







仅供学习、交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理。
文章目录
前言
仅供学习、交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理。
https://httpbin.org/#/HTTP_Methods
requests
这个工具很多人拿它去做爬虫,就是去网上爬数据。 这个工具主要就是用它做数据请求的,叫requests,它是python的一个第三方库,requests应用的人非常多。
安装
pip install requests
使用
首先导入请求模块
import requests
第一种 requests.request(“请求方式”, …)
一般这种方法用的比较少
- requests.request(method, url, **kwargs)
- method - method for the newRequest object: GET ,OPTIONS ,HEAD , POST,PUT, PATCH , or DELETE
- url - URL for the newRequest object,params - (optional) Dictionary, list of tuples or bytes to send in the query string for theRequest.
- data - (optional) Dictionary, list of tuples, bytes, or file-likeobject to send in the body of the Request.
- json - (optional) A JSON serializable Python object to send in the body of the Request.
- headers -(optional) Dictionary of HTTP Headers to send with the Request.
- cookies - (optional) Dict or CookieJar object to send with the Request.
- auth - (optional) Auth tuple to enable Basic/Digest/Custom HTTP Auth.
- timeout (float or tuple) - (optional) How many seconds to wait for the server to send data before giving up, as a float, or a(connect timeout, read timeout) tuple.
- verify - (optional) Either a boolean, in which case it controls whether we verify the server’s TLS certificate, or a string, in which case it must be a path to a CA bundle to use. Defaults to True .
- stream - (optional) if False , the response content will be immediately downloaded.
- cert - (optional) if String, path to ssl client cert file (.pem). If Tuple, (‘cert’, "key’) pair.
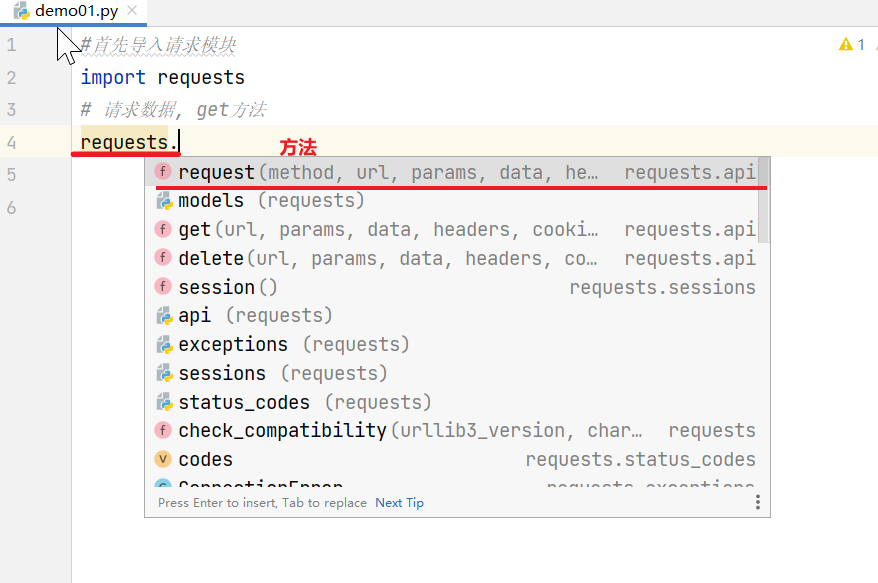
代码:
# 首先导入请求模块
import requests
# 请求数据, get方法
req = requests.request('GET', 'https://httpbin.org/get')
print(req, type(req)) # <Response [200]> <class 'requests.models.Response'>
print("响应的状态码:", req.status_code) # 200
第二种 requests.请求方式(参数)
- 尝试获取一个网页:
- r =
requests.get(‘https://httpbin.org/get’)
现在,我们有一个响应对象,称为r。我们可以从这个对象得到我们需要的所有信息。 - 发出HTTP POST请求的方式
r =requests.post(‘https://httpbin.org/post’, data = {‘key’:‘value’}) - 其他 HTTP 请求类型都很简单:
- r =
requests.put(‘https://httpbin.org/put’, data = {‘key’:‘value’}) - r =
requests.delete(‘https://httpbin.org/delete’) - r =
requests.head(‘https://httpbin.org/get’)
.head() 返回响应的头部信息 - r =
requests.options(‘https://httpbin.org/get’)
- r =
- r =
代码:
# 首先导入请求模块
import requests
# 请求数据, get方法
print('*' * 10 + 'get方法' + '*' * 10)
url = 'https://httpbin.org/get'
reqs = requests.get(url)
print(reqs, type(reqs)) # <Response [200]> <class 'requests.models.Response'>
print("响应的状态码:", reqs.status_code) # 200
# post 方法
print('*' * 10 + 'post 方法' + '*' * 10)
url = 'https://httpbin.org/post'
r = requests.post(url)
print("响应的内容: ", r.text)
print(r.json())
# head 方法
print('*' * 10 + 'head 方法' + '*' * 10)
r = requests.head(url)
print("响应的头部信息: ",r.headers)
返回结果:
**********get方法**********
<Response [200]> <class 'requests.models.Response'>
响应的状态码: 200
**********post 方法**********
响应的内容: {
"args": {},
"data": "",
"files": {},
"form": {},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Content-Length": "0",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.31.0",
"X-Amzn-Trace-Id": "Root=1-64fbe6c3-3840f850205869a62835cedc"
},
"json": null,
"origin": "112.94.96.111",
"url": "https://httpbin.org/post"
}
{'args': {}, 'data': '', 'files': {}, 'form': {}, 'headers': {'Accept': '*/*', 'Accept-Encoding': 'gzip, deflate', 'Content-Length': '0', 'Host': 'httpbin.org', 'User-Agent': 'python-requests/2.31.0', 'X-Amzn-Trace-Id': 'Root=1-64fbe6c3-3840f850205869a62835cedc'}, 'json': None, 'origin': '112.94.96.111', 'url': 'https://httpbin.org/post'}
**********head 方法**********
响应的头部信息: {'Date': 'Sat, 09 Sep 2023 03:30:14 GMT', 'Content-Type': 'text/html', 'Content-Length': '178', 'Connection': 'keep-alive', 'Server': 'gunicorn/19.9.0', 'Allow': 'POST, OPTIONS', 'Access-Control-Allow-Origin': '*', 'Access-Control-Allow-Credentials': 'true'}
URL中传递参数 params=xx
您经常希望在 URL 的查询字符串中发送某种数据。如果手动构造 URL,则此数据将在问号之后在 URL中作为键/值对(例如:请求允许您使用这些参数作为字符串字典提供这些参数。
通过打印 URL,您可以看到 URL已正确编码。r.url
# 首先导入请求模块
import requests
# 带参数的GET方法
url = 'https://httpbin.org/get'
payload = {'name': 'wanan', 'id': '18'}
r = requests.get(url, params=payload)
print(r.json())
print(r.url)# 通过打印 URL,您可以看到 URL已正确编码
print(r.content)
结果:
{'args': {'id': '18', 'name': 'wanan'}, 'headers': {'Accept': '*/*', 'Accept-Encoding': 'gzip, deflate', 'Host': 'httpbin.org', 'User-Agent': 'python-requests/2.31.0', 'X-Amzn-Trace-Id': 'Root=1-64fc2070-24d255f27164d9cd7a4333ec'}, 'origin': '27.46.235.100', 'url': 'https://httpbin.org/get?name=wanan&id=18'}
https://httpbin.org/get?name=wanan&id=18
b'{\n "args": {\n "id": "18", \n "name": "wanan"\n }, \n "headers": {\n "Accept": "*/*", \n "Accept-Encoding": "gzip, deflate", \n "Host": "httpbin.org", \n "User-Agent": "python-requests/2.31.0", \n "X-Amzn-Trace-Id": "Root=1-64fc2070-24d255f27164d9cd7a4333ec"\n }, \n "origin": "27.46.235.100", \n "url": "https://httpbin.org/get?name=wanan&id=18"\n}\n'
响应内容 r.text
可以读取服务器响应的内容。
import requests # 首先导入请求模块
r = requests.get('https://httpbin.org/get')
print(r.text)
{
"args": {},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.31.0",
"X-Amzn-Trace-Id": "Root=1-64fc2213-0920c543561342fa7e29ddb9"
},
"origin": "27.47.32.74",
"url": "https://httpbin.org/get"
}
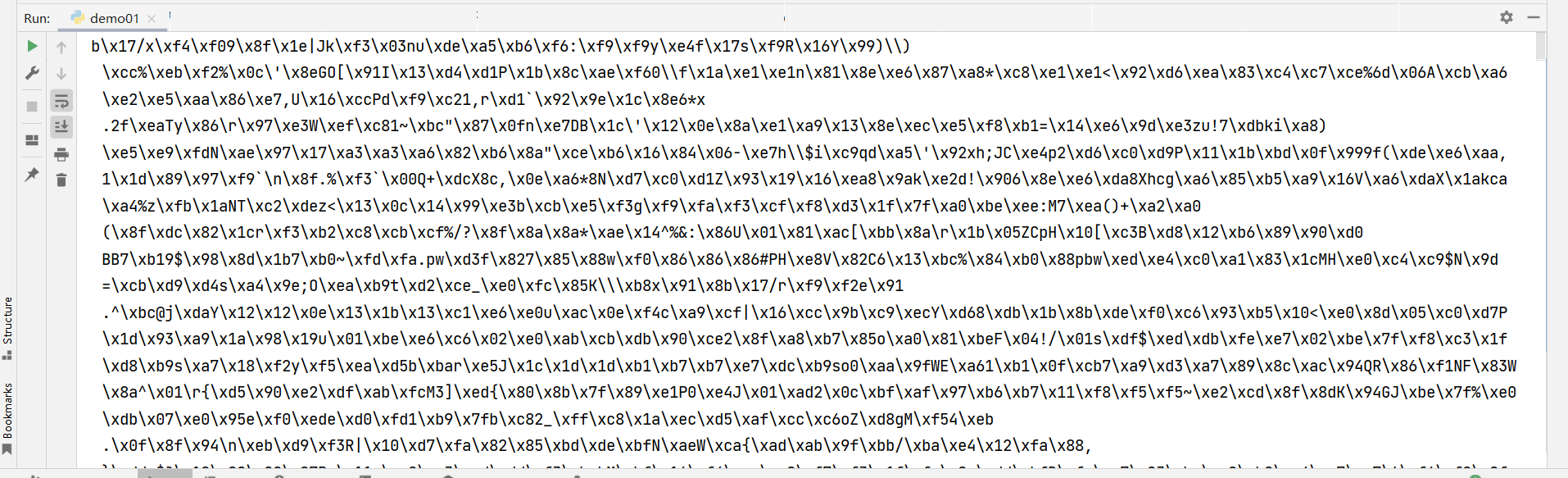
二进制响应内容 r.content
可以以字节形式访问响应正文,用于非文本请求:
比如说网上请求的是图片、视频、音频
与 r.text 相比,多了b开头,这是bytes的标志哟(字节字符串),要用的话还要编码一下。
import requests # 首先导入请求模块
r = requests.get('https://img-blog.csdnimg.cn/b758f764b6b146b5bddbde873b8dd07e.png')
print(r.content)
JSON 响应内容 r.json()
还有一个内置的JSON解码器,如果您正在处理JSON数据。r.json()就是以JSON格式输出你的响应。
import requests # 首先导入请求模块
r = requests.post('https://httpbin.org/post')
print(r.json())
{'args': {}, 'data': '', 'files': {}, 'form': {}, 'headers': {'Accept': '*/*', 'Accept-Encoding': 'gzip, deflate', 'Content-Length': '0', 'Host': 'httpbin.org', 'User-Agent': 'python-requests/2.31.0', 'X-Amzn-Trace-Id': 'Root=1-64fc2379-4771694175685c4370874c88'}, 'json': None, 'origin': '27.46.235.100', 'url': 'https://httpbin.org/post'}
自定义标头 headers=...
如果要向请求添加 HTTP 标头,只需将 dict项中传递给 headers参数即可。
user-agent:向服务器发送,包含了访问者系统引擎版本、浏览器信息的字段信息。一般服务器识别出是爬虫请求,会拒绝访问。所以此时设置user-agent,可以将爬虫伪装成用户通过浏览器访问。
例如:
我们的请求头部信息是可以自己定义的,我们试一下自定义标头,以百度为例:
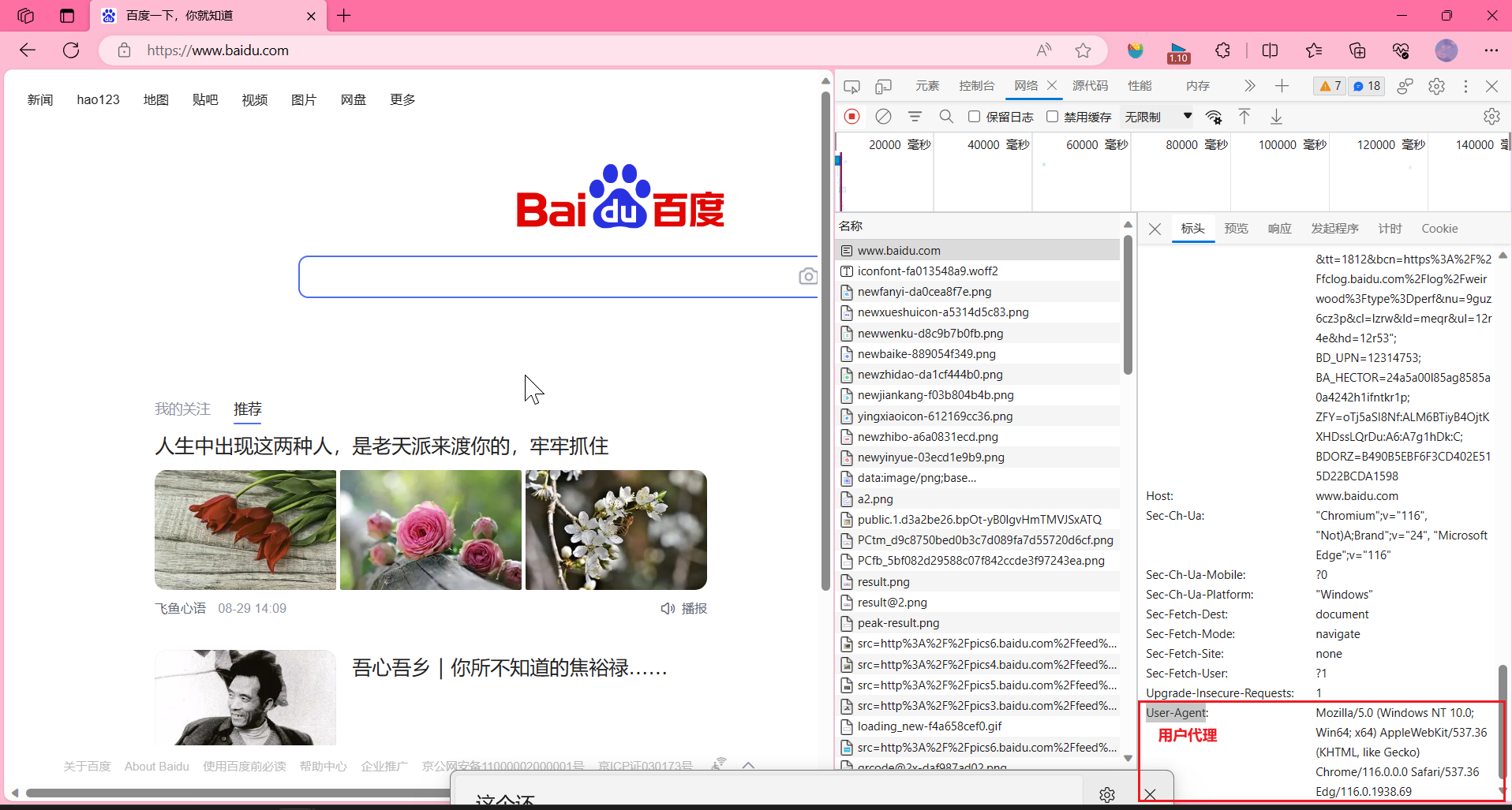
复制user-agent来使用,headers不止可以加user-agent,还可以加Accept(接受什么)、Accept-Encoding(接受什么样的压缩方式)… 这些都是可以往前加的,加的时候就是以字典的这种形式。
代码:
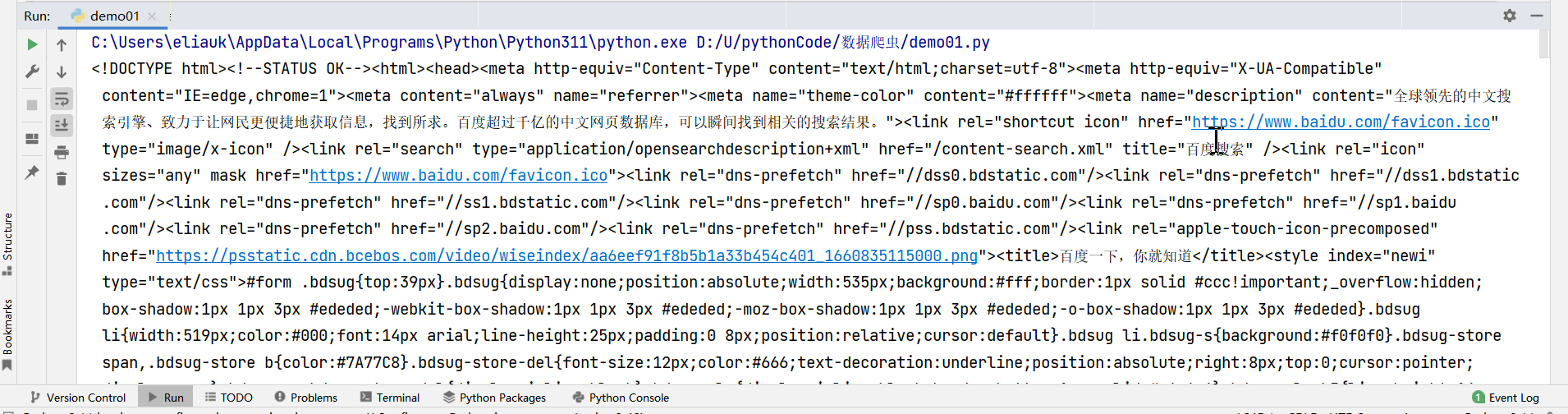
import requests # 首先导入请求模块
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36 Edg/116.0.1938.69'}
r = requests.get('https://www.baidu.com', headers=headers)
print(r.text)
print(r.status_code)
返回结果:可以看到返回了这么多的数据,这是百度首页的内容
响应状态代码 r.status_code
我们可以检查响应状态代码:
import requests # 首先导入请求模块
r = requests.get('https://httpbin.org/get')
print(r.status_code) # 200
响应标头 r.headers
r.headers 查看响应头部信息
我们可以使用 Python 字典查看服务器的响应标头:
import requests
r = requests.get('https://httpbin.org/get')
print(r.headers)
{'Date': 'Sat, 09 Sep 2023 07:55:17 GMT', 'Content-Type': 'application/json', 'Content-Length': '305', 'Connection': 'keep-alive', 'Server': 'gunicorn/19.9.0', 'Access-Control-Allow-Origin': '*', 'Access-Control-Allow-Credentials': 'true'}
字典很特别,但是:它只是为了 HTTP 标头。根据RFC 7230,HTTP标头名称不区分大小写。
从头部信息里提取某个字段
print(r.headers['Content-Type'])
print(r.headers.get('content-type'))
结果:
application/json
application/json
cookie
-
如果响应包含一些 cookie,您可以快速访问它们
注意:import requests # 首先导入请求模块 url = 'https://httpbin.org/cookies/set/example_cookie_name/xiaoyi' r = requests.get(url) rcookie = r.cookies print(rcookie) # <RequestsCookieJar[]> print(r.text) print(rcookie.get('example_cookie_name')) # None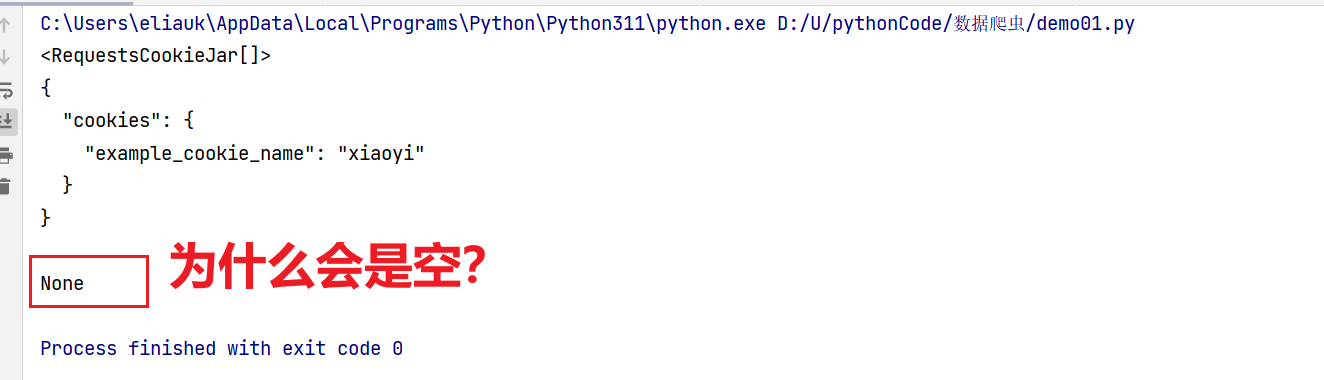
注意:有时候,requests 返回的 cookies 会为空,原因是因为链接发生了 301/302 重定向跳转,而 cookies 是跟着第一个响应返回的,第二个响应没有返回 Set-Cookie header。所以直接读取 r.cookies 就是空的,但是在 session.cookies 中是有数据的。
-
解决办法:在请求参数中加入"allow_redirects": False关闭重定向。import requests # 首先导入请求模块 url = 'https://httpbin.org/cookies/set/example_cookie_name/xiaoyi' # 解决办法:在请求参数中加入"allow_redirects": False关闭重定向。 r1 = requests.get(url=url, allow_redirects=False) cookie = r1.cookies print(cookie) print(cookie.get('example_cookie_name')) print(cookie['example_cookie_name'])结果:
<RequestsCookieJar[<Cookie example_cookie_name=xiaoyi for httpbin.org/>]> xiaoyi xiaoyi可以看到成功啦!!!

