







参考视频链接:尚硅谷MySQL数据库高级,mysql优化,数据库优化(尚硅谷MySQL数据库高级,mysql优化,数据库优化_哔哩哔哩_bilibili)
参考笔记链接:(https://blog.csdn.net/oneby1314/category_10278969.html)
目录
一、Mysql的架构介绍
mysql是一个关系型数据库
端口:3306
配置文件:①二进制日志log-bin:主从复制;②错误日志log-error;③查询日志log。
数据文件:①frm文件-存放表结构;②myd文件-存放表数据;③mui文件-存放表索引。
二、索引优化分析
1、sql解析:
(机读从FROM开始读)
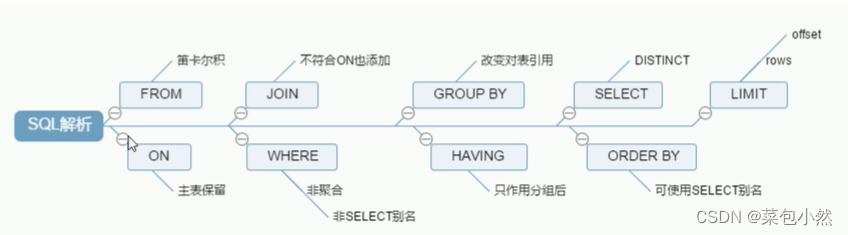
2、7种join图:
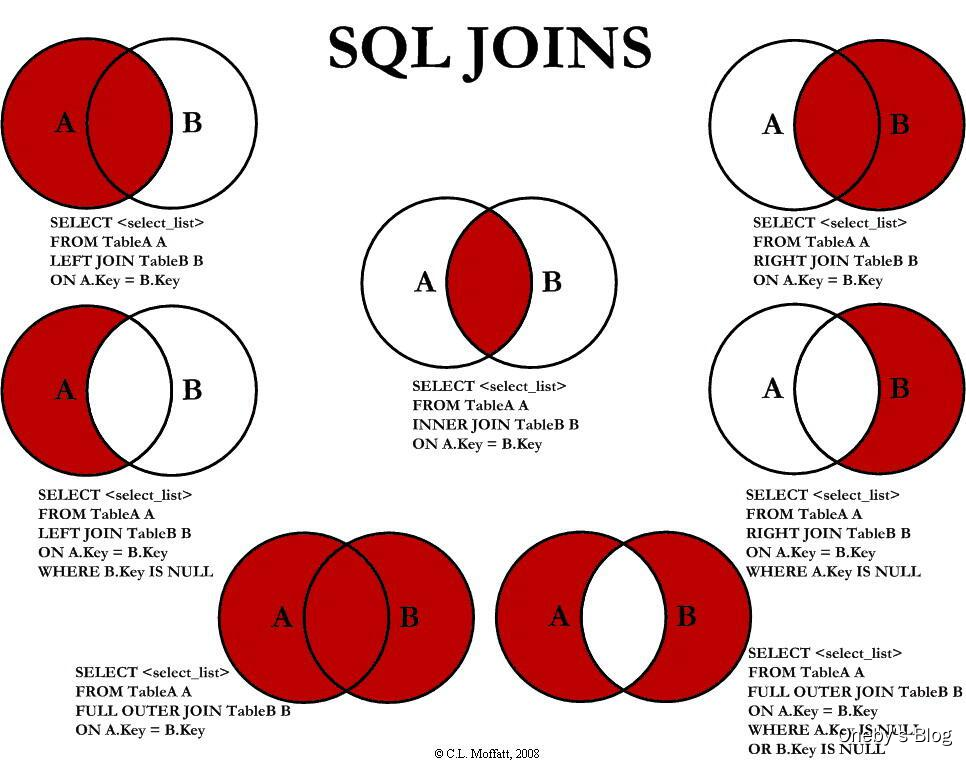
union:”+“
3、索引:
1.索引简介:
索引(Index)是帮助MqSQL高效获取数据的数据结构,可以理解为排好序的快速查找数据结构。
(1)索引的优势与劣势:
优势:①提高数据检索的效率;②降低数据排序的成本。
劣势:①索引列也是要占用空间的;②会降低更新表的速度;③要花时间研究建立最优索引,不断优化。
(2)sql索引的分类:
①单值索引:一个索引只包含单个列,一个表可以有多个单列索引。
②唯一索引:索引列的值必须唯一,但允许有空值。例:主键。
③复合索引:一个索引包含多个列。
基本语法:
创建:【1】CREATE [UNIQUE] INDEX indexName ON mytable(columname(length));
【2】ALTER mytable ADD [UNIQUE] INDEX [indexName] ON (columnaame(length))
删除:DROP INDEX [indexName] ON mytable;
查看:SHOW INDEX FROM table_name\G
(3)sql索引结构:
①BTree索引;②Hash索引;③ full-text全文索引;④R-Tree索引。
(4)哪些情况要建索引?
