






 本文介绍了使用后羿采集器爬取京东数据的流程,以及Python的docx模块如何创建和编辑Word文档,包括添加标题、段落、表格、图片和修改字体样式,还涉及到页眉页脚的设置和PDF转Word的方法。
本文介绍了使用后羿采集器爬取京东数据的流程,以及Python的docx模块如何创建和编辑Word文档,包括添加标题、段落、表格、图片和修改字体样式,还涉及到页眉页脚的设置和PDF转Word的方法。
十六周内容笔记
day46
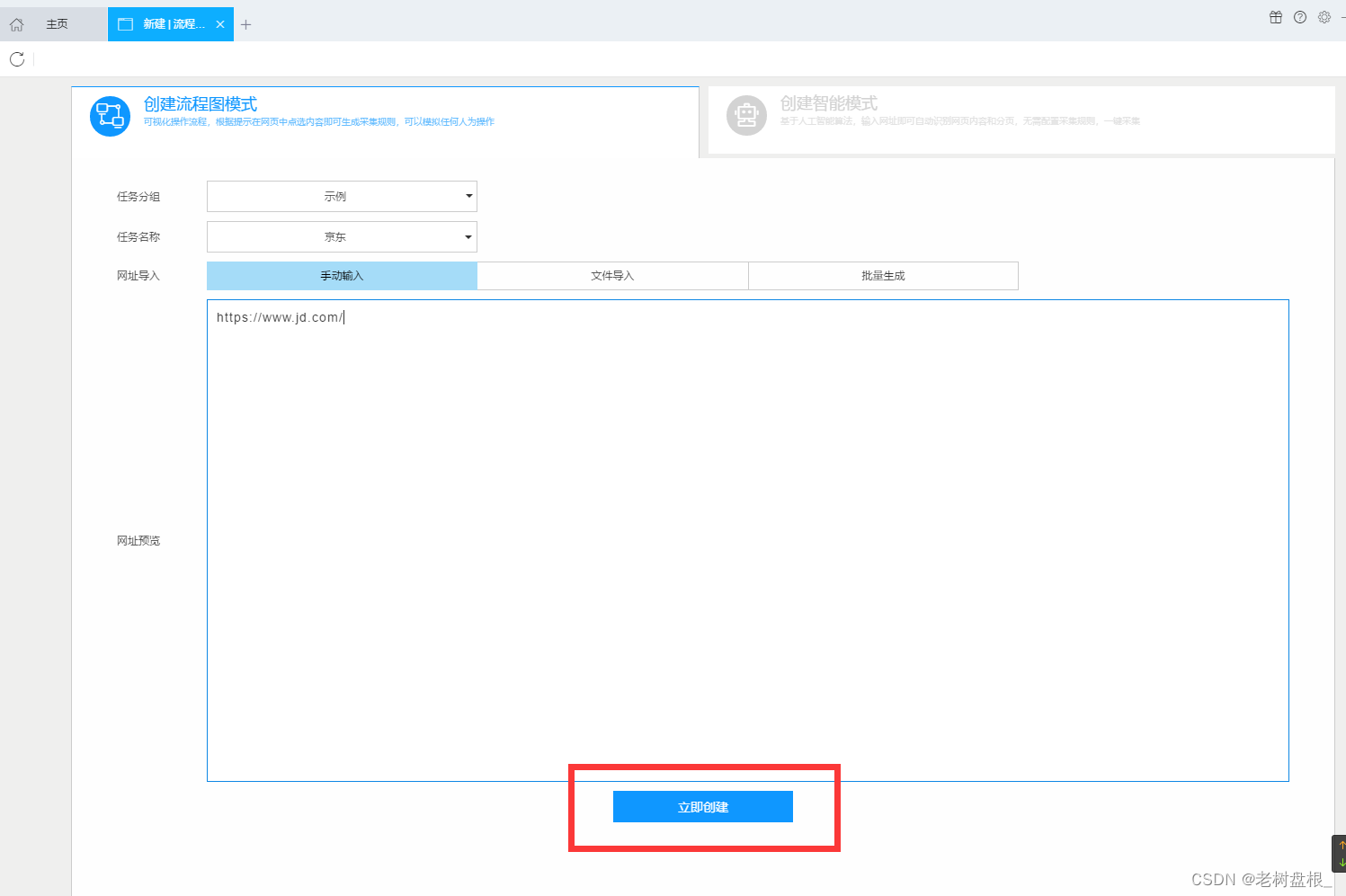
使用后羿采集器的流程图模式对京东进行爬取
创建任务
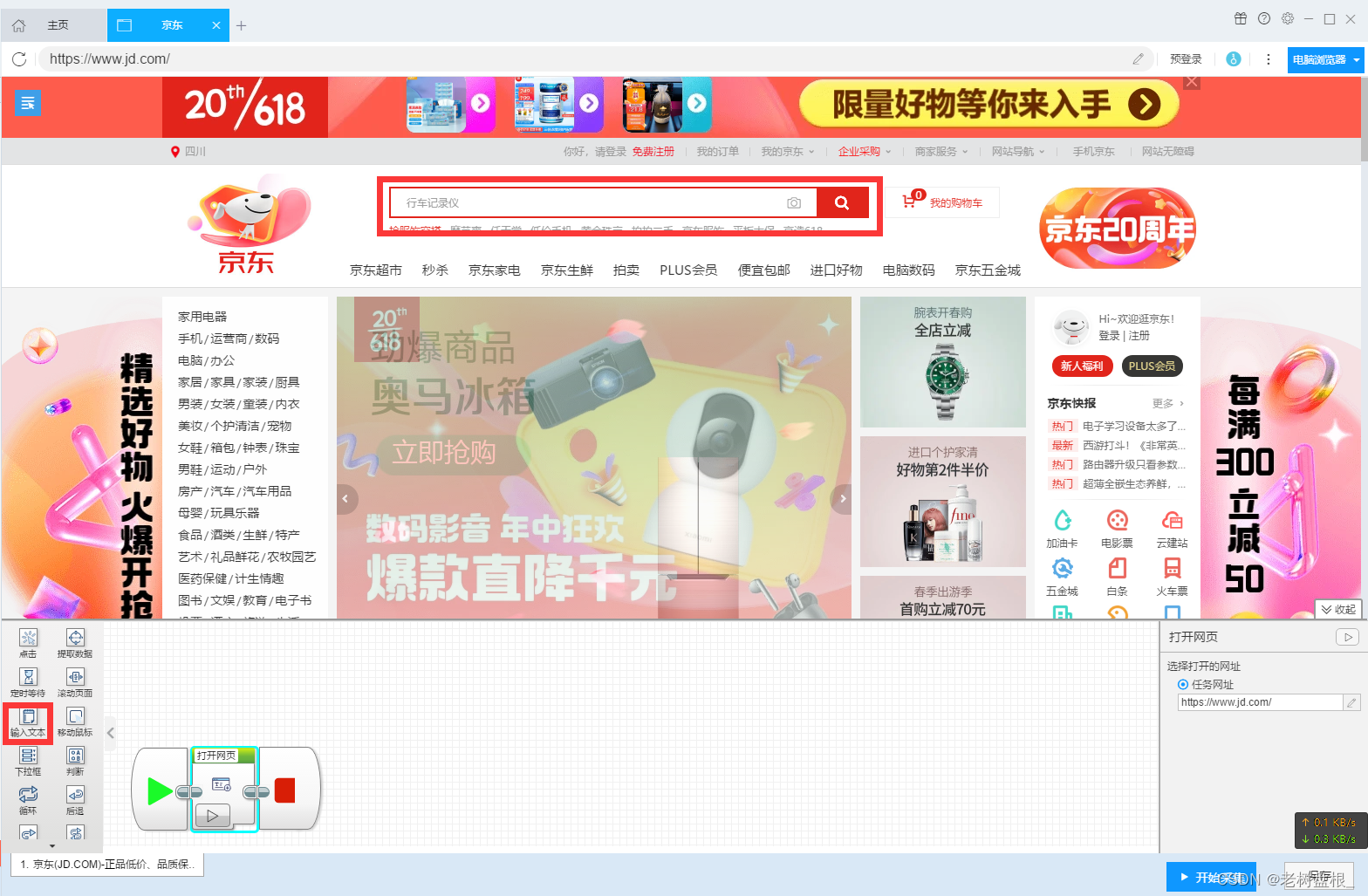
在搜索框输入要输入的内容并确定
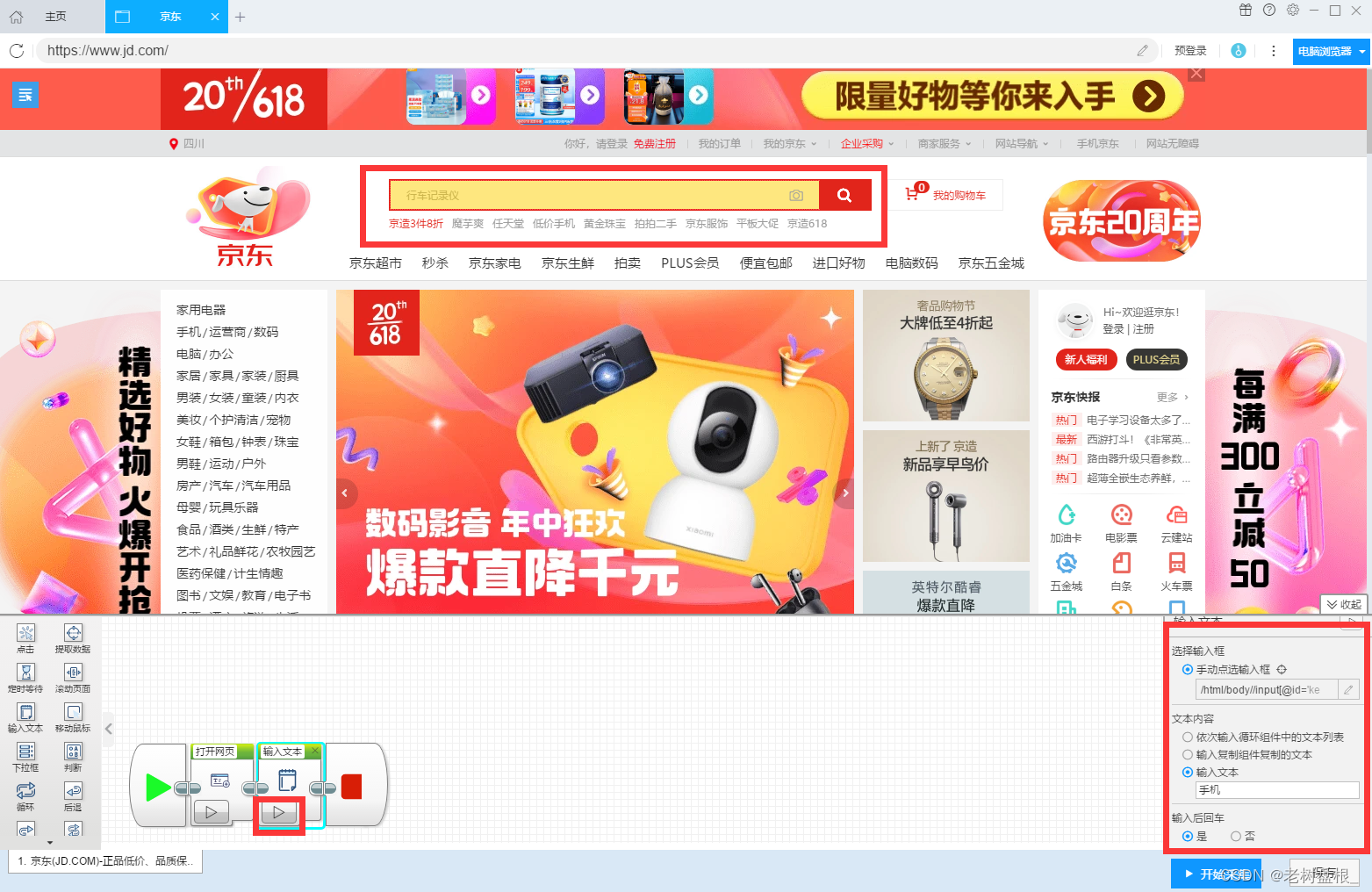
开始采集数据(只需要点击想要的商品元素等待工具自动识别就可以,这里我选择的是商品名称)
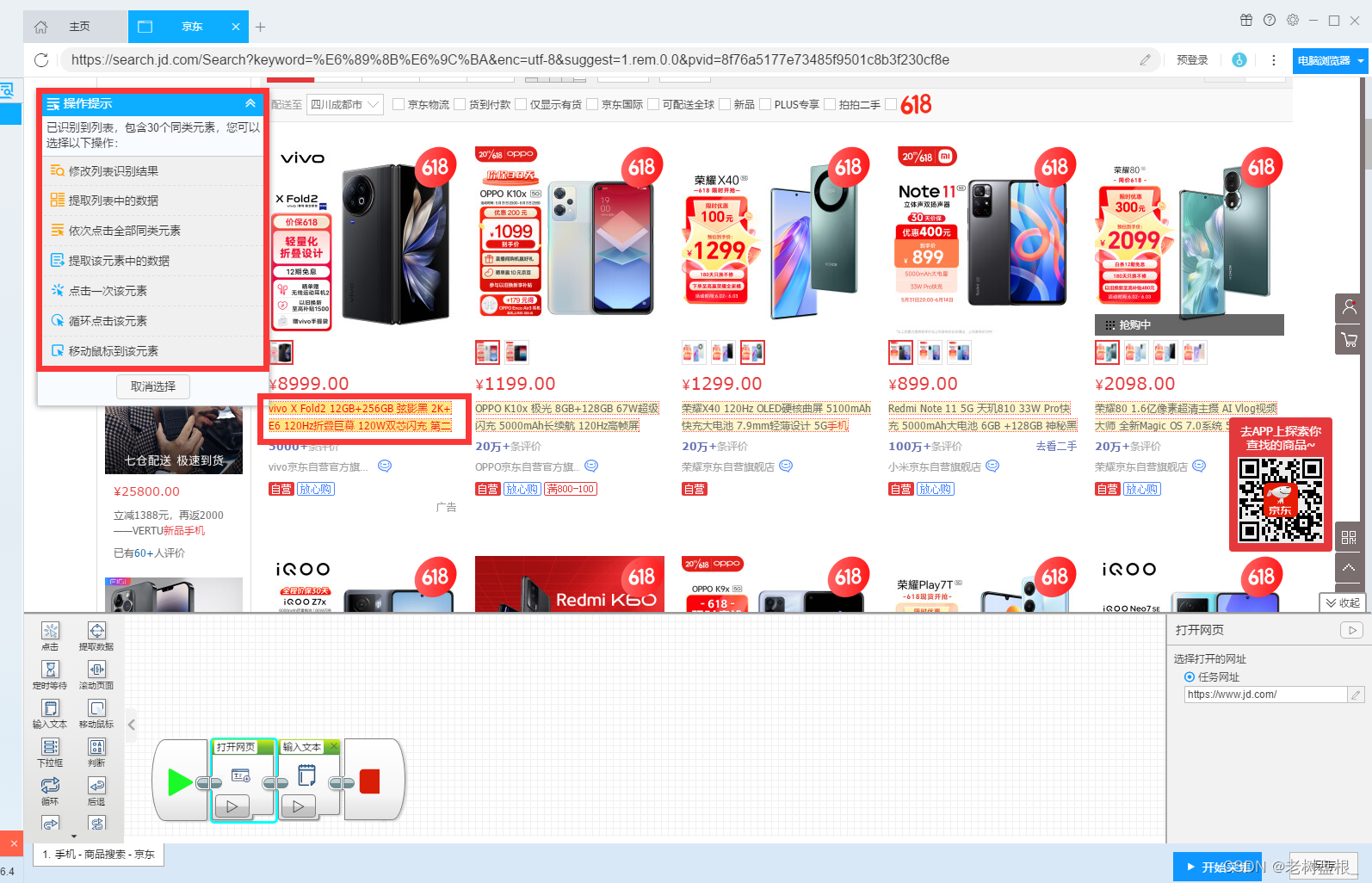
还有操作提示,非常的人性化
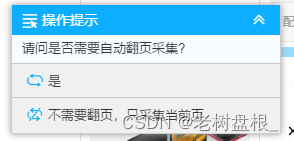
这里的分页是没有正确的,需要滑动到下面才可以识别到正确的分页
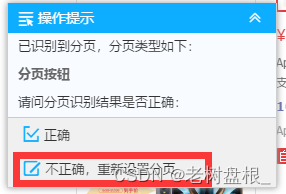
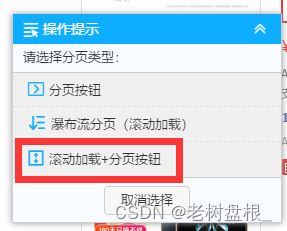
按照提示操作
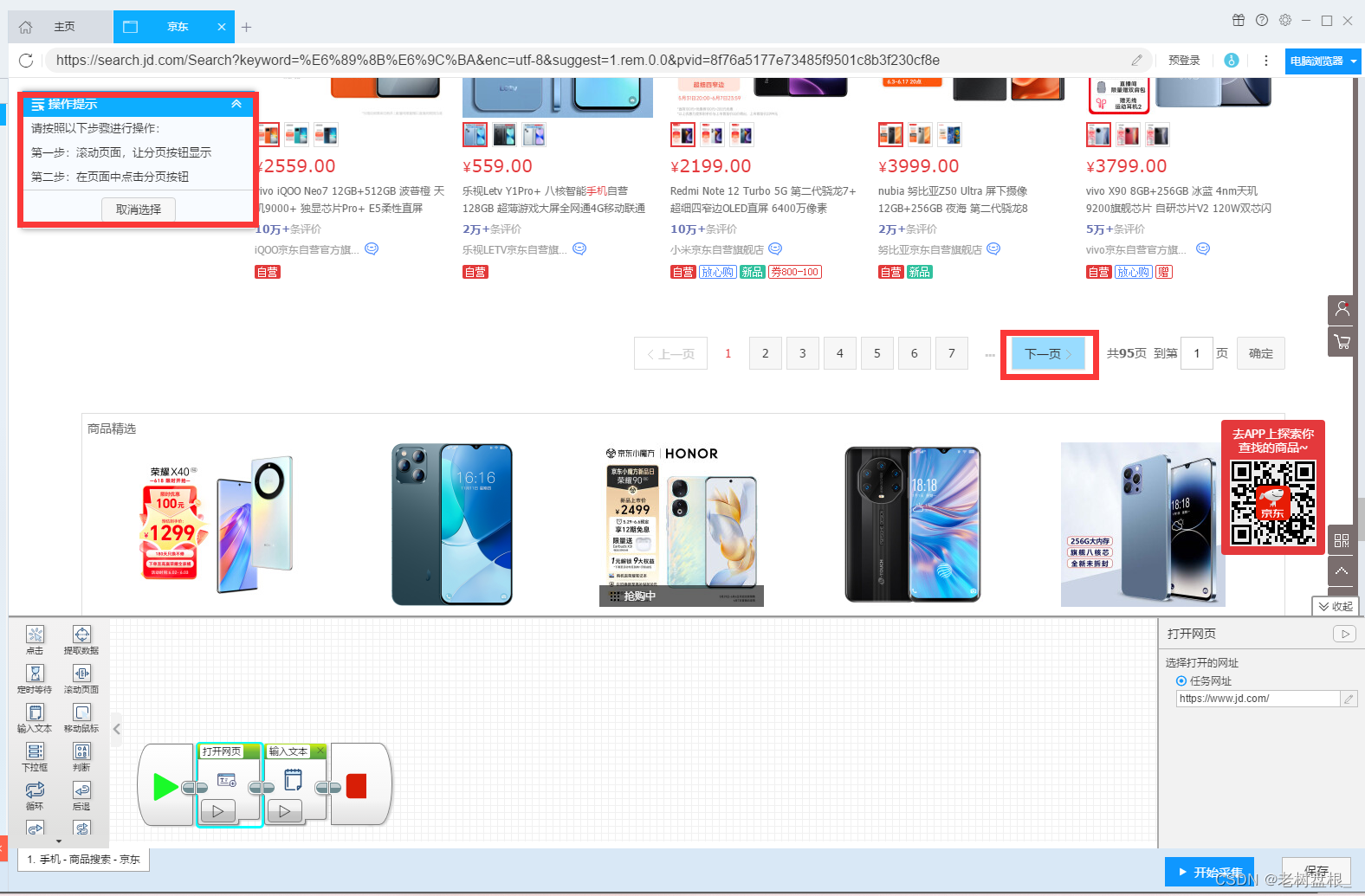
他会为你自动生成流程图,非常的智能快捷,现在就可以开始采集了
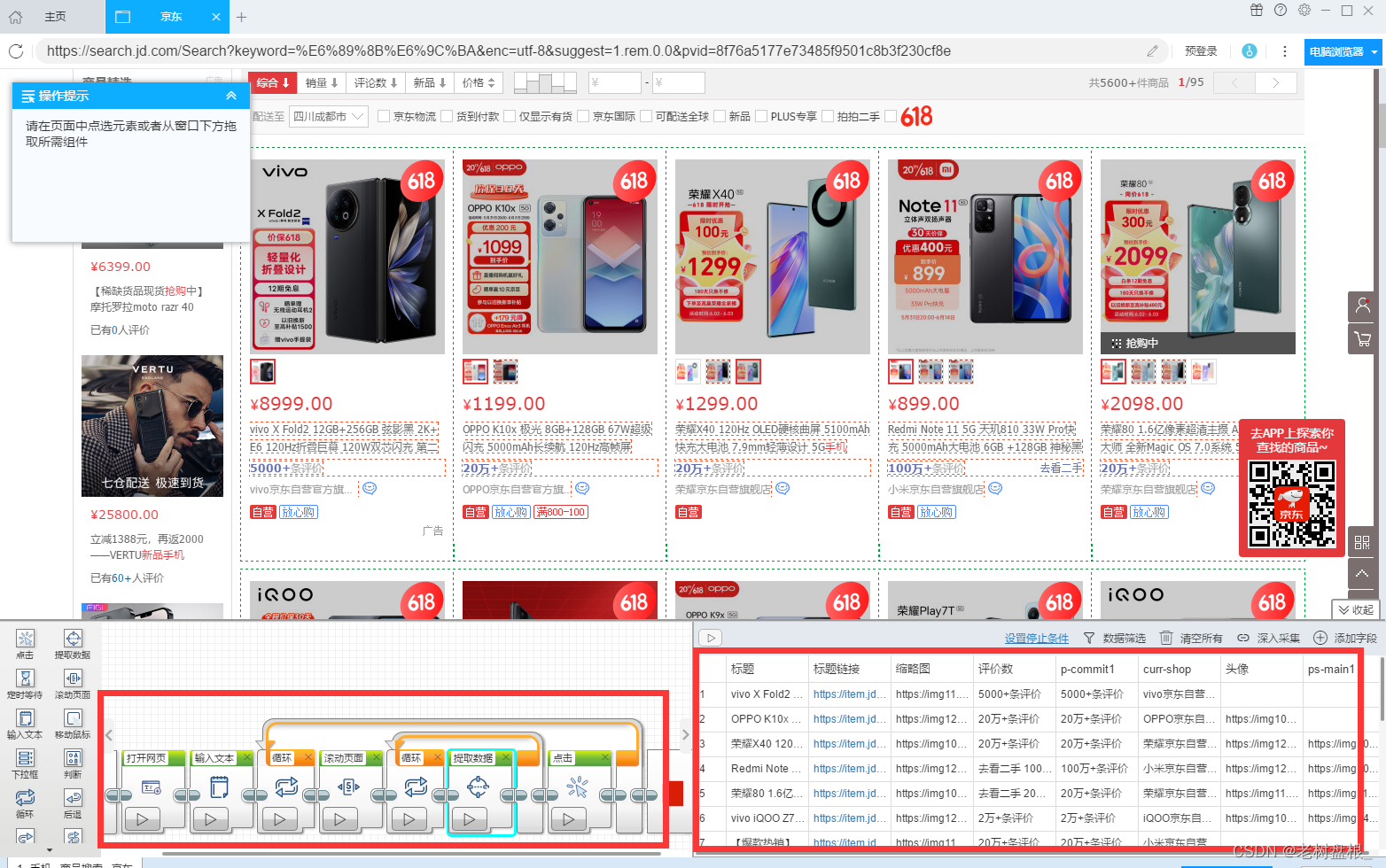
这个工具简单智能,不能说强大但是确实很智能哈哈
day47
01-python操作word文档
