







一.基本信息
题目:《Fusion of statistical importance for feature selection in Deep Neural Network-based Intrusion Detection System》
中文:《基于深度神经网络的入侵检测系统中特征选择的统计重要性融合》
作者:Ankit Thakkar,Ritika Lohiya
DOI号:10.1016/j.inffus.2022.09.026
发表期刊:Information Fusion
发表时间:2023
中科院分区:1区
JCR分区:Q1
影响因子:14.7
引用次数:96
二.论文阅读
1.研究背景
深度学习技术已成为开发IDS的主要方案;
入侵检测数据集的数据特征存在着冗余等问题
2.研究的主要贡献:
A.提出了一种基于特征统计重要度融合的特征选择技术
B.使用DNN来做分类模型
C.使用三个数据集对方法进行评估
D.使用不同的评估标准进行整体性能分析
E.将提出的方法与其他特征选择技术进行比较
3.相关技术的介绍
A.特征选择的介绍:
1.什么是特征选择?
定义:去除不相关和冗余特征以更好地表示数据的选择策略
2.特征选择的本质是什么?
本质:从底层数据集中选择特征,获取有效信息
3.特征选择的结果是什么?
选取出在后序分类过程中贡献更大的特征,也就是选择更有效的特征
4.特征选择技术的类别?
①基于过滤器的特征选择技术
工作原理:基于一个标准去筛选重要特征值,具体来说就是为每个特征计算一个相关性分数,然后保留那些得分高、对模型性能有帮助的特征
②基于包装的特征选择技术
工作原理:将特征选择与后面的具体的分类算法结合起来,根据预设的条件(比如选择 提高模型性能最多的特征组合),最终确定一个特征子集。
简单来说,包裹式特征选择就像是为某个分类模型量身定制一套最适合的特征组合③嵌入式特征选择技术
原理:由学习阶段和特征选择阶段组成,可以在两个阶段分别选择特征5.特征选择与IDS的关系?
将分类系统与特征选择技术相结合,并且侧重于在减少误报率的基础上提高分类
精度,可以提高IDS的性能;换句话说,设计出的IDS系统需要有有效的特征选择技术
B.相关变量的介绍:
1.标准差
表达式:
意义: ❶度量特征与平均值之间的变异或偏差的数量
高的标准差:特征分布在较大的值范围内;
低的标准差:特征值相对于平均值的位置很近
❷标准差代表了特征区分样本的能力
标准差越大,该特征在不同样本中的变化越明显,越反映样本之间的差异。
本实验的选择:标准差大的特征
2.中位数和均值
意义:表示数据分布中偏差的相对大小,平均值和中位数差异越大,说明这个特征的数
据范围和分布越广,特征更重要,适合用来做预测或分类
4.研究过程
1.数据集的说明
采用的数据集是NSL-KDD, UNSW_NB-15, and CIC- IDS-2017
2.数据预处理
❶特征编码
技术:One-Hot独热编码
作用:将分类特征转化为数值特征
❷特征标准化
技术:标准差标准化standard scalar
作用:解决数据在不同维度和数值尺度上的差异问题
3.特征选择
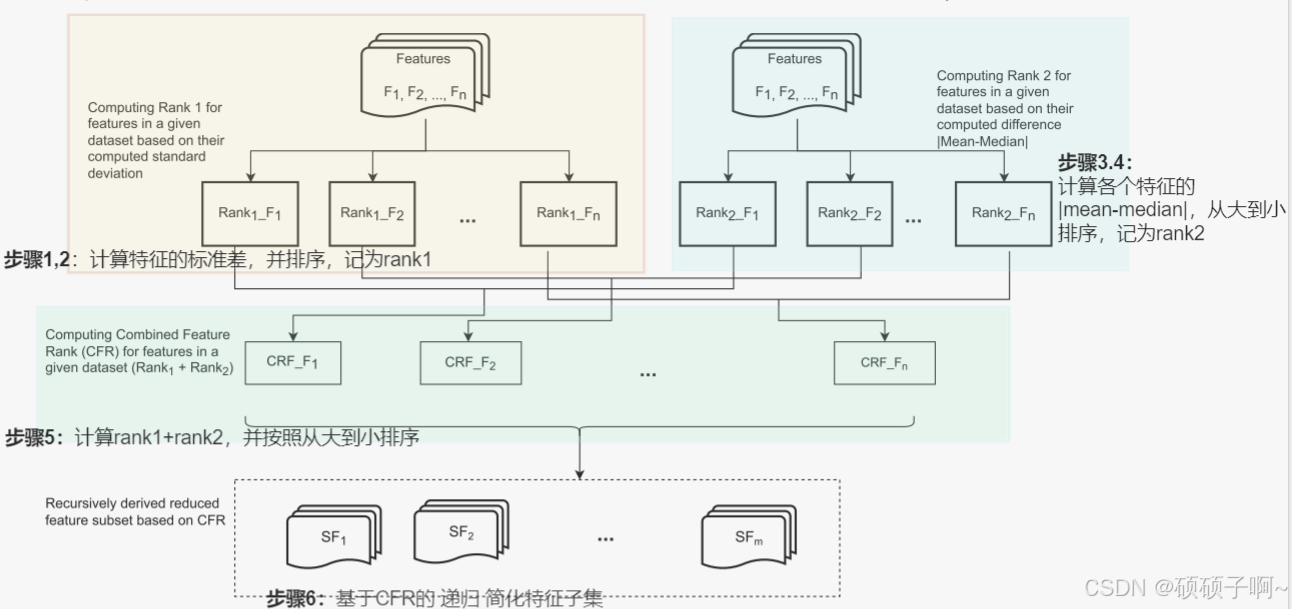
A.特征选择的步骤:
1.计算各个特征的标准差
2.根据标准差将特征从高到低排序,将排名记为rank1
3.计算特征的均值和中位数,得出两个数的绝对差
4.根据绝对差将特征从高到低排名,记为rank2
5.计算特征的组合特征排名=rank1+rank2
6.根据组合特征排名筛选有效的特征数据,具体保留多少个有效特征看其准确性,如果后续再添加特征后准确性不优于先前,那么停止添加特征
B.过程图:
C. 三个数据集特征选择后的结果

4.分类识别
分类模型:DNN
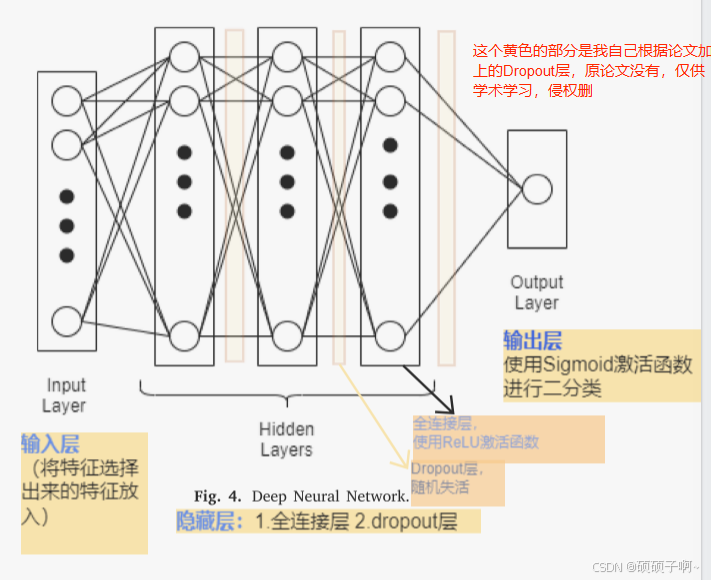
模型结构:
输入层:将特征选择中选择出来的特征作为输入
隐藏层:1.全连接层,使用ReLU激活函数; 2.Dropout层,随机失活神经元,减少过拟合
输出层:使用Sigmoid函数进行二分类
模型结构示意图:
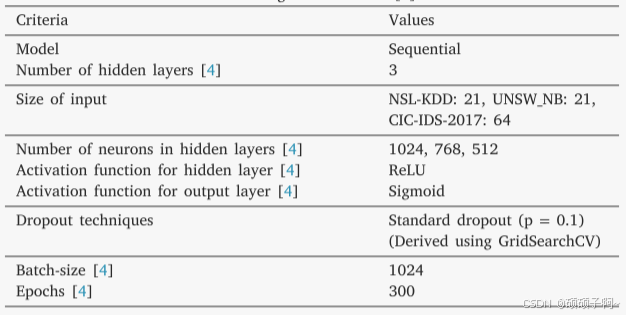
参数配置:
5.整个研究过程图示
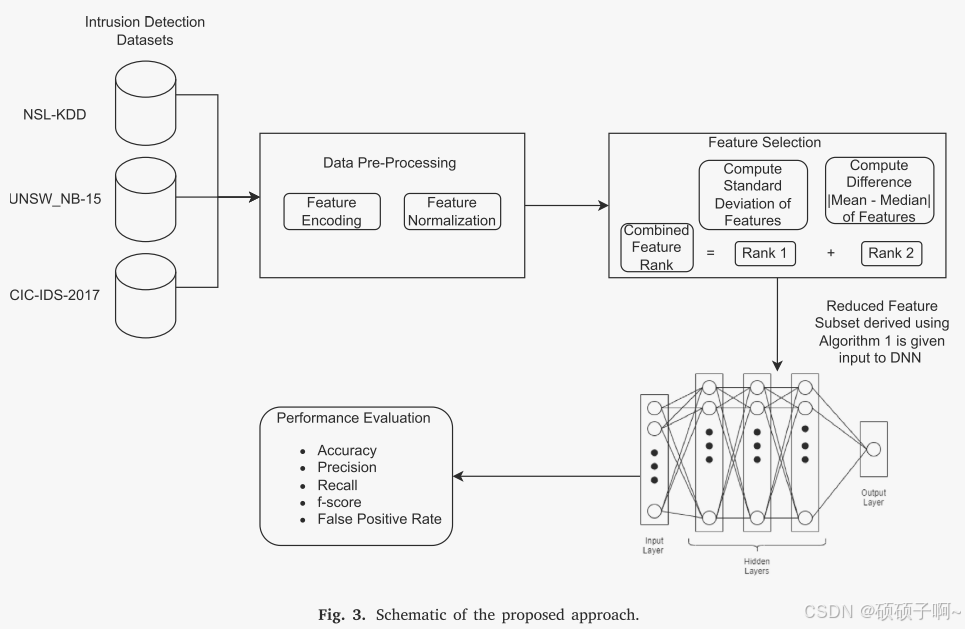
5.评估标准

6.研究结果
A.现有特征选择 VS 所提出的特征选择:
1.原有技术介绍:
·RFE递归特征消除:递归消除贡献度低的特征
