






1.实现并总结容器跨主机的通信过程:通过host-gw模式实行容器跨主机通信
[root@db02 ~]# vim /lib/systemd/system/docker.service
ExecStart=/usr/bin/dockerd -H fd:// --containerd=/run/containerd/containerd.sock --bip=10.10.0.1/24
[root@db02 ~]# systemctl daemon-reload && systemctl restart docker宿主机192.168.220.53
[root@db03 ~]# vim /lib/systemd/system/docker.service
ExecStart=/usr/bin/dockerd -H fd:// --containerd=/run/containerd/containerd.sock --bip=10.20.0.1/24
[root@db03 ~]# systemctl daemon-reload && systemctl restart docker在宿主机添加静态路由,将去往的目的容器网关(下一跳)指向目的容器所在的宿主机eth0网卡:
宿主机192.168.220.52
[root@db02 ~]# route add -net 10.20.0.0/24 gw 192.168.220.53
[root@db02 ~]# route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
10.20.0.0 192.168.220.53 255.255.255.0 UG 0 0 0 eth0
[root@db02 ~]# iptables -A FORWARD -s 192.168.220.0/24 -j ACCEPT #允许响应报文的转发
[root@db02 ~]# iptables -vnL
Chain FORWARD (policy DROP 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
0 0 ACCEPT all -- * * 192.168.220.0/24 0.0.0.0/0 宿主机192.168.220.53
[root@db03 ~]# route add -net 10.10.0.0/24 gw 192.168.220.52
[root@db03 ~]# iptables -A FORWARD -s 192.168.220.0/24 -j ACCEPT #允许响应报文的转发运行容器并测试容器间通信
宿主机192.168.220.52
[root@db02 ~]# docker run -d alpine sh
3857f488f20737faf5e0ef0416f0f8a7638e1e1f757daaaf82fb8100d728e955
[root@db02 ~]# docker exec -it 3857f488f20737f sh
/ # ip a
21: eth0@if22: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1500 qdisc noqueue state UP
link/ether 02:42:0a:0a:00:02 brd ff:ff:ff:ff:ff:ff
inet 10.10.0.2/24 brd 10.10.0.255 scope global eth0
valid_lft forever preferred_lft forever
/ # ping 10.20.0.2
PING 10.20.0.2 (10.20.0.2): 56 data bytes
64 bytes from 10.20.0.2: seq=0 ttl=62 time=0.338 ms
64 bytes from 10.20.0.2: seq=1 ttl=62 time=0.224 ms
64 bytes from 10.20.0.2: seq=2 ttl=62 time=0.230 ms
64 bytes from 10.20.0.2: seq=3 ttl=62 time=0.235 ms
^C
--- 10.20.0.2 ping statistics ---
4 packets transmitted, 4 packets received, 0% packet loss
round-trip min/avg/max = 0.224/0.256/0.338 ms宿主机192.168.220.53
[root@db03 ~]# docker run -d alpine sh
4462e4a836ec16e101766a4e33407ada834eda8dae6b883f7e63c69333cc7533
[root@db03 ~]# docker exec -it 4462e4a836e sh
/ # ip a
7: eth0@if8: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1500 qdisc noqueue state UP
link/ether 02:42:0a:14:00:02 brd ff:ff:ff:ff:ff:ff
inet 10.20.0.2/24 brd 10.20.0.255 scope global eth0
valid_lft forever preferred_lft forever
/ # ping 10.10.0.2
PING 10.10.0.2 (10.10.0.2): 56 data bytes
64 bytes from 10.10.0.2: seq=0 ttl=62 time=3.062 ms
64 bytes from 10.10.0.2: seq=1 ttl=62 time=0.230 ms
64 bytes from 10.10.0.2: seq=2 ttl=62 time=0.291 ms
64 bytes from 10.10.0.2: seq=3 ttl=62 time=0.267 ms
^C
--- 10.10.0.2 ping statistics ---
4 packets transmitted, 4 packets received, 0% packet loss
round-trip min/avg/max = 0.230/0.962/3.062 mshost-gw模式原理在于宿主机充当路由

host-gw 模式的工作原理: 将每个 Flannel 子网(Flannel Subnet,比如:10.20.0.1/24)的“下一跳”,设置成了该子网对应的宿主机的 IP 地址。也就是说,这台“主机”(Host)会充当这条容器通信路径里的“网关”(Gateway)。这也正是“host-gw”的含义。
步骤1:宿主机Node1上新建一条路由规则
flanneld 会在宿主机上创建一条路由规则,以 Node 1 为例:
$ ip route
...