主键自动建立唯一索引;
频繁作为查询条件的字段;
查询中与其他表关联的字段,外键关系应该建立索引;
查询中排序的字段,排序字段若同通过索引去访问将大大提高排序速度;
高并发情况下,倾向于建立索引;
查询中统计或者分组字段。
(5)哪些情况不适合建索引?
频繁更新的字段;
Where条件中用不到的字段;
表记录太少;
数据重复且分布平均的表字段。
2.性能分析:
(1)MySql Query Optimizer:Mysql中专门负责优化SELECT语句的优化模块。
(2)MySQL常见瓶颈:
CPU负担重:CPU在饱和的时候 一般发生在数据装入内存或从磁盘上读取数据的时候。
IO负担重:磁盘I/O瓶颈发生在装入数据远大于内存容量的时候。
服务器硬件的性能瓶颈:top,free,iostat,vmstat来查看系统的性能状态。
(3)Explain:
是什么?
使用EXPLAIN关键字可以模拟优化器执行SQL语句,从而知道MySQL是如何处理你的SQL语句的。分析查询语句或结构的性能瓶颈。
官网地址:MySQL :: MySQL 8.0 Reference Manual :: 8.8.2 EXPLAIN Output Format
能干啥?
-
表的读取顺序(id 字段)
-
数据读取操作的操作类型(select_type 字段)
type 从最好到最差依次是:system>const>eq_ref>ref>range>index>All,一般来说至少要达到
-
哪些索引可以使用(possible_keys 字段)
-
哪些索引被实际使用(keys 字段)
-
表之间的引用(ref 字段)
-
每张表有多少行被优化器查询(rows 字段)
Extra:
Using filesort:“文件排序”。(九死一生)
Using temporary:临时表,常见于排序order by和分组查询group by。(十死无生)
Using index:(非常好,效率不错!)
怎么玩?
-
Explain + SQL语句
练习题:

3.索引优化:
(1)【全值匹配我最爱】 (2)最佳左前缀法则:【带头大哥不能死,中间兄弟不能断】 (3)不在索引列上做任何操作 ( 计算、函数、(自动or手动) 类型转换),会导致索引失效而转向全表扫描【索引列上不计算】 (4)存储引擎不能使用索引中范围条件右边的列【范围之后全失效】 (5)尽量使用覆盖索引(只访问索引的查询(索引列和查询列一致)),减少select 【覆盖索引不写*】 (6)字符串不加单引号索引失效【字符串要加引号】 (7)like以通配符开头(’%abc…’)mysql索引失效会变成全表扫描操作【like百分加右边】 (8)“mysql在使用不等于(!=或者<>)的时候无法使用索引会导致全表扫描 (9)is null,is not null 也无法使用索引(早期版本不能走索引,后续版本应该优化过,可以走索引) (10)少用or,用它连接时会索引失效【注意不等、空值、OR】
三、查询截取分析
1 、查询优化:
(1)优化原则:RBO原理:” 小表驱动大表“,即小的数据集驱动大的数据集。
SELECT ... FROM table WHERE EXISTS (subquery)
【将主查询的数据 放到子查询中做条件验证,根据验证结果(TURE或FALSE)来做决定 主查询的数据是否得以保留】
(2)排序优化【order by】:
①order by能使用索引最左前缀(order by默认升序,索引查询必须同升或同降,否则filesort)。
②如果WHERE使用索引的最左前缀定义为常量,则order by能使用索引。
③不能使用索引进行排序。
(3)分组优化【group by】:
①与order by特点相同;
②实质是先排序后分组;
③where高于having。
2、慢查询日志:
运行时间超过long_query_time值的sql,会被记录到慢查询日志中。
!默认情况下,mysql没有开启慢查询日志。
!如果不是调优需要的话,一般不建议启动该参数。
set global slow_query_log = 1;开启慢查询日志
日志分析工具mysqldumpslow:
1. s:是表示按何种方式排序 2. c:访问次数 3. l:锁定时间 4. r:返回记录 5. t:查询时间 6. al:平均锁定时间 7. ar:平均返回记录数 8. at:平均查询时间 9. t:即为返回前面多少条的数据 10. g:后边搭配一个正则匹配模式,大小写不敏感的
3、批量数据脚本:
(1)随机产生字符串的函数:
delimiter $$ # 两个 $$ 表示结束 create function rand_string(n int) returns varchar(255) begin declare chars_str varchar(100) default 'abcdefghijklmnopqrstuvwxyz'; declare return_str varchar(255) default ''; declare i int default 0; while i < n do set return_str = concat(return_str,substring(chars_str,floor(1+rand()*52),1)); set i=i+1; end while; return return_str; end $$
(2)随机产生部门编号的函数:
delimiter $$ create function rand_num() returns int(5) begin declare i int default 0; set i=floor(100+rand()*10); return i; end $$
创建表---设置参数---创建随机函数---创建存储过程---调用存储过程。
4、Show Profile:
Show Profile是mysql提供可以用来分析当前会话中语句执行的资源消耗情况。可以用于SQL的调优测量。(功能更强大)
默认环境下,参数处于关闭状态。
-
set profiling=on;开启 Show Profile
-
show profiles; 指令查看结果
-
show profile cpu, block io for query SQL编号;查看 SQL 语句执行的具体流程以及每个步骤花费的时间
-
参数备注:
ALL:显示所有的开销信息 BLOCK IO:显示块IO相关开销 CONTEXT SWITCHES:上下文切换相关开销 CPU:显示CPU相关开销信息 IPC:显示发送和接收相关开销信息 MEMORY:显示内存相关开销信息 PAGE FAULTS:显示页面错误相关开销信息 SOURCE:显示和Source_function,Source_file,Source_line相关的开销信息 SWAPS:显示交换次数相关开销的信息
-
日常开发需要注意的结论
converting HEAP to MyISAM:查询结果太大,内存都不够用了往磁盘上搬了。 Creating tmp table:创建临时表,mysql 先将拷贝数据到临时表,然后用完再将临时表删除 Copying to tmp table on disk:把内存中临时表复制到磁盘,危险!!! locked:锁表
5、全局查询日志:
只允许在测试环境用,不允许在生产环境用!
四、Mysql锁机制
1、表锁(读锁、写锁):
读写锁的区别:
读锁 会 阻塞写,但是不会阻塞读,而 写锁 会把 读和写 都阻塞。
添加锁:
lock table 表名1 read(write), 表名2 read(write), ...;
释放锁:
unlock tables;
MyISAM在执行查询语句(SELECT)前,会自动给涉及的所有表加读锁,在执行增删改操作前,会自动给涉及的表加写锁。 MySQL的表级锁有两种模式: 表共享读锁(Table Read Lock) 表独占写锁(Table Write Lock)
结论:
结合上表,所以对MyISAM表进行操作,会有以下情况:
对MyISAM表的读操作(加读锁),不会阻塞其他进程对同一表的读请求,但会阻塞对同一表的写请求。只有当读锁释放后,才会执行其它进程的写操作。 对MyISAM表的写操作(加写锁),会阻塞其他进程对同一表的读和写操作,只有当写锁释放后,才会执行其它进程的读写操作
2、行锁:
(1)行锁支持事务:Transaction和ACID属性。
①ACID属性:原子性、一致性、隔离性、持久性。
②并发事务处理带来的问题:更新丢失(更新覆盖)、脏读(A读到了B已修改但尚未提交的数据)、不可重复读(A读到了B已提交的修改数据)、幻读(A读到了B提交的新增数据)。