·卡方检验 Chi-Square:通过计算特征与目标变量(标签)的卡方来确定特征对结果的影响程度(本质是计算两个变量的依赖性)
·基于关联的特征选择CFS:核心思想是通过分析特征与目标变量(标签)之间的相关性以及特征间的相关性,从而筛选出一个高效的特征子集。
·遗传算法 GA:随机生成子集——>计算适应度——>保留“最有基因”——>杂交——>变异——>迭代
·互信息 MI:通过估计特征与目标值的相关性来进行特征选择
·Relief-f:它通过最近邻样本的特征差异计算特征分数,再根据分数排序选择最优特征子集
·随机森林RF:随机森林的特征选择机制基于特征对 Gini 指数的影响,能够在模型训练过程中自动评估特征的重要性。
2.所提出的技术:
新的基于过滤器的特征选择技术/基于特征统计重要度融合的特征选择技术
3.结果:
结果:在三个数据集上,基于本文提出的特征选择的DNN模型比基于其他原有技术的特征选择方法的模型的效果好
具体分析:
1.准确度:
在NSL-KDD数据集上,本文方法准确度:99.84%,高出现有技术的1%-18%。
在UNSW NB15数据集上,本文方法的准确度为89.03%,高出原有的7%-17%在CICIDS-2017数据集上,本文方法的准确度为99.80%,高出原有的0.9%-2%
2.精确度和召回率
NSL-KDD dataset:
精确度:99.94%,提高了0.04%-18%;
召回率:98.81%,提高了0.06%-7%
UNSW NB15 dataset:
精确度:95%,提高了3%-28%;
召回率:98.95%,提高了0.09%-9%
CIC-IDS-2017 dataset:精确度:99.85%,提高了0.05-2%;
召回率:99.94%,提高了0.67%-2%
3.F1分数
NSL-KDD dataset: 99.37%,提高了0.07%-10%
UNSW NB-15 dataset: 96.93%,提高了3%-17%
CIC-IDS-2017 database: 99.89%,提高了0.59%-2%
4.假阳性率
本研究的假阳性率最低
5.执行时间
本研究保留的特征最多,执行时间却最少
具体数据表:
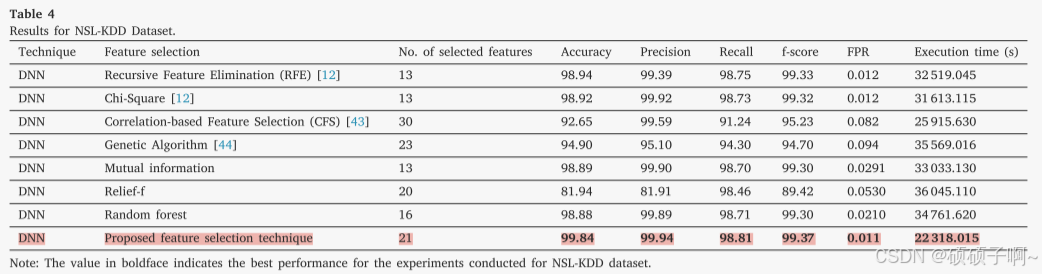
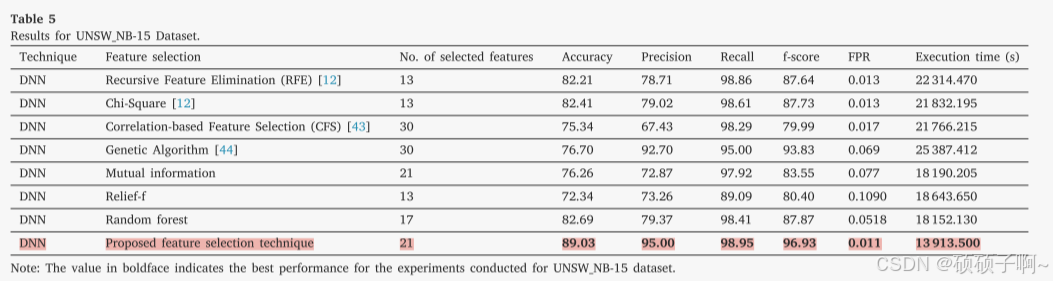