10.244.1.0/24 via 10.168.0.3 dev eth0
这条路由规则的含义是:目的 IP 地址属于 10.244.1.0/24 网段的 IP 包,应该经过本机的 eth0 设备发出去(即:dev eth0);并且,它下一跳地址(next-hop)是 10.168.0.3(即:via 10.168.0.3)。所谓下一跳地址就是:如果 IP 包从主机 A 发到主机 B,需要经过路由设备 X 的中转。那么 X 的 IP 地址就应该配置为主机 A 的下一跳地址。而从 host-gw 示意图中我们可以看到,这个下一跳地址对应的,正是我们的目的宿主机 Node 2。
步骤2:宿主机Node1将目的IP转为目的MAC
一旦配置了下一跳地址,那么接下来,**当 IP 包从网络层进入链路层封装成帧的时候,eth0 设备就会使用下一跳地址对应的 MAC 地址,作为该数据帧的目的 MAC 地址。显然,这个 MAC 地址,正是 Node 2 的 MAC 地址。**这样,这个数据帧就会从 Node 1 通过宿主机的二层网络顺利到达 Node 2 上。
步骤3:宿主机Node2从收到的请求中取出IP包
Node 2 的内核网络栈从二层数据帧里拿到 IP 包后,会“看到”这个 IP 包的目的 IP 地址是 10.244.1.3,即 Infra-container-2 的 IP 地址。这时候,根据 Node 2 上的路由表,该目的地址会匹配到第二条路由规则(也就是 10.244.1.0 对应的路由规则),从而进入 cni0 网桥,进而进入到 Infra-container-2 当中。
2.总结Dockerfile的常见指令
docker pull ubuntu:22.04
mkdir nginx-dockerfilecd nginx-dockerfilevim DockerfileFROM ubuntu:22.04
MAINTAINER "jack 2973707860@qq.com"
ADD sources.list /etc/apt/sources.list
RUN apt update && apt install -y iproute2 ntpdate tcpdump telnet traceroute nfs-kernel-server nfs-common lrzsz tree openssl libssl-dev libpcre3 libpcre3-dev zlib1g-dev ntpdate tcpdump telnet traceroute gcc openssh-server lrzsz tree openssl libssl-dev libpcre3 libpcre3-dev zlib1g-dev ntpdate tcpdump telnet traceroute iotop unzip zip make
ADD nginx-1.22.0.tar.gz /usr/local/src/
RUN cd /usr/local/src/nginx-1.22.0 && ./configure --prefix=/apps/nginx && make && make install && ln -sv /apps/nginx/sbin/nginx /usr/bin
RUN groupadd -g 2088 nginx && useradd -g nginx -s /usr/sbin/nologin -u 2088 nginx && chown -R nginx.nginx /apps/nginx
ADD nginx.conf /apps/nginx/conf/
ADD frontend.tar.gz /apps/nginx/html/
EXPOSE 80 443
#ENTRYPOINT ["nginx"]
CMD ["nginx","-g","daemon off;"]
docker build -t harbor.magedu.net/myserver/nginx:v1 .[root@db02 nginx-dockerfile]# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
harbor.magedu.net/myserver/nginx v1 db67cd822e4f 12 seconds ago 447MB
docker run -d -p 80:80 db67cd822e4f
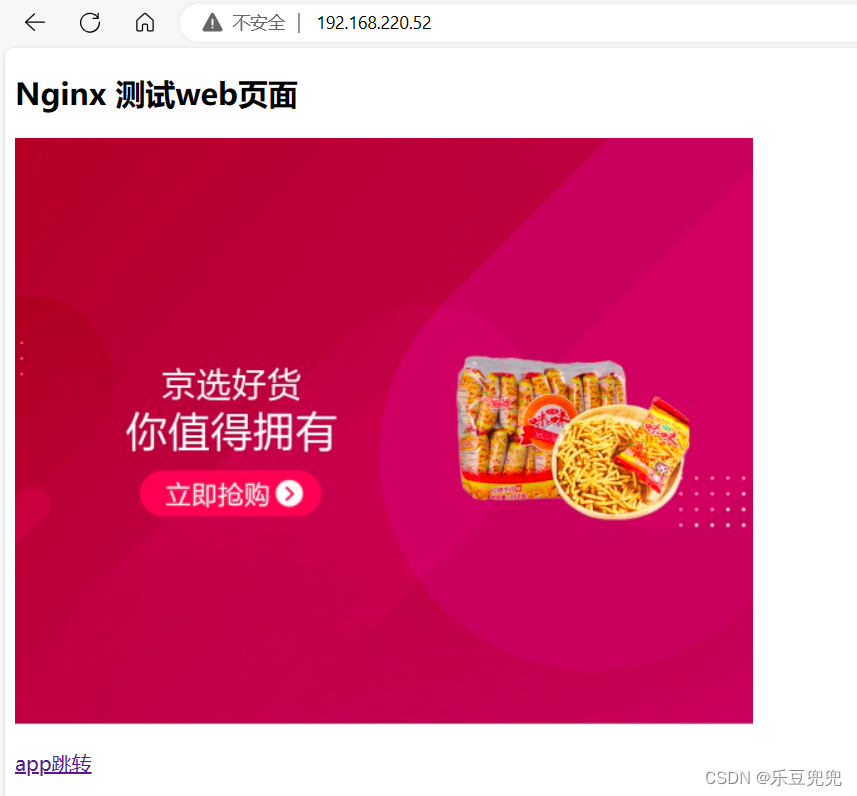
4.部署单机harbor并实现镜像的上传与下载
Harbor 部署的先决条件
Harbor 部署为多个 Docker 容器。因此,您可以将其部署在任何支持 Docker 的 Linux 发行版上。目标主机需要安装 Docker 和 Docker Compose。
硬件
下表列出了用于部署 Harbor 的最低和建议的硬件配置。
| 资源 | 最低 | 推荐 |
|---|---|---|
| 中央处理器 | 2 核 | 4 核 |
| 内存 | 4 GB | 8 GB |
| 磁盘 | 40 GB | 160 GB |
软件
下表列出了必须在目标主机上安装的软件版本。
| 软件 | 版本 | 描述 |
|---|---|---|
| Docker引擎 | 版本 17.06.0-ce+ 或更高版本 | 有关安装说明,请参阅 Docker 引擎文档 |