python-docx 模块安装:pip install python-docx
# Doucument:使用Document方法创建word文档
# word文档后缀名:docx、doc
# docx后缀名本是word的后缀名,wps创建的word的后缀名为doc
from docx import Document
# 空白的word
doc_1 = Document()
# add_heading():添加标题
# level() 一共0~9十个等级,数值越小,表示字号越大
doc_1.add_heading('唐诗三百首', level=0)
doc_1.add_heading('唐诗三百首', level=1)
doc_1.add_heading('唐诗三百首', level=2)
doc_1.add_heading('比赛背景', level=1)
content = ' 古诗大赛是一项弘扬中华文化、传承经典的比赛活动,它通过让参赛者撰写中文古诗,' \
'培养他们对经典诗歌的欣赏和理解能力,同时也拓展了他们的创作视野和写作技能。' \
'古诗大赛旨在鼓励青少年学习中华经典诗歌,传承中华文化。' \
'因此,比赛的主办方一般会选择一位著名的文学专家或作家作为评委,根据古诗的语言表达与技巧'
# add_paragraph():添加段落
doc_1.add_paragraph(content)
# 添加一首古诗:《忘庐山瀑布》
doc_1.add_heading('望庐山瀑布', level=1)
p_1 = doc_1.add_paragraph('日照香炉生紫烟, \n遥看瀑布挂前川。\n')
# insert_paragraph_before():在*段落之前插入内容
p_1.insert_paragraph_before('唐 李白')