-
-
定义自己的cookie
要将你自己的 cookie 发送到服务器,可以使用以下参数: cookies
import requests # 首先导入请求模块
url = 'https://httpbin.org/cookies'
cookies = dict(cookies_are='working')
r=requests.get(url,cookies=cookies)
print(r.text)
结果:
{
"cookies": {
"cookies_are": "working"
}
}
Basic Authentication 基本身份认证
Many web services that require authentication accept HTTP Basic Auth. This is the simplest kind, and Requests supports it straightout of the box.
许多需要身份验证的web服务都接受HTTP基本身份验证。这是最简单的一种,并且Requests直接支持它。
- 第一种方法(用的比较少)
Making requests with HTTP Basic Auth is very simple:
使用HTTP基本认证发出请求非常简单:
>>> from requests.auth import HTTPBasicAuth
>>> requests.get('https://api.github.com/user', auth=HTTPBasicAuth('user', 'pass'))
<Response[200]>
- 第二种方法
In fact, HTTP Basic Auth is so common that Requests provides a handy shorthand for using it:
事实上,HTTP基本认证是如此普遍,请求提供了一个方便的速记使用它:
>>> requests.get('https://api.github.com/user', auth=('user', 'pass'))
<Response[200]>
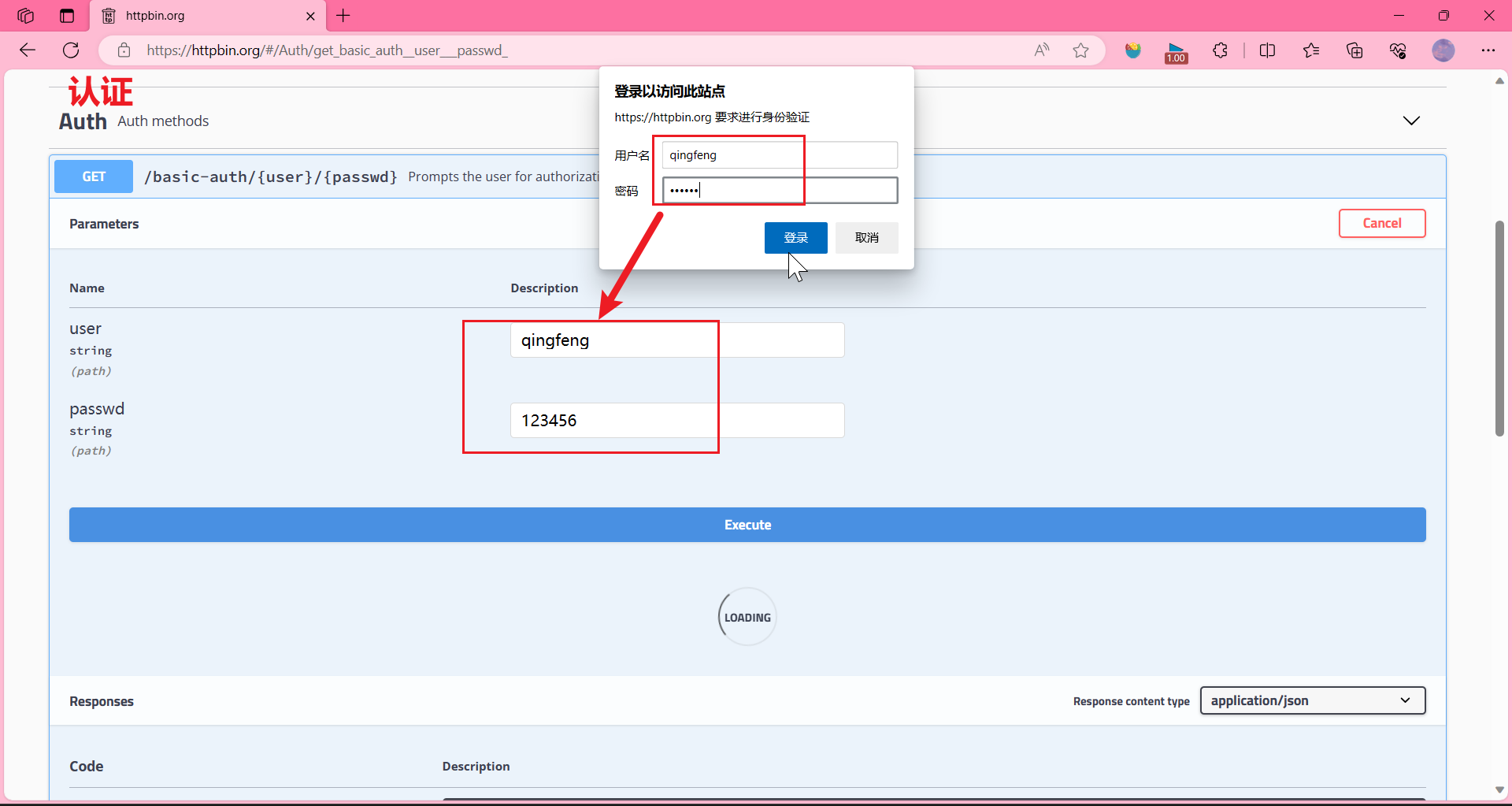
这个用户名密码就是你刚才写的user和passwd。
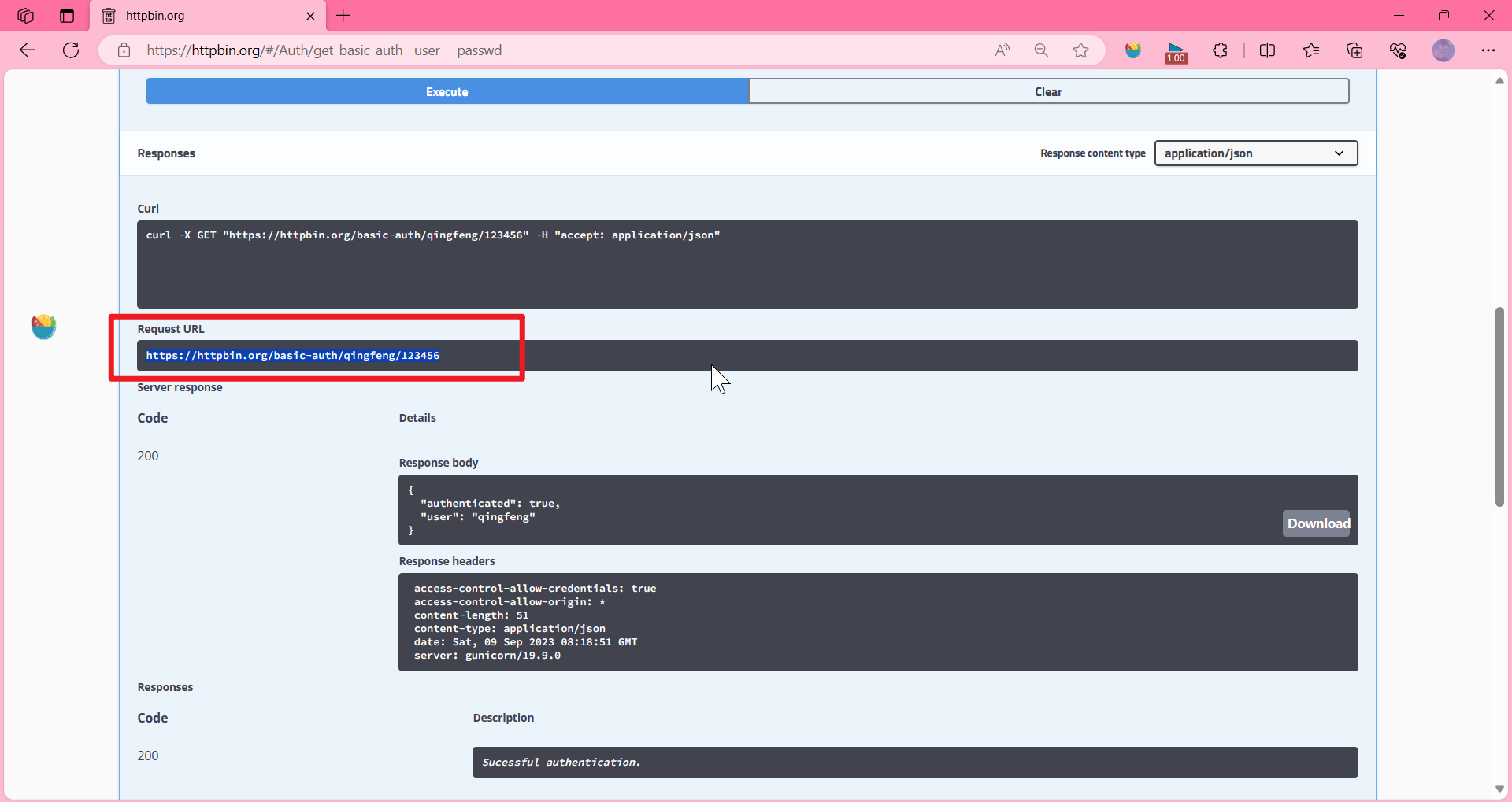
import requests
# 基础认证
url = "https://httpbin.org/basic-auth/qingfeng/123456"
r = requests.get(url, auth=('qingfeng', '123456'))
print(r.status_code)
print(r.json())
bs4
BeautifulSoup 是一个可以从HTML或XML文件中提取数据的Python库, 它能够通过你喜欢的转换器实现惯用的文档导航,查找,
修改文档的方式.BeautifulSoup会帮你节省数小时甚至数天的工作时间。
安装
pip install bs4
使用
介绍一个工具 https://curlconverter.com/
1.先拷贝所有的URL
2. 打开我们这个工具 https://curlconverter.com/,把刚刚复制的放到 curl command,它会自己生成代码
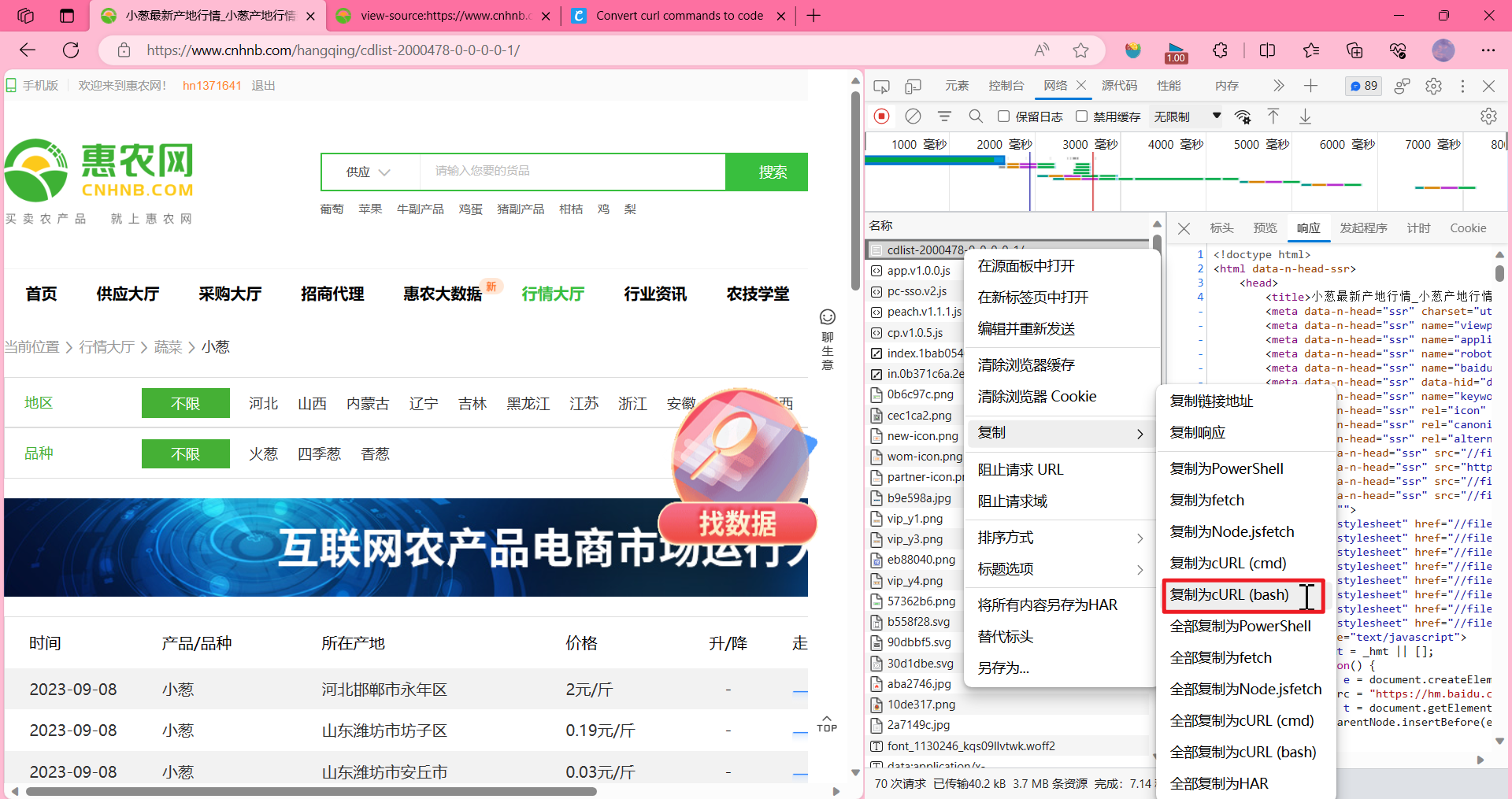
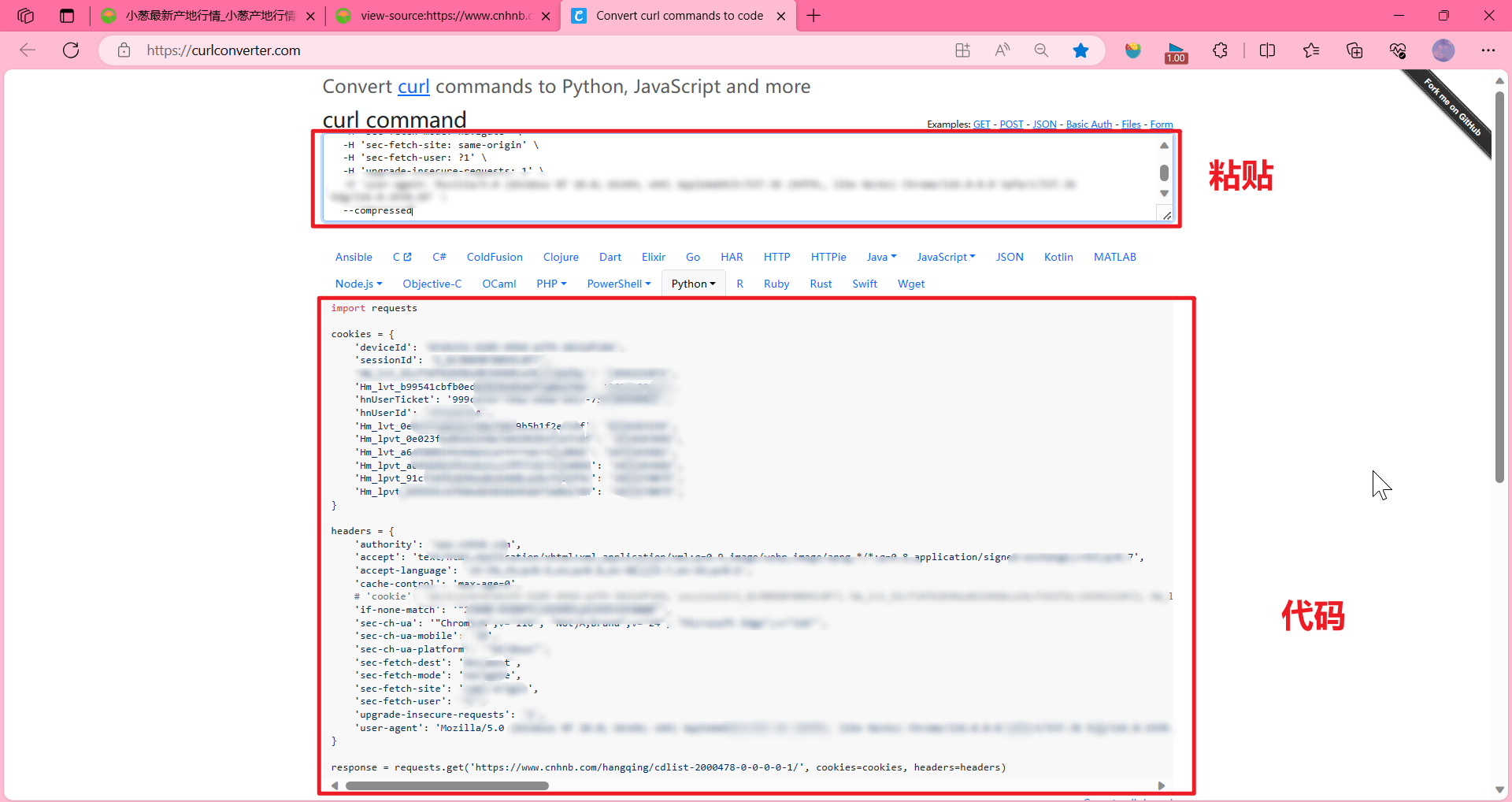
复制生成的代码
from bs4 import BeautifulSoup
import requests
# 复制上面生成的代码
cookies = {
'deviceId': '',。。。。。。
}
headers = {
'authority': 'www.cnhnb.com',。。。。。。
}
# 复制上面生成的代码
response = requests.get('https://www.cnhnb.com/hangqing/cdlist-2000478-0-0-0-0-1/', cookies=cookies, headers=headers)
# print(response.text)
"""
<!doctype html>
<html data-n-head-ssr>
<head >
<title> 小葱最新产地行情_小葱产地行情数据_小葱批发价格查询 - 惠农网</title>
......
