "*.js,*.gif,*.jpg,*.png,*.css,*.ico,*.map,/druid/*");
// 是否使用 session 监控功能
initParams.put("sessionStatEnable", "true");
// 是否使用 session 监控最大数量(默认是1000)
initParams.put("sessionStatMaxCount", "1000");
// 使得 druid 能够知道当前的 session 的用户是谁,根据需要,把改值修改为你 user 信息保存在 session 中的 sessionName
initParams.put("principalSessionName", "session_user_key");
// 如果你的 user 信息保存在 cookie 中,你可以配置 principalCookieName,使得 druid 知道当前的 user 是谁,根据需要,把该值修改为你 user 信息保存在 cookie 中的 cookieName
initParams.put("principalCookieName", "cookie_user_key");
// 是否监控单个 url 调用的 sql 列表
initParams.put("profileEnable", "true");
bean.setInitParameters(initParams);
return bean;
}
}6.验证下连接数据库是否正常
新建表,写入数据(这些我就不一一阐述了)。同学们可以自己操作下。
我的项目结构
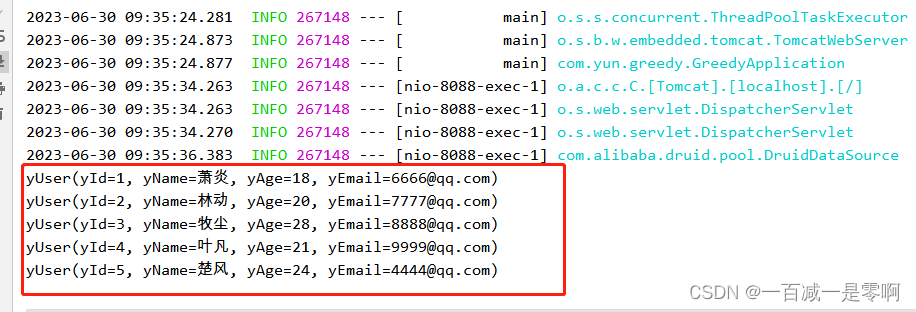
我找了一张表,写一个Controller我们查下看看是否可以正常查询
import com.yun.greedy.modules.staff.entity.yUser;
import com.yun.greedy.modules.staff.service.StaffService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.List;
@RestController
@RequestMapping("/staff")
public class StaffController {
@Autowired
private StaffService staffService;
@RequestMapping("/list")
public String list() {
List<yUser> list = staffService.getBaseMapper().selectList(null);
list.forEach(System.out::println);
return "查询完成";
}
}
验证连接数据库查询成功!

7.查看Druid的监控信息
登录此地址http://localhost:8088/druid/login.html
账号密码是ServletRegistrationBean中的配置admin admin
登录成功之后就可以查看各种的监控信息了
对于Druid连接池自带的监控,主要包括以下几个方面:
监控数据统计:Druid连接池内置了丰富的监控指标,可以统计连接池的使用情况、连接池的性能指标、SQL执行情况等。通过Druid的监控数据统计,可以方便地了解连接池的状态和性能。
SQL监控:Druid连接池可以记录SQL执行的详细信息,包括SQL语句、执行时间、执行结果等。通过Druid的SQL监控,可以方便地分析和优化SQL语句的性能。
防火墙功能:Druid连接池内置了防火墙功能,可以对SQL进行实时的监控和过滤,防止恶意的SQL攻击。
监控界面:Druid连接池提供了一个Web界面,可以直观地查看连接池的状态和性能指标,方便进行监控和管理。


好了,到这里就是完成了,有兴趣的同学可以自己尝试一下呃。更强大的功能可以参考下官网
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