# add_run:继续写
p_1.add_run('飞流直下三千尺,\n 疑似银河落九川。')
# 分页符:add_page_break()
doc_1.add_page_break()
# add_table:添加表格
table_1 = doc_1.add_table(rows=1, cols=2)
# 下标为0的第一行
# cells:获取所有单元格
th = table_1.rows[0].cells
th[0].text = '作者'
th[1].text = '诗词'
data = [
['李白', '将进酒'],
['李白', '望月'],
['苏轼', '江城子 密州出猎']
]
# 添加行:add_row()
for i in data:
row_cell = table_1.add_row().cells
row_cell[0].text = i[0]
row_cell[1].text = i[1]
# 添加图片:add_picture
from docx.shared import Inches, Cm, Pt
# Inches(英寸)/Cm(厘米)/Pt(磅) --> word 文档支持这三种单位
# 添加图片时,支持调节宽高,但是不建议同时给宽高加数值,单独给宽或者高添加尺寸,
# 另一个没有添加尺寸的会按照比例自动缩放
doc_1.add_picture('./背景图1.jpg', width=Inches(6.0))
doc_1.save('./word 文档1.doc')
doc_1.save('./word 文档1.docx')
word 文档的页面结构:段落、文字块、标题、图片、表格
02-python修改文档字体
from docx import Document
doc_2 = Document()
# 添加一个空白段落
p_1 = doc_2.add_paragraph()