</head>
<body >......
</body>
</html>
"""
html_doc = response.text
soup = BeautifulSoup(html_doc, 'html.parser') # .parser就是解析方法
print(soup.title) # <title> 小葱最新产地行情_小葱产地行情数据_小葱批发价格查询 - 惠农网</title>
# 我们想要拿什么就可以直接 .标签名
# print(type(soup.title)) # <class 'bs4.element.Tag'>
# 获取 title 里的内容
print(soup.title.string) # 小葱最新产地行情_小葱产地行情数据_小葱批发价格查询 - 惠农网
# 获取标签的名称
print(soup.title.name) # title
# 获取父标签
print(soup.title.parent.name) # head
print("=" * 10 + "分隔线" + "=" * 10)
# ul、a标签很多不止一个,但是只获取到第一个
# print("获取<ul>:\n", soup.ul) # 获取的第一个ul
print("获取<a>:\n", soup.a) # 获取的第一个a
print("-" * 10 + "分隔线" + "-" * 10)
# 如果我要把a标签或者ul标签都找出来,怎么做?
# print(soup.find_all('ul')) # 得到的是一个列表 [<ul>...</ul>, ......,<ul>...</ul>]
# # 遍历列表
# for ul_item in soup.find_all('ul'):
# print(ul_item)
first_ul = soup.find_all('ul')[0] # 我们获得第一个 ul
print("first_ul: \n", first_ul)
print("+" * 10 + "分隔线" + "+" * 10)
# 方法一 .contents获取子元素
# first_li=first_ul.contents[0] # .contents[0] 获得第一个子元素
# 方法二 .find_all() 接着往下查子元素
first_li = first_ul.find_all('li')[0] # 我们获得第一个ul 里的 第一个li
# print(first_li)
# print("_" * 10)
first_ul_first_a = first_li.find_all('a')[0] # 获取li 里的子元素的第一个 a标签
# print(first_ul_first_a)
"""
<a class="third-cate-item btn-clear selected" data-v-2164816a="" data-v-ecc15b76="" href="/hangqing/cdlist-2000478-0-0-0-0-1/" query="[object Object]" rel="" target="_blank">
不限
</a>
"""
# 第一种 .get(属性名) 获取属性
print(first_ul_first_a.get('href')) # /hangqing/cdlist-2000478-0-0-0-0-1/
print(first_ul_first_a.get('class')) # ['third-cate-item', 'btn-clear', 'selected']
# 第二种 [属性名] 像字典取某一个对应的值一样
print(first_ul_first_a['class']) # ['third-cate-item', 'btn-clear', 'selected']
结果:
<title> 小葱最新产地行情_小葱产地行情数据_小葱批发价格查询 - 惠农网</title>
小葱最新产地行情_小葱产地行情数据_小葱批发价格查询 - 惠农网
title
head
==========分隔线==========
获取<a>:
<a class="l-i" data-v-ea33ae2c="" href="https://m.cnhnb.com" target="_blank"><i class="iconfont icon-shouji" data-v-ea33ae2c=""></i>
手机版
</a>
----------分隔线----------
first_ul:
<ul data-v-9dfe180a=""><li class="sub-row" data-v-2164816a="" data-v-9dfe180a=""><span class="second-cate-item green" data-v-2164816a="">地区</span> <a class="third-cate-item btn-clear selected" data-v-2164816a="" data-v-ecc15b76="" href="/hangqing/cdlist-2000478-0-0-0-0-1/" query="[object Object]" rel="" target="_blank">
不限
</a> <a class="third-cate-item link-expanded" data-v-2164816a="" data-v-ecc15b76="" href="/hangqing/cdlist-2000478-0-3-0-0-1/" query="[object Object]" rel="" target="_blank">
河北
</a><a class="third-cate-item link-expanded" data-v-2164816a="" data-v-ecc15b76="" href="/hangqing/cdlist-2000478-0-4-0-0-1/" query="[object Object]" rel="" target="_blank">
山西
</a><a class="third-cate-item link-expanded" data-v-2164816a="" data-v-ecc15b76="" href="/hangqing/cdlist-2000478-0-5-0-0-1/" query="[object Object]" rel="" target="_blank">
内蒙古
</a><a class="third-cate-item link-expanded" data-v-2164816a="" data-v-ecc15b76="" href="/hangqing/cdlist-2000478-0-6-0-0-1/" query="[object Object]" rel="" target="_blank">
辽宁
</a><a class="third-cate-item link-expanded" data-v-2164816a="" data-v-ecc15b76="" href="/hangqing/cdlist-2000478-0-7-0-0-1/" query="[object Object]" rel="" target="_blank">
吉林
</a><a class="third-cate-item link-expanded" data-v-2164816a="" data-v-ecc15b76="" href="/hangqing/cdlist-2000478-0-8-0-0-1/" query="[object Object]" rel="" target="_blank">
黑龙江
</a><a class="third-cate-item link-expanded" data-v-2164816a="" data-v-ecc15b76="" href="/hangqing/cdlist-2000478-0-10-0-0-1/" query="[object Object]" rel="" target="_blank">
江苏
</a><a class="third-cate-item link-expanded" data-v-2164816a="" data-v-ecc15b76="" href="/hangqing/cdlist-2000478-0-11-0-0-1/" query="[object Object]" rel="" target="_blank">
浙江
</a><a class="third-cate-item link-expanded" data-v-2164816a="" data-v-ecc15b76="" href="/hangqing/cdlist-2000478-0-12-0-0-1/" query="[object Object]" rel="" target="_blank">
安徽
</a><a class="third-cate-item link-expanded" data-v-2164816a="" data-v-ecc15b76="" href="/hangqing/cdlist-2000478-0-13-0-0-1/" query="[object Object]" rel="" target="_blank">
福建
</a><a class="third-cate-item link-expanded" data-v-2164816a="" data-v-ecc15b76="" href="/hangqing/cdlist-2000478-0-14-0-0-1/" query="[object Object]" rel="" target="_blank">