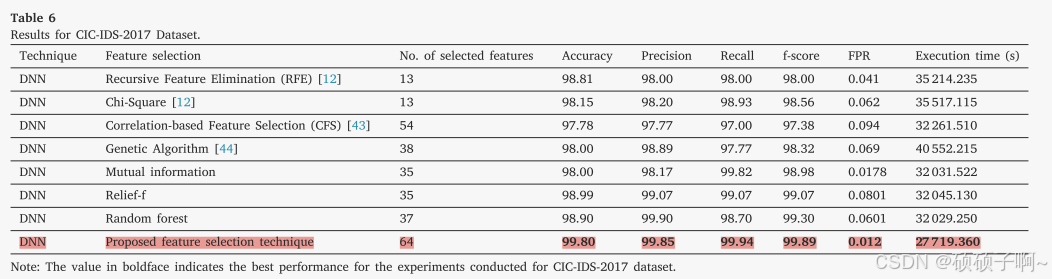
B.将本研究的整个模型与现有模型的对比
·与机器学习模型相比,深度学习的模型表现较好
·与其他深度学习模型相比:
1.在NSL-KDD数据集上:
与《Unified Deep Learning approach for Efficient Intrusion Detection System using Integrated Spatial–Temporal Features 》中的深度学习模型OCNN-HMLSTM相比,本文的模型在NSL-KDD数据集上的准确性提高了9%,假阳性率下降了7%;
与《Hybrid Intrusion Detection using MapReduce based Black Widow Optimized Convolutional Long Short-Term Memory Neural Networks》中的深度学习模型LSTM(Conv-LSTM)相比,本文的模型在NSL-KDD数据集上的准确度提高了1%,假阳性率下降了6%
2.在UNSW_NB-15数据集上:
上述两篇文章的模型在准确性、精度、召回率和𝑓-score等各种性能指标方面表现更好,但是本研究方法在假阳性率方面表现更好;
原因:UNSW_NB-15数据集包含大量异常值和偏斜数据
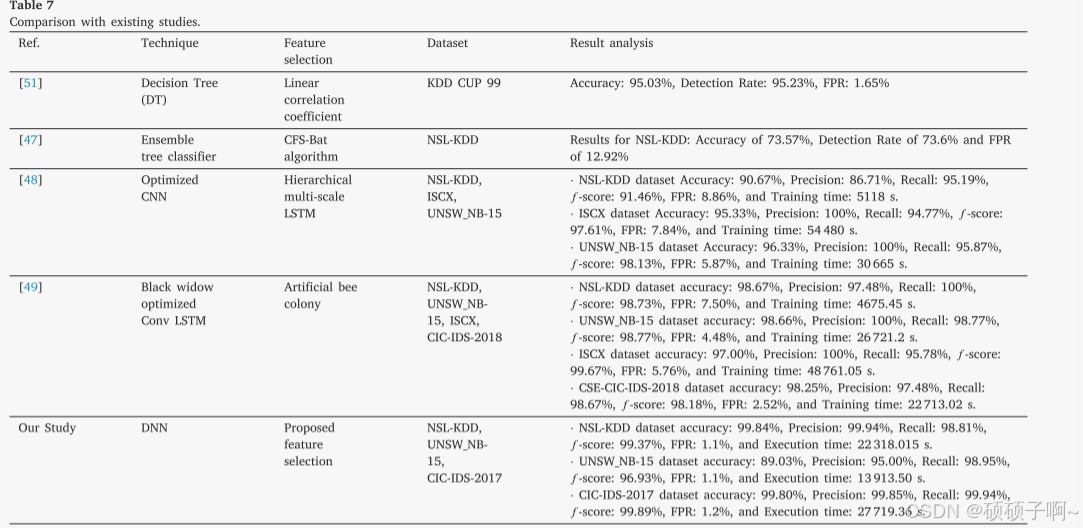
C.算法时间复杂度分析
计算标准差、均值、中位数、联合rank的时间复杂度为
递归从特征子集中消除特征的时间复杂度为
总体时间复杂度为

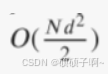
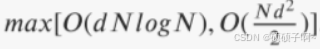
D.能源消耗分析
与其他现有的用于比较分析的特征选择技术相比,所提出的方法消耗的能量更少
E.统计意义及讨论
统计显著性验证:实验中所有数据集的p值均小于0.05,说明实验结果在统计上是显著的
特征选择方法的讨论:本研究的方法忽略了特征之间的潜在相关性。

7.未来展望
·优化神经网络架构以提升入侵检测系统的性能
·改进特征选择技术以提高特征子集的质量