# 修改字体是否加粗(bold),是否倾斜(italic)
p_1.add_run('静夜思').bold = True
p_1.add_run('静夜思').italic = True
a = p_1.add_run('唐 李白')
a.bold = True
a.italic = True
# docx.shared -> 样式模块
from docx.shared import Pt, RGBColor
a.font.size = Pt(20)
# 修改字的颜色:RGBColor -> RGB -> 三原色(红绿蓝)
# RGB也被叫做加色模式,通过R、G、B的辐射量,可描述出任何一种颜色
# 计算机中定义的RGB分别又0-255一共256个等级,0表示没有刺激量,255表示刺激量最大
# RGB共同为0时构成了黑色,共同为255时,刺激量达到最大,为白光。
a.font.color.rgb = RGBColor(124, 252, 0)
# ----以下代码都是在声明都是有了”宋体“这个字体----
# 字体样式的设置:宋体、楷体、隶书
# WD_STYLE_TYPE -> word_style_type
from docx.enum.style import WD_STYLE_TYPE
# 设置宋体样式
# 将宋体添加到style_font中
style_font = doc_2.styles.add_style('楷体', WD_STYLE_TYPE.CHARACTER)
# 声明这个字体叫做宋体
style_font.font.name = '楷体'
from docx.oxml.ns import qn
# w:eastAsia --> w表示world、eastAsia代表东亚
doc_2.styles['楷体']._element.rPr.rFonts.set(qn('w:eastAsia'), '楷体')