江西
</a><a class="third-cate-item link-expanded" data-v-2164816a="" data-v-ecc15b76="" href="/hangqing/cdlist-2000478-0-15-0-0-1/" query="[object Object]" rel="" target="_blank">
山东
</a><a class="third-cate-item link-expanded" data-v-2164816a="" data-v-ecc15b76="" href="/hangqing/cdlist-2000478-0-16-0-0-1/" query="[object Object]" rel="" target="_blank">
河南
</a><a class="third-cate-item link-expanded" data-v-2164816a="" data-v-ecc15b76="" href="/hangqing/cdlist-2000478-0-17-0-0-1/" query="[object Object]" rel="" target="_blank">
湖北
</a><a class="third-cate-item link-expanded" data-v-2164816a="" data-v-ecc15b76="" href="/hangqing/cdlist-2000478-0-18-0-0-1/" query="[object Object]" rel="" target="_blank">
湖南
</a><a class="third-cate-item link-expanded" data-v-2164816a="" data-v-ecc15b76="" href="/hangqing/cdlist-2000478-0-19-0-0-1/" query="[object Object]" rel="" target="_blank">
广东
</a><a class="third-cate-item link-expanded" data-v-2164816a="" data-v-ecc15b76="" href="/hangqing/cdlist-2000478-0-20-0-0-1/" query="[object Object]" rel="" target="_blank">
广西
</a><a class="third-cate-item link-expanded" data-v-2164816a="" data-v-ecc15b76="" href="/hangqing/cdlist-2000478-0-21-0-0-1/" query="[object Object]" rel="" target="_blank">
海南
</a><a class="third-cate-item link-expanded" data-v-2164816a="" data-v-ecc15b76="" href="/hangqing/cdlist-2000478-0-23-0-0-1/" query="[object Object]" rel="" target="_blank">
四川
</a><a class="third-cate-item link-expanded" data-v-2164816a="" data-v-ecc15b76="" href="/hangqing/cdlist-2000478-0-24-0-0-1/" query="[object Object]" rel="" target="_blank">
贵州
</a><a class="third-cate-item link-expanded" data-v-2164816a="" data-v-ecc15b76="" href="/hangqing/cdlist-2000478-0-25-0-0-1/" query="[object Object]" rel="" target="_blank">
云南
</a><a class="third-cate-item link-expanded" data-v-2164816a="" data-v-ecc15b76="" href="/hangqing/cdlist-2000478-0-26-0-0-1/" query="[object Object]" rel="" target="_blank">
西藏
</a><a class="third-cate-item link-expanded" data-v-2164816a="" data-v-ecc15b76="" href="/hangqing/cdlist-2000478-0-27-0-0-1/" query="[object Object]" rel="" target="_blank">
陕西
</a><a class="third-cate-item link-expanded" data-v-2164816a="" data-v-ecc15b76="" href="/hangqing/cdlist-2000478-0-28-0-0-1/" query="[object Object]" rel="" target="_blank">
甘肃
</a><a class="third-cate-item link-expanded" data-v-2164816a="" data-v-ecc15b76="" href="/hangqing/cdlist-2000478-0-29-0-0-1/" query="[object Object]" rel="" target="_blank">
青海
</a><a class="third-cate-item link-expanded" data-v-2164816a="" data-v-ecc15b76="" href="/hangqing/cdlist-2000478-0-30-0-0-1/" query="[object Object]" rel="" target="_blank">
宁夏
</a><a class="third-cate-item link-expanded" data-v-2164816a="" data-v-ecc15b76="" href="/hangqing/cdlist-2000478-0-31-0-0-1/" query="[object Object]" rel="" target="_blank">
新疆
</a><a class="third-cate-item link-expanded" data-v-2164816a="" data-v-ecc15b76="" href="/hangqing/cdlist-2000478-0-45081-0-0-1/" query="[object Object]" rel="" target="_blank">
北京
</a><a class="third-cate-item link-expanded" data-v-2164816a="" data-v-ecc15b76="" href="/hangqing/cdlist-2000478-0-45082-0-0-1/" query="[object Object]" rel="" target="_blank">
天津
</a><a class="third-cate-item link-expanded" data-v-2164816a="" data-v-ecc15b76="" href="/hangqing/cdlist-2000478-0-45083-0-0-1/" query="[object Object]" rel="" target="_blank">
上海
</a><a class="third-cate-item link-expanded" data-v-2164816a="" data-v-ecc15b76="" href="/hangqing/cdlist-2000478-0-45084-0-0-1/" query="[object Object]" rel="" target="_blank">
重庆
</a><a class="third-cate-item link-expanded" data-v-2164816a="" data-v-ecc15b76="" href="/hangqing/cdlist-2000478-0-45085-0-0-1/" query="[object Object]" rel="" target="_blank">
台湾省
</a><a class="third-cate-item link-expanded" data-v-2164816a="" data-v-ecc15b76="" href="/hangqing/cdlist-2000478-0-45086-0-0-1/" query="[object Object]" rel="" target="_blank">
香港特别行政区
</a><a class="third-cate-item link-expanded" data-v-2164816a="" data-v-ecc15b76="" href="/hangqing/cdlist-2000478-0-45087-0-0-1/" query="[object Object]" rel="" target="_blank">
澳门特别行政区