③事务的隔离级别: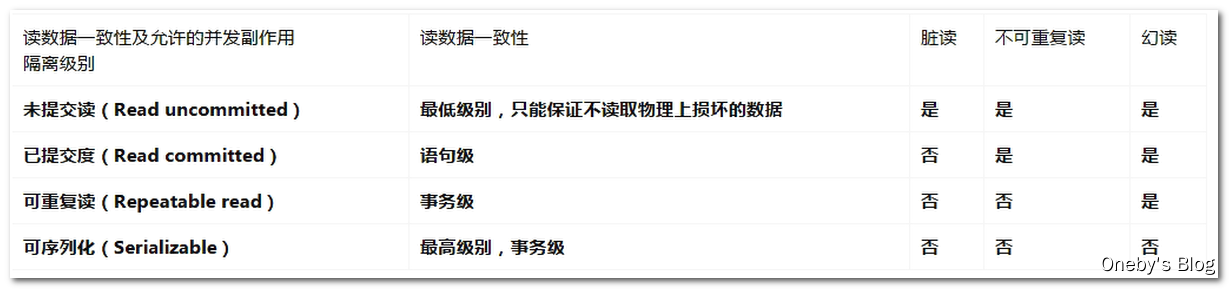
(2)结论:
①间隙锁:当使用范围条件而不是相等条件检索数据,并请求共享或排他锁时,InnoDB会给符合条件的已有数据记录的索引项加锁;对于键值在条件范围内但并不存在的记录,叫做“间隙(GAP)”。间隙锁的危害:因为Query执行过程中通过范围查找的话,他会锁定整个范围内所有的索引键值,即使这个键值并不存在。
②手动行锁:select xxx ... for update 锁定某一行,其他的操作会被阻塞,直到锁定行的会话提交commit。
③通过检查InnoDB_row_lock状态变量来分析系统上的行锁的争夺情况,(比较重要的几个状态变量):
-
Innodb_row_lock_time_avg(等待平均时长)
-
Innodb_row_lock_waits(等待总次数)
-
Innodb_row_lock_time(等待总时长)
④行锁优化:
-
尽可能让所有数据检索都通过索引来完成,避免无索引行锁升级为表锁
-
合理设计索引,尽量缩小锁的范围
-
尽可能较少检索条件,避免间隙锁
-
尽量控制事务大小,减少锁定资源量和时间长度
-
尽可能低级别事务隔离
3、页锁:
-
开销和加锁时间界于表锁和行锁之间:会出现死锁;
-
锁定粒度界于表锁和行锁之间,并发度一般。
-
了解即可
五、主从复制
1、复制的基本原理
slave会从master读取binlog来进行数据同步,主从复制的三步骤:
①master将改变记录到二进制日志(binary log),这些记录过程叫做二进制日志事件(binary log events); ②slave将master的binary log events拷贝到它的中继日志(relay log); ③slave重做中继日志中的事件,将改变应用到自己的数据库中。MySQL复制是异步的且串行化的。

2、复制的基本原则
-
每个slave只有一个master
-
每个slave只能有一个唯一的服务器ID
-
每个master可以有多个salve
3、复制最大问题
因为发生多次 IO, 存在延时问题。
4、一主一从常见配置:
(1)ping测试:mysql版本一致,主从机在同一网段下;并且后台以服务运行。
(2)主机修改my.ini配置文件:
①【必须配】主服务器唯一ID:server-id=1
②【必须配】启用二进制日志:log-bin=自己本地的路径/musqlbin
③【可选】启用错误日志:log-err=自己本地的路径/mysqlerr
④【可选】根目录:basedir=“自己本地路径”
⑤【可选】临时目录:tmpdir=“自己本地路径”
⑥【可选】数据目录:datadir=“自己本地路径/Data/”
⑦read-only=0
⑧【可选】设置不要复制的数据库:binlog-ignore-db=mysql
⑨【可选】设置需要复制的数据库:binlog-do-db=需要复制的主数据库的名字
(3)从机修改my,cnf配置文件:
①【必须配】从服务器唯一ID:server-id=2
②【可选】启用二进制日志(建议打开)
(4)(因修改过配置文件)主机+从机重新启动mysql服务。
(5)主机+从机关闭防火墙。
(6)在Windows主机上建立账户并授权slave:
GRANT REPLICATION SLAVE ON *.* TO '备份账号'@'从机器数据库 IP' IDENTIFIED BY '账号密码'; flush privileges; //刷新 show master status; //查询master的状态
记录下File和Position的值。
(7)在Linux从机上配置需要复制的主机。
GRANT REPLICATION SLAVE ON *.* TO '备份账号'@'主机器数据库 IP' IDENTIFIED BY '账号密码', MASTER_LOG_FILE="名字",MASTER_LOG_POS=Position数字; start slave; //开启复制 show slave status //查询状态
如果Slave_IO_Running、Slave_SQL_Running都是yes,证明主从配置成功!