# ------------------------------------------
p_1.add_run('静夜思', style='楷体')
doc_2.save('字体配置.docx')
day48
01-字体样式的修改
from docx import Document
doc = Document()
p_1 = doc.add_paragraph('尊敬的 xxx:')
# WD_STYLE_TYPE:word文档的样式类型
from docx.enum.style import WD_STYLE_TYPE
# qn:自定义字体
from docx.oxml.ns import qn
def font_setting(font_name):
# 先把字体加进来
style_font = doc.styles.add_style(font_name, WD_STYLE_TYPE.CHARACTER)
# 再去起名字
style_font.font.name = font_name
# 再去声明地区
doc.styles[font_name]._element.rPr.rFonts.set(qn('w:eastAsia'), font_name)
font_1 = '隶书'
font_setting(font_1)
p_1.add_run('您好,我们诚挚的邀请您参加xxxx 比赛', style=font_1).font.name = 'cambria'
content = p_1.add_run('您好,我们诚挚的邀请您参加xxxx 比赛', style=font_1)
content.font.name = 'calibri'
content.bold = True
# 字的样式补充
# bold:加粗
# italic:倾斜
# color:颜色
# double_strike:双删除线
# strike:删除线
# hidden:隐藏
# shadow:阴影
# underline:下划线
# subscript:下标
# superscript:上标
# all_caps:全部大写字母
content_1 = p_1.add_run('abcde')
# 方式一(部分起作用):
content_1.underline = True
content_1.bold = True
content_1.italic = True
# 方式二(完全没作用):
content_1.style.font.all_caps = True
# 方式三(全部起作用):
content_1.font.all_caps = True
content_1.font.double_strike = True
doc.save('字体样式设置.docx')
02-修改字的位置
from docx import Document
# WD_PARAGRAPH_ALIGNMENT:word文档段落位置
from docx.enum.text import WD_PARAGRAPH_ALIGNMENT
doc = Document()
title = doc.add_heading('一级标题', level=0)
# LEFT/RIGHT/CENTER --> 默认左对齐
title.alignment = WD_PARAGRAPH_ALIGNMENT.CENTER
# 首行缩进,段落行间距等等,也都有对应的操作
content = '周杰伦(Jay Chou),1979年1月18日出生于台湾省新北市,祖籍福建省泉州市永春县,' \
'中国台湾流行乐男歌手、音乐人、演员、导演、编剧,毕业于淡江中学。'