</a><a class="third-cate-item link-expanded" data-v-2164816a="" data-v-ecc15b76="" href="/hangqing/cdlist-2000478-0-45114-0-0-1/" query="[object Object]" rel="" target="_blank">
境外
</a> <!-- --></li></ul>
++++++++++分隔线++++++++++
/hangqing/cdlist-2000478-0-0-0-0-1/
['third-cate-item', 'btn-clear', 'selected']
['third-cate-item', 'btn-clear', 'selected']
案例:图片批量下载
https://blog.csdn.net/weixin_59633478/article/details/131738682?spm=1001.2014.3001.5501
我们想要把这篇文章所有的图片下载下来
- 思路
- 先请求https://blog.csdn.net/weixin_59633478/article/details/131738682?spm=1001.2014.3001.5501的源代码(html)
- 源代码(html)中找到图片img的URL
- 对图片的url再进行一次请求,将它的数据保存为文件
跟前面一样用工具 https://curlconverter.com/,或者自己手写headers那些。
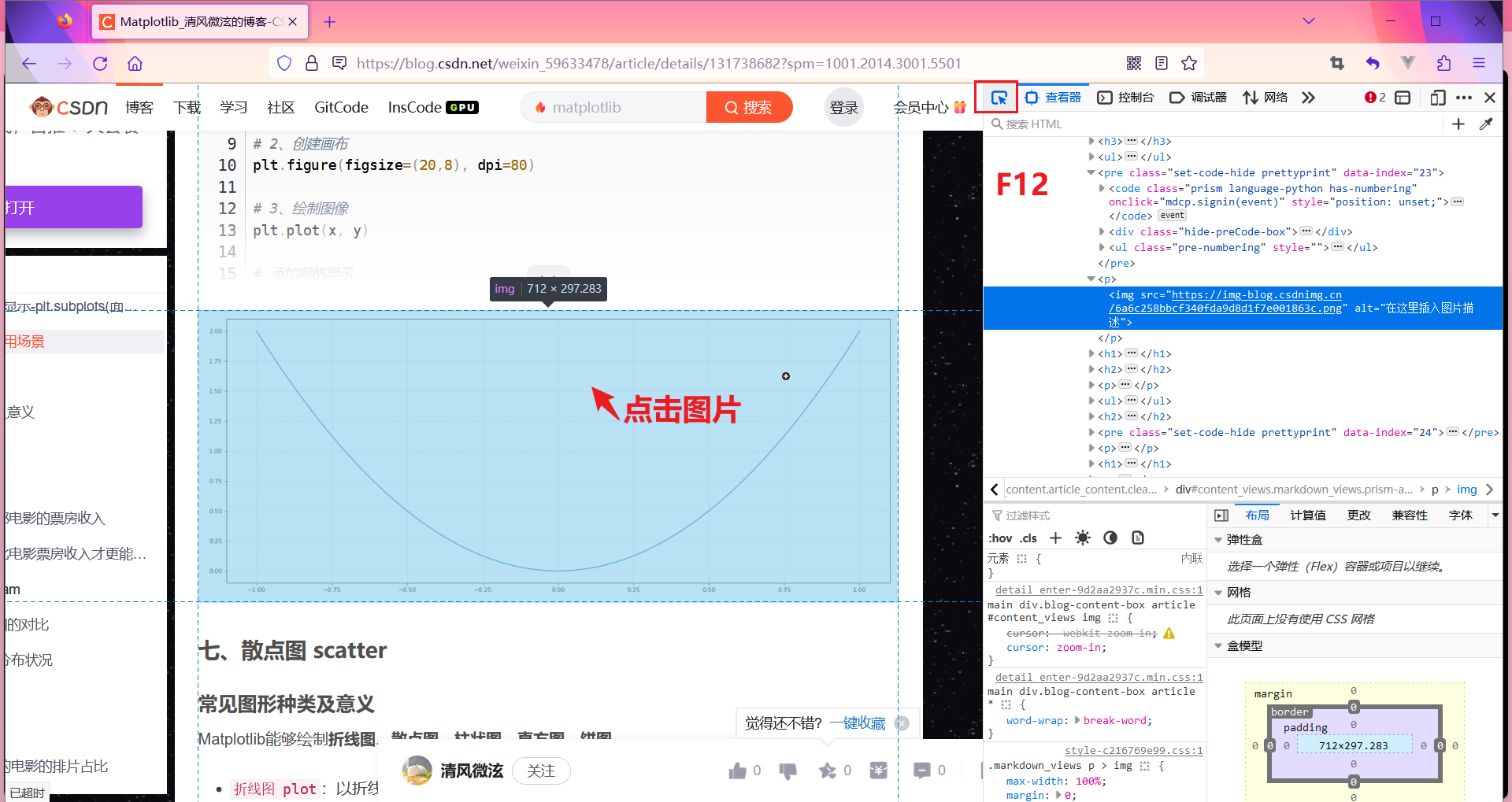
F12 检查,点鼠标图标 然后选中图片就能看到图片 img的结构啦,src就是图片URL 。当然,也可以把src里的地址复制到浏览器搜索,看看是不是可以用的。
然后选中图片就能看到图片 img的结构啦,src就是图片URL 。当然,也可以把src里的地址复制到浏览器搜索,看看是不是可以用的。
wb+ 以二进制格式打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。
代码:
import requests
from bs4 import BeautifulSoup
# https://blog.csdn.net/weixin_59633478/article/details/131738682?spm=1001.2014.3001.5501
# 我们想要把这篇文章所有的图片下载下来
# 1. 先请求https://blog.csdn.net/weixin_59633478/article/details/131738682?spm=1001.2014.3001.5501的源代码(html)
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:109.0) Gecko/20100101 Firefox/117.0"
}
response = requests.get('https://blog.csdn.net/weixin_59633478/article/details/131738682', headers=headers)
# print(response.status_code)
# print(response.text)
html_code = response.text
# 2. 源代码(html)中找到图片img的URL
# 遍历列表,提取图片的URL
soup = BeautifulSoup(html_code, 'html.parser') # 解析
imgs_list = soup.find_all('img') # 所有的图片
for img_item in imgs_list:
# print(img_item.get('class'))# 无就是None
# 如果我们只想要文章中的图片就要根据结构之间的不同点进行if筛选
if (img_item.get('class') == None or img_item.get('src') == None) and (
img_item.get('alt') != None and img_item.get('alt') != "" and img_item.get('alt') != "表情包"):
# 筛选之后这些就是这篇文章里的照片啦
# print(img_item)
img_url = img_item.get('src')
# print(img_url)# https://img-blog.csdnimg.cn/68deab801b1144edb1caee34b1861632.png
# 3. 对图片的url再进行一次请求,将它的数据保存为文件
image_response = requests.get(img_url)
image = image_response.content # 图片要用.content二进制响应内容 ,不应该用.text
# print(type(image))# <class 'bytes'>
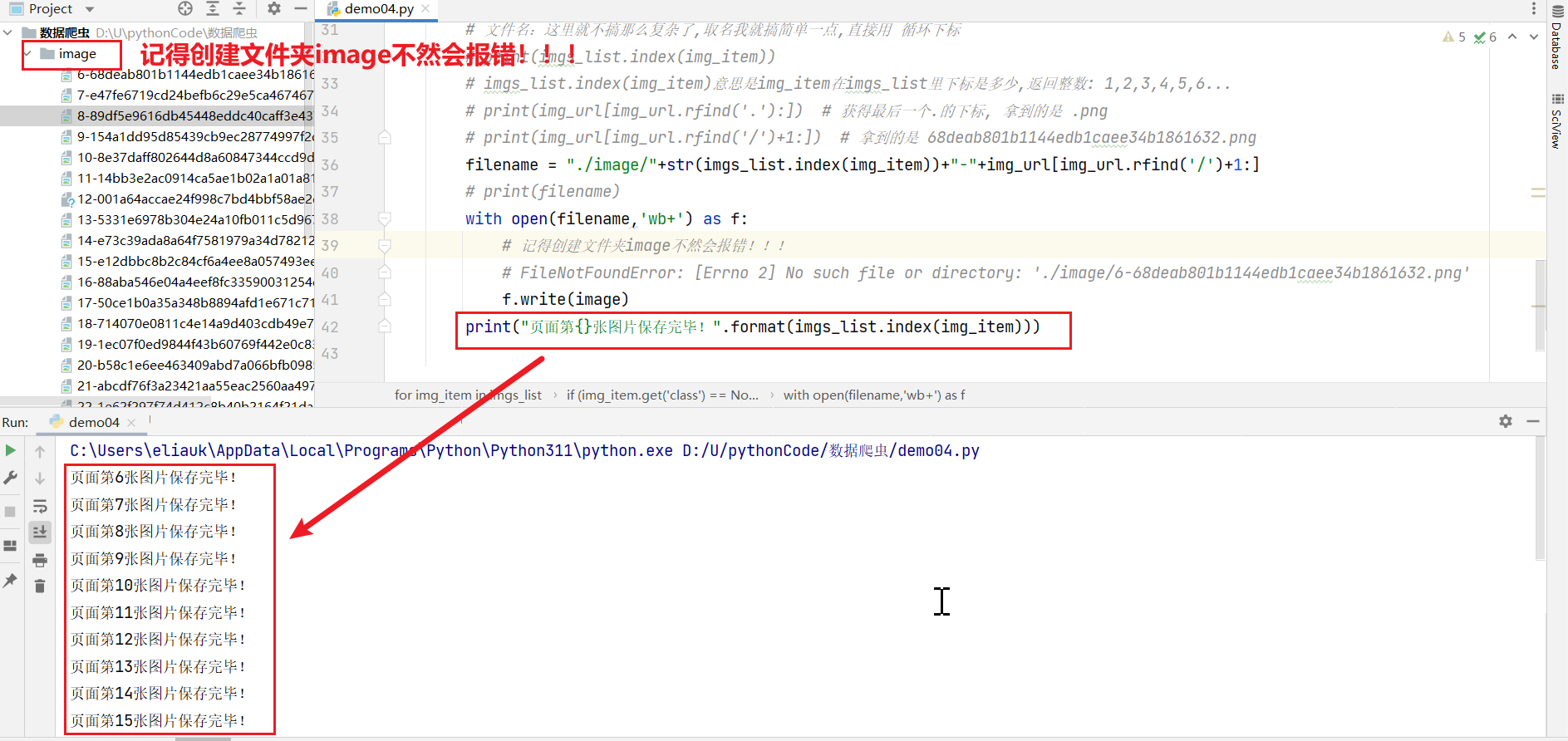
# 文件名:这里就不搞那么复杂了,取名我就搞简单一点,直接用 循环下标
# print(imgs_list.index(img_item))
# imgs_list.index(img_item)意思是img_item在imgs_list里下标是多少,返回整数: 1,2,3,4,5,6...
# print(img_url[img_url.rfind('.'):]) # 获得最后一个.的下标, 拿到的是 .png
# print(img_url[img_url.rfind('/')+1:]) # 拿到的是 68deab801b1144edb1caee34b1861632.png
filename = "./image/"+str(imgs_list.index(img_item))+"-"+img_url[img_url.rfind('/')+1:]
# print(filename)
with open(filename,'wb+') as f:
# 记得创建文件夹image不然会报错!!!
# FileNotFoundError: [Errno 2] No such file or directory: './image/6-68deab801b1144edb1caee34b1861632.png'
f.write(image)
print("页面第{}张图片保存完毕!".format(imgs_list.index(img_item)))
REST API-pagination 分页
The same principles apply to REST APis.The main reasons for using pagination in REST APis are as follows:
同样的原则也适用于REST api。在REST api中使用分页的主要原因如下:
I. Save resources: Providing large responses demands a lot of compute and network resources
节约资源:提供大型响应需要大量的计算和网络资源
II. lmprove response times: Because the paginated responses are much smaller, they can behandled by the server and the network faster.
改进响应时间: 由于分页响应要小得多,服务器和网络可以更快地处理它们。
lll. lmprove end user experience: Faster responses provide better user experiences. The relevant information can be obtained much simpler, without parsing large sets of data, and the respons can be customized for different client applications.
改进最终用户体验: 更快的响应提供更好的用户体验。可以更简单地获得相关信息,而无需解析大量数据集,并且可以针对不同的客户机应用程序定制响应。
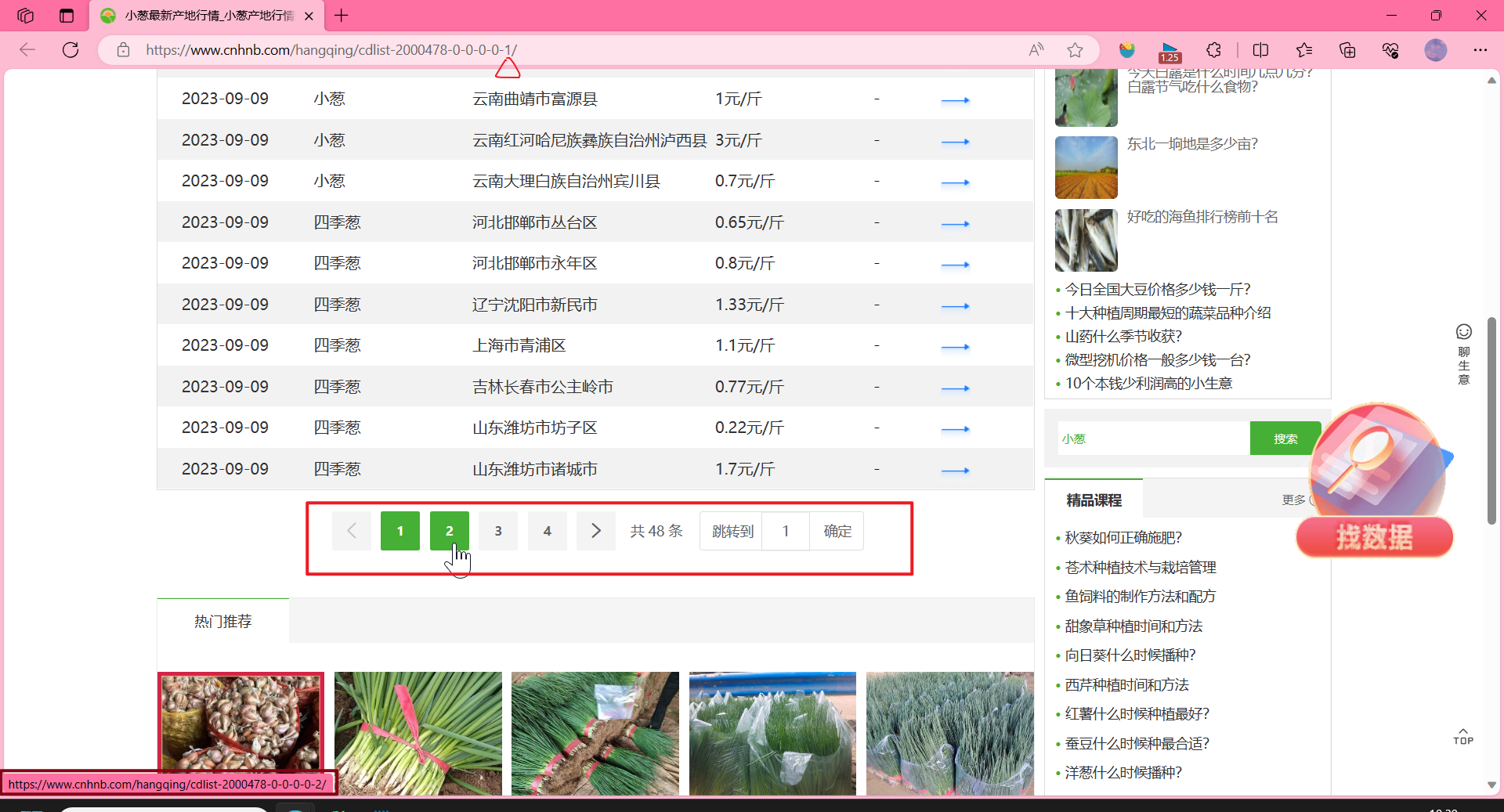
注意观察:
https://www.cnhnb.com/hangqing/cdlist-2000478-0-0-0-0-1/
https://www.cnhnb.com/hangqing/cdlist-2000478-0-0-0-0-2/
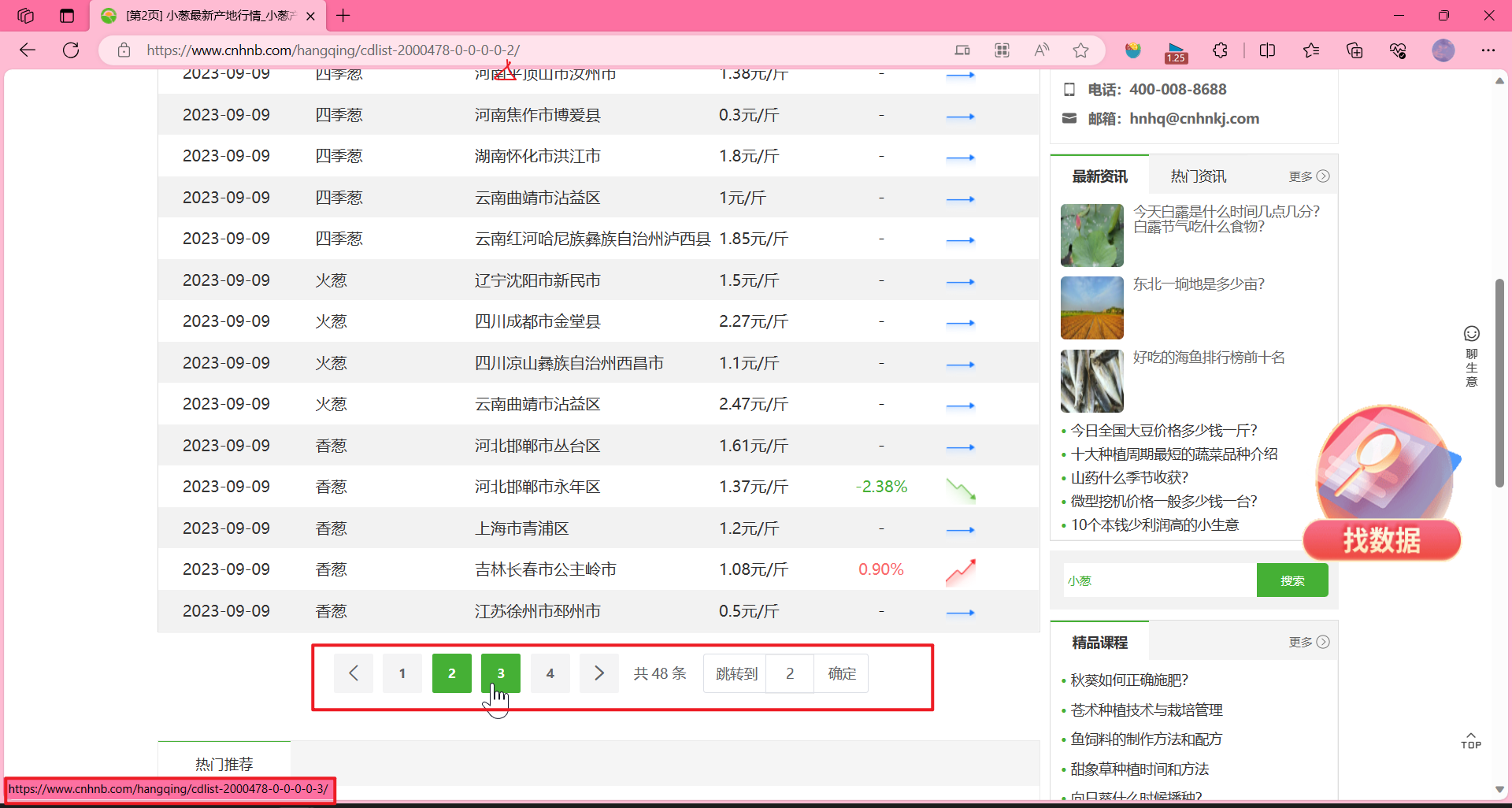
这个就是分页。
当然他是通过直接修改URL的名称来的。还有其他方式,比如:
基于页面的分页数据请求


https://movie.douban.com/
我们点击豆瓣高分
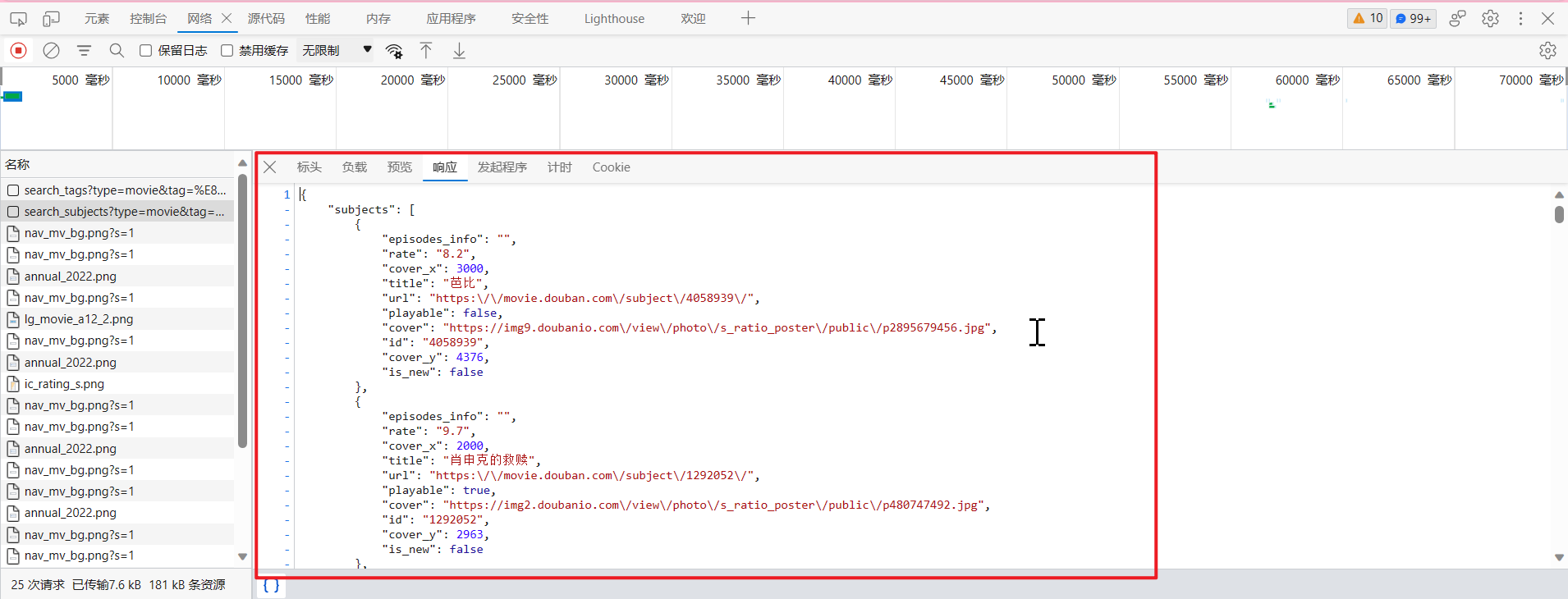
?后面的是参数
page_limit=50 一页50个数据
page_start=0 从哪一个开始的?从0开始
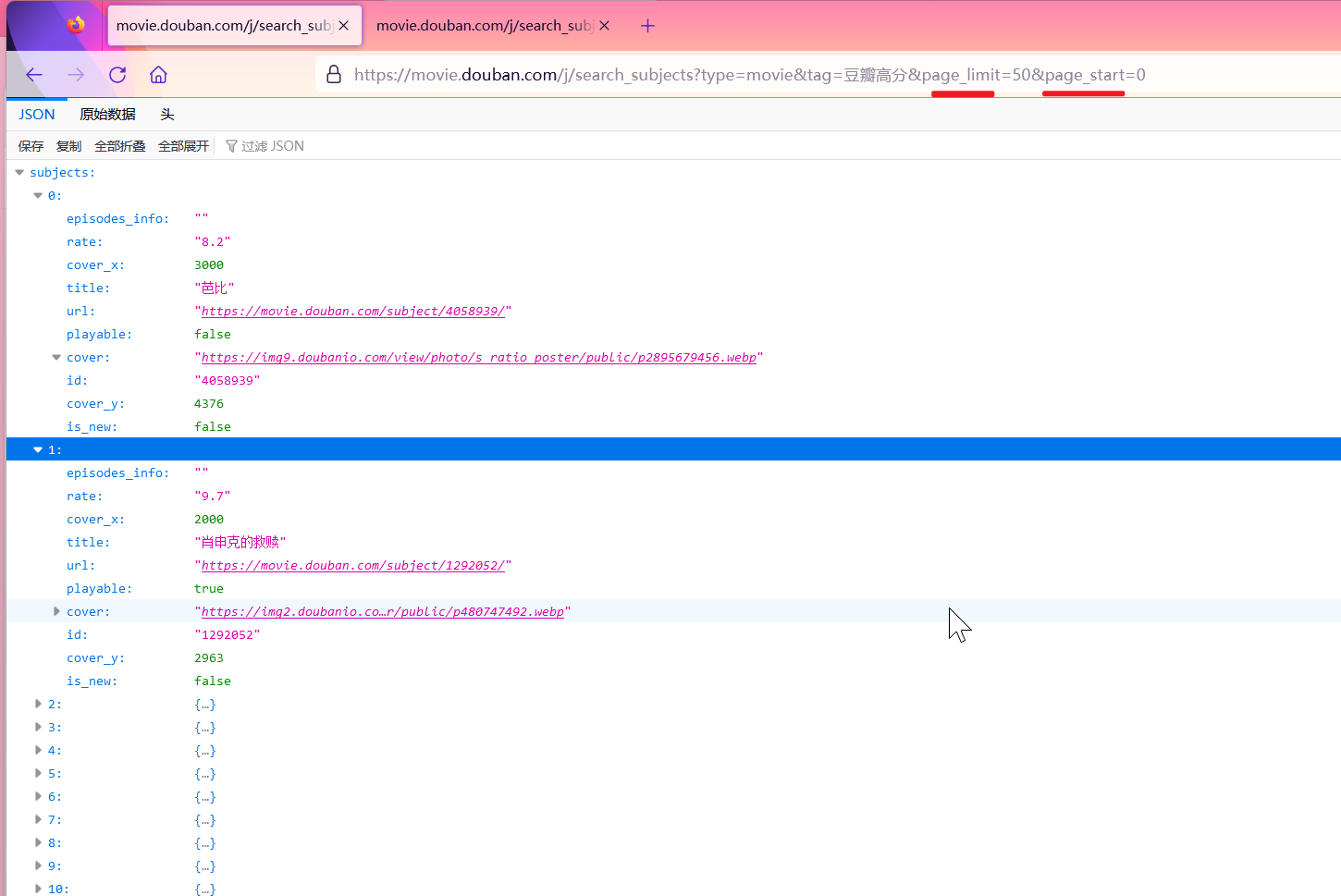
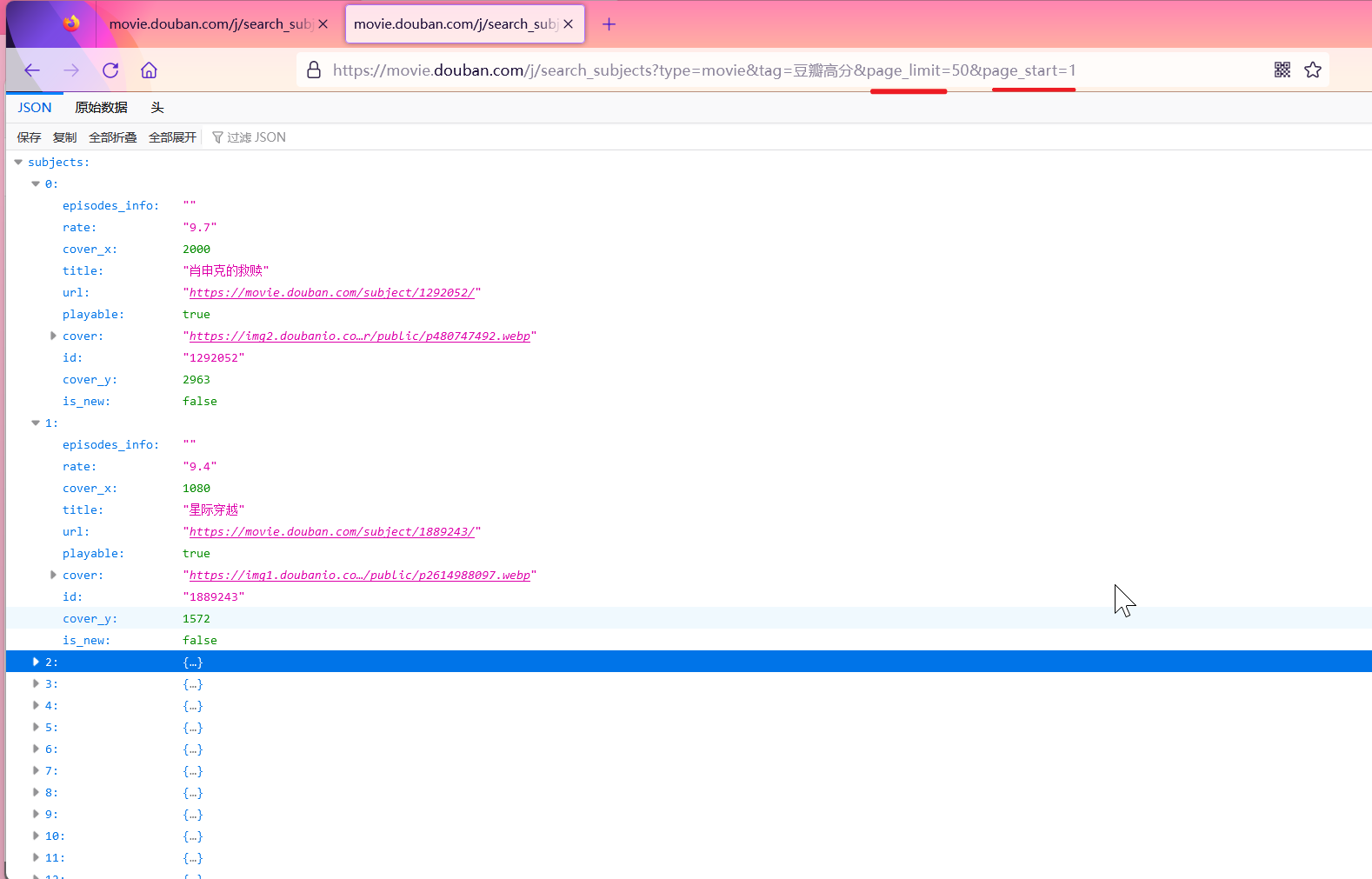
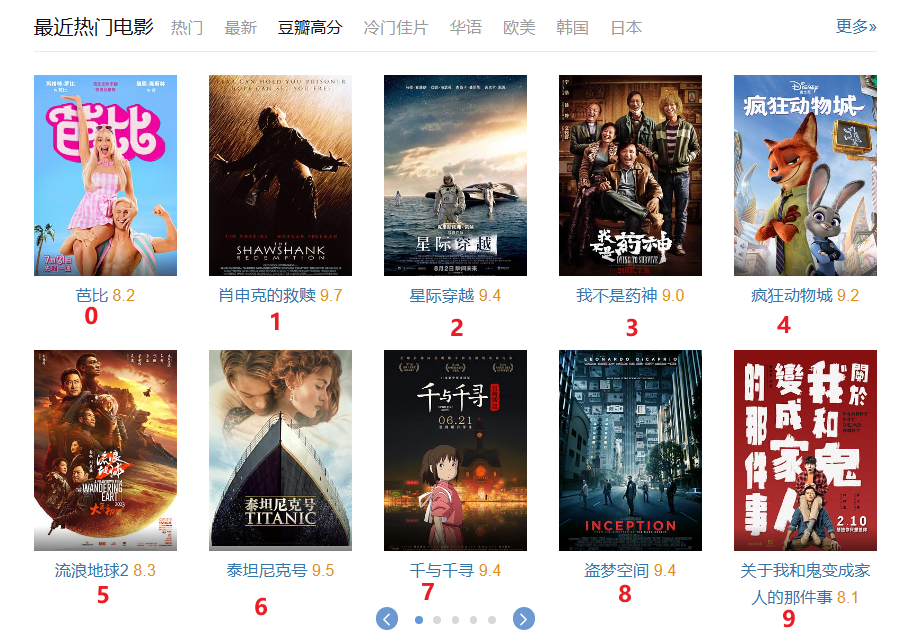
这种就是分页请求,如果是用Python怎么做?
实践:获取豆瓣高分电影的数据(分页)
import requests