(8)主机新建新建表、insert记录;从机复制。
(9)停止从服务复制功能:stop slave;
六、MVCC机制
参考文档:
-
undo log版本链与ReadView机制如何让事务读取到该读的数据?一文搞懂undo log版本链与ReadView机制如何让事务读取到该读的数据
-
MySQL 中是如何通过 MVCC 机制来解决不可重复读和幻读问题的?在 MySQL 中是如何通过 MVCC 机制来解决不可重复读和幻读问题的?
-
在读提交的事务隔离级别下,MVCC 机制是如何工作的?在读提交的事务隔离级别下,MVCC 机制是如何工作的?
问题一:undo log版本链与ReadView机制 如何 让事务读取到该读的数据?
1、undo log版本链
row_rex_id:更新本行数据的事务id。
roll_pointer:回滚指针,指向该行数据上一个版本的undo log。
啥是undo log版本链?
只要有事务修改了这一行的数据,就会记录一条对应的 undo log,一条 undo log 对应这行数据的一个版本,当这行数据有多个版本时,就会有多条 undo log 日志,undo log 之间通过 roll_pointer 指针连接,这样就形成了一个 undo log 版本链。
2、ReadView机制
在当前事务期间内,出现多次查询时,都不会重新创建 ReadView 视图
在读提交隔离级别下,在事务范围内,则会在每次查询前,都会重新创建 ReadView 视图
creator_trx_id:当前事务的id。
m_ids:当前系统中所有活跃事务的id。(活跃事务是指当前系统中 开启了但还没提交的事务)
min_trx_id:当前系统中 所有活跃事务中id最小的那个事务。
max_trx_id:当前系统中 id最大的事务+1,即系统中下一个要生成的事务。
ReadView是嘎哈的?
ReadView根据这四个属性,结合undo log版本链,实现MVCC机制,来决定让一个事务能读取哪些数据,不能读取哪些数据。
ReadView咋实现的?,规则:
如果当前数据的 row_trx_id < min_trx_id,那么表示这条数据是在当前事务开启之前,其他的事务就已经将该条数据修改了并提交了事务(事务的 id 值是递增的),所以当前事务能读取到。
如果当前数据的 row_trx_id ≥ max_trx_id,那么表示在当前事务开启以后,过了一段时间,系统中有新的事务开启了,并且新的事务修改了这行数据的值并提交了事务,所以当前事务肯定是不能读取到的,因此这是后面的事务修改提交的数据。
如果当前数据的 row_trx_id 处于 min_trx_id 和 max_trx_id 的范围之间,又需要分两种情况:
(a)row_trx_id 在 m_ids 数组中,那么当前事务不能读取到。为什么呢?row_trx_id 在 m_ids 数组中表示的是和当前事务在同一时刻开启的事务,修改了数据的值,并提交了事务,所以不能让当前事务读取到;
(b) row_trx_id 不在 m_ids 数组中(在读提交的事务隔离级别下,会出现这种现象),那么当前事务能读取到。row_trx_id 不在 m_ids 数组中表示的是在当前事务开启之前,其他事务将数据修改后就已经提交了事务,所以当前事务能读取到。
问题二:通过 MVCC 机制 解决 不可重复读、幻读问题?
MVCC(Mutil-Version Concurrent Control(多版本并发控制)),指 数据库中的每一条数据,会存在多个版本。对同一条数据而言,MySQL 会通过一定的手段(ReadView 机制)控制每一个事务看到不同版本的数据,这样也就解决了不可重复读的问题。
(1)不可重复读:在一个事务内,连续两次查询同一条数据,查到的结果前后不一样。
(2)幻读:后面查询比前面查询的记录条数多,看到了前面没看到的数据,就像产生幻觉一样。
快照读:基于事务开启时生成的ReadView来读取事务。
当前读:读取最新的数据。(例如在select语句后加上for updata【排他锁】或者lock in share mode【共享锁】等)
(MVCC机制解决的是快照读的幻读问题,不能解决 当前读的幻读问题(间隙锁解决的))
-
在可重复读隔离级别下,如果事务只是进行查询操作,那么就只会在第一次查询的时候生成 ReadView 快照
问题三:在读提交的事务隔离级别下,MVCC机制是如何工作的?
脏读:一个事物读到了另一个事务未提交的数据。
在读提交隔离级别下,不存在脏读问题。【因为ReadView机制】
在读提交隔离级别下,存在不可重复读的问题。【因为在读提交隔离级别下,在一个事务内,每次查询,都会重新创建一个新的 ReadView】















 582
582











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