p_1 = doc.add_paragraph(content)
# 首行缩进两个汉字,以厘米为单位,默认一个汉字 0.4 厘米
from docx.shared import Cm, Pt, Inches
# first_line_indent:首行缩进
p_1.paragraph_format.first_line_indent = Cm(0.8)
# 行间距(设置的是两行之间的间距),如果有要求,一般单位都是要求磅
# line_spacing:行间距 -> 1.5磅行间距
p_1.paragraph_format.line_spacing = 1.5
# 段后距离:1.0英寸
p_1.paragraph_format.space_after = Inches(5.0)
doc.save('字的位置.docx')
03-python中修改word的页眉页脚
from docx import Document
# 空白word文档默认只有一页
doc = Document()
# 使用sections参数获取第一页(下标0),使用header参数获取也没,使用footer参数获取页脚
Header = doc.sections[0].header
# 获取页眉的段落内容,add_run从页眉的段落内容中添加信息
Header.paragraphs[0].add_run('这是第一节的页眉')
Footer = doc.sections[0].footer
# 获取页眉的段落内容,add_run从页眉的段落内容中添加信息
Footer.paragraphs[0].add_run('这是第一节的页脚')
"""
页眉页脚,是对当前页起说明作用的,说明这一页属于文章的哪个板块,说明这一页是这个板块的第N页
论文中有摘要,摘要的页脚声明页码,1、2
论文中有正文,页脚申明1、2、3、4、5、6......