url = 'https://movie.douban.com/j/search_subjects'
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:109.0) Gecko/20100101 Firefox/117.0"
}
# https://movie.douban.com/j/search_subjects?type=movie&tag=豆瓣高分&page_limit=50&page_start=0
params = {
'type': 'movie',
'tag': '豆瓣高分',
'page_limit': '50',
# 'page_limit': '20',
'page_start': '0',
# 'page_start': '3'
}
r = requests.get(url, headers=headers, params=params)
# print(r.status_code)# 200 请求成功
# print(r.json())
data = r.json()
# data['subjects'] list
# print(len(data['subjects'])) # 50
for i in data['subjects']:
# print(i)
# {'episodes_info': '',
# 'rate': '8.2', 'cover_x': 3000,
# 'title': '芭比', 'url': 'https://movie.douban.com/subject/4058939/',
# 'playable': False, 'cover': 'https://img9.doubanio.com/view/photo/s_ratio_poster/public/p2895679456.jpg',
# 'id': '4058939', 'cover_y': 4376, 'is_new': False}
print(i['title'] + " , 评分:" + i['rate'])
结果:
芭比 , 评分:8.2
肖申克的救赎 , 评分:9.7
星际穿越 , 评分:9.4
我不是药神 , 评分:9.0
疯狂动物城 , 评分:9.2
流浪地球2 , 评分:8.3
泰坦尼克号 , 评分:9.5
千与千寻 , 评分:9.4
盗梦空间 , 评分:9.4
关于我和鬼变成家人的那件事 , 评分:8.1
寻梦环游记 , 评分:9.1
阿甘正传 , 评分:9.5
绿皮书 , 评分:8.9
楚门的世界 , 评分:9.4
这个杀手不太冷 , 评分:9.4
哪吒之魔童降世 , 评分:8.4
霸王别姬 , 评分:9.6
怦然心动 , 评分:9.1
摔跤吧!爸爸 , 评分:9.0
你的名字。 , 评分:8.5
让子弹飞 , 评分:9.0
三傻大闹宝莱坞 , 评分:9.2
海上钢琴师 , 评分:9.3
少年的你 , 评分:8.2
当幸福来敲门 , 评分:9.2
哈利·波特与魔法石 , 评分:9.2
阿凡达 , 评分:8.8
寄生虫 , 评分:8.8
大话西游之大圣娶亲 , 评分:9.2
宇宙探索编辑部 , 评分:8.0
无间道 , 评分:9.3
头号玩家 , 评分:8.7
釜山行 , 评分:8.6
功夫 , 评分:8.8
银河护卫队3 , 评分:8.4
蜘蛛侠:纵横宇宙 , 评分:8.5
忠犬八公的故事 , 评分:9.4
飞屋环游记 , 评分:9.1
长安三万里 , 评分:8.3
龙猫 , 评分:9.2
看不见的客人 , 评分:8.8
触不可及 , 评分:9.3
放牛班的春天 , 评分:9.3
何以为家 , 评分:9.1
超能陆战队 , 评分:8.7
大话西游之月光宝盒 , 评分:9.0
猫鼠游戏 , 评分:9.1
唐伯虎点秋香 , 评分:8.7
蝙蝠侠:黑暗骑士 , 评分:9.2
心灵奇旅 , 评分:8.7
基于光标的分页数据请求

beforeId=6&max=3
从哪个id之前要几个数据
afterDate=2019-09-23T13:11:08.773Z&max=2
哪个时间之后我要几个数据
超链接数据请求
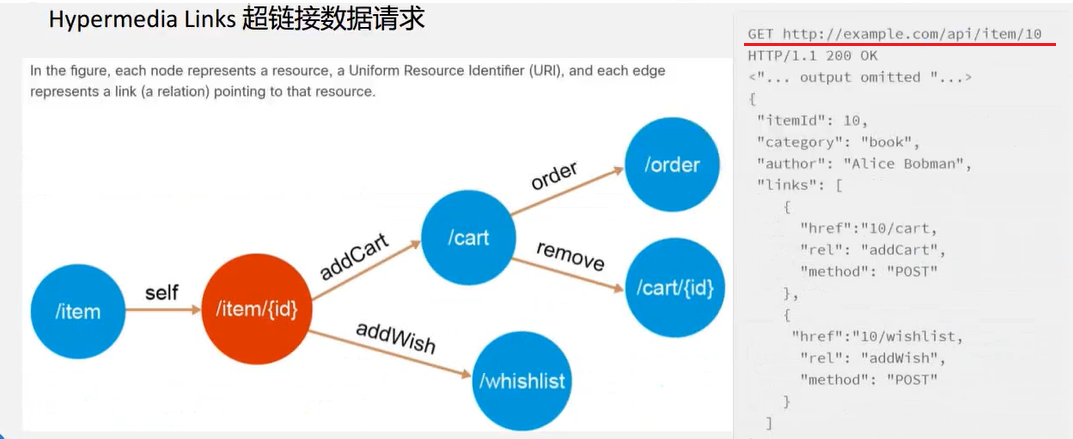
http://example.com/api/item/10
这个URL写的很具体
REST API-errors 网络错误
Network error
Network errors are present when your request does not reach the destination server orthe response from REST API did not reach the caller.there are numerous reasons for sucherrors but most of them are listed here:
- Connection timeout
- Destination host unreachable
- Destination port unreachable
- Protocol error (using HTTP when HTTPS required)
当您的请求没有到达目标服务器或来自REST API的响应没有到达调用者时,就会出现网络错误。造成这种错误的原因有很多,但这里列出了大多数原因:
- 连接超时,比如网络不好
- 目标主机不可达(无法访问这个网站)
- 是一条由网络设备(如路由器或防火墙)生成的ICMP(Internet Control Message Protocol)错误消息,用于通知源设备目标设备或端口无法到达。
- 协议错误(在需要HTTPS时使用HTTP)
request.get(timeout= )
request.get(参数timeout=0.2)
timeout 0.2秒
timeout参数可以传入一个简单的浮点数,它将请求的连接部分和读取部分设为相同的超时时间。
timeout参数也可以传入一个包含两个简单浮点数的元组,用来分别设置请求超时时间和读取超时时间。
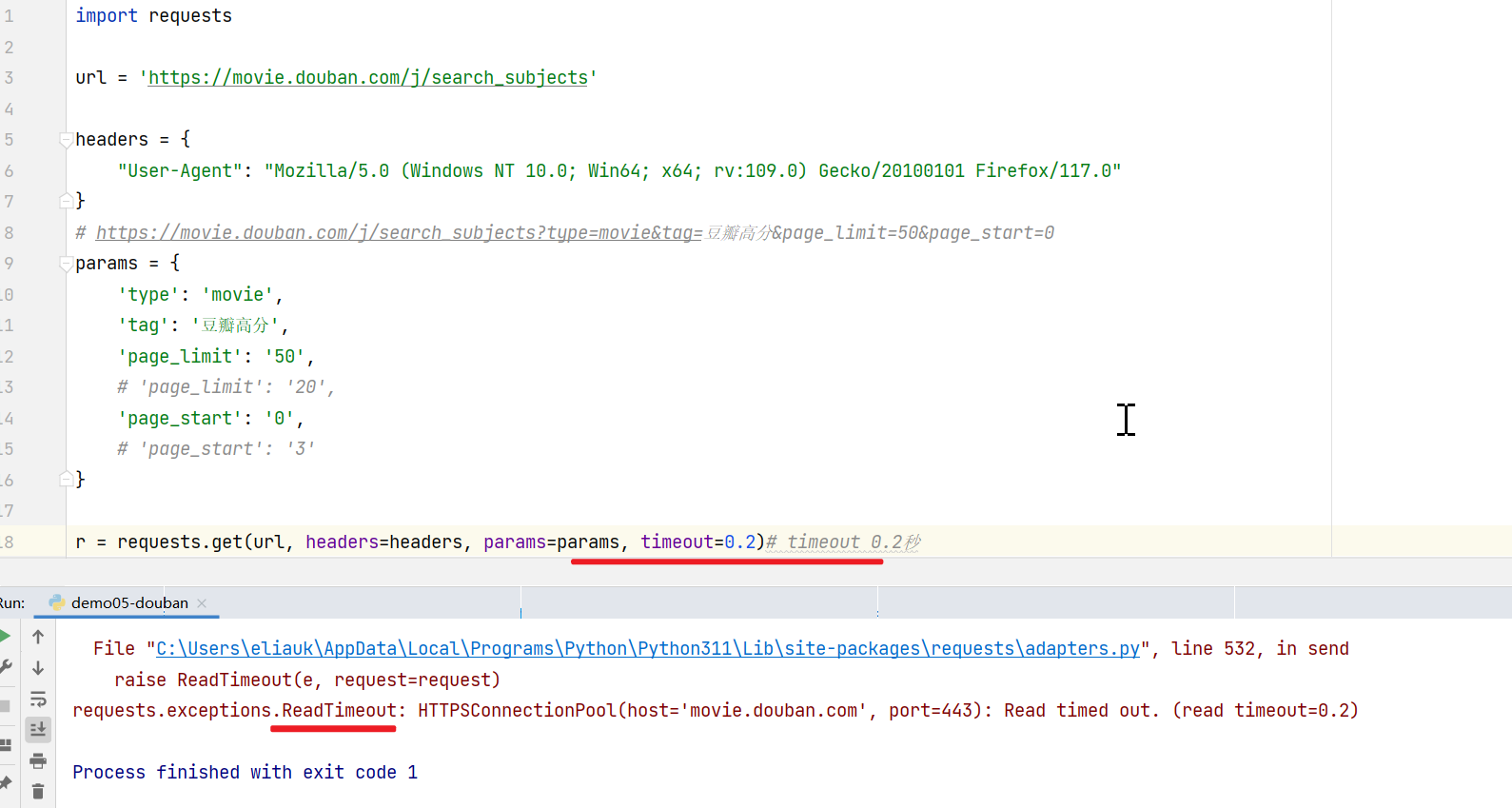
报错:读取超时
常见响应的状态码:
| HTTP状态码分类 | |
|---|---|
| 200 | 成功,操作被成功接收并处理 |
| 3XX | 表示要完成请求,需要进一步操作。 通常,这些状态代码用来重定向 |
| 4XX | 客户端错误,请求包含语法错误或无法完成请求 |
| 5XX | 这些状态代码表示服务器在尝试处理请求时发生内部错误。 这些错误可能是服务器本身的错误,而不是请求出错 |
400(错误请求)服务器不理解请求的语法
401(未授权) 请求要求身份验证。对于登录后请求的网页,服务器可能返回此响应
403(禁止) 服务器拒绝请求。你权限不够
404(末找到)服务器找不到请求的网页。例如,对于服务器上不存在的网页经常会返回此代码。
409(冲突)服务器在完成请求时发生冲突。服务器必须在响应中包含有关冲突的信息。服务器在响应与前一个请求相冲突的 PUT请求时可能会返回此代码,以及两个请求的差异列表。
410(已删除)如果请求的资源已永久删除,服务器就会返回此响应。该代码与 404 (未找到)代码类似,但在资源以前存在而现在不存在的情况下,有时会用来替代 404 代码。如果资源已永久移动,您应使用 301 指定资源的新位置
415(不支持的媒体类型)请求的格式不受请求页面的支持
411:请求太长了,请求内容太多了
429:请求太多了,有很多网站都会限制请求次数,比如限制IP, 这个IP单位时间内请求的次数不能超过多少次,超过了就是429
405: Method Not Allowed (方法禁用)禁用请求中指定的方法,请求方法不被允许,看允许哪个方法允许 ,get、post…
408:请求超时
500:(服务器内部错误)服务器遇到错误,无法完成请求。
501:(尚未实施)服务器不具备完成请求的功能。例如,服务器无法识别请求方法时可能会返回此代码。
502:(错误网关)服务器作为网关或代理,从上游服务器收到无效响应。
503:(服务不可用)服务器目前无法使用 (由于超载或停机维护)。通常,这只是暂时状态。
504:(网关超时)服务器作为网关或代理,但是没有及时从上游服务器收到请求。
505:(HTTP版本不受支持)服务器不支持请求中所用的 HTTP 协议版本。
REST API backoff (HTTP 回退机制)
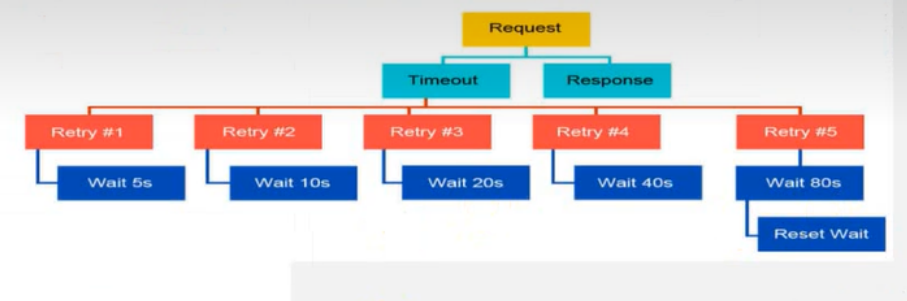
正常情况下,如果你请求成功了,他就会返回响应。
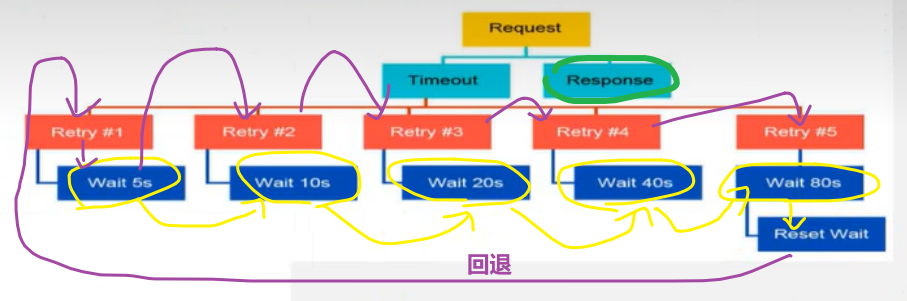
如果没成功超时了,他就会一次一次去重试,当然重试是有时间间隔,第一次等待5s,等完5s发起下一次请求,这个请求也有一个超时时间,就是前面写的timeout超时时间request.get(参数timeout=0.2) 0.2秒,过了0.2s之后没拿到数据。接下来等10s,等完10s之后再发起下一次的请求,下一次请求的超时时间还是0.2s,0.2s完了之后还没拿到响应。再进行重新试一次,等20s之后再重试发起请求 … 等待时间逐渐增加,如果等待时间增加到一定的值(80s),它会启动一个回退,回退到5s。这就是它的回退机制。
REST APl idempotency(幂等性)
幂等性原本是数学中的含义,表达式的是N次变换与1次变换的结果相同。
而RESTFui API中的幂等性是指调用某个方法1次或N次对资源产生的影响结果都是相同的,需要特别注意的是:这里幂等性指的是对资源产生的影响结果,而不是调用HTTP方法的返回结果。
API幂等性不仅仅针对RESTFul接口,而是对所有类型的接口适用,目的是为了确保调用1次或N次接口时对资源的影响结果都是相同的。