·当前的特征选择技术在考虑特征独立性方面存在不足,忽视了特征间的相关性。未来可以采用多特征联合排序技术,结合特征之间的相关性和单特征的重要性,从而选择出更优的特征子集,
8.总结
该研究提出的基于标准差和均值与中位数之差融合统计重要度的特征选择方法,可以有效减少特征冗余,提升分类性能,并显著提高基于DNN的入侵检测系统中的效率。
9.思维导图
通俗易懂的说这个文章讲的是啥:
对于入侵检测,作者优化的不是分类器,他们改善的是特征选择那里,
到底是怎么做的呢?
他们用的是一个“新的”基于过滤器的特征选择技术,
首先,什么叫基于过滤器的特征选择?
就是选择特征的思路是基于一个标准,给每个特征打分,筛选出分数比较高的特征
其次,作者的新的...是咋回事呢?
作者的原理是先算每个特征的标准差,然后排序,记为rank1,再算每个特征的平均值与中位数的绝对差,排序,记为rank2;然后rank=rank1+rank2,根据rank的排名来筛选特征。
最后,为什么这个方法就能筛选出好的特征呢?
1.标准差反映了特征数据的离散程度。高标准差的特征说明其值在数据样本中分布范围较大,表明该特征具有更好的辨识能力,有助于分类器区分不同类别
2.均值与中位数的绝对差值(|Mean - Median|)可以揭示数据分布的非对称性或偏斜程度(就是数据是否偏向于某一侧,或是否存在极端值,数据分布越对称,那么偏斜值越小)。较大的偏斜值通常表明该特征有较强的差异性。这种差异性能够使分类模型更容易区分不同类别,从而增强分类性能。(举个例子,比如说A特征,样本一-A是0.01,对于样本二-A是100,那么这个A特征就可以很好区分出样本1和样本2;但是如果样本一-A是0.010,样本二-A是0.012,如果两个样本属于异类,那么就很难分辨出1和2)
3.递归优化特征子集:作者通过递归地计算综合排名,不断添加特征到特征子集中,并以模型的性能提升为依据,确保最终选择的特征集是对分类任务最有贡献的子集
!!!声明!!!
这篇文章仅用于本人的学术学习,侵权即删,转载或学习请标明原论文的信息,正确引用!

















 2141
2141

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