| docker-compose | docker-compose (v1.18.0+) 或 docker compose v2 (docker-compose-plugin) | 有关安装说明,请参阅 Docker 撰写文档 |
| OpenSSL | 最新者优先 | 用于为 Harbor 生成证书和密钥 |
网络端口
Harbor 要求在目标主机上打开以下端口。
| 港口 | 协议 | 描述 |
|---|---|---|
| 443 | HTTPS | Harbor 门户和核心 API 接受此端口上的 HTTPS 请求。您可以在配置文件中更改此端口。 |
| 4443 | HTTPS | 连接到 Docker Content Trust Service for Harbor。仅当启用了公证时才需要。您可以在配置文件中更改此端口。 |
| 80 | HTTP | Harbor 门户和核心 API 接受此端口上的 HTTP 请求。您可以在配置文件中更改此端口。 |
下载并上传安装包后解压安装包
[root@hadoop100 ~]# cd /opt/software/
[root@hadoop100 software]# rz -E
rz waiting to receive.
[root@hadoop100 software]# tar xf harbor-offline-installer-v2.8.2.tgz
打开Harbor配置文件修改域名,关闭https
[root@hadoop100 software]# cd harbor/
[root@hadoop100 harbor]# cp harbor.yml.tmpl harbor.yml
[root@hadoop100 harbor]# vim harbor.ymlhostname: www.mydomain.com
# https related config
#https:
# https port for harbor, default is 443
#port: 443
# The path of cert and key files for nginx
#certificate: /your/certificate/path
#private_key: /your/private/key/path
配置域名解析
[root@hadoop100 harbor]# vim /etc/hosts
192.168.220.100 www.mydomain.com
执行安装脚本
[root@hadoop100 harbor]# ./install.sh --with-trivy #启用镜像安全扫描
在镜像上传主机配置仓库地址和域名解析
[root@db02 ~]# vim /etc/docker/daemon.json
{
"insecure-registries": ["www.mydomain.com"]
}[root@db02 ~]# systemctl restart docker
[root@db02 ~]# vim /etc/hosts
92.168.220.100 www.mydomain.com
给需要上传的镜像打标签
[root@db02 ~]# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
harbor.magedu.net/myserver/nginx v1 db67cd822e4f 6 hours ago 447MB[root@db02 ~]# docker tag harbor.magedu.net/myserver/nginx:v1 www.mydomain.com/myserver/nginx:v1
[root@db02 ~]# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
harbor.magedu.net/myserver/nginx v1 db67cd822e4f 6 hours ago 447MB
www.mydomain.com/myserver/nginx v1 db67cd822e4f 6 hours ago 447MB
登录并上传镜像
[root@db02 ~]# docker login www.mydomain.com
[root@db02 ~]# docker push www.mydomain.com/myserver/nginx:v1
在另一台主机下载镜像
[root@db03 ~]# vim /etc/hosts
[root@db03 ~]# vim /etc/docker/daemon.json
[root@db03 ~]# systemctl restart docker
[root@db03 ~]# docker pull www.mydomain.com/myserver/nginx:v1[root@db03 ~]# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
www.mydomain.com/myserver/nginx v1 db67cd822e4f 7 hours ago 447MB
5.基于systemd实现容器的CPU及内存的使用限制
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