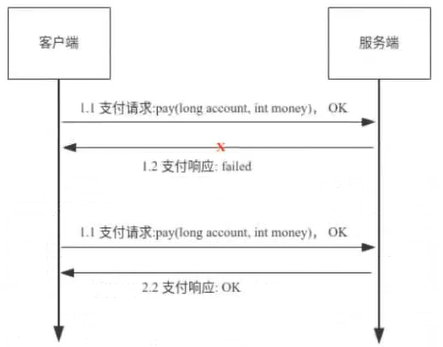
举个例子:
我们网上支付的时候,点支付按钮有时候突然网卡了,到底是支付成功了还是支付失败了;或者多点了几次支付按钮,到底是支付了一次还是支付了多次。
不管你点了多少次,3次、4次,最终的支付只有一次,也就说我点了3次支付它也是支付了一次。这就叫幂等性。
GET 方法就具有幂等性,而POST就不一样了,因为我们用POST是给服务端传数据的,每一次传的数据可能就不一样,返回的结果也就不一样,所以POST就不具有幂等性。
- OPTIONS方法常常用于获取服务器信息,不会对资源产生影响,也不会对资源进行修改,因此它是幂等的也是安全的;
- HEAD方法用于请求资源的头部信息,不会资源产生影响,也不会对资源进行修改,因此它是幂等的也是安全的。
- GET方法用于获取资源信息,虽然可能每次返回的结果都不相同,但是GET方法本身不会对资源产生影响,在RESTFul语义里GET方法也不会修改资源,因此它是幂等的,也是安全的。
- PUT方法在RESTFul语义里表示对资源进行全量更新,因此调用1次或N次的结果都是一致的,所以它是幂等的,但不是安全的。
- DELETE方法用于删除资源,调用1次或N次的结果都是相同的,因此是幂等的,但不是安全的。
- POST方法在RESTFul语义里表示新建资源,显然调用1次与调用N次的结果不同(调用1次新建1个资源,调用N次新建N个资源),因此不是幂等的,同时也不是安全的。
- PATCH方法在RESTFul语义里表示对资源的局部更新,因此不能保证调用1次与调用N次的结果相同(如:被更新的资源某个属性随着不同的调用次数在变化) ,所以不是幂等的,同时也不是安全的。
Cache-Control 缓存机制
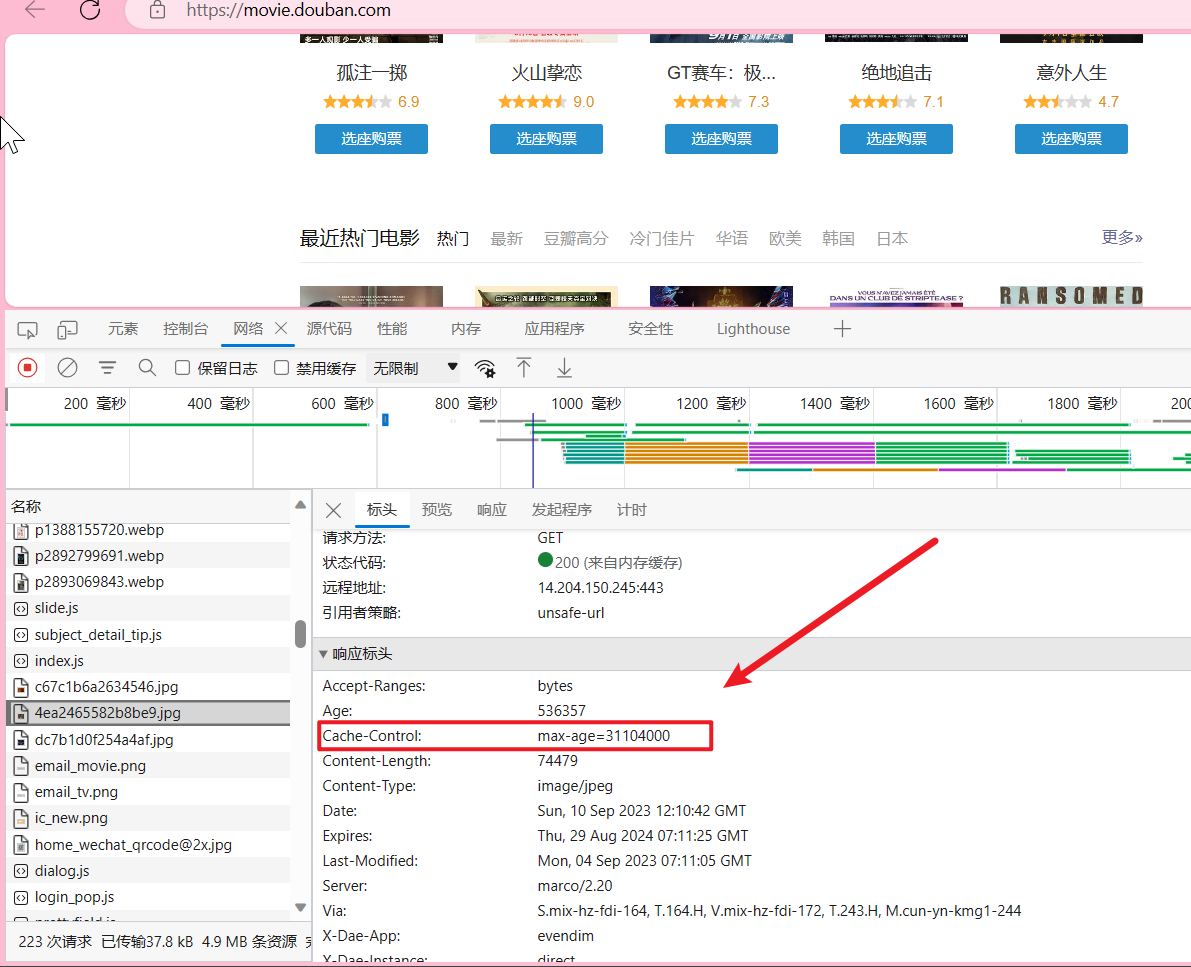
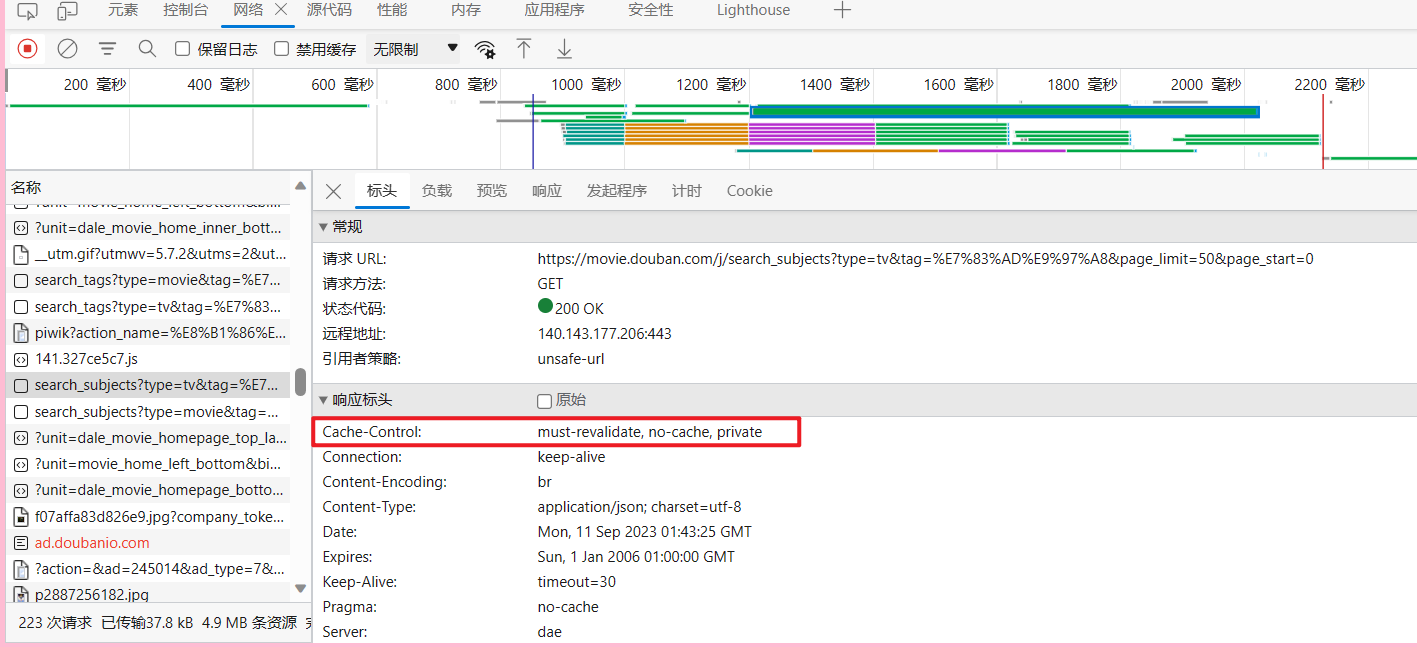
Cache-Control 可以由多个字段组合而成,主要有以下几个取值:
1.max-age 指定一个时间长度,在这个时间段内缓存是有效的,单位是s。
2.no-store 禁止缓存,每次请求都要向服务器重新获取数据。
3.public 表明响应可以被任何对象 (发送请求的客户端、代理服务器等等) 缓存。
4.private 表明响应只能被单个用户(可能是操作系统用户、浏览器用户)缓存,是非共享的,不能被代理服务器缓存
5.no-cache 强制所有缓存了该响应的用户,在使用已缓存的数据前,发送带验证器的请求到服务器。不是字面意思上的不缓存。
案例:爬取惠农网里的广东蔬菜批发价并保存到本地
https://www.cnhnb.com/hangqing/cdlist-2003192-0-19-0-0-1/
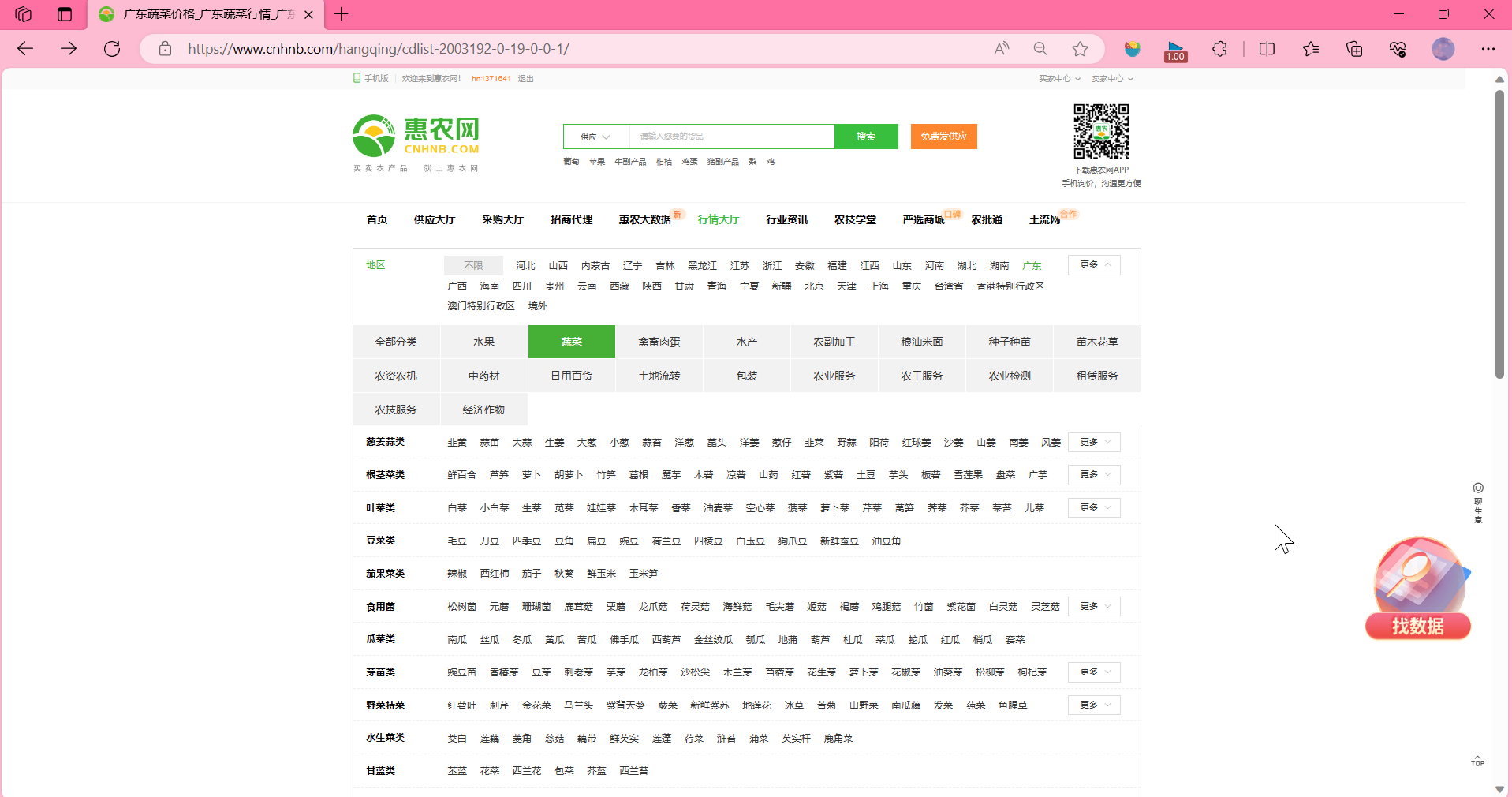
- 先观察这个页面
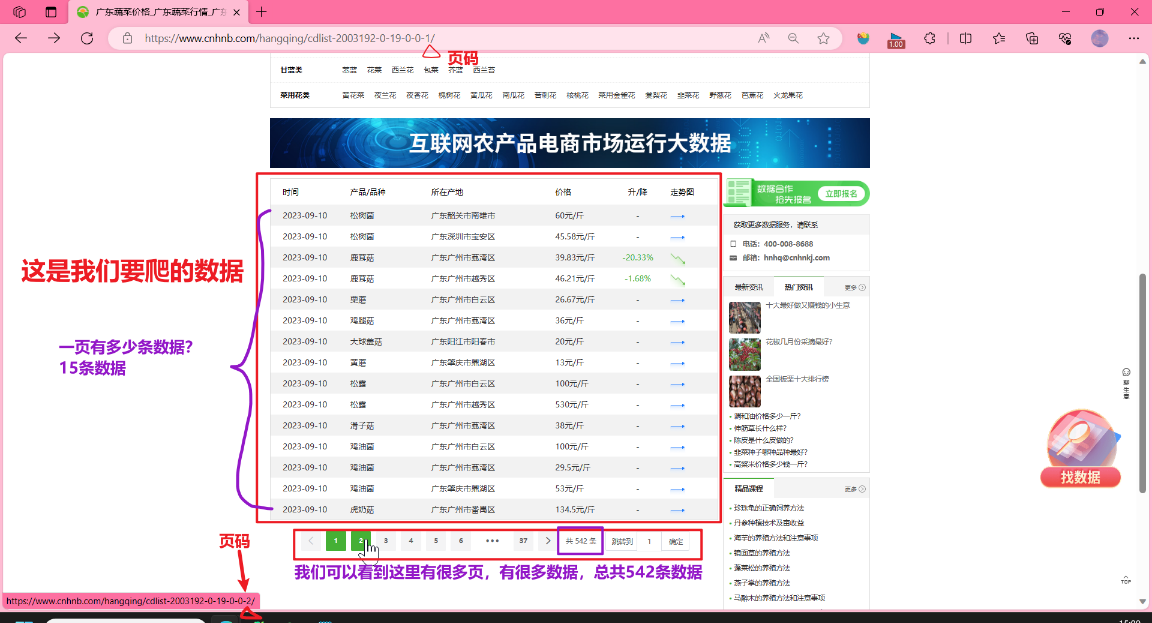
总数据542条,一页数据有15条
总共有多少页?
542/15=36.13333
是不是应该向上取整呀,math.ceil(),应该是37页
import math
print(542/15)# 36.13333333333333
print(math.ceil(542/15))# 37
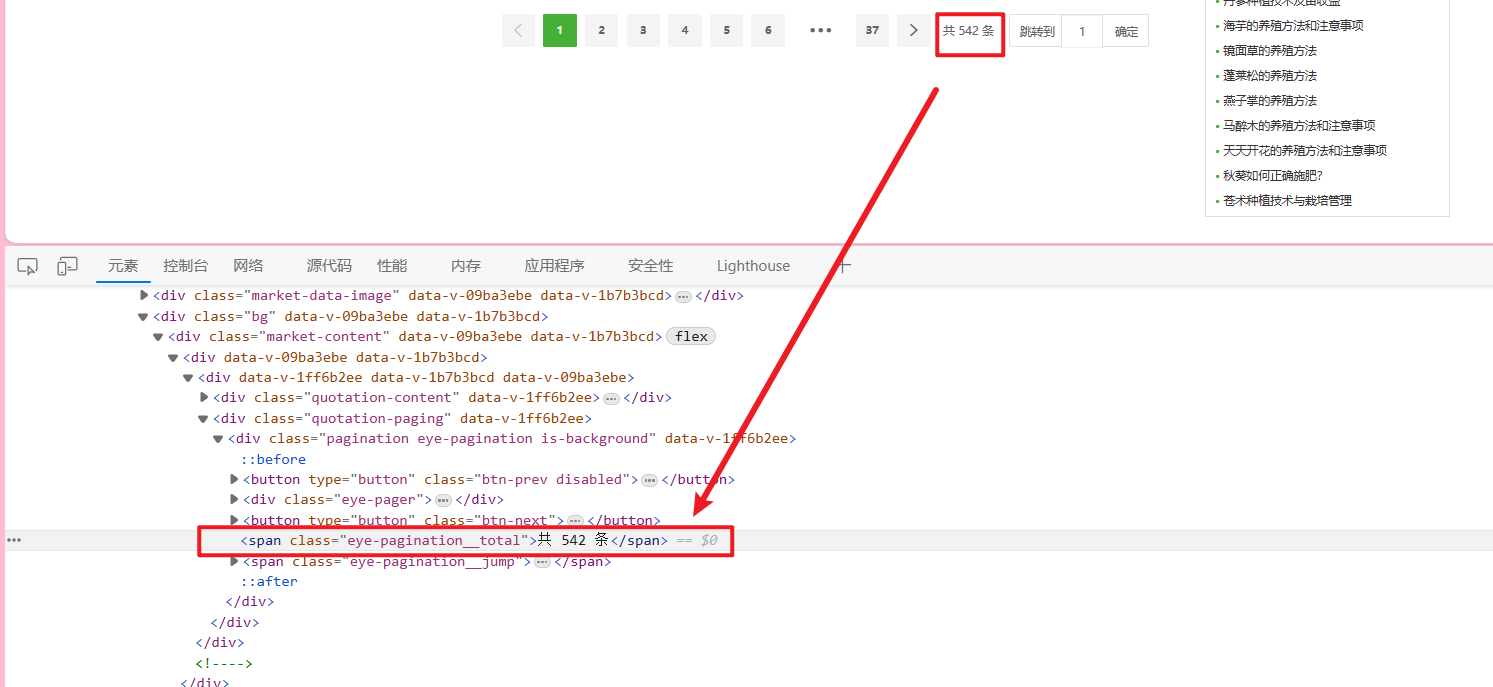
<span class="eye-pagination__total">共 542 条</span>
想要获得总数据数 可以 通过span的class来查找
soup.find_all('span', attrs={"class": "eye-pagination__total"})
#按照字典的形式给attrs参数赋值
以此类推:
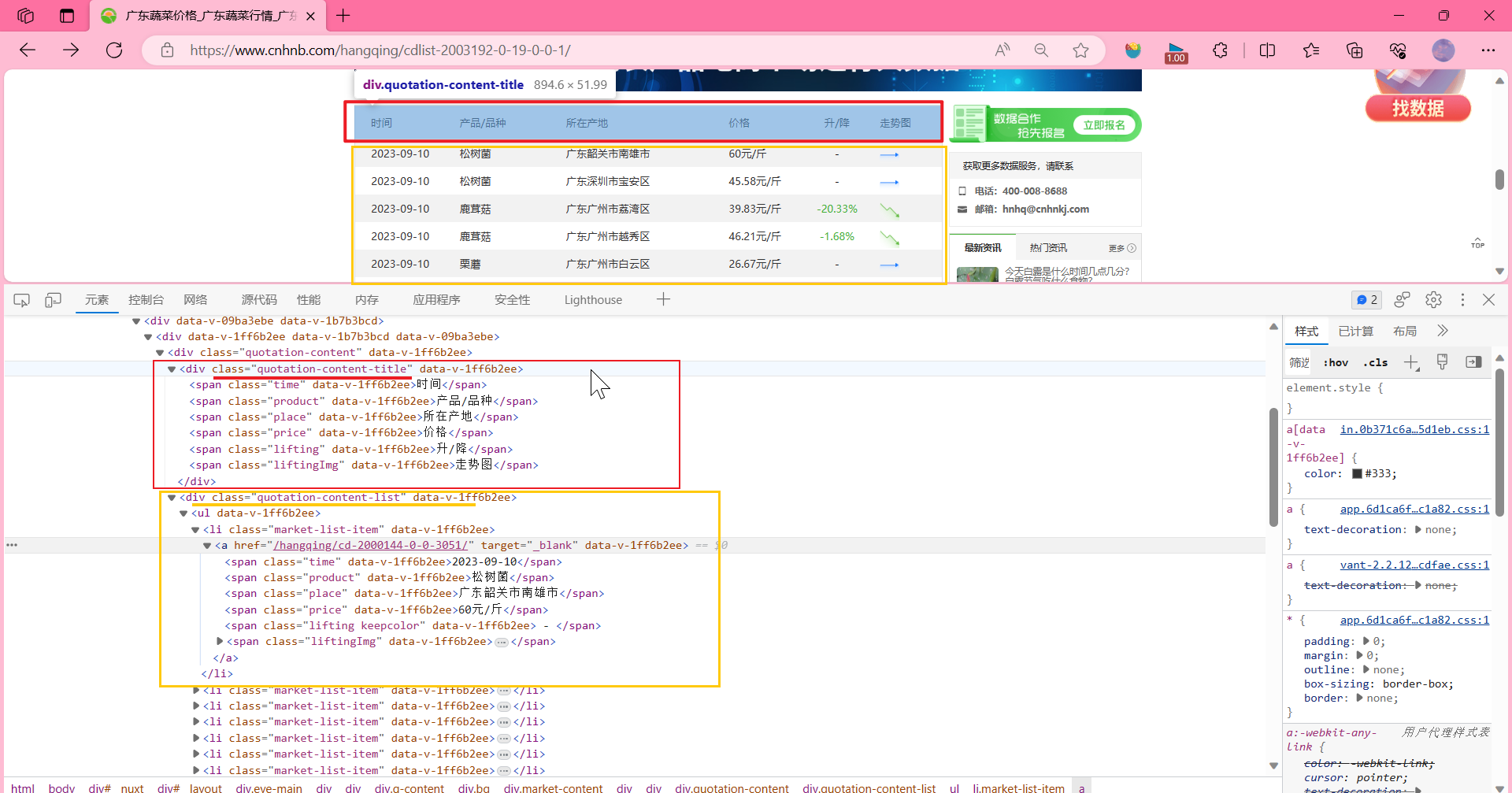
这里我们 "走势图"这列 我们存 走势图的链接吧,a的href属性里的URL。
- 写代码
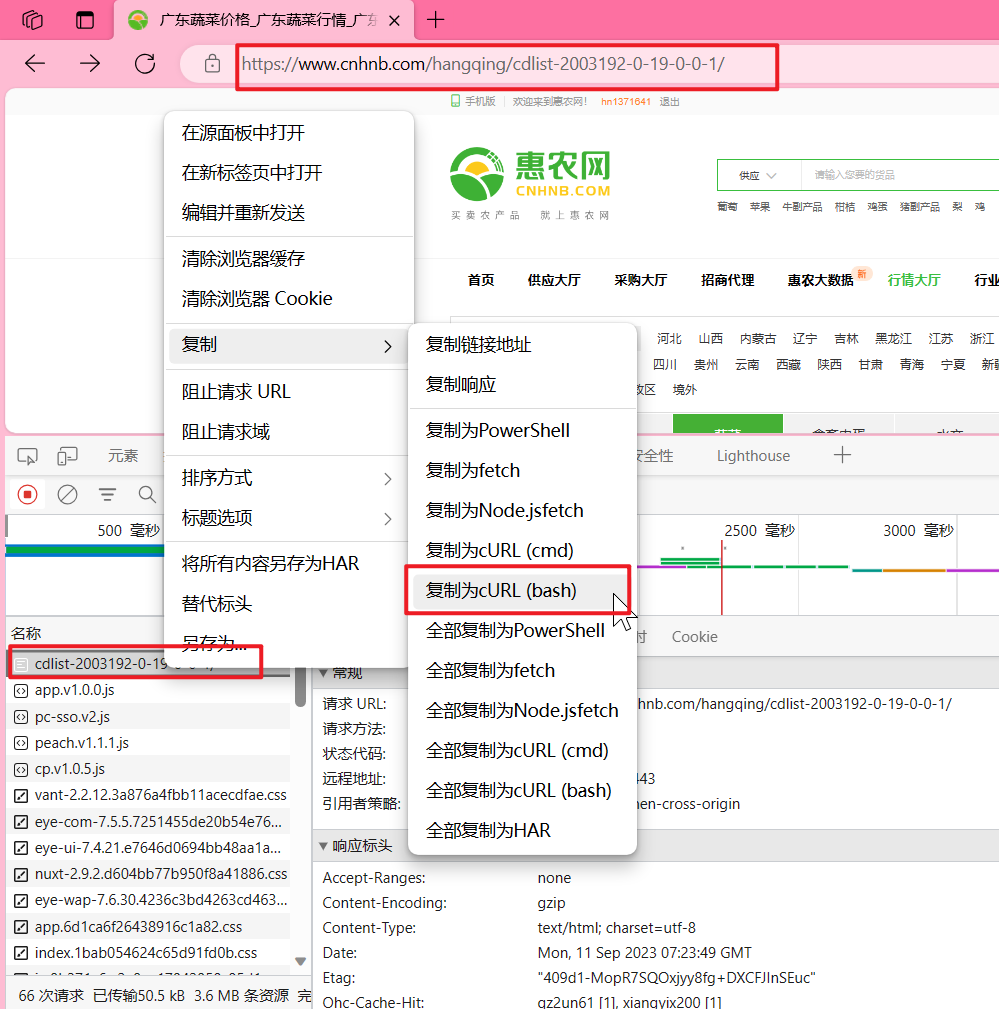
复制cURL(bash),使用我们的工具 https://curlconverter.com/,把刚刚复制的放到 curl command,它会自己生成代码,复制,等下需要用。
获取第一页的数据
import math
import requests
from bs4 import BeautifulSoup
import pandas as pd
def get_url_page_values(url_format, page_number=1, cookies={}, headers={
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36 Edg/117.0.1920.72'
}):
"""
:param url_format:
:param page_number:页码
:param cookies:
:param headers:
:return: vegetable_value, pages_num,title
返回一页数据 , 总页数 列标题
列标题:['time', 'product', 'place', 'price', 'lifting', 'liftingImg']
列标题:['时间', '产品/品种', '所在产地', '价格', '升/降', '走势图']
"""
response = requests.get(url_format.format(page_number), cookies=cookies, headers=headers)
html_doc = response.text
print("URL:", url_format.format(page_number), "状态码:", response.status_code)
# print(html_doc)
if response.status_code == 503:
# print(html_doc)
input("请解决滑块验证,随便输入点什么按回车")
# return [],0,[]
return get_url_page_values(url_format, page_number)
soup = BeautifulSoup(html_doc, 'html.parser') # .parser就是解析方法
page_total = 0 # 总数据条数
title = [] # 数据的 列标题
# 1. 获取总数据条数
# page_total = soup.find_all('span', attrs={"class": "eye-pagination__total"})[0]
# print(page_total.string, type(page_total))
# print(soup.find_all('span', attrs={"class": "eye-pagination__total"}))
page_total_str = soup.find_all('span', attrs={"class": "eye-pagination__total"})[0].string
# print(page_total_str) # "共 542 条"
page_total = int(
page_total_str[(page_total_str.find(' ') + 1):page_total_str.find(' ', page_total_str.find(' ') + 1)])
# print("总数据条数:" + page_total) # 542
# 2.获取数据的 列标题
html_title_span = soup.find_all('div', attrs={"class": "quotation-content-title"})[0].find_all('span') # 列标题
"""
for i in html_title_span:
# print(i.string)
title.append(i.string)
# print(title) # ['时间', '产品/品种', '所在产地', '价格', '升/降', '走势图']
"""
for i in html_title_span:
title.extend(i.get('class'))
# print("列标题", title) # ['time', 'product', 'place', 'price', 'lifting', 'liftingImg']
# 3. 获得一页的数据 和 一页有多少数据
vegetable_value = [] # 一页的数据
html_vegetable_list_a = soup.find_all('div', attrs={"class": "quotation-content-list"})[0].find_all('a')
page_size = len(html_vegetable_list_a) # 每页的数据条数
pages_num = math.ceil(page_total / page_size) # 总页数
# print("总页数:", pages_num, " 当前页数:", page_number)
for a_item in html_vegetable_list_a:
span_list = a_item.find_all('span')
vegetable_value_item = [] # 一行数据