"""
# 页眉:居中:页脚中页码右对齐
from docx.enum.text import WD_PARAGRAPH_ALIGNMENT
Header.paragraphs[0].alignment = WD_PARAGRAPH_ALIGNMENT.CENTER
doc.save('页眉页脚.doc')
04-word文档中样式的对照修改
from docx import Document
doc = Document()
t = doc.add_table(rows=2, cols=3, style='LightShading-Accent1')
t_1 = doc.add_table(rows=2, cols=3, style='MediumShading2-Accent1')
p_1 = doc.add_paragraph('这是一个段落', style='ListNumber3')
doc.save('样式修改对照表使用.doc')
参考Create-List-Of-BuiltIn-Styles_DocTools文件
05-邀请信编写
编写一封挑战赛邀请信
1.要求有标题、信件内容、表格、图片
2.要求有央视的修改,标题居中,信件内容隶书(其他字体)、表格样式修改
3.页眉、页脚设置(内容随便)
4.批量生成一些人名的邀请信
5.通过邮件发送(暂不实现)
from docx import Document
from docx.shared import Inches
import datetime
from docx.enum.text import WD_PARAGRAPH_ALIGNMENT
from docx.enum.style import WD_STYLE_TYPE
from docx.oxml.ns import qn
def creat_word(user):
# 创建一个空白word
doc = Document()
# 编写标题
Title = doc.add_heading('国学达人挑战赛邀请函', level=0)
# 设置大标题居中对齐
Title.alignment = WD_PARAGRAPH_ALIGNMENT.CENTER
content = f'尊敬的{user}:\n 您好,我们诚挚的邀请您参加火星电视台于' \
'9999年99月97日举办的第108届国学达人挑战赛,' \
'地址在火星地核,欢迎您的到来,已为您购置飞往火星的船票,请查收!'
# 设置信件内容段落为隶书
font_name = '隶书'
Font_style = doc.styles.add_style(font_name, WD_STYLE_TYPE.CHARACTER)
Font_style.font.name = font_name
doc.styles[font_name]._element.rPr.rFonts.set(qn('w:eastAsia'), font_name)
# 添加信件内容(段落)
p_1 = doc.add_paragraph()
p_1.add_run(content, style=font_name)
# 添加表格标题
doc.add_heading('赛程安排', level=2)
# 时间安排表格
data_table = doc.add_table(rows=4, cols=2, style='LightGrid')
race_list = [
['时间', '安排'],
['9999-99-97', '开幕仪式'],
['9999-99-98', '对对子'],
['9999-99-99', '闭幕仪式']
]
# enumerate同时拿到列表中元素的下标的元素本身
for Index, Value in enumerate(race_list):
# 向每一行的每个单元格添加元素
data_table.rows[Index].cells[0].text = Value[0]
data_table.rows[Index].cells[1].text = Value[1]
# 添加奖项设置标题
doc.add_heading('奖项设置', level=2)
content = '一等奖一名,火星回地球船票一等座;' \
'二等奖两名,火星回地球船票二等座;' \
'三等奖三名,火星回地球船票无座。'
doc.add_paragraph(content)
# 添加船票图片
doc.add_picture('火星船票.jpg', width=Inches(6))
# 添加署名、日期
name_data = f'姓名:张三\n 日期:{datetime.date.today()}'
name = doc.add_paragraph(name_data)
name.alignment = WD_PARAGRAPH_ALIGNMENT.RIGHT
# 添加页眉(居中)页脚(右对齐)
Header = doc.sections[0].header
Header_p = Header.paragraphs[0]
Header_p.add_run('国学达人挑战赛邀请函')
Header_p.alignment = WD_PARAGRAPH_ALIGNMENT.CENTER
Footer = doc.sections[0].footer
Footer_p = Footer.paragraphs[0]
Footer_p.add_run('第一页')
Footer_p.alignment = WD_PARAGRAPH_ALIGNMENT.RIGHT
# 保存
doc.save(f'国学达人挑战赛邀请函---{user}.doc')
# 拿到人名,一次批量创建邀请函
name_list = ['小明', '小刚', '小红']
for i in name_list:
creat_word(i)
效果实现如下

06-pdf转word
pdf2docx -> pdf转word的模块
安装:pip install pdf2docx
1.pdf2docx使用PyMuPDF从PDF中提取数据,写入word
2.PyMuPDF是里那个一个python操作PDF的模块,PyMuPDF比pypdf稍微强大一些,但是赶不上reportlib
3.并不是所有pdf都能使用pdf2docx转为word
4.有些pdf并没有采用标准的pdf格式、协议等
import os
from pdf2docx import parse
# 一般都是转换所有的pdf页面,首先选择parse
file_list = os.listdir('./')
for i in file_list:
if i[-4:] == '.pdf':
try:
parse(pdf_file=i, docx_file=f'{i[:-4]}.docx')
except Exception as err:
print(err)
print('转换失败')


















 8972
8972

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