# print(len(title[:-2])) # 4
# 总共6列,最后一列'走势图'我们用链接,倒数第二列我们需要处理一下,我们循环前4列
for index in range(len(title[:-2])):
# print(span_list[index].string)
vegetable_value_item.append(span_list[index].string)
lifting = span_list[-2].string # '升/降' 列
# print(lifting)
"""
'\n 一堆空格 -\n 一堆空格 '
或者
'\n 一堆空格 -20.33%\n 一堆空格 '
"""
vegetable_value_item.append(lifting[lifting.find('-'):lifting.rfind('\n')])
vegetable_value_item.append("https://m.cnhnb.com/" + a_item.get('href'))
# print(vegetable_value_item)
vegetable_value.append(vegetable_value_item)
# 返回一页数据, 总页数 列标题
return vegetable_value, pages_num, title
# 创建csv文件
def create_csv_file(vegetable_value, title, filename):
"""
把vegetable_value数据保存到'vegetable_value'目录中
:param vegetable_value: 数据
:param title: 列标题
:param filename: 文件名
:return:
"""
'''
把vegetable_value目录下的文件绝对路径保存到csv文件中,同时把文件名中的label也保存下来
保存两列 filename, label
:return:
'''
df = pd.DataFrame(data=vegetable_value,
columns=title)
# df.to_csv('./vegetable_value/{}.csv'.format(filename)) # 默认值是True, 表示保存每行的行索引
df.to_csv('./vegetable_value/{}.csv'.format(filename), index=False) # False表示不保存行索引
if __name__ == "__main__":
vegetable_value = [] # 最后得到的蔬菜数据
page_number = 1 # 当前页码
# url = 'https://www.cnhnb.com/hangqing/cdlist-2003192-0-19-0-0-1/'
url_format = 'https://www.cnhnb.com/hangqing/cdlist-2003192-0-19-0-0-{}/'
# title 是列标题
page_value, pages_num, title = get_url_page_values(url_format, page_number) # 返回一页数据, 总页数,列标题
vegetable_value.extend(page_value)
print(f'第{page_number}页数据获取完毕')
# for i in range(page_number + 1, pages_num):
# page_value, pages_num, title = get_url_page_values(url_format, i) # 返回值:一页数据, 总页数,列标题
# vegetable_value.extend(page_value)
# print(f'第{i}页数据获取完毕')
# print(len(vegetable_value), title)
# 列标题:['时间', '产品/品种', '所在产地', '价格', '升/降', '走势图']
# 列标题:['time', 'product', 'place', 'price', 'lifting', 'liftingImg']
# print(len(vegetable_value), title)
create_csv_file(vegetable_value, title, '2023-09-11')
执行结果:
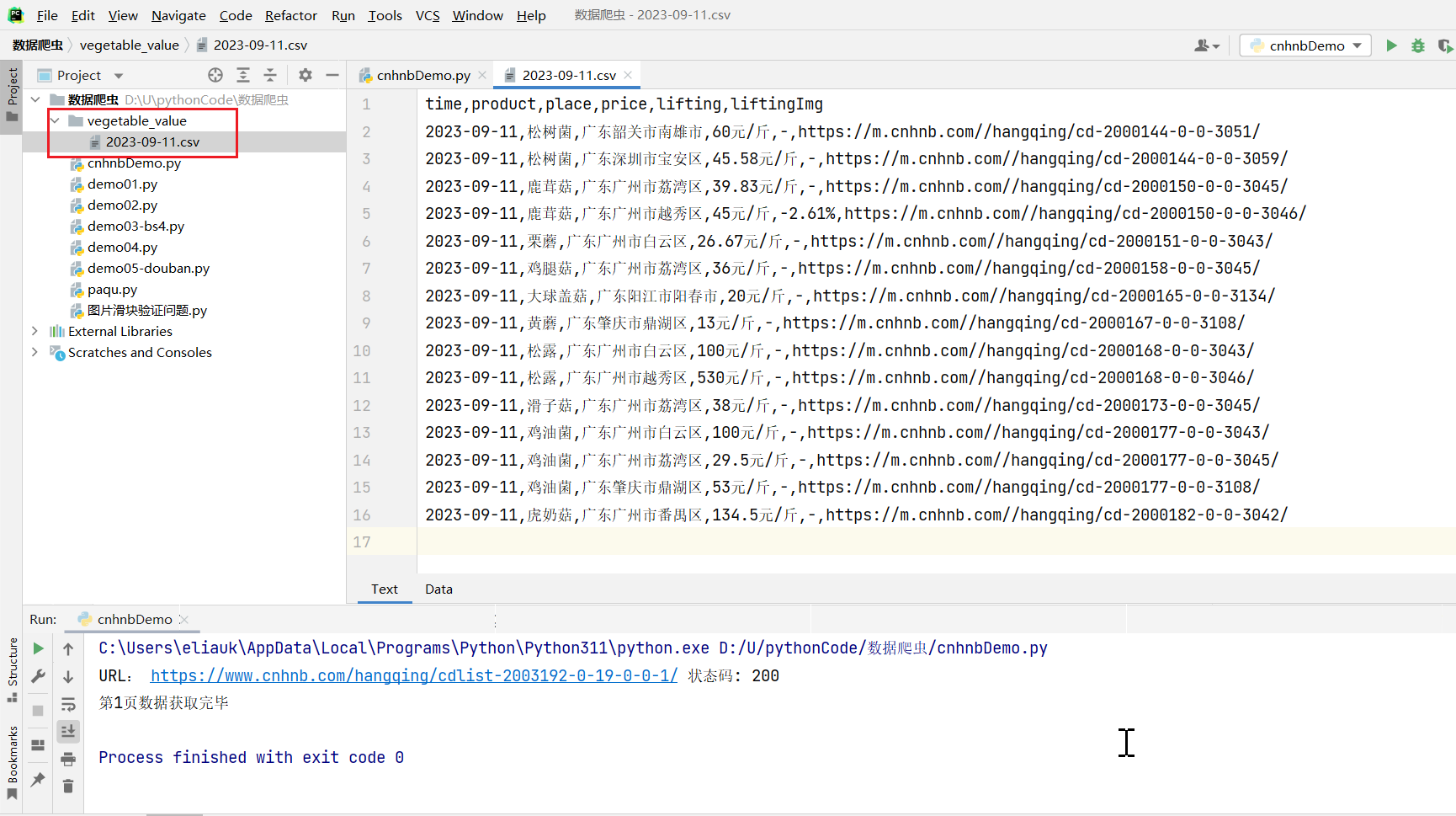
获取所有页的数据
if __name__ == "__main__":
vegetable_value = [] # 最后得到的蔬菜数据
page_number = 1 # 当前页码
# url = 'https://www.cnhnb.com/hangqing/cdlist-2003192-0-19-0-0-1/'
url_format = 'https://www.cnhnb.com/hangqing/cdlist-2003192-0-19-0-0-{}/'
# title 是列标题
page_value, pages_num, title = get_url_page_values(url_format, page_number) # 返回一页数据, 总页数,列标题
vegetable_value.extend(page_value)
print(f'第{page_number}页数据获取完毕')
for i in range(page_number + 1, pages_num):
page_value, pages_num, title = get_url_page_values(url_format, i) # 返回值:一页数据, 总页数,列标题
vegetable_value.extend(page_value)
print(f'第{i}页数据获取完毕')
# print(len(vegetable_value), title)
# 列标题:['时间', '产品/品种', '所在产地', '价格', '升/降', '走势图']
# 列标题:['time', 'product', 'place', 'price', 'lifting', 'liftingImg']
# print(len(vegetable_value), title)
create_csv_file(vegetable_value, title, '2023-09-11')
执行
我们遇到了503,我们打开浏览器看一下,图片滑块验证问题
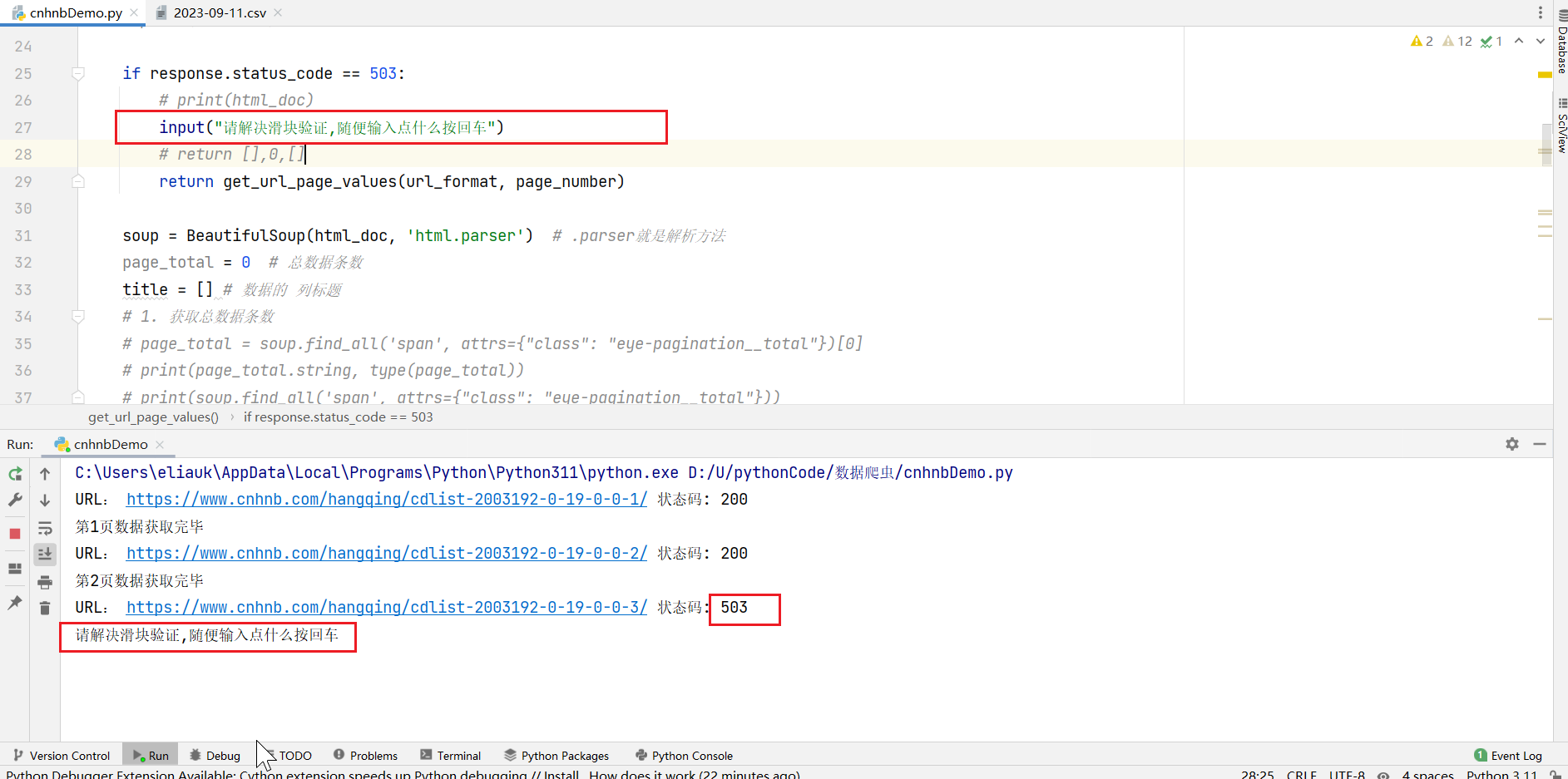
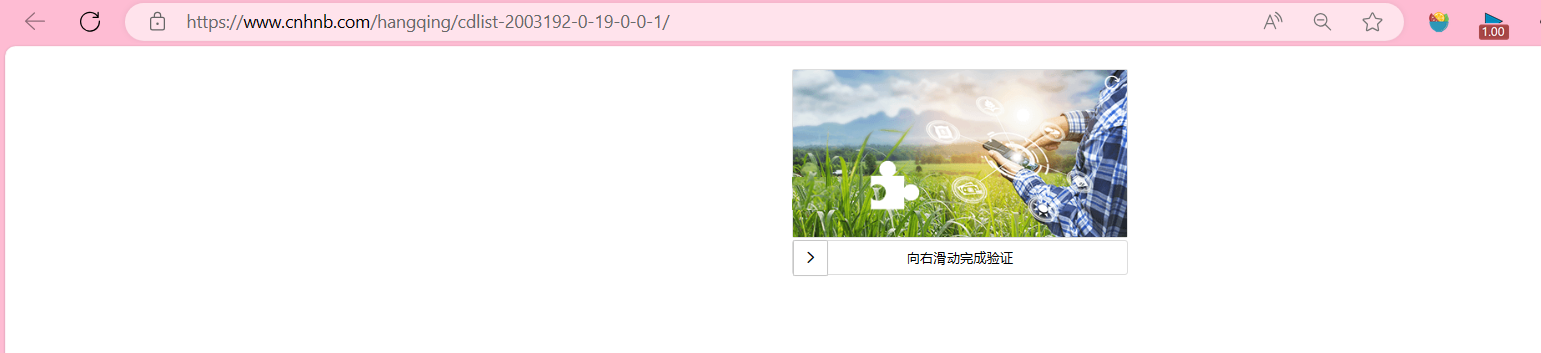
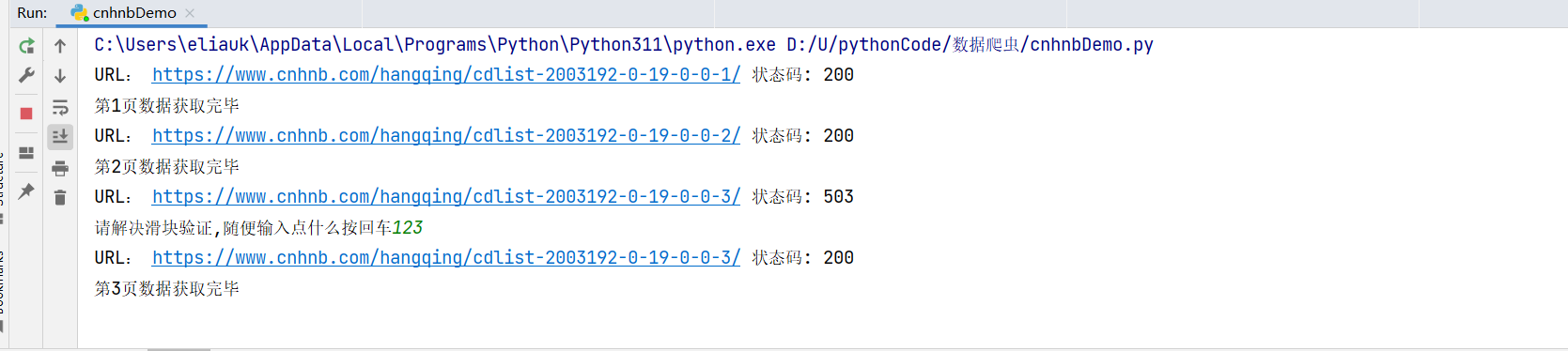
新问题
我们总不能老是手动来做验证吧?
这个网站不止滑块验证一种来反爬虫,本文章就不写反反爬虫了,感兴趣的可以自己去百度找资源学习。
爬虫、反爬虫与反反爬虫
- 爬虫
- 自动获取网页信息的程序。
- 反爬虫
- 阻止爬虫程序获取网页信息的程序。
- 反反爬虫
- 应对反爬虫程序,爬取网页信息的程序。
其中,爬虫和反反爬虫是用户的行为;反爬虫是服务器的行为。
常见的反爬虫技术
主要包括以下四种:
1)Headers校验
2)动态页面
3)IP限制
4)验证码
HTTP的请求头(headers)是指每次向网络服务器发送请求时传递的一组属性和配置信息。
HTTP定义了十多种请求头类型,但只有几个字段比较常用。对 HTTP 请求头的每个属性进行“是否具有人性”的检查,就是为了阻挡爬虫程序。
| 属性 | 内容 |
|---|---|
| Host | www.baidu.com |
| Connection | keep-alive |
| Accept | text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,/;q=0.8,application/signed-exchange;v=b3;q=0.7 |
User-Agent | Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36 Edg/115.0.1935.75 |
| Referer | https://cn.bing.com/ |
| Accept-Encoding | gzip, deflate, br |
| Accept-Language | zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6 |
请求头可以通过requests模块进行自定义。
Headers校验
- User-Agent
User Agent,中文名为用户代理,简称 UA,它是一个特殊字符串头,使得服务器能够识别客户使用的操作系统及版本、CPU 类型、浏览器及版本、浏览器渲染引擎、浏览器语言、浏览器插件等。
在网络请求当中,User-Agent 是标明身份的一种标识。网站通过判断 UA 来给不同的操作系统、不同的浏览器发送不同的页面,因此可能造成某些页面无法在某个浏览器中正常显示,但通过伪装UA 可以绕过检测。
UA反爬虫:是一种黑名单策略,只要出现在黑名单中的请求,都视为爬虫,对于此类请求将不予处理或返回错误提示。
绕过 UA反爬虫:将爬虫程序中请求头的 User-Agent 的值改为浏览器的User-Agent ,这样就能够欺骗服务器,达到绕过反爬虫的目的。















 508
508











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









